") 什么是LlamaIndex?LlamaIndex數(shù)據(jù)框架的特點和功能
什么是LlamaIndex?LlamaIndex數(shù)據(jù)框架的特點和功能
來源:Coggle數(shù)據(jù)科學(xué)
什么是LlamaIndex ?
LlamaIndex是一個數(shù)據(jù)框架,用于讓基于LLM的應(yīng)用程序攝取、結(jié)構(gòu)化和訪問私有或領(lǐng)域特定的數(shù)據(jù)。它提供Python和Typescript版本。
LLMs提供了人類和數(shù)據(jù)之間的自然語言接口。廣泛可用的模型預(yù)先訓(xùn)練了大量公開可用的數(shù)據(jù),如維基百科、郵件列表、教科書、源代碼等。然而,雖然LLMs在大量數(shù)據(jù)上進行了訓(xùn)練,但它們沒有接觸您的數(shù)據(jù),這可能是私有的或與您要解決的問題特定相關(guān)的數(shù)據(jù)。它可能存在于APIs、SQL數(shù)據(jù)庫中,或者被困在PDF和幻燈片中。
LlamaIndex特點
LlamaIndex采用了一種稱為檢索增強生成(RAG)的不同方法。與要求LLMs立即生成答案不同,LlamaIndex:
先從您的數(shù)據(jù)源中檢索信息,
將其添加到您的問題作為上下文,
要求LLMs基于豐富的提示進行回答。
RAG克服了微調(diào)方法的所有三個缺點:
由于不涉及訓(xùn)練,因此它是便宜的。
僅在您要求時才檢索數(shù)據(jù),因此它始終保持最新。
LlamaIndex可以向您展示檢索到的文檔,因此它更可信。
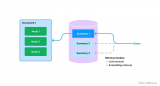
LlamaIndex對您如何使用LLMs沒有限制。您仍然可以將LLMs用作自動完成、聊天機器人、半自主代理等(請參見左側(cè)的用例)。它只是使LLMs對您更有相關(guān)性。
LlamaIndex功能
LlamaIndex提供以下工具:
數(shù)據(jù)連接器從其原生來源和格式攝取您的現(xiàn)有數(shù)據(jù)。這可以是APIs、PDF、SQL等等。
數(shù)據(jù)索引將您的數(shù)據(jù)結(jié)構(gòu)化為中間表示,LLMs可以輕松高效地使用。
引擎為您的數(shù)據(jù)提供自然語言訪問。例如:
查詢引擎是用于知識增強輸出的強大檢索接口。
聊天引擎是用于與數(shù)據(jù)進行多消息、“來回”交互的對話接口。
數(shù)據(jù)代理是由工具增強的LLM驅(qū)動的知識工作者,從簡單的輔助功能到API集成等等。
應(yīng)用集成將LlamaIndex與您的生態(tài)系統(tǒng)的其余部分相連接。這可以是LangChain、Flask、Docker、ChatGPT或… 其他任何東西!
LlamaIndex安裝
pipinstallllama-index
安裝通常所需的可選依賴項的方法。目前,這些依賴項分為三組:
pip install llama-index[local_models]安裝對私有LLMs、本地推理和HuggingFace模型有用的工具
pip install llama-index[postgres]如果您正在使用Postgres、PGVector或Supabase,則此選項很有用
pip install llama-index[query_tools]為您提供混合搜索、結(jié)構(gòu)化輸出和節(jié)點后處理的工具
檢索增強生成(RAG)
LLMs在龐大的數(shù)據(jù)集上進行訓(xùn)練,但它們并沒有接觸您的數(shù)據(jù)。檢索增強生成(RAG)通過將您的數(shù)據(jù)添加到LLMs已經(jīng)可以訪問的數(shù)據(jù)中來解決這個問題。在本文檔中,您將經(jīng)常看到對RAG的引用。
在RAG中,您的數(shù)據(jù)被加載并準(zhǔn)備進行查詢或“索引”。用戶的查詢作用于索引,將您的數(shù)據(jù)篩選到最相關(guān)的上下文。然后,此上下文和您的查詢與LLM一起傳遞給一個提示,LLM將提供響應(yīng)。
即使您正在構(gòu)建的是一個聊天機器人或代理,您也會想要了解RAG技術(shù),以將數(shù)據(jù)引入您的應(yīng)用程序。
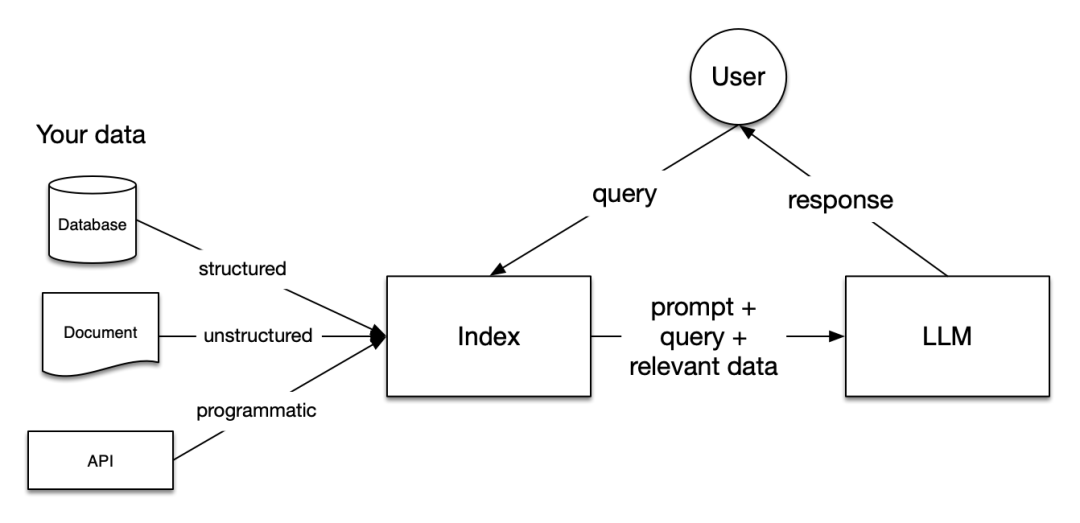
RAG中的階段
RAG中有五個關(guān)鍵階段,這些階段將成為您構(gòu)建的任何更大應(yīng)用程序的一部分。這些階段是:
加載:這指的是從數(shù)據(jù)所在的地方(無論是文本文件、PDF、另一個網(wǎng)站、數(shù)據(jù)庫還是API)獲取您的數(shù)據(jù),將其引入您的管道。LlamaHub 提供了數(shù)百個可供選擇的連接器。
索引:這意味著創(chuàng)建一個允許查詢數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu)。對于LLMs,這幾乎總是意味著生成矢量嵌入,這是您的數(shù)據(jù)意義的數(shù)字表示,以及許多其他元數(shù)據(jù)策略,使其易于準(zhǔn)確找到上下文相關(guān)的數(shù)據(jù)。
存儲:一旦您的數(shù)據(jù)被索引,您幾乎總是希望存儲您的索引,以及其他元數(shù)據(jù),以避免必須重新索引它。
查詢:對于任何給定的索引策略,您可以使用LLMs和LlamaIndex數(shù)據(jù)結(jié)構(gòu)以多種方式進行查詢,包括子查詢、多步查詢和混合策略。
評估:在任何管道中,檢查其相對于其他策略或在進行更改時的有效性是一個關(guān)鍵步驟。評估提供了有關(guān)您對查詢的響應(yīng)的準(zhǔn)確性、忠實度和速度的客觀度量。

每個步驟中的重要概念
在每個階段中,您還會遇到一些涉及到這些階段的術(shù)語。
加載階段
節(jié)點和文檔:一個文檔是圍繞任何數(shù)據(jù)源的容器,例如PDF、API輸出或從數(shù)據(jù)庫檢索的數(shù)據(jù)。節(jié)點是LlamaIndex中數(shù)據(jù)的原子單位,表示源文檔的“塊”。節(jié)點具有將其與所在文檔和其他節(jié)點相關(guān)聯(lián)的元數(shù)據(jù)。
連接器:數(shù)據(jù)連接器(通常稱為讀取器)從不同的數(shù)據(jù)源和數(shù)據(jù)格式中攝取數(shù)據(jù)到文檔和節(jié)點中。
索引階段
索引:一旦攝取了您的數(shù)據(jù),LlamaIndex將幫助您將數(shù)據(jù)索引到易于檢索的結(jié)構(gòu)中。這通常涉及生成矢量嵌入,這些嵌入存儲在一個稱為矢量存儲的專用數(shù)據(jù)庫中。索引還可以存儲有關(guān)您的數(shù)據(jù)的各種元數(shù)據(jù)。
嵌入:LLMs生成稱為嵌入的數(shù)據(jù)的數(shù)字表示。在為相關(guān)性過濾數(shù)據(jù)時,LlamaIndex將查詢轉(zhuǎn)換為嵌入,并且您的矢量存儲將找到數(shù)值上與查詢嵌入相似的數(shù)據(jù)。
查詢階段
檢索器:檢索器定義了在給定查詢時如何有效地從索引中檢索相關(guān)上下文。您的檢索策略對于檢索的數(shù)據(jù)的相關(guān)性以及執(zhí)行此操作的效率至關(guān)重要。
路由器:路由器確定將使用哪個檢索器從知識庫中檢索相關(guān)上下文。更具體地說,RouterRetriever類負(fù)責(zé)選擇一個或多個候選檢索器來執(zhí)行查詢。它們使用選擇器根據(jù)每個候選的元數(shù)據(jù)和查詢選擇最佳選項。
節(jié)點后處理器:節(jié)點后處理器接收一組檢索到的節(jié)點并對其應(yīng)用變換、過濾或重新排序邏輯。
響應(yīng)合成器:響應(yīng)合成器使用用戶查詢和一組檢索到的文本塊從LLM生成響應(yīng)。
將所有內(nèi)容整合在一起
有無數(shù)數(shù)據(jù)支持的LLM應(yīng)用程序的用例,但它們大致可以分為三類:
查詢引擎:查詢引擎是一個端到端的管道,允許您在數(shù)據(jù)上提問。它接收自然語言查詢,并返回一個響應(yīng),以及檢索到的并傳遞給LLM的參考上下文。
聊天引擎:聊天引擎是一個端到端的管道,用于與您的數(shù)據(jù)進行對話(而不是單一的問答)。
代理:代理是由LLM驅(qū)動的自動決策者,通過一組工具與世界互動。代理可以采取任意數(shù)量的步驟來完成給定任務(wù),動態(tài)決定最佳行動方案,而不是按照預(yù)先確定的步驟進行。這使得它具有處理更復(fù)雜任務(wù)的額外靈活性。
審核編輯:湯梓紅
-
接口
+關(guān)注
關(guān)注
33文章
8598瀏覽量
151157 -
SQL
+關(guān)注
關(guān)注
1文章
764瀏覽量
44130 -
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3799瀏覽量
64390 -
自然語言
+關(guān)注
關(guān)注
1文章
288瀏覽量
13350 -
LLM
+關(guān)注
關(guān)注
0文章
288瀏覽量
335
原文標(biāo)題:小白學(xué)大模型:LlamaIndex數(shù)據(jù)框架
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
多功能程序框架
主流web前端技術(shù)框架
power_supply框架包括哪些功能?
OpenHarmony 3.1 Beta版本關(guān)鍵特性解析——HiStreamer框架大揭秘
WCDB移動數(shù)據(jù)框架的功能
基于功能體驗ios新增了SiriKit框架
什么是Hibernate?Hibernate框架架構(gòu)與框架原理分析
大數(shù)據(jù)具有哪些特點優(yōu)勢和應(yīng)用功能
DB4494_無線工業(yè)節(jié)點上的多傳感器AI數(shù)據(jù)監(jiān)控框架,STM32Cube的功能包

LlamaIndex:面向QA系統(tǒng)的全新文檔摘要索引
fastapi框架原理及應(yīng)用
谷歌模型框架是什么?有哪些功能和應(yīng)用?
使用OpenVINO和LlamaIndex構(gòu)建Agentic-RAG系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論