 一文讀懂:圖像特征檢測算法!
一文讀懂:圖像特征檢測算法!
1. 局部特征點
圖像特征提取是圖像分析與圖像識別的前提,它是將高維的圖像數據進行簡化表達最有效的方式,從一幅圖像的M × N × 3的數據矩陣中,我們看不出任何信息,所以我們必須根據這些數據提取出圖像中的關鍵信息,一些基本元件以及它們的關系。
局部特征點是圖像特征的局部表達,它只能反正圖像上具有的局部特殊性,所以它只適合于對圖像進行匹配,檢索等應用。對于圖像理解則不太適合。而后者更關心一些全局特征,如顏色分布,紋理特征,主要物體的形狀等。全局特征容易受到環境的干擾,光照,旋轉,噪聲等不利因素都會影響全局特征。相比而言,局部特征點,往往對應著圖像中的一些線條交叉,明暗變化的結構中,受到的干擾也少。
而斑點與角點是兩類局部特征點。斑點通常是指與周圍有著顏色和灰度差別的區域,如草原上的一棵樹或一棟房子。它是一個區域,所以它比角點的噪能力要強,穩定性要好。而角點則是圖像中一邊物體的拐角或者線條之間的交叉部分。
2. 斑點檢測原理與舉例 2.1 LoG與DoH
斑點檢測的方法主要包括利用高斯拉普拉斯算子檢測的方法(LOG),以及利用像素點Hessian矩陣(二階微分)及其行列式值的方法(DOH)。
LoG的方法已經在斑點檢測這入篇文章里作了詳細的描述。因為二維高斯函數的拉普拉斯核很像一個斑點,所以可以利用卷積來求出圖像中的斑點狀的結構。
DoH方法就是利用圖像點二階微分Hessian矩陣:
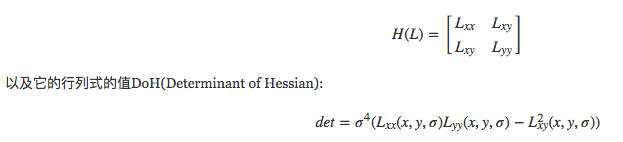
Hessian矩陣行列式的值,同樣也反映了圖像局部的結構信息。與LoG相比,DoH對圖像中的細長結構的斑點有較好的抑制作用。
無論是LoG還是DoH,它們對圖像中的斑點進行檢測,其步驟都可以分為以下兩步:
1)使用不同的σ生成模板,并對圖像進行卷積運算;
2)在圖像的位置空間與尺度空間中搜索LoG與DoH響應的峰值。
2.2 SIFT
詳細的算法描述參考:SIFT定位算法關鍵步驟的說明
2004年,Lowe提高了高效的尺度不變特征變換算法(SIFT),利用原始圖像與高斯核的卷積來建立尺度空間,并在高斯差分空間金字塔上提取出尺度不變性的特征點。該算法具有一定的仿射不變性,視角不變性,旋轉不變性和光照不變性,所以在圖像特征提高方面得到了最廣泛的應用。
該算法大概可以歸納為三步:1)高斯差分金字塔的構建;2)特征點的搜索;3)特征描述。
在第一步中,它用組與層的結構構建了一個具有線性關系的金字塔結構,讓我們可以在連續的高斯核尺度上查找特征點。它比LoG高明的地方在于,它用一階高斯差分來近似高斯的拉普拉斯核,大大減少了運算量。
在第二步的特征點搜索中,主要的關鍵步驟是極值點的插值,因為在離散的空間中,局部極值點可能并不是真正意義上的極值點,真正的極植點可以落在了離散點的縫隙中。所以要對這些縫隙位置進行插值,然后再求極值點的坐標位置。
第二步中另一關鍵環節是刪除邊緣效應的點,因為只忽略那些DoG響應不夠的點是不夠的,DoG的值會受到邊緣的影響,那些邊緣上的點,雖然不是斑點,但是它的DoG響應也很強。所以我們要把這部分點刪除。我們利用橫跨邊緣的地方,在沿邊緣方向與垂直邊緣方向表現出極大與極小的主曲率這一特性。所以通過計算特征點處主曲率的比值即可以區分其是否在邊緣上。這一點在理解上可以參見Harris角點的求法。
最后一步,即為特征點的特征描述。特征點的方向的求法是需要對特征點鄰域內的點的梯度方向進行直方圖統計,選取直方圖中比重最大的方向為特征點的主方向,還可以選擇一個輔方向。在計算特征矢量時,需要對局部圖像進行沿主方向旋轉,然后再進鄰域內的梯度直方圖統計(4x4x8)。
2.3 SURF
詳細的算法描述參考:1. SURF算法與源碼分析、上 2. SURF算法與源碼分析、下
2006年,Bay和Ess等人基于SIFT算法的思路,提出了加速魯棒特征(SURF),該算法主要針對于SIFT算法速度太慢,計算量大的缺點,使用了近似Harr小波方法來提取特征點,這種方法就是基于Hessian行列式(DoH)的斑點特征檢測方法。通過在不同的尺度上利用積分圖像可以有效地計算出近似Harr小波值,簡化了二階微分模板的構建,搞高了尺度空間的特征檢測的效率。
SURF算法在積分圖像上使用了盒子濾波器對二階微分模板進行了簡化,從而構建了Hessian矩陣元素值,進而縮短了特征提取的時間,提高了效率。其中SURF算法在每個尺度上對每個像素點進行檢測,其近似構建的Hessian矩陣及其行列式的值分另為:
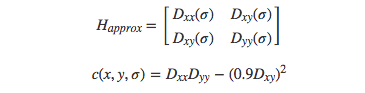
其中D x x , D x y和D y y為利用盒子濾波器獲得的近似卷積值。如果c ( x , y , σ )大于設置的門限值,則判定該像素點為關鍵字。然后與SIFT算法近似,在以關鍵點為中心的3 × 3 × 3像素鄰域內進行非極大值抑制,最后通過對斑點特征進行插值運算,完成了SURF特征點的精確定位。
而SURF特征點的描述,則也是充分利用了積分圖,用兩個方向上的Harr小波模板來計算梯度,然后用一個扇形對鄰域內點的梯度方向進行統計,求得特征點的主方向。
3. 角點檢測的原理與舉例
角點檢測的方法也是極多的,其中具有代表性的算法是Harris算法與FAST算法。
這兩個算法我都有專門寫過博文來描述其算法原理。Harris角點和FAST特征點檢測。
3.1 Harris角點特征提取
Harris角點檢測是一種基于圖像灰度的一階導數矩陣檢測方法。檢測器的主要思想是局部自相似性/自相關性,即在某個局部窗口內圖像塊與在各個方向微小移動后的窗口內圖像塊的相似性。
在像素點的鄰域內,導數矩陣描述了數據信號的變化情況。假設在像素點鄰域內任意方向上移動塊區域,若強度發生了劇烈變化,則變化處的像素點為角點。定義2 × 2的Harris矩陣為:
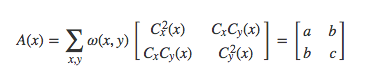
其中,C x和C y分別為點x = ( x , y )在xx和y方向上的強度信息的一階導數,ω ( x , y )為對應位置的權重。通過計算Harris矩陣的角點響應值D來判斷是否為角點。其計算公式為:
其中,det和trace為行列式和跡的操作符,m是取值為0.04~0.06的常數。當角點響應值大于設置的門限,且為該點鄰域內的局部最大值時,則把該點當作角點。
3.2 FAST角點特征提取
基于加速分割測試的FAST算法可以快速地提取出角點特征。該算法判斷一個候選點p是否為角點,依據的是在一個像素點p為圓心,半徑為3個像素的離散化Bresenllam圓周上,在給定閾值t的條件下,如果在圓周上有n個連續的像素灰度值大于I ( p ) + t或小于I ( p ) ? t。
針對于上面的定義,我們可以用快速的方法來完成檢測,而不用把圓周上的所有點都比較一遍。首先比較上下左右四個點的像素值關系,至少要有3個點的像素灰度值大于I ( p ) + t或小于I ( p ) ? t,則p為候選點,然后再進一步進行完整的判斷。
為了加快算法的檢測速度,可以使用機器學習ID3貪心算法來構建決策樹。這里需要說明的是,在2010年Elmar和Gregory等人提出了自適應通用加速分割檢測(AGAST)算法,通過把FAST算法中ID3決策樹改造為二叉樹,并能夠根據當前處理的圖像信息動態且高效地分配決策樹,提高了算法的運算速度。
4. 二進制字符串特征描述子
可以注意到在兩種角點檢測算法里,我們并沒有像SIFT或SURF那樣提到特征點的描述問題。事實上,特征點一旦檢測出來,無論是斑點還是角點描述方法都是一樣的,可以選用你認為最有效的特征描述子。
特征描述是實現圖像匹配與圖像搜索必不可少的步驟。到目前為止,人們研究了各種各樣的特征描述子,比較有代表性的就是浮點型特征描述子和二進帽字符串特征描述子。
像SIFT與SURF算法里的,用梯度統計直方圖來描述的描述子都屬于浮點型特征描述子。但它們計算起來,算法復雜,效率較低,所以后來就出現了許多新型的特征描述算法,如BRIEF。后來很多二進制串描述子ORB,BRISK,FREAK等都是在它上面的基礎上的改進。
4.1 BRIEF算法
BRJEF算法的主要思想是:在特征點周圍鄰域內選取若干個像素點對,通過對這些點對的灰度值比較,將比較的結果組合成一個二進制串字符串用來描述特征點。最后,使用漢明距離來計算在特征描述子是否匹配。
BRIEF算法的詳細描述可以參考:BRIEF特征描述子
4.2 BRISK算法
BRISK算法在特征點檢測部分沒有選用FAST特征點檢測,而是選用了穩定性更強的AGAST算法。在特征描述子的構建中,BRISK算法通過利用簡單的像素灰度值比較,進而得到一個級聯的二進制比特串來描述每個特征點,這一點上原理與BRIEF是一致的。BRISK算法里采用了鄰域采樣模式,即以特征點為圓心,構建多個不同半徑的離散化Bresenham同心圓,然后再每一個同心圓上獲得具有相同間距的N個采樣點。
由于這種鄰域采樣模式在采樣時會產生圖像灰度混疊的影響,所以BRISK算法首先對圖像進行了高斯平滑圖像。并且使用的高斯函數標準差σ i與各自同心圓上點間距成正比。
假設在( N 2 )個采樣點中任意選取一對采樣點( p i , p j ),其平滑后的灰度值分別為I ( p i , σ i )和I ( p j , σ j ),則兩點間的局部梯度為:
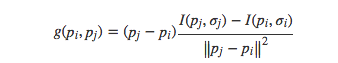
假設把所有采樣點對構成的集合記為A,則
那么短距離采樣點對構成的集合S以及長距離采樣點構成的集合L分別為:
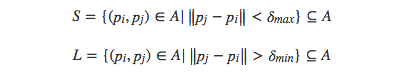
其中,通常設置距離閾值為
δ m a x = 9.75 δ , δ m i n = 13.67 δ,其中δ為特征點的尺度。
由于長距離采樣點對含有更多的特征點角度信息,且局部梯度相互抵消,所以可以在集合L中計算出特征點的特征模式方向為:
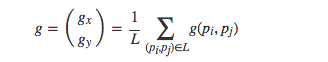
然后將采樣模式圍繞特征點旋轉角度α = a r c t a n 2 ( g y , g x ),進而特征描述子具有了旋轉不變性。
最后,在旋轉后的短距離采樣點集合S內,對所有的特征點對( P i α , p j α )行像素灰度值比較,最終形成512比特的二進制字符串描述子。
4.3 ORB算法
ORB算法使用FAST進行特征點檢測,然后用BREIF進行特征點的特征描述,但是我們知道BRIEF并沒有特征點方向的概念,所以ORB在BRIEF基礎上引入了方向的計算方法,并在點對的挑選上使用貪婪搜索算法,挑出了一些區分性強的點對用來描述二進制串。ORB算法的詳細描述可以參考:ORB特征點檢測。
4.4 FREAK算法
Fast Retina KeyPoint,即快速視網膜關鍵點。
根據視網膜原理進行點對采樣,中間密集一些,離中心越遠越稀疏。并且由粗到精構建描述子,窮舉貪婪搜索找相關性小的。42個感受野,一千對點的組合,找前512個即可。這512個分成4組,前128對相關性更小,可以代表粗的信息,后面越來越精。匹配的時候可以先看前16bytes,即代表精信息的部分,如果距離小于某個閾值,再繼續,否則就不用往下看了。
5. 應用之圖像匹配
圖像匹配的研究目標是精確判斷兩幅圖像之間的相似性。圖像之間的相似性的定義又隨著不同的應用需求而改變。例如,在物體檢索系統中(找出含有亞伯拉罕·林肯的臉的圖像),我們認為同一物體的不同圖像是相近的。而在物體類別檢索系統中(找出含有人臉的圖像),我們則認為相同類的物體之間是相近的。
這里局部特征點的應用主要表現在第一種相似性上,也就是說我們需要設計某種圖像匹配算法來判斷兩幅圖像是否是對同一物體或場景所成的圖像。理想的圖像匹配算法應該認為兩幅同一物體的圖像之間相似度很高,而兩幅不同物體的圖像之間相似度很低,如下圖所示。
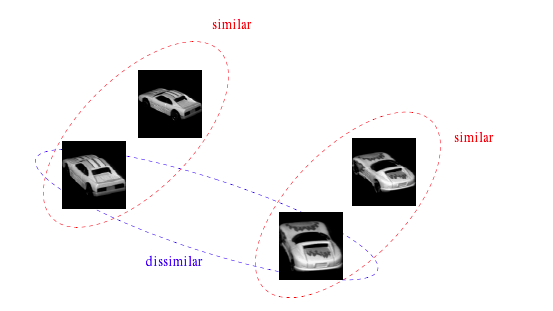
由于成像時光照,環境,角度的不一致,我們獲取的同一物體的圖像是存在差異的,如同上圖中的兩輛小車的圖像一樣,角度不同,成像就不同。我們直接利用圖像進行比較是無法進行判斷小車是否為同一類的。必須進行特征點的提取,再對特征點進行匹配。
圖像會存在哪些變換呢?一般來說包括了光照變化與幾何變化,光照變化表現是圖像上是全局或局部顏色的變化,而幾何變化種類就比較多了,可以是平移、旋轉、尺度、仿射、投影變換等等。所以我們在研究局部特征點時才要求特征點對這些變化具有穩定性,同時要有很強的獨特性,可以讓圖像與其他類的圖像區分性強,即類內距離小而類間距離大。
-
算法
+關注
關注
23文章
4612瀏覽量
92891 -
圖像
+關注
關注
2文章
1084瀏覽量
40463 -
數據矩陣
+關注
關注
0文章
2瀏覽量
1815
原文標題:一文讀懂:圖像特征檢測算法!
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
人臉檢測算法及新的快速算法
分享一款高速人臉檢測算法
基于YOLOX目標檢測算法的改進
基于改進邊緣檢測算子的圖像特征點提取算法
一種改進的結合前景背景特征的顯著性檢測算法
手指靜脈圖像魯棒邊緣檢測算法
如何實現一種深度特征導向顯著性檢測算法

基于高斯金字塔圖像的改進Harris特征點檢測算法







 工商網監
工商網監
評論