") 專補(bǔ)大模型短板的RAG有哪些新進(jìn)展?這篇綜述講明白了
專補(bǔ)大模型短板的RAG有哪些新進(jìn)展?這篇綜述講明白了
同濟(jì)大學(xué)王昊奮研究員團(tuán)隊(duì)聯(lián)合復(fù)旦大學(xué)熊赟教授團(tuán)隊(duì)發(fā)布檢索增強(qiáng)生成(RAG)綜述,從核心范式,關(guān)鍵技術(shù)到未來(lái)發(fā)展趨勢(shì)對(duì) RAG 進(jìn)行了全面梳理。這份工作為研究人員繪制了一幅清晰的 RAG 技術(shù)發(fā)展藍(lán)圖,指出了未來(lái)的研究探索方向。同時(shí),為開發(fā)者提供了參考,幫助辨識(shí)不同技術(shù)的優(yōu)缺點(diǎn),并指導(dǎo)如何在多樣化的應(yīng)用場(chǎng)景中最有效地利用這些技術(shù)。
大型語(yǔ)言模型(LLMs)已經(jīng)成為我們生活和工作的一部分,它們以驚人的多功能性和智能化改變了我們與信息的互動(dòng)方式。
然而,盡管它們的能力令人印象深刻,但它們并非無(wú)懈可擊。這些模型可能會(huì)產(chǎn)生誤導(dǎo)性的 “幻覺”,依賴的信息可能過時(shí),處理特定知識(shí)時(shí)效率不高,缺乏專業(yè)領(lǐng)域的深度洞察,同時(shí)在推理能力上也有所欠缺。
在現(xiàn)實(shí)世界的應(yīng)用中,數(shù)據(jù)需要不斷更新以反映最新的發(fā)展,生成的內(nèi)容必須是透明可追溯的,以便控制成本并保護(hù)數(shù)據(jù)隱私。因此,簡(jiǎn)單依賴于這些 “黑盒” 模型是不夠的,我們需要更精細(xì)的解決方案來(lái)滿足這些復(fù)雜的需求。 正是在這樣的背景下,檢索增強(qiáng)生成技術(shù)(Retrieval-Augmented Generation,RAG)應(yīng)時(shí)而生,成為 AI 時(shí)代的一大趨勢(shì)。
RAG 通過在語(yǔ)言模型生成答案之前,先從廣泛的文檔數(shù)據(jù)庫(kù)中檢索相關(guān)信息,然后利用這些信息來(lái)引導(dǎo)生成過程,極大地提升了內(nèi)容的準(zhǔn)確性和相關(guān)性。RAG 有效地緩解了幻覺問題,提高了知識(shí)更新的速度,并增強(qiáng)了內(nèi)容生成的可追溯性,使得大型語(yǔ)言模型在實(shí)際應(yīng)用中變得更加實(shí)用和可信。RAG 的出現(xiàn)無(wú)疑是人工智能研究領(lǐng)域最激動(dòng)人心的進(jìn)展之一。
本篇綜述將帶你全面了解 RAG,深入探討其核心范式、關(guān)鍵技術(shù)及未來(lái)趨勢(shì),為讀者和實(shí)踐者提供對(duì)大型模型以及 RAG 的深入和系統(tǒng)的認(rèn)識(shí),同時(shí)闡述檢索增強(qiáng)技術(shù)的最新進(jìn)展和關(guān)鍵挑戰(zhàn)。

論文原文:https://arxiv.org/abs/2312.10997
官方倉(cāng)庫(kù):https://github.com/Tongji-KGLLM/RAG-Survey
RAG 是什么?
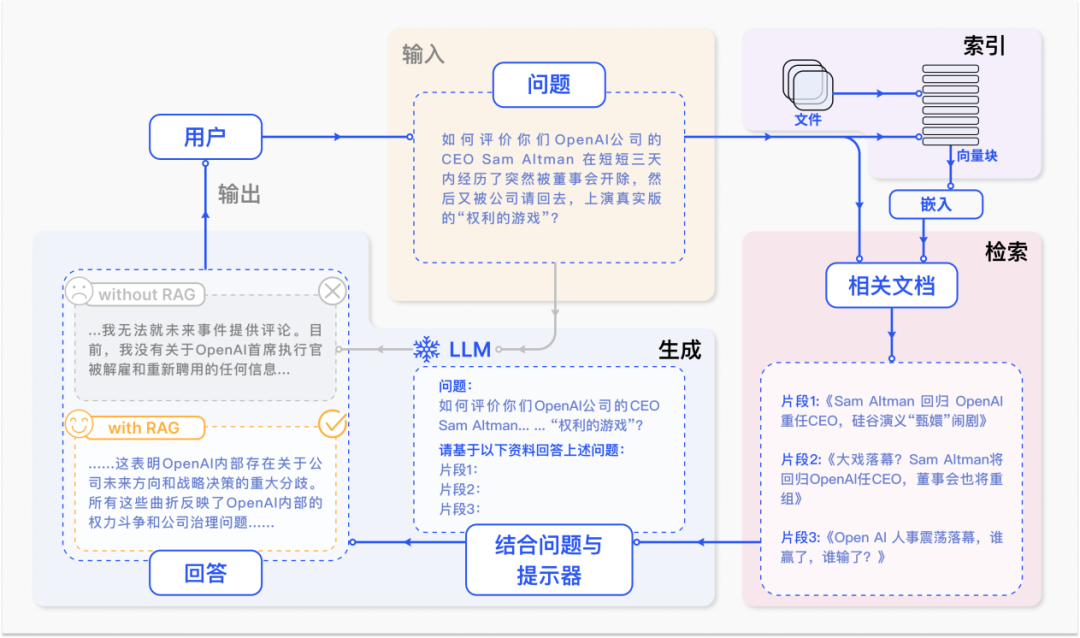
圖 1 RAG 技術(shù)在 QA 問題中的案例
一個(gè)典型的 RAG 案例如圖所示。如果我們向 ChatGPT 詢問 OpenAI CEO Sam Atlman 在短短幾天內(nèi)突然解雇隨后又被復(fù)職的事情。由于受到預(yù)訓(xùn)練數(shù)據(jù)的限制,缺乏對(duì)最近事件的知識(shí),ChatGPT 則表示無(wú)法回答。RAG 則通過從外部知識(shí)庫(kù)檢索最新的文檔摘錄來(lái)解決這一差距。在這個(gè)例子中,它獲取了一系列與詢問相關(guān)的新聞文章。這些文章,連同最初的問題,隨后被合并成一個(gè)豐富的提示,使 ChatGPT 能夠綜合出一個(gè)有根據(jù)的回應(yīng)。
RAG 技術(shù)范式發(fā)展
RAG 的概念首次于 2020 年被提出,隨后進(jìn)入高速發(fā)展。RAG 技術(shù)的演進(jìn)歷程如圖所示,相關(guān)研究進(jìn)展可以明確地劃分為數(shù)個(gè)關(guān)鍵階段。在早期的預(yù)訓(xùn)練階段,研究的焦點(diǎn)集中在如何通過預(yù)訓(xùn)練模型注入額外的知識(shí),以此增強(qiáng)語(yǔ)言模型的能力。隨著 ChatGPT 的面世,對(duì)于運(yùn)用大型模型進(jìn)行深層次上下文學(xué)習(xí)的興趣激增,這推動(dòng)了 RAG 技術(shù)在研究領(lǐng)域的快速發(fā)展。隨著 LLMs 的潛力被進(jìn)一步開發(fā),旨在提升模型的可控性并滿足不斷演變的需求,RAG 的研究逐漸聚焦于增強(qiáng)推理能力,并且也探索了在微調(diào)過程中的各種改進(jìn)方法。特別是隨著 GPT-4 的發(fā)布,RAG 技術(shù)經(jīng)歷了一次深刻的變革。研究重點(diǎn)開始轉(zhuǎn)移至一種新的融合 RAG 和微調(diào)策略的方法,并且持續(xù)關(guān)注對(duì)預(yù)訓(xùn)練方法的優(yōu)化。
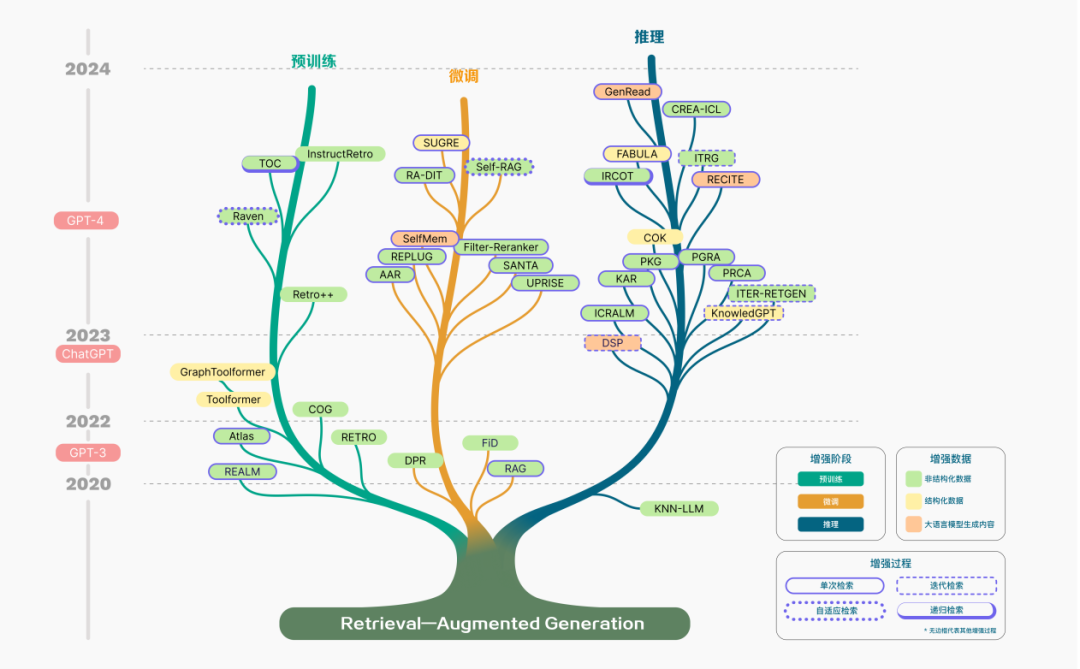
圖 2 RAG 技術(shù)發(fā)展的科技樹
在 RAG 的技術(shù)發(fā)展過程中,我們從技術(shù)范式角度,將其總結(jié)成如下幾個(gè)階段:
樸素(Naive RAG)
前文案例中展示了經(jīng)典的 RAG 流程,也被稱為 Naive RAG。主要包括包括三個(gè)基本步驟:
1. 索引 — 將文檔庫(kù)分割成較短的 Chunk,并通過編碼器構(gòu)建向量索引。
2. 檢索 — 根據(jù)問題和 chunks 的相似度檢索相關(guān)文檔片段。
3. 生成 — 以檢索到的上下文為條件,生成問題的回答。
進(jìn)階的 RAG(Advanced RAG)
Naive RAG 在檢索質(zhì)量、響應(yīng)生成質(zhì)量以及增強(qiáng)過程中存在多個(gè)挑戰(zhàn)。Advanced RAG 范式隨后被提出,并在數(shù)據(jù)索引、檢索前和檢索后都進(jìn)行了額外處理。通過更精細(xì)的數(shù)據(jù)清洗、設(shè)計(jì)文檔結(jié)構(gòu)和添加元數(shù)據(jù)等方法提升文本的一致性、準(zhǔn)確性和檢索效率。在檢索前階段則可以使用問題的重寫、路由和擴(kuò)充等方式對(duì)齊問題和文檔塊之間的語(yǔ)義差異。在檢索后階段則可以通過將檢索出來(lái)的文檔庫(kù)進(jìn)行重排序避免 “Lost in the Middle ” 現(xiàn)象的發(fā)生。或是通過上下文篩選與壓縮的方式縮短窗口長(zhǎng)度。
模塊化 RAG(Modular RAG)
隨著 RAG 技術(shù)的進(jìn)一步發(fā)展和演變,新的技術(shù)突破了傳統(tǒng)的 Naive RAG 檢索 — 生成框架,基于此我們提出模塊化 RAG 的概念。在結(jié)構(gòu)上它更加自由的和靈活,引入了更多的具體功能模塊,例如查詢搜索引擎、融合多個(gè)回答。技術(shù)上將檢索與微調(diào)、強(qiáng)化學(xué)習(xí)等技術(shù)融合。流程上也對(duì) RAG 模塊之間進(jìn)行設(shè)計(jì)和編排,出現(xiàn)了多種的 RAG 模式。然而,模塊化 RAG 并不是突然出現(xiàn)的,三個(gè)范式之間是繼承與發(fā)展的關(guān)系。Advanced RAG 是 Modular RAG 的一種特例形式,而 Naive RAG 則是 Advanced RAG 的一種特例。
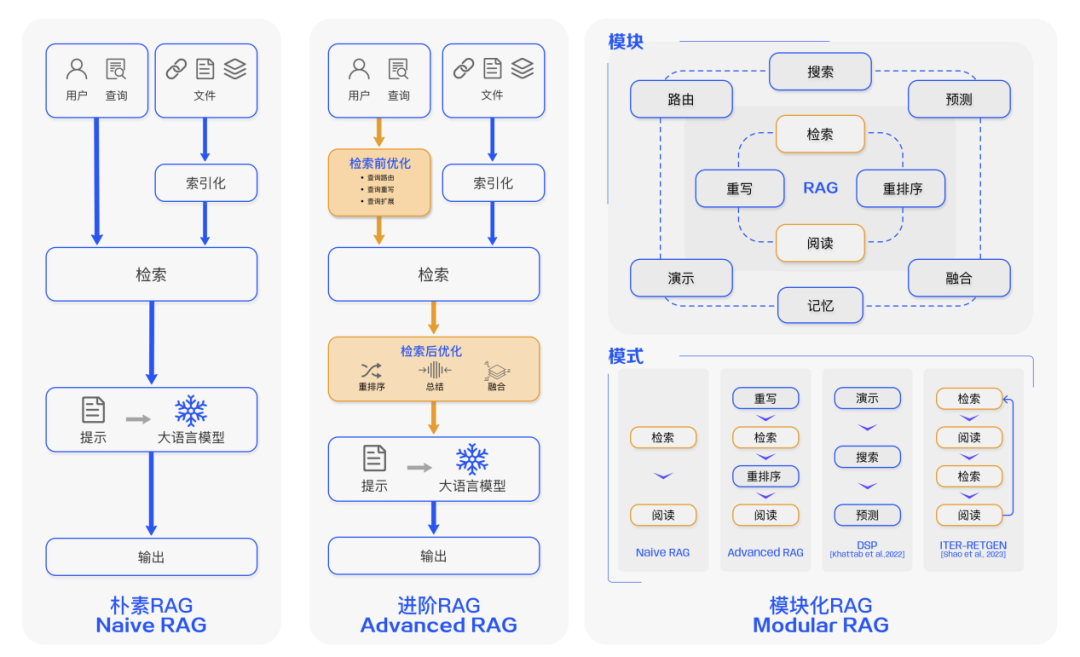
圖 3 RAG 范式對(duì)比圖
如何進(jìn)行檢索增強(qiáng)?
RAG 系統(tǒng)中主要包含三個(gè)核心部分,分別是 “檢索”,“增強(qiáng)” 和 “生成”。正好也對(duì)應(yīng)的 RAG 中的三個(gè)首字母。想要構(gòu)建一個(gè)好的 RAG 系統(tǒng),增強(qiáng)部分是核心,則需要考慮三個(gè)關(guān)鍵問題:檢索什么?什么時(shí)候檢索?怎么用檢索的內(nèi)容?
檢索增強(qiáng)的階段:在預(yù)訓(xùn)練、微調(diào)和推理三個(gè)階段中都可以進(jìn)行檢索增強(qiáng),這決定了外部知識(shí)參數(shù)化程度的高低,對(duì)應(yīng)所需要的計(jì)算資源也不同。
檢索增強(qiáng)的數(shù)據(jù)源:增強(qiáng)可以采用多種形式的數(shù)據(jù),包括非結(jié)構(gòu)化的文本數(shù)據(jù),如文本段落、短語(yǔ)或單個(gè)詞匯。此外,也可以利用結(jié)構(gòu)化數(shù)據(jù),比如帶有索引的文檔、三元組數(shù)據(jù)或子圖。另一種途徑是不依賴外部信息源,而是充分發(fā)揮 LLMs 的內(nèi)在能力,從模型自身生成的內(nèi)容中檢索。
檢索增強(qiáng)的過程:最初的檢索是一次性過程,在 RAG 發(fā)展過程中逐漸出現(xiàn)了迭代檢索、遞歸檢索以及交由 LLMs 自行判斷檢索時(shí)刻的自適應(yīng)檢索方法。
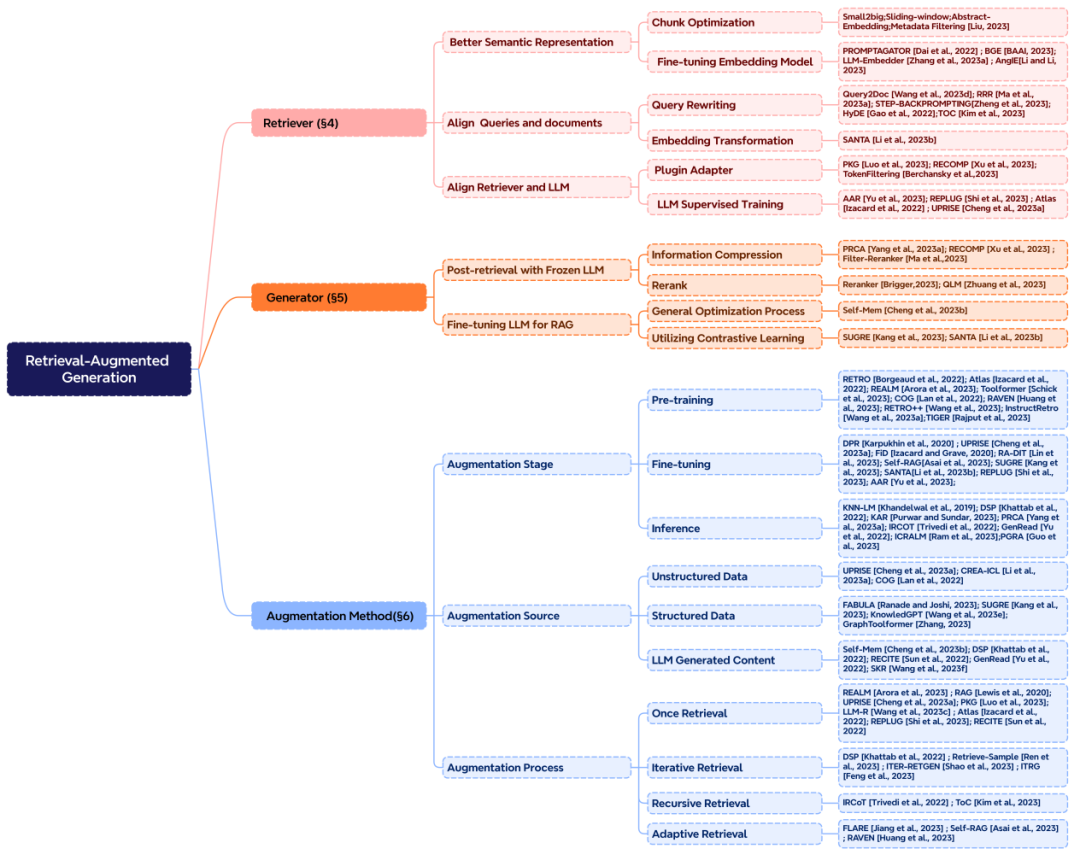
圖 4 RAG 核心組件的分類體系
RAG 和微調(diào)應(yīng)該如何選擇?
除了 RAG,LLMs 主要優(yōu)化手段還包括了提示工程 (Prompt Engineering)、微調(diào) (Fine-tuning,F(xiàn)T)。他們都有自己獨(dú)特的特點(diǎn)。根據(jù)對(duì)外部知識(shí)的依賴性和模型調(diào)整要求上的不同,各自有適合的場(chǎng)景。

RAG 就像給模型一本教科書,用于定制的信息檢索,非常適合特定的查詢。另一方面,F(xiàn)T 就像一個(gè)學(xué)生隨著時(shí)間的推移內(nèi)化知識(shí),更適合模仿特定的結(jié)構(gòu)、風(fēng)格或格式。FT 可以通過增強(qiáng)基礎(chǔ)模型知識(shí)、調(diào)整輸出和教授復(fù)雜指令來(lái)提高模型的性能和效率。然而,它不那么擅長(zhǎng)整合新知識(shí)或快速迭代新的用例。RAG 和 FT,并不是相互排斥的,它們可以是互補(bǔ)的,聯(lián)合使用可能會(huì)產(chǎn)生最佳性能。
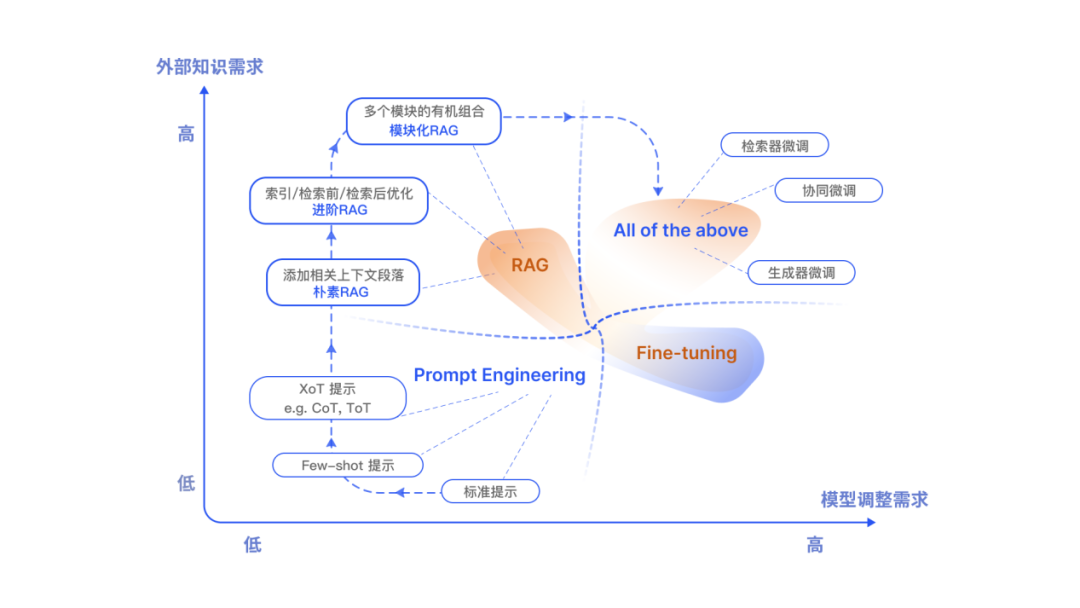
圖 5 RAG 與其他大模型微調(diào)技術(shù)對(duì)比
如何評(píng)價(jià) RAG?
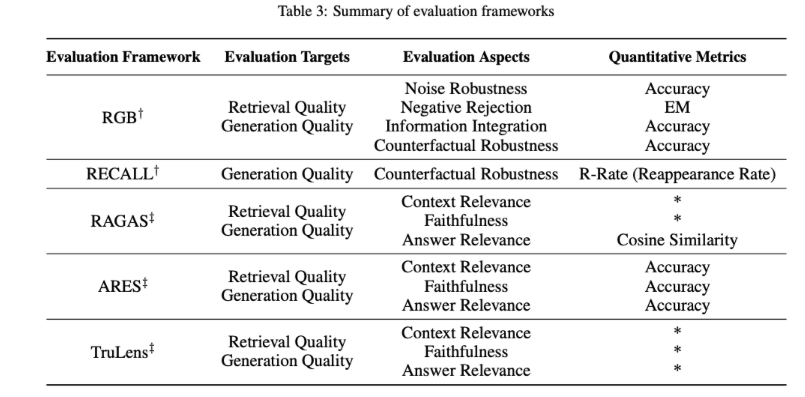
RAG 的評(píng)估方法多樣,主要包括三個(gè)質(zhì)量評(píng)分:上下文相關(guān)性、答案忠實(shí)性和答案相關(guān)性。此外,評(píng)估還涉及四個(gè)關(guān)鍵能力:噪聲魯棒性、拒答能力、信息整合和反事實(shí)魯棒性。這些評(píng)估維度結(jié)合了傳統(tǒng)量化指標(biāo)和針對(duì) RAG 特性的專門評(píng)估標(biāo)準(zhǔn),盡管這些標(biāo)準(zhǔn)尚未統(tǒng)一。
在評(píng)估框架方面,存在如 RGB 和 RECALL 這樣的基準(zhǔn)測(cè)試,以及 RAGAS、ARES 和 TruLens 等自動(dòng)化評(píng)估工具,它們有助于全面衡量 RAG 模型的表現(xiàn)。表中匯總了如何將傳統(tǒng)量化指標(biāo)應(yīng)用于 RAG 評(píng)估以及各種 RAG 評(píng)估框架的評(píng)估內(nèi)容,包括評(píng)估的對(duì)象、維度和指標(biāo),為深入理解 RAG 模型的性能和潛在應(yīng)用提供了寶貴信息。

未來(lái) RAG 還有哪些發(fā)展前景?
RAG 的發(fā)展方興未艾,還有哪些問題值得進(jìn)一步去研究?我們從三個(gè)方面進(jìn)行展望:
1.RAG 的垂直優(yōu)化
垂直優(yōu)化旨在進(jìn)一步解決 RAG 當(dāng)前面臨的挑戰(zhàn);
長(zhǎng)下文長(zhǎng)度。檢索內(nèi)容過多,超過窗口限制怎么辦 ?如果 LLMs 的上下文窗口不再受限制,RAG 應(yīng)該如何改進(jìn)?
魯棒性。檢索到錯(cuò)誤內(nèi)容怎么處理?怎么對(duì)檢索出來(lái)內(nèi)容進(jìn)行過濾和驗(yàn)證?怎么提高模型抗毒、抗噪聲的能力。
與微調(diào)協(xié)同。如何同時(shí)發(fā)揮 RAG 和 FT 的效果,兩者怎么協(xié)同,怎么組織,是串行、交替還是端到端?
Scaling-Law:RAG 模型是否滿足 Scaling Law?RAG 是否會(huì),或是在什么場(chǎng)景下會(huì)出現(xiàn) Inverse Scaling Law 的現(xiàn)象?
LLM 的角色。LLMs 可以用于檢索(用 LLMs 的生成代替檢索或檢索 LLMs 記憶)、用于生成、用于評(píng)估。如何進(jìn)一步挖掘 LLMs 在 RAG 中的潛力?
工程實(shí)踐。如何降低超大規(guī)模語(yǔ)料的檢索時(shí)延?如何保證檢索出來(lái)內(nèi)容不被大模型泄露?
2.RAG 的多模態(tài)的拓展
如何將 RAG 不斷發(fā)展的技術(shù)和思想拓展到圖片、音頻、視頻或代碼等其他模態(tài)的數(shù)據(jù)中?一方面可以增強(qiáng)單一模態(tài)的任務(wù),另一方面可以通過 RAG 的思想將多模態(tài)進(jìn)行融合。
3.RAG 的生態(tài)
RAG 的應(yīng)用已經(jīng)不僅僅局限于問答系統(tǒng),其影響力正在擴(kuò)展到更多領(lǐng)域。現(xiàn)在,推薦系統(tǒng)、信息抽取和報(bào)告生成等多種任務(wù)都開始受益于 RAG 技術(shù)的應(yīng)用。與此同時(shí),RAG 技術(shù)棧也在井噴。除了已知的 Langchain 和 LlamaIndex 等工具,市場(chǎng)上涌現(xiàn)出更多針對(duì)性的 RAG 工具,例如:用途定制化,滿足更加聚焦場(chǎng)景的需求;使用簡(jiǎn)易化,進(jìn)一步降低上手門檻的;功能專業(yè)化,逐漸面向生產(chǎn)環(huán)境。
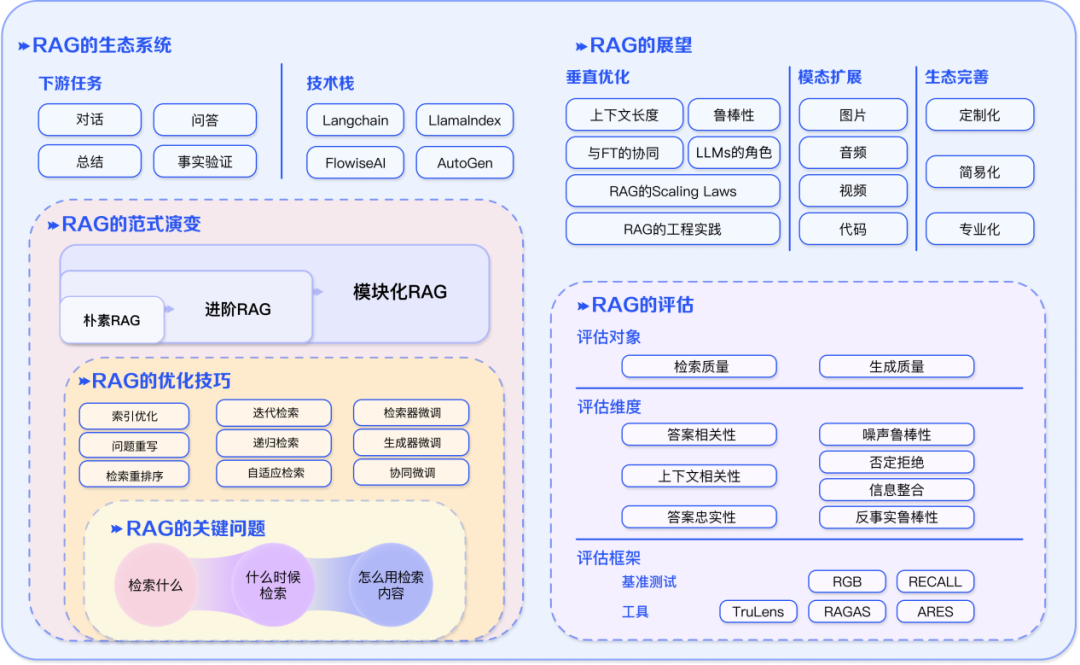
圖 6 RAG 的生態(tài)系統(tǒng)概覽
-
人工智能
+關(guān)注
關(guān)注
1791文章
47279瀏覽量
238499 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
524瀏覽量
10277 -
大模型
+關(guān)注
關(guān)注
2文章
2450瀏覽量
2707
原文標(biāo)題:專補(bǔ)大模型短板的RAG有哪些新進(jìn)展?這篇綜述講明白了
文章出處:【微信號(hào):TheBigData1024,微信公眾號(hào):人工智能與大數(shù)據(jù)技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論