") 打破I/O 墻,還得靠高速接口IP和 Chiplet
打破I/O 墻,還得靠高速接口IP和 Chiplet
電子發(fā)燒友網(wǎng)報道(文/周凱揚)隨著 AI、自動駕駛等應用的興起,SoC 的設(shè)計變得愈發(fā)復雜,絕大多數(shù)走上自研芯片的公司都將絕大部分精力放在了計算單元上,比如自研核心、異構(gòu)計算等等。畢竟計算單元的算力決定了其性能上限,高性能產(chǎn)品也更容易收獲來自 AI、HPC、汽車等領(lǐng)域客戶的訂單。
打造這樣一個高性能SoC,尤其是面向數(shù)據(jù)中心和自動駕駛的高性能 SoC,高速接口同樣少不了,然而這一領(lǐng)域的自研壁壘就比較高了,往往需要組建專門的團隊。所以絕大多數(shù)廠商會選擇獲取第三方高速接口 IP的授權(quán)或者直接購買 Chiplet,從而縮短芯片的上市時間。
高速接口 IP
在數(shù)據(jù)中心,若想要發(fā)揮最新的 800Gbps 以太網(wǎng)的全部速度,就必須使用一個高速串行總線接口來匹配,為此不少 NIC/DPU和交換機廠商都在基于112G 以太網(wǎng)PHY IP開發(fā)支持 PAM-4 的 800Gbps 產(chǎn)品。諸如 Alphaware、新思、Cadence等廠商,都基于新的工藝節(jié)點推出了 112G 的IP。據(jù)統(tǒng)計,112G 以太網(wǎng)的部署將在 2025 年達到峰值,這是因為要想進一步控制功耗,此類 IP 也已經(jīng)過渡到 3nm 工藝,而 2025 年 3nm 也將成為主流節(jié)點之一。
此外,未來的 1.6Tbps 以太網(wǎng)也已經(jīng)在規(guī)劃中了,接口 IP 廠商們也迅速開啟了新一輪的布局和研發(fā)。以新思為例,在今年的TSMC Symposium上,新思成功展示了在背板通道上實現(xiàn) 224G 以太網(wǎng) PHY IP 的互操作,支持 PAM-4/6,可以與下一代可插拔近封裝光學(NPO)和共封裝光學(CPO)應用完美匹配。
數(shù)據(jù)到達服務(wù)器上后,仍需要利用高速接口,為存儲和加速器提供高速連接的支持,比如 PCIe 和 CXL 等,這才是 PCIe 6.0早早就被下一代 AI 芯片設(shè)計納入考量的原因,不少大廠和初創(chuàng)公司的產(chǎn)品路線圖上,都能看到 PCIe 6.0 的身影。
新思也在今年開啟了 PCIe 6.0 IP 的進程,Intel Innovation 2023大會上,新思在英特爾的PCIe 6.0 測試芯片上,展示了其 PCIe 6.0 IP在 FPGA 實現(xiàn)與測試芯片的互操作。這也與英特爾開啟 IDM 2.0 路線后的 EDA/IP 合作緊密相關(guān),今年 8 月,新思與英特爾宣布在英特爾未來的先進工藝節(jié)點上拓展合作關(guān)系,所以未來新思的一眾標準化高速接口 IP,也會對英特爾的Intel 3 和 Intel 18A 等節(jié)點提供支持。
當然,要說從商業(yè)角度來看,目前新思的高速接口 IP 還是在與臺積電的合作中取得了最大的成功。如果你對今年推出的各種高性能 AI 芯片有所關(guān)注的話,就會發(fā)現(xiàn)其中不少都用到了新思的DesignWare高速接口 IP。
在臺積電每年舉辦的OIP生態(tài)系統(tǒng)論壇上,新思往往是年度接口IP 合作伙伴這一獎項的常勝者。比如今年,除了N2、N3P 設(shè)計架構(gòu)、毫米波解決方案、3Dblox 設(shè)計原型解決方案以及與 Ansys、是德科技在 RF 參考設(shè)計流上的合作獲獎外,新思在 N3E 工藝節(jié)點上提供的接口 IP 方案,也獲得了臺積電的接口 IP 大獎,這些也都體現(xiàn)了新思在高速接口 IP 上的整體實力。
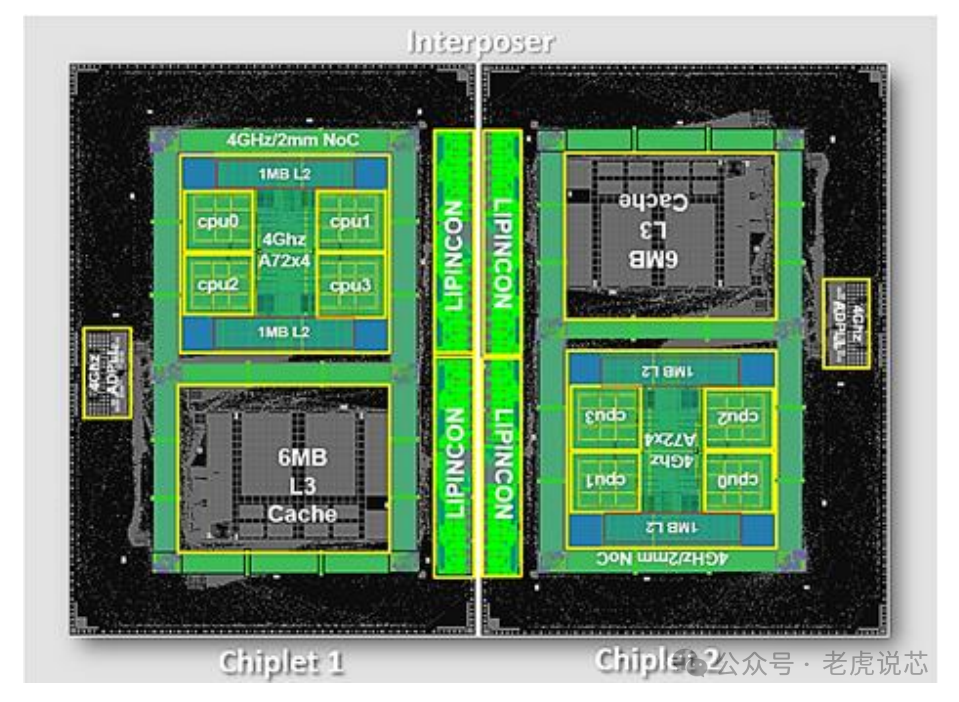
Chiplet互聯(lián)
早在數(shù)年前Chiplet就已經(jīng)面世了,但介于當時有限的互聯(lián)接口生態(tài),幾乎是只有半導體巨頭獨享,也沒有公開的市場供設(shè)計公司購買現(xiàn)成的 Chiplet并用于先進封裝中。這與 Chiplet 的數(shù)據(jù)互聯(lián)標準有關(guān),要想在封裝內(nèi)不同的 Chiplet 之間實現(xiàn)數(shù)據(jù)傳輸,就必須確定下標準。
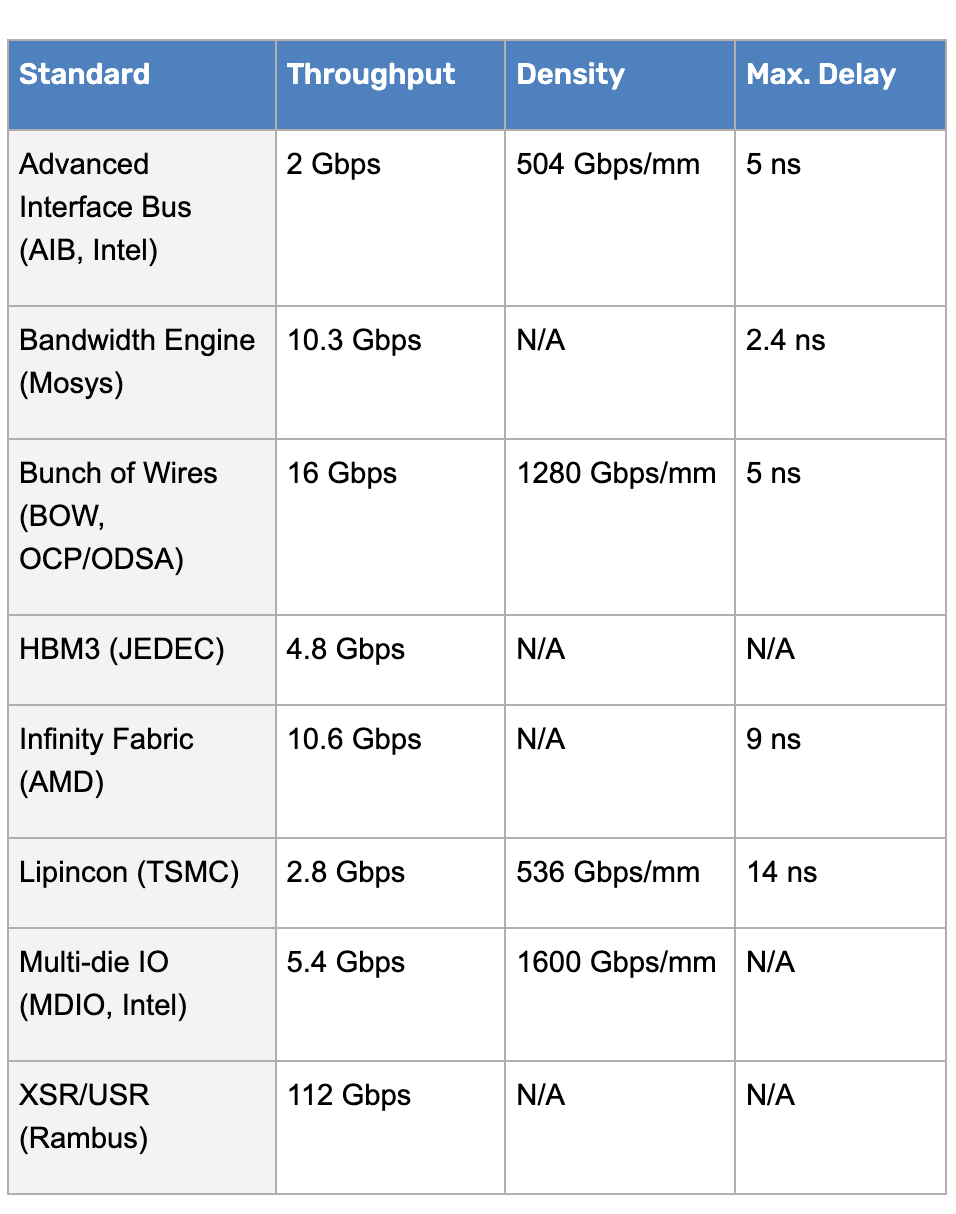
不同標準的吞吐量、密度和時延 / Cadence
如果我們來看上圖所示的互聯(lián)標準就會發(fā)現(xiàn),除了 BOW 和 HBM 以外,Chiplet 可用接口幾乎都是大廠開發(fā)的專有標準。如此一來,不僅設(shè)計受限,還必須獲得 IP 授權(quán)才能為自己的產(chǎn)品選用合適的接口,這也就是 UCIe 標準的成立如此重要的原因。
采用并行總線架構(gòu)的UCIe 可以看作是性能更高的 BOW,且不像 HBM 一樣只局限于 DRAM,追求的是通用 Chiplet 之間的高速互聯(lián)互通,也支持 PCIe 和 CXL 等協(xié)議。在 Chiplet 技術(shù)逐漸成熟的當下,芯粒接口標準和相關(guān)的統(tǒng)一生態(tài)已經(jīng)初具雛形,為此產(chǎn)業(yè)鏈上下游都在跟進這一新的設(shè)計路線。但由于與 Chiplet設(shè)計緊密相關(guān)的先進封裝方案成本高、產(chǎn)能低,所以基于 Chiplet 設(shè)計 SoC的更大規(guī)模量產(chǎn)還未實現(xiàn)。
為此國內(nèi) IP 廠商奎芯科技也提出了自己的解決方案,作為國內(nèi)領(lǐng)先的高速接口 IP 和 Chiplet 廠商,其在 2023 年成功研發(fā)了 LPDDR5X、LPDDR4X和 ONFI 5.1接口 IP,也推出了基于 UCIe 標準的 D2D 接口 IP 以及 M2Link 系列接口芯粒產(chǎn)品。
而 M2LINK,就是奎芯科技為解決 HBM 互聯(lián)提供的 UCIe Chiplet解決方案,實現(xiàn)HBM 與 SoC 的解耦。從不少采用 HBM 方案的芯片設(shè)計中可以看出,主 SoC 是與 HBM 緊緊相連且對齊的,SoC 的設(shè)計中也必須把HBM IP 占用面積和所用工藝考慮在內(nèi),這樣一來SoC 的設(shè)計就頻繁受限了,更不用說追求大容量 HBM必須考慮的成本和產(chǎn)能問題。
而奎芯科技的 M2LINK D2D 則利用一顆額外的 Chiplet 將 HBM 接口協(xié)議,轉(zhuǎn)換成 UCIe 接口協(xié)議,這樣主 SoC 的設(shè)計上只需將原來的 HBM IP 替換為 UCIe IP。根據(jù)奎芯科技提供的數(shù)據(jù),這樣的改動可以讓 SoC 可利用面積增大 44%,最大芯片尺寸擴大兩倍,SoC 與 DRAM 模組之間的距離可以拉遠至 25mm。且其M2Link D2D產(chǎn)品支持 2D 封裝,只需基于臺積電 12nm 工藝節(jié)點即可實現(xiàn)。
寫在最后
隨著越來越多的廠商跨界加入自研芯片的行列,尤其是云服務(wù)廠商和互聯(lián)網(wǎng)廠商,IP 市場還將迎來新一輪的增長。而在他們加大投入的過程中,我們也能清楚地看到,接口 IP 營收的復合增長率開始高過處理器 IP,尤其是PCIe、DDR 內(nèi)存控制器與 SerDes 相關(guān)的產(chǎn)品。
而 Chiplet 作為更為簡單快捷的設(shè)計路線,在 UCIe 生態(tài)壯大后,也勢必會成為新的主流。至于國產(chǎn)IP 和 Chiplet 廠商,還需要在更先進的工藝節(jié)點上盡快獲得硅驗證,也不能止步于提供單一的解決方案,因為一站式的解決方案在不少設(shè)計廠商看來或許更有吸引力。
-
高速接口
+關(guān)注
關(guān)注
1文章
44瀏覽量
14786 -
chiplet
+關(guān)注
關(guān)注
6文章
434瀏覽量
12609
發(fā)布評論請先 登錄
相關(guān)推薦

物聯(lián)網(wǎng)中常見的I/O擴展電路設(shè)計方案_IIC I/O擴展芯片
宜科FX20系列分布式I/O再添兩位新成員
淺談如何克服FPGA I/O引腳分配挑戰(zhàn)
雙向4Tbps、兼容PCIe5.0!英特爾光學I/O chiplet再突破
便攜儲能中種類豐富的I/O接口芯片
加速科技突破2.7G高速數(shù)據(jù)接口測試技術(shù)
16路數(shù)字量輸入I/O模塊用于測量和控制

BACnet/IP 智慧樓宇擴展分布式I/O
Ethernet/IP 協(xié)議分布式I/O系統(tǒng)
FANUC外部I/O點數(shù)不夠用了怎么辦?可以擴展I/O點數(shù)嗎?
光I/O接口革命:4Tb/s超高速傳輸引領(lǐng)未來

什么是Chiplet技術(shù)?
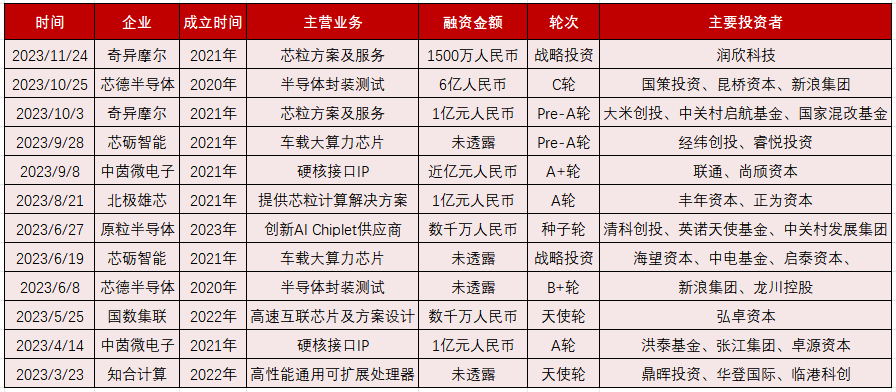
2023年Chiplet發(fā)展進入新階段,半導體封測、IP企業(yè)多次融資





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論