 機器視覺原理及常用工具庫
機器視覺原理及常用工具庫
來源:古月居
對于人類來講,90%以上的信息都是通過視覺獲取的,眼睛就是獲取大量視覺信息的傳感器,然后再交給大腦這個“處理器”進行處理,之后我們才能理解外部環境,建立世界觀。
如何讓機器人也能理解外部環境呢,我們首先想到的就是給機器人也安裝一對眼睛,是不是就可以和人類一樣來理解世界了呢?但是這個過程可比人類復雜的多,本講我們就來學習機器人中的視覺處理技術。
機器視覺這么火,那么它的基本原理是什么樣的呢?我們先來了解一下。
機器視覺原理
?機器視覺:用計算機來模擬人的視覺功能,但并不僅僅是人眼的簡單延伸,更重要的是具有人腦的一部分功能一一從客觀事物的圖像中提取信息,進行處理并加以理解,最終用于實際檢測、測量和控制;
?交叉學科:涉及人工智能、神經生物學、物理學、計算機科學、圖像處理、模式識別等諸多領域;
?關鍵技術:圖像采集與處理、模式識別、機器學習…;
?傳感器:單目視覺、雙目立體視覺、多目視覺、全景視覺等;
人類視覺擅長于對復雜、非結構化的場景進行定性解釋,但機器視覺憑借速度、精度和可重復性等優勢,非常適合對結構化場景進行定量測量。
一般來講,典型的機器視覺系統可以分為如圖1所示的三個部分:圖像采集、圖像分析和控制輸出。

圖1 典型機器視覺系統的三個部分
圖像采集注重對原始光學信號的采樣,是整個視覺系統的傳感部分,核心是相機和相關的配件。
其中光源用于照明待檢測的物體,并突顯其特征,便于讓相機能夠更好的捕捉圖像。光源是影響機器視覺系統成像質量的重要因素,好的光源和照明效果對機器視覺判斷影響很大。當前,機器視覺的光源已經突破人眼的可見光范圍,其光譜范圍跨越紅外光(IR)、可見光、紫外光(UV)乃至X射線波段,可實現更精細和更廣泛的檢測范圍,以及特殊成像需求。
相機被喻為機器視覺系統的“眼睛”,承擔著圖像信息采集的重要任務。圖像傳感器又是相機的核心元器件,主要有CCD和CMOS兩種類型,其工作原理是將相機鏡頭接收到的光學信號轉化成數字信號。選擇合適的相機是機器視覺系統設計的重要環節,不僅直接決定了采集圖像的質量和速度,同時也與整個系統的運行模式相關。
圖像處理系統接收到相機傳來的數字圖像之后,通過各種軟件算法進行圖像特征提取、特征分析和數據標定,最后進行判斷。這是各種視覺算法研究最為集中的部分,從傳統的模式識別算法,到當前熱門的各種機器學習方法,都是為了更好的讓機器理解環境。
對于人來講,識別某一個物體是蘋果似乎理所當然,但是對于機器人來講,就需要提取各種各樣不同種類、顏色、形狀的蘋果特征,然后訓練得到一個蘋果的“模型”,再通過這個模型對實時圖像做匹配,從而分析面前這個東西到底是不是蘋果。
在機器人系統中,視覺識別的結果最終要和機器人的某些行為綁定,也就是第三個部分——控制輸出,包含I/O接口、運動控制、可視化顯示等。當圖像處理系統完成圖像分析后,將判斷的結果發給機器人控制系統,接下來機器人完成運動控制。比如視覺識別到了抓取目標的位置,通過IO口控制夾爪完成抓取和放置,過程中識別的結果和運動的狀態,都可以在上位機中顯示,方便我們監控。
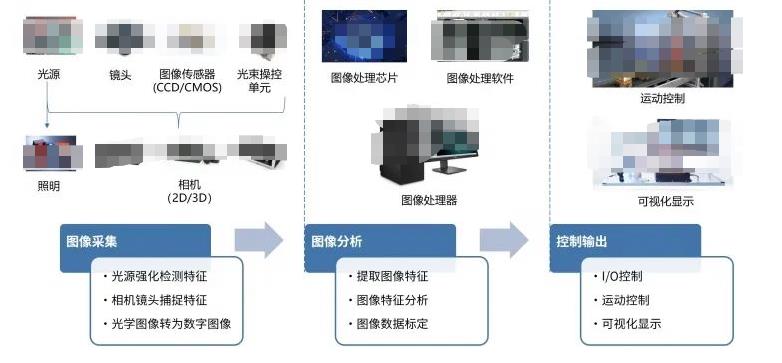
圖2 典型機器視覺系統的三個部分
開源軟件或框架
就機器視覺而言,在這三個部分中,圖像分析占據了絕對的 核心,涉及的方法、使用的各種開源軟件或者框架非常多,我們來了解最為常用的幾個。
OpenCV
?推進機器視覺的研究,提供一套開源且優化的基礎庫,實現了圖像處理和計算機視覺方面的很多通用算法;
?提供一個共同的基礎庫,使得開發人員的代碼更容易閱讀和轉讓,促進了知識的傳播;
?透過提供不需要開源或免費的軟件許可( BSD ),促進商業應用軟件的開發;
?由一系列C函數和少量C++類構成,同時提供C++、Python、Ruby、MATLAB、C#、GO等語言的接口。
OpenCV這個名稱很多人應該聽說過,這是機器視覺領域最為知名的開源軟件之一。
OpenCV主要使用C/C++語言編寫,執行效率較高,致力于真實世界的實時應用。OpenCV實現了圖像處理和計算機視覺方面很多通用算法,這樣我們在開發視覺應用的時候,就不需要重新去造輪子,而是基于這些基礎庫,專注自己應用的優化,同時大家的基礎平臺一致,在知識傳播的時候也更加方便,只要你看得懂OpenCV的函數,就可以很快熟悉別人用OpenCV寫的代碼,大家交流起來非常方便。
和機器人操作系統一樣,一款可以快速傳播的開源軟件,一般都會選擇相對開放的許可證,OpenCV主要采用BSD許可證,我們基于OpenCV寫的代碼,可以對原生庫做修改,不用開源,還可以商業化應用。OpenCV目前支持的編程語言也非常多,無論你熟悉哪一種,都可以調用OpenCV快速開始視覺開發,比如C ++,Python,Java、MATLAB等語言,而且還支持Windows,Linux,Android和Mac OS等操作系統。
OpenCV中提供的功能非常多,我們在后續的內容中,會給大家介紹一些基礎的圖像處理方法,大家如果想要深入研究,還可以網上搜索相關的內容。
?Google在2015年發布的機器學習平臺,采用數據流圖,架構靈活,用于數值計算的開源軟件庫;
?節點在圖中表示數學操作,線表示在節點間相互聯系的多維數據數組,即張量(tensor);
TensorFlow的整體技術框架為兩個部分:前端系統提供編程模型,負責構造計算圖;后端系統提供運行時環境,負責執行計算圖。
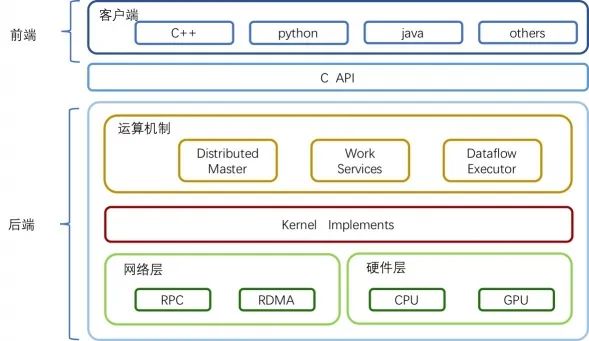
圖4 TensorFlow整體技術框架
這里的計算圖大家應該似曾相識,沒錯,機器人操作系統ROS的技術框架也是用到了計算圖。在TensorFlow的計算圖中,數據流是重點,數據在這個圖中以張量(tensor)的形式存在,節點在圖中表示數學操作,邊表示節點間數據的流向。在機器學習的訓練過程中,張量——也就是數據,會不斷從數據流圖中的一個節點流向(flow)另外一個節點,從而完成一系列數學運算,最終得到結果。這就是TensorFlow名稱的由來,正如如圖5所示的這張圖一樣,它生動形象地描述了復雜數據結構在人工神經網中的流動、傳輸、分析和處理模式。
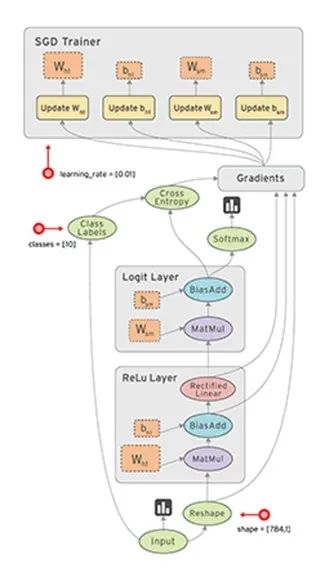
圖5 TensorFlow整體技術框架
為了便于數據的調試和可視化,TensorFlow還提供了一套可視化工具——TensorBoard,用戶可以很容易看到數據流動的每一個部分,同時看到數據訓練或者測試的效果。比如如圖9-8所示中,經過前邊神經網絡的計算,藍色和黃色兩種數據被逐漸識別并區分開來。
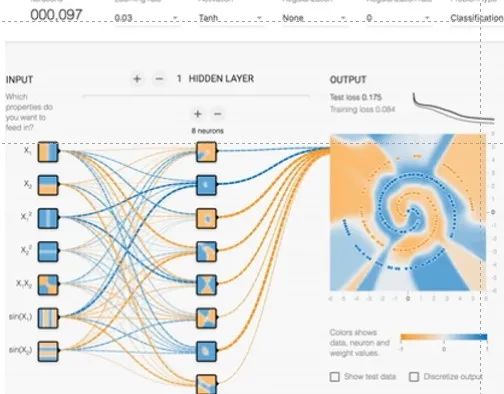
圖6 TensorBoard
TensorFlow跨平臺性好,可以在Linux、MacOS、Windows、Android等系統下運行,還可以在眾多計算機中分布式運行,回想一下多年前戰勝人類的圍棋AI——AlphaGo,其后臺在上萬臺計算機中、基于TensorFlow搭建的“最強大腦”。
當然,TensorFlow也有不足之處,主要表現在它的代碼比較底層,需要用戶編寫大量的應用代碼,而且很多相似的功能,用戶還不得不“重新造輪子”。
此外,TensorFlow是Google資深工程師開發而來,使用了不少高深的技術和概念,對于大眾開發者來講,上手學習的門檻就有點高,熟悉的人可以用的爐火純青,做出很炫酷的效果,不熟悉的人上手就得花費很長時間。對此,TensorFlow官方也提供了一些開源例程和不少訓練好的模型,其中之一就是Tensorflow Object Detection API,實現了近年來多種優秀的深度卷積神經網絡,可以幫助開發者輕松構建、訓練和部署對象檢測模型。
如圖7所示,前兩個是TensorFlow官方例程中的目標檢測演示,可以在圖片中識別出小狗、人、風箏等目標,在這套開源的框架中,官方還附帶了80多種已經訓練好的目標模型,包含了我們生活中常見的物品,這兩個圖片就是使用官方模型識別的效果,比如這里識別到的碗、西蘭花,還有這里的杯子、桌子、瓶子等,都可以較為穩定的識別到。不過模型之外的物品就難以識別了。
圖7 TensorFlow Object Detection API
想要使用這套框架識別其他目標怎么辦,沒問題,我們可以針對想要識別的目標采樣并標注,再放到網絡中訓練,就可以得到自己的模型庫了,接下來就可以完成我們想要的識別任務。比如這里識別兩位明星的效果,就是網友使用TensorFlow目標檢測方法實現的。
總之Tensorflow Object Detection API,為我們演示了一整套TensorFlow工程應用的流程,按照這個流程,我們就可以快速開發視覺目標檢測了。
PyTorch
PyTorch:
?Facebook在2017年發布的一個開源的Python機器學習庫,底層由C++實現;
?不僅能夠實現強大的GPU加速,同時還支持動態神經網絡;
?簡潔高效,追求最少的封裝,符合人類思維,讓用戶盡可能地專注于實現自己的想法;
?除了Facebook外,它已經被Twitter、CMU和Salesforce等機構采用;
之前我們有提到過TensorFlow入門門檻較高,除此之外,TensorFlow中的計算圖是靜態的,也就是說我們要先創建好計算圖的結構,然后才能訓練,過程中想要改變網絡模型是比較困難的。
2017年初,Facebook發布了另外一個開源的機器學習庫——PyTorch,雖然底層也是用C++實現的,但是上層主要支持Python。如果用編程語言做一個類比,Tensorflow需要先構建計算圖,這就類似C語言,運行之前需要先進行編譯,但是可以適配不同的硬件平臺,效率較高;而PyTorch類似Python語言,可以動態構建圖結構,簡單靈活,但是功能的全面性和跨平臺性稍差。
除此之外,PyTorch的設計追求最少的封裝,盡量符合人類的思維模式,避免重復造輪子,讓用戶盡可能地專注于實現自己的想法,所思即所得,不需要考慮太多關于框架本身的束縛。不像TensorFlow中張量、圖、操作、變量等抽象的概念,PyTorch精簡了很多,源碼也只有TensorFlow的十分之一左右,更少的抽象、更直觀的設計,使得PyTorch的源碼十分易于閱讀,也更容易進行調試,就像Python代碼一樣。
總結而言,TensorFlow和PyTorch都是優秀的機器學習開源框架,兩者的功能類似,TensorFlow跨平臺性能更好,PyTorch靈活易用性更好,兩者都有較為廣泛的應用,而且作為機器學習的計算平臺,兩者不僅都可以用于機器視覺識別,還可以用于自然語言理解、運動控制等諸多領域。
圖8 PyTorch
YOLO
回到具體的目標識別。以自動駕駛為例,人們看到圖像以后,可以立即識別其中的對象以及所在的位置。這讓我們能夠在幾乎無意識的情況下完成復雜的任務,比如躲避行人。
因此,自動駕駛的訓練需要類似水平的反應能力和準確性。這樣的系統必須能夠分析實時視頻中的道路,并且能夠在確定路徑之前,檢測各種類型的對象及其在現實中的位置。
YOLO就是當前最為熱門的一種實時目標檢測系統,在2015年提出,全稱是You only look once,看一眼就能夠識別出來,可見實時性對YOLO是至關重要的指標。簡單介紹下YOLO的算法流程,它將對象檢測重新定義為一個回歸問題,運用單個卷積神經網絡(CNN) ,將圖像分成網格,并預測每個網格的對象概率和邊界框。
以一個100x100的圖像為例,Yolo的CNN網絡將輸入的圖片分割成7x7的網格,然后每個網格負責去檢測那些中心點落在該格子內的目標,比如如圖9所示,小狗這個目標的中心點在左下角的網格中,那該網格就負責預測狗這個對象。
每個網格中將有多個邊界框,在訓練時,我們希望每個對象只有一個邊界框,比如最終只有一個邊界框把這只狗包起來。因此,我們根據哪個邊界框與之前標注的重疊度最高,預測對象的位置和概率。
最終包圍對象的邊界框,就是識別的結果,使用四個描述符進行說明:
1.邊界框的中心位置
2.邊界框的高度
3.邊界框的寬度
4.識別到對象所屬的類
這樣就完成了對目標的實時檢測,拿到目標的信息之后,就可以進行后續的機器人行為控制了。YOLO識別的速度非常快,它能夠處理實時視頻流,比如車輛行駛的動態監測、自然環境中的目標識別,有著非常廣泛的應用價值。
以上就是當前較為熱門的機器學習和目標檢測框架,用于機器視覺的開源軟件還有很多,有興趣可以繼續探索補充。
審核編輯:湯梓紅
-
傳感器
+關注
關注
2551文章
51147瀏覽量
753999 -
機器視覺
+關注
關注
162文章
4376瀏覽量
120381 -
機器學習
+關注
關注
66文章
8421瀏覽量
132703 -
OpenCV
+關注
關注
31文章
635瀏覽量
41370
原文標題:機器視覺原理及常用工具庫
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論