") 什么是CUDA?誰能打破CUDA的護城河?
什么是CUDA?誰能打破CUDA的護城河?
在最近的一場“AI Everywhere”發(fā)布會上,Intel的CEO Pat Gelsinger炮轟Nvidia的CUDA生態(tài)護城河并不深,而且已經(jīng)成為行業(yè)的眾矢之的。Gelsinger稱,“整個行業(yè)都希望能干掉CUDA,包括Google、OpenAI等公司都在想方設(shè)法讓人工智能訓練更加開放。我們認為CUDA的護城河既淺又窄。”
Gelsinger的這番話確實道出了整個人工智能行業(yè)對于Nvidia的CUDA又愛又恨的情緒;一方面,由于有了CUDA生態(tài),人工智能算法的訓練和部署從硬件層角度變得容易,人工智能工程師無需成為芯片專家,也能夠讓人工智能訓練高效地運行在Nvidia的GPU上。而從另一個角度,整個業(yè)界也過于依賴CUDA,以至于不少主打人工智能公司都對于CUDA的過度依賴產(chǎn)生了警惕性,這也就是Gelsinger所說的Google、OpenAI等公司都在設(shè)法研制自己的相應(yīng)解決方案(例如OpenAI的Triton)。本文將深入分析CUDA的強勢到底來源于哪里,以及究竟誰能打破CUDA壟斷。
什么是CUDA?
首先,我們先分析一下CUDA的來龍去脈。當我們在談?wù)摗癈UDA”的時候,我們究竟在談?wù)撌裁矗渴聦嵣希覀冋J為,CUDA包含三個層次。
首先,CUDA是一套編程語言。最初,3D圖像加速卡的主要任務(wù)是加速3D圖像的渲染,其用途相當專一。在本世紀初,Nvidia推出了GPU的概念以允許用戶使用圖像加速卡去做通用計算,并且在大約十五年前推出了相應(yīng)的CUDA編程語言,其主要任務(wù)是提供GPU的編程模型,從而實現(xiàn)通用GPU編程。在CUDA編程語言中,Nvidia提供了GPU的各種硬件抽象,例如基于線程的并行計算、內(nèi)存存取等概念,從而為GPU編程提供了方便。
除了編程語言之外,CUDA的第二層含義是一套高性能編譯系統(tǒng)。在使用CUDA編程之后,還需要把用CUDA語言編寫的程序使用CUDA編譯器針對相應(yīng)硬件優(yōu)化并且映射到更底層的硬件指令(對于Nvidia顯卡來說就是PTX)。CUDA的編譯器和GPU硬件的整合效率相當高,因此能編譯出非常高效的底層指令,這也是CUDA的另一個核心組成部分。
最后,CUDA的第三層是含義是Nvidia基于CUDA語言的一系列高性能函數(shù)庫,以及人工智能/高性能計算社區(qū)基于CUDA語言開發(fā)的一系列代碼庫。例如,CUDA的常用高性能函數(shù)庫包括用于線性計算的cuBLAS和CUTLASS,用于稀疏矩陣計算的cuSPARSE,用于傅立葉變幻的cuFFT,用于數(shù)值求解的cuSOLVER等。這些函數(shù)庫的發(fā)展至今已經(jīng)歷經(jīng)了十余年的努力,其優(yōu)化幾乎已經(jīng)做到了極致。另外,人工智能社區(qū)也有大量基于CUDA開發(fā)的代碼庫,例如Pytorch的默認后端就是CUDA。
CUDA每個層面的護城河
如上分析可知,CUDA其實包含了三個層面:編程語言,編譯器和生態(tài)。那么,CUDA這三個層面的護城河究竟在有多高?
首先,從編程語言的角度,事實上一直有OpenCL等社區(qū)開源語言試圖去實現(xiàn)類似(甚至更加廣泛的功能;OpenCL針對的不只是GPU編程,還包括了FPGA等異構(gòu)計算體系)的功能,AMD的ROCm平臺也是試圖做到與CUDA語言等價。從編程語言角度,CUDA并非不可取代。
其次,從編譯器的角度來看,CUDA提供的高性能編譯器確實是一個很高的護城河。編譯器的性能從很大程度上決定了用戶編寫的程序在GPU上執(zhí)行的效率;或者換句話說,對于人工智能應(yīng)用來說,一個很直觀的衡量標準就是用戶編寫的人工智能算法,能多大程度上利用GPU的峰值算力?大多數(shù)情況下,峰值算力平均利用率不到50%。另外,編譯器的性能還牽扯到了用戶調(diào)優(yōu)的過程。如果用戶是GPU專家,通過在編寫GPU程序時進行調(diào)優(yōu)(例如使用某種特定的方式去編寫語句),也可以很大程度上彌補編譯器的不足(因為編譯器的一個重要功能就是對編寫的程序做優(yōu)化,那么如果編寫的程序已經(jīng)比較優(yōu)化了那么對編譯器優(yōu)化能力的要求就可以低一些)。
但是,這就牽扯到了用戶的門檻,如果編譯器性能不夠好,需要用戶是專家才能實現(xiàn)高效率的GPU程序,就會大大提高用戶門檻,即只有擁有一支精英GPU編程專家團隊的公司才能充分發(fā)揮出GPU的性能;相反如果編譯器性能夠好,那么就可以降低用戶門檻,讓更多公司和個人也可以使用GPU高性能運行算法。
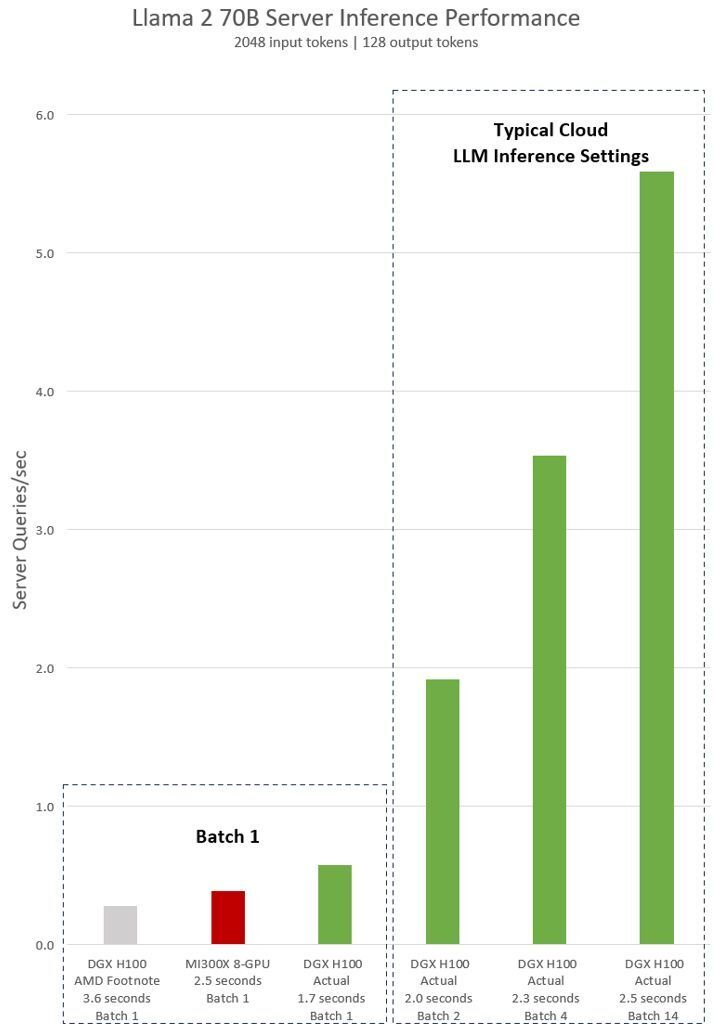
從這個角度來說,經(jīng)過十多年的積累,CUDA的編譯器(NVCC)已經(jīng)達到了相當高的水平。最近的另一個新聞也從側(cè)面印證了編譯器性能的重要性:AMD在12月初的發(fā)布會上宣布新的MI300X平臺在運行Llama2-70B模型的推理任務(wù)時,比起Nvidia H100 HGX的性能要強1.4倍;一周后,Nvidia回應(yīng)稱AMD在編譯測試時并沒有使用合理的設(shè)置,在使用正確設(shè)置后H100 HGX的性能事實上比MI300X要強1.5倍。由此可見,一個好的編譯器優(yōu)化對于充分利用GPU的性能可以說是至關(guān)重要。
然而,編譯器的護城河也并不是高不可破。例如,OpenAI的開源Triton編譯器可以同時兼容Nvidia和AMD以及更多平臺,支持把用戶使用Python編寫的程序直接優(yōu)化編譯到底層硬件指令語言,并且在Nvidia的成熟GPU上實現(xiàn)和CUDA接近的執(zhí)行效率。如果Triton這樣的開源編譯器獲得成功的話,至少從某種角度上可以省去其他人工智能芯片公司花數(shù)年精力去開發(fā)自己的編譯器的需求。
第三個層面是生態(tài)。目前,CUDA在生態(tài)領(lǐng)域可以說是遙遙領(lǐng)先,因為CUDA有著十多年的高性能程序庫的積累,以及基于這些程序庫上面社區(qū)開發(fā)的各種高性能框架代碼。生態(tài)的積累首先需要能提供一個領(lǐng)先的解決方案——如果其他公司也能提供一個高性能的編程語言和編譯器方案的話,自然會有社區(qū)去基于它開發(fā)代碼,而經(jīng)過長期不懈的積累之后,生態(tài)自然也會趕上。例如,人工智能領(lǐng)域最流行的框架PyTorch從這兩年開始也對于AMD的ROCm提供了支持,這就是生態(tài)領(lǐng)域的一個例子。換句話說,只要給足夠的時間和與CUDA語言/編譯器性能接近的方案,生態(tài)自然會慢慢趕上。
誰能打破CUDA的護城河
之前我們分析了CUDA從三個層面的護城河,我們可以發(fā)現(xiàn),Nvidia的CUDA從三個層面分別來看,編譯器和生態(tài)的護城河比較高,但也不是不可超越。我們看到,軟件科技公司之間正在試圖超越這條護城河,例如OpenAI的Triton編譯器能提供幾乎比肩CUDA的性能,而人工智能編程框架PyTorch的最新版本已經(jīng)在后端集成了Triton,可望在Nvidia已經(jīng)推出的成熟GPU上能實現(xiàn)很高的性能。
然而,Nvidia CUDA最強的護城河事實上在于軟件-芯片協(xié)同設(shè)計。如前所述,在Nvidia的GPU推出一段時間之后(例如半年或一年),第三方的軟件公司的方案(例如OpenAI的Triton)在研究透徹這款GPU之后,可以讓自己的方案做到比肩CUDA的水平。這意味著兩點:
首先,第三方軟件公司開發(fā)編譯器去嘗試匹配CUDA的性能永遠是一個追趕的過程,Nvidia發(fā)布新的GPU和相應(yīng)CUDA版本之后,需要半年到一年的時間才能實現(xiàn)性能基本匹配,但是基本難以到達Nvidia新GPU發(fā)布就立刻實現(xiàn)性能匹配甚至領(lǐng)先。
其次,芯片公司如果被動等待第三方軟件公司的編譯器去適配自己的人工智能加速硬件以追趕Nvidia的話,永遠無法打破Nvidia CUDA的領(lǐng)先地位。原因是,第三方軟件公司適配新的人工智能加速硬件需要時間;而在一年后等到第三方軟件公司的方案達到接近CUDA的水平的時候,Nvidia已經(jīng)發(fā)布下一代GPU了。這就陷入了永遠在追趕過程中的陷阱,難以打破CUDA護城河并實現(xiàn)領(lǐng)先。
因此,能真正打破CUDA護城河的,必須是有芯片-軟件協(xié)同設(shè)計能力的團隊,而不僅僅是一個軟件公司。這個團隊可以是一家擁有強大軟件能力的芯片公司(例如,Nvidia就是這樣的一個擁有強大芯片-軟件協(xié)同設(shè)計能得芯片公司的例子),或者是芯片和科技公司的結(jié)合。只有在芯片設(shè)計過程中就開始編譯器和軟件生態(tài)的適配,才能夠在芯片發(fā)布的初期就能推出芯片性能和軟件性能同時都比肩Nvidia GPU +CUDA的產(chǎn)品,從而真正打破CUDA的護城河。
如何在芯片設(shè)計過程中就實現(xiàn)軟硬件協(xié)同設(shè)計?事實上,編譯器的設(shè)計是基于一種編程模型,把硬件抽象為一些不同的層次(例如內(nèi)部并行計算,內(nèi)存存取等等),并且進一步根據(jù)這些硬件抽象去構(gòu)建性能模型,來實現(xiàn)性能的預(yù)測和優(yōu)化。從芯片設(shè)計的角度,需要能充分理解編譯器層面的這些硬件抽象和性能模型并不會百分百準確,因此如何設(shè)計一個好的芯片架構(gòu)讓編譯器能夠較為容易地去優(yōu)化程序就很重要。而從編譯器的角度,如前所述每一款芯片的編程模型和硬件抽象層都會略有不同,因此需要在芯片設(shè)計周期中就介入開始編譯器的優(yōu)化和硬件建模。兩者相結(jié)合,就能實現(xiàn)在芯片推出時就同時有很強的芯片理論性能和高度優(yōu)化的編程語言/編譯器,最終實現(xiàn)整體解決方案能和Nvidia的GPU+CUDA做有力的競爭。
從這個角度來看,Google的TPU+XLA就是一個滿足之前所屬芯片-軟件協(xié)同設(shè)計的案例。Google的自研TPU過程中和XLA編譯器通過軟硬件結(jié)合設(shè)計實現(xiàn)整體高性能方案(這也是TPU在MLPerf benchmark上和Nvidia的方案性能接近甚至領(lǐng)先的重要原因)。雖然TPU并不對第三方銷售因此這個方案并不會完全打破Nvidia CUDA的護城河,但是它至少提供了一個打破Nvidia CUDA護城河的技術(shù)方向。從另一個方面,AMD和Intel等芯片公司在編譯器領(lǐng)域的方案目前還有待加強,但是通過和OpenAI等科技公司合作,通過在下一代AI產(chǎn)品的設(shè)計過程中就和Triton這樣的領(lǐng)先編譯器方案協(xié)同設(shè)計,可望能在未來追趕Nvidia GPU + CUDA的性能;而在性能接近之后,生態(tài)的培養(yǎng)就只是一個時間問題了。
綜上,我們認為,CUDA雖然是一個軟件生態(tài),但是如果想要打破CUDA的護城河,需要的是軟硬件協(xié)同設(shè)計。
審核編輯:劉清
-
CUDA
+關(guān)注
關(guān)注
0文章
121瀏覽量
13623 -
GPU芯片
+關(guān)注
關(guān)注
1文章
303瀏覽量
5812 -
人工智能算法
+關(guān)注
關(guān)注
0文章
61瀏覽量
5236 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13225 -
OpenAI
+關(guān)注
關(guān)注
9文章
1087瀏覽量
6509
原文標題:誰能挑戰(zhàn)CUDA?
文章出處:【微信號:IC大家談,微信公眾號:IC大家談】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
怎么在TMDSEVM6678: 6678自帶的FFT接口和CUDA提供CUFFT函數(shù)庫選擇?
打破英偉達CUDA壁壘?AMD顯卡現(xiàn)在也能無縫適配CUDA了
英國公司實現(xiàn)英偉達CUDA軟件在AMD GPU上的無縫運行
中科馭數(shù)HADOS 3.0:以四大架構(gòu)革新,全面擁抱敏捷開發(fā)理念,引領(lǐng)DPU應(yīng)用生態(tài)

軟件生態(tài)上超越CUDA,究竟有多難?
傲睿科技用MEMS噴墨打印芯片助力國產(chǎn)打印機新品上市
借助NVIDIA Aerial CUDA增強5G/6G的DU性能和工作負載整合
英偉達CUDA-Q平臺推動全球量子計算研究
NVIDIA 通過 CUDA-Q 平臺為全球各地的量子計算中心提供加速

Keil使用AC6編譯提示CUDA版本過高怎么解決?
英偉達AI霸主地位遭巨頭聯(lián)手挑戰(zhàn),CUDA壟斷遭破局
適者生存,程序員最終會流向哪……
摩爾線程MUSA/MUSIFY與英偉達CUDA無依賴,開發(fā)者無憂
深入淺出理解PagedAttention CUDA實現(xiàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論