 RDMA RNIC虛擬化方案
RDMA RNIC虛擬化方案
作者簡介:KIKI,中國科學院計算技術研究所在讀博士生
01引言
遠程直接內存訪問(Remote Direct Memory Access,RDMA)技術允許應用程序繞過操作系統內核,以零拷貝的方式和遠程計算機進行網絡通信,具有低延遲和高帶寬的優勢。RDMA協議主要包括Inifiband、RoCE以及iWARP。實現RDMA協議的I/O設備被稱為RNIC。主流云服務提供商已經開始廣泛部署RNIC,例如亞馬遜云推出的彈性網絡適配器(Elastic Network Adapter,ENA)[1]。同時,云服務提供商通過硬件虛擬化技術對物理資源進行池化管理,提升資源效率。
硬件虛擬化(Virtualization)技術是一種計算機資源管理技術,在各類計算機硬件(例如CPU、內存、存儲、網絡設備)上創建一個抽象層,將單個物理硬件資源模擬為多個虛擬資源。本文討論針對RDMA網卡(RDMA Network Interface Controller,RNIC)的虛擬化技術,即將一個RNIC模擬為多個RNIC供虛擬機(Virtual Machine,VM)使用。根據實現方式,I/O虛擬化可以分為直通,全虛擬化、半虛擬化以及基于硬件輔助的全虛擬化。
RNIC虛擬化方案既要維持RDMA的高性能優勢,又要滿足云環境的部署要求。RDMA網絡相對于傳統TCP網絡的性能優勢包括更低的延遲、更高的帶寬以及更低的CPU占用,因此針對RNIC的虛擬化方案首先應該盡可能降低虛擬化引入的RDMA性能開銷。同時,云計算對虛擬實例之間的隔離性,虛擬實例的可遷移性以及虛擬實例的可管控性都有比較高的要求。本文針對虛擬機和容器兩種實體的典型RDMA虛擬化技術進行了調研,并且對相關領域的研究內容進行了總結和展望。
02背景知識介紹
RDMA關鍵特征簡介
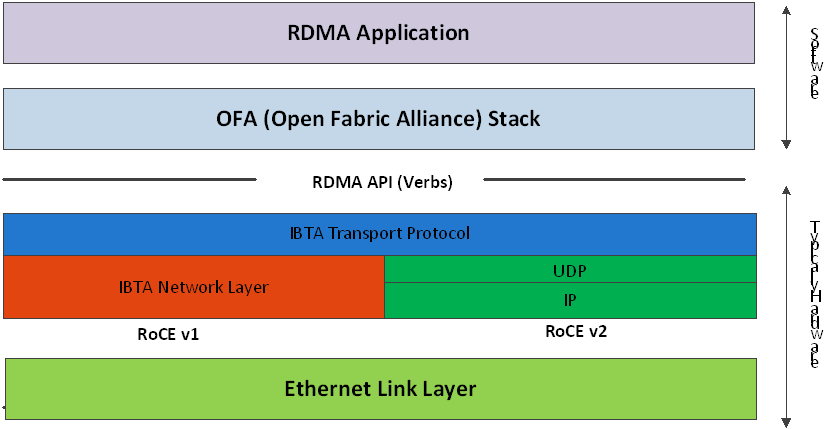
如Figure 1所示,RDMA技術采用了控制路徑(Control path)-數據路徑(Data path)分離的思想。RDMA的控制面包括設備管理,Queue Pair、Completion Queue、Memory Region等資源的管理,以及異常處理等功能。RDMA的數據面包括請求的發起以及請求的完成確認。RDMA用戶態的庫向應用提供統一的、標準的動詞(Verbs)接口。Verbs接口定義了控制面和數據面的具體內容,因此Verbs接口也可以進一步分為控制Verbs和數據Verbs。控制Verbs都會經過內核態RNIC驅動的轉發到達RNIC內部的控制Verbs處理單元。控制Verbs和內核驅動交互的過程涉及系統調用和上下文切換,被認為是慢路徑。數據Verbs通過內存映射I/O的方式直接和RNIC內部的數據Verbs處理單元交互。數據Verbs直接訪問RNIC的過程被認為是快路徑。RDMA的數據傳輸性能取決于數據Verbs的實現。
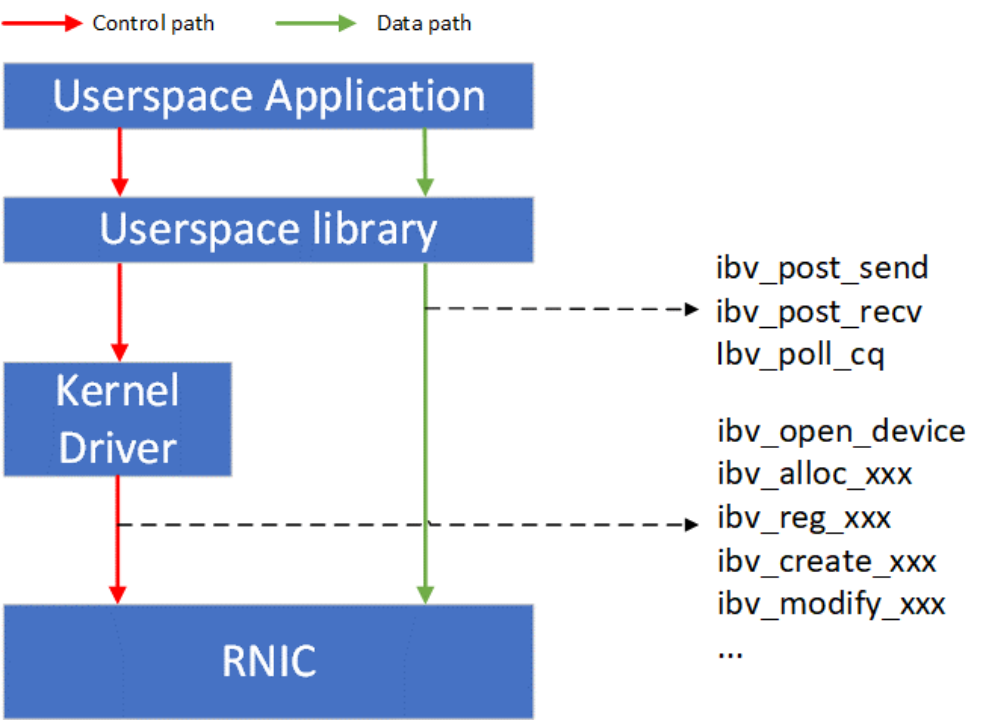
Figure 1 RDMA控制和數據路徑
RDMA數據Verbs的高性能依賴于數據傳輸過程中的零拷貝實現。零拷貝實現要求RNIC具有主動發起PCIe DMA直接讀寫應用緩沖區的能力。應用在RDMA數據傳輸中使用進程虛擬地址,然而PCIe DMA需要總線映射后的DMA地址。RNIC需要主動將應用緩沖區的虛擬地址翻譯為DMA地址。在具體的實現中,RNIC會緩存應用進程頁表的一部分到其管理的內存翻譯表(Memory Translation Table,MTT)。在RDMA虛擬化的實現中,由于Guest OS中映射的DMA地址不一定連續,MTT表中的DMA地址需要由Hypervisor提供。
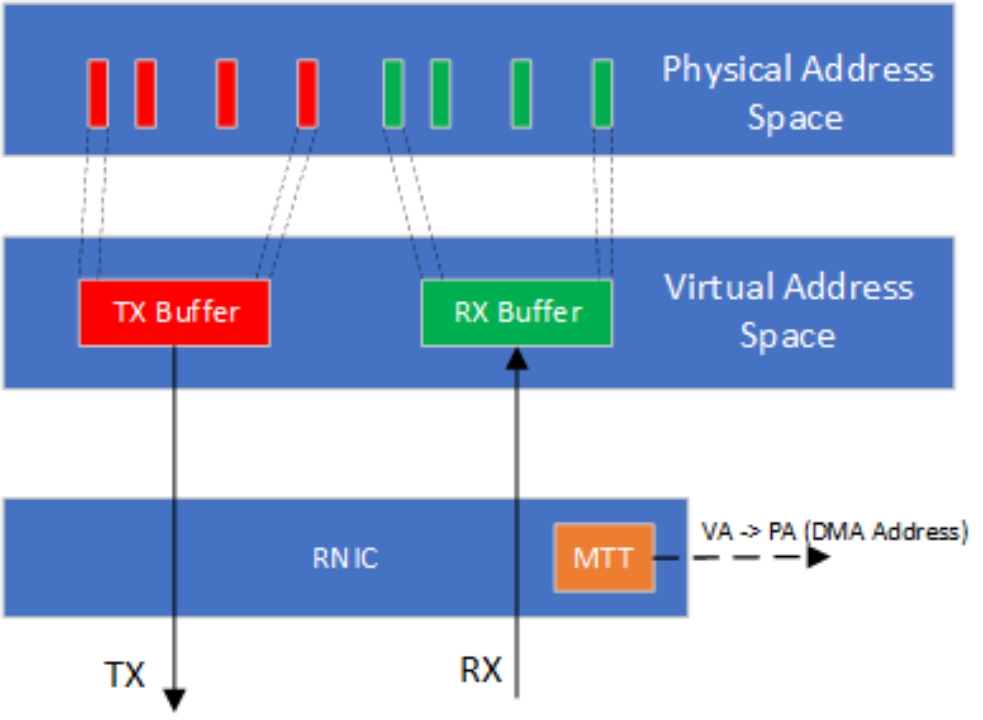
Figure 2 RNIC通過主動的內存翻譯實現零拷貝傳輸
虛擬機和容器簡介
虛擬化技術使軟件應用程序能夠運行在虛擬硬件(通過虛擬機和虛擬機監控程序(Virtual Machine Monitor,VMM)實現虛擬化)或虛擬操作系統(通過容器(Container)實現虛擬化)上。虛擬機(VM),也稱為客戶機,是一個軟件模擬的硬件平臺,為客戶操作系統(Guest OS)提供虛擬操作環境。VMM也稱為Hypervisor,是一個運行在實際主機(Host)的軟件程序,監督虛擬機上客戶操作系統的執行。Hypervisor包括Type 1和Type 2兩類,其中Type 1 Hypervisor直接控制Host的硬件,而Type 2 Hypervisor通過Host操作系統間接控制硬件。目前主流的Hypervisor實現多屬于Type2,包括KVM,VMware以及VirtualBox等。容器是一個虛擬運行時環境集合,包含執行目標軟件應用所需的所有資源(例如文件系統、CPU、內存、進程空間以及網絡接口等)。
容器可以看作是對操作系統的虛擬化(也有觀點認為容器不能歸類到虛擬化技術),并不模擬底層硬件。相對于虛擬機,容器更加輕量化,啟動速度也更加快。容器引擎是運行容器的基礎環境,主流實現包括Docker以及LXC等。在容器規模比較大的情況,需要使用諸如Docker Swarm或Kubernetes(K8s)等容器編排(Containter Orchestration)工具管理容器的部署。
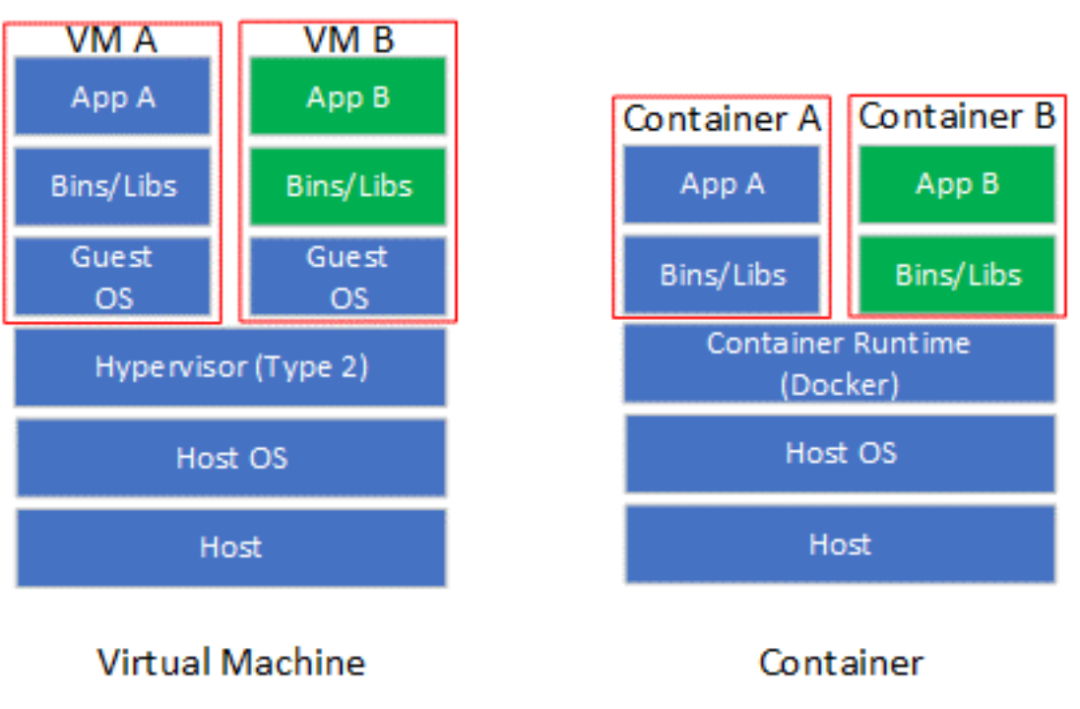
Figure 3 虛擬機和容器對比
03針對虛擬機的RDMA虛擬化技術
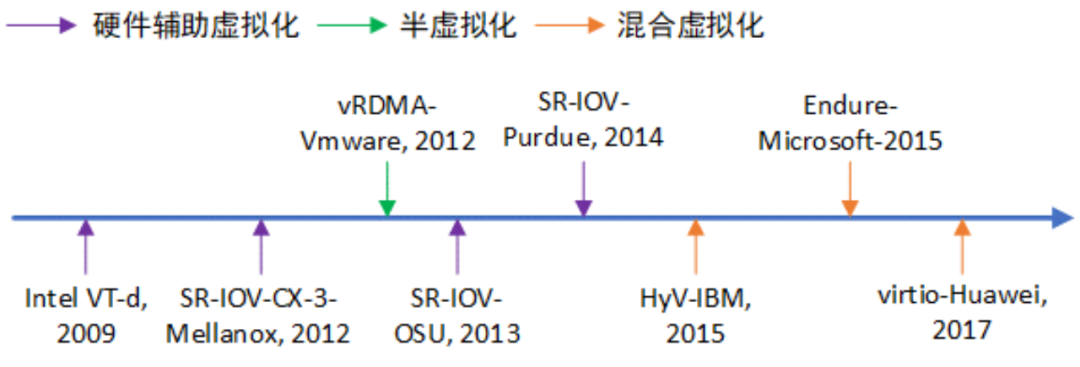
Figure 4 RDMA虛擬化技術發展歷程
最基礎的RNIC虛擬化方案是使用Hypervisor作為虛擬機和RNIC的唯一中間層,RDMA全部的數據和控制路徑的全部請求都被Hypervisor截獲、翻譯以及執行,即全虛擬化I/O技術。如Figure 5所示,Hypervisor中的RDMA Proxy處理VM1和VM2的控制路徑和數據路徑。VM每次執行RDMA相關操作都需要通過VM-Exit將控制權交給VMM,VMM處理完后再通過VM-entry重新進入到VM。全虛擬化具有靈活可控的優勢,不需要為VM提供專有驅動,且云計算的各類要求可以在RDMA Proxy中實現。VM Exit/Entry過程涉及從VM到Hypervisor之間的上下文切換,會產生相當大的性能開銷。由于全虛擬化的性能開銷較大,并未在工業界和學術界調查到基于全虛擬化技術的RNIC虛擬化方案。
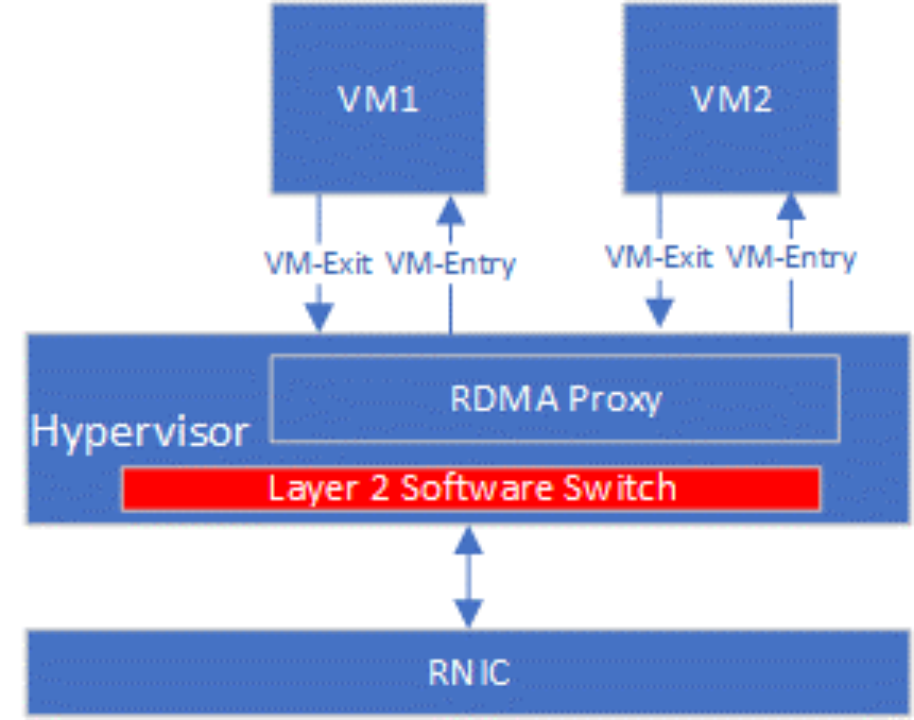
Figure 5 全虛擬化RDMA實現示意
另外一種純軟件實現的虛擬化技術是半虛擬化(Paravirtualization),其由前端驅動和后端驅動共同模擬實現。在客戶機中運行的驅動程序稱之為前端(Frontend),在主機上與前端通信的驅動程序稱之為后端(Backend)。前端發送VM請求給后端,后端驅動處理完這些請求后再返回給前端。相對于全虛擬化,半虛擬化能夠減少VM Exit/Entry次數,性能相對提升。VMware公司提出的vRDMA [2]屬于半虛擬化RDMA方案,其整體架構如Figure 6所示。vRDMA向Guest OS的RDMA應用提供VMCI虛擬設備,libvrdma是VMCI虛擬設備的用戶態驅動,vRDMA Driver是VMCI虛擬設備的用戶態驅動。同時,VRDMA Driver也是半虛擬化框架中的前端驅動,后端驅動是Hypervisor中的vRDMA VMCI Endpoint。vRDMA VMCI Endpoin最終通過RDMA內核Verbs調用RDMA內核態驅動。
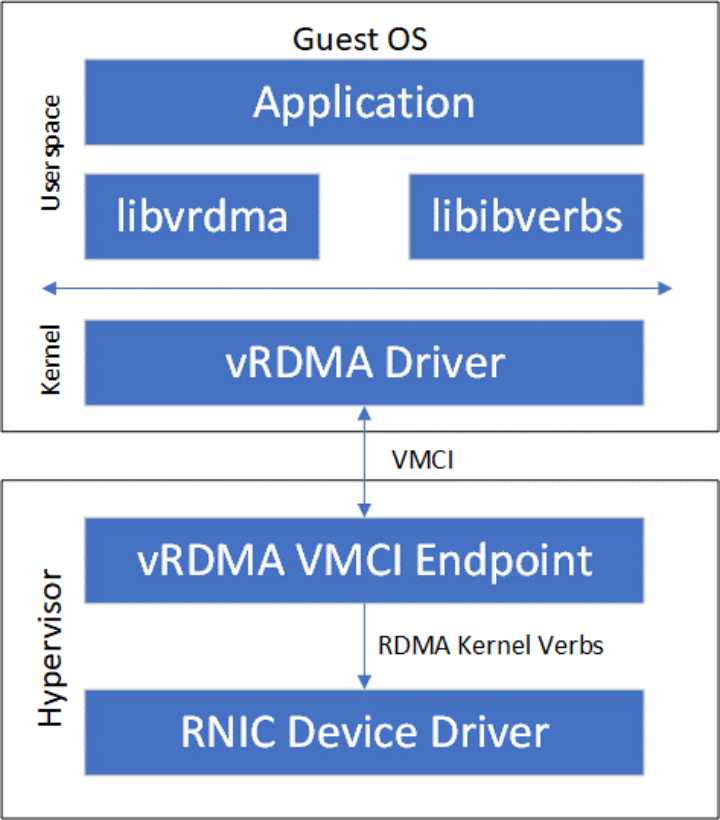
Figure 6 VMvare vRDMA實現架構
硬件輔助虛擬化包括直通和SR-IOV兩種主流方案。RNIC以一個PCIe設備的形式接入到現有系統,因此最基礎的硬件輔助RNIC虛擬化方案是采用Intel VT-D或者AMD Vi技術將RNIC直接綁定到一個虛擬機,這種虛擬化方法也被稱為直通(Passthrough)。直通方式能夠使得虛擬機獨占RNIC,RNIC性能可以實現零損耗。然而一臺主機上會存在多個虛擬機,如果采用直通方式實現RNIC虛擬化,則主機上安裝的RNIC數量需要和主機最大支持虛擬機數量相等。顯然,直通方式的并不具備虛擬機層面的可擴展性。SR-IOV(Single Root Input/Output Virtualization)技術能夠將一個物理PCIe設備模擬成多個虛擬的PCIe設備(基于SR-IOV引入的Virtual Function,VF),專門用于針對VM的網卡虛擬化。根據OSU大學公開的性能評估結果 [3],SR-IOV虛擬化RDMA的小消息延遲相對于非虛擬化RDMA只增加了0.5us~1us,大消息延遲和非虛擬化RDMA無明顯差距。此外,基于SR-IOV的虛擬化RDMA和非虛擬化RDMA的可達帶寬無明顯差距。Purdue大學的Malek等人 [4]提出了針對SR-IOV虛擬化RDMA的參數(例如中斷聚合閾值、共享接收隊列水線)優化方法,進一步減小了SR-IOV虛擬化RDMA和非虛擬化RDMA的性能差距。僅就RDMA虛擬化的性能而言,SR-IOV可以被認為是最優的選擇。然而SR-IOV并不靈活,不能滿足云計算的可遷移性和可管控性要求。例如,Mellanox ConnextX-4/5/6系列RNIC在重新配置SR-IOV的VF數量時需要首先將VF數量清零 [5],清零意味著當前正使用VF的VM需要放棄其對應的虛擬RNIC。假設當前主機RNIC的SR-IOV配置了4個VF,因為業務需求需要從其他主機遷入一個VF,則需要將SR-IOV的VF數量重新配置為8,則當前4個VM都需要放棄其虛擬RNIC。此外,基于SR-IOV的虛擬化方案需要在RDMA網卡內部集成支持虛擬網絡的2層交互模塊(L2 Switch),在將VM從一個主機熱遷移到另外一個主機時需要重新配置L2 Switch,硬件重配置通常被認為是不靈活的。
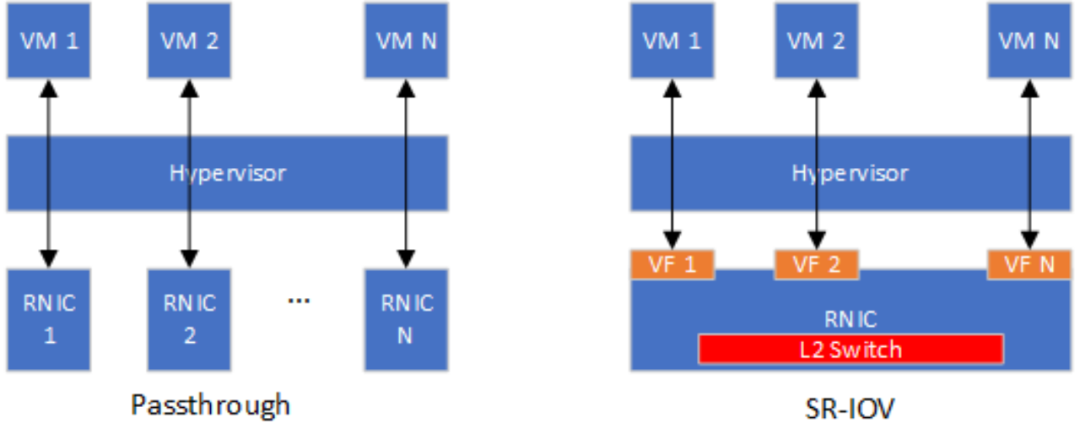
Figure 7 基于Passthrough和SR-IOV虛擬化方案對比
混合虛擬化利用了RDMA設計中的控制-數據路徑分離的特點,對控制路徑使用半虛擬化,對數據路徑采用基于內存映射的硬件直通。IBM研究人員提出的HyV [6]是混合虛擬化的代表案例,相應的論文發表在2015年的VEE會議。在控制路徑上,VM中的前端驅動攔截用戶態驅動的ibv_create_qp, ibv_create_cq等控制Verbs轉發到到Hypervisor中的后端驅動。后端驅動對接受到的控制Verbs調用實現VM層面的隔離、安全以及資源管控等要求后,將控制Verbs轉發給RNIC設備驅動。在后端驅動中,內存映射相關的控制路徑需要實現1)將RNIC提供的隊列門鈴映射到VM進程的地址空間;2)QP等資源占用的內存在后端驅動的地址空間分配,需要映射到VM進程的地址空間;3)VM進程數據緩沖區對應的Guest VA到Host PA映射需要同步到RNIC。在數據路徑上,應用通過映射后的門鈴和直接和RNIC交互,實現post_send,post_recv以及poll_cq。在具體實現上,HyV使用成熟的Virtio框架實現了控制路徑的前后端驅動。實驗評估顯示HyV的性能和SR-IOV相近,在資源管理的靈活性上接近半虛擬化。微軟提出的Endure(Enlighteded Network Direct On Azure) [7]以及華為提出的virtio-RDMA [8]都沿用了類似HyV的設計。在具體的實現上,Endure采用自定義的VMBus實現控制路徑Guest-Host交互,而不是沿用virtio。Virtio-RDMA將HyV的前端驅動重新實現在Guest OS的用戶態,減少上下文切換的次數。
以HyV為代表的RDMA混合虛擬化提出后,通過半虛擬化實現控制面和通過內存映射方式實現數據面直通硬件的方案已經成為共識。如何改造繼續改造RDMA虛擬化方案,使得其更好地適應云計算特定的需求成為新的研究關注的。例如華為在SGICOMM 2021提出的MasQ [9],進一步在虛擬化控制面強化了租戶隔離、安全隔離以及服務質量的設計,使得虛擬化RDMA能夠在VPC(Virtual Private Cloud)網絡部署。
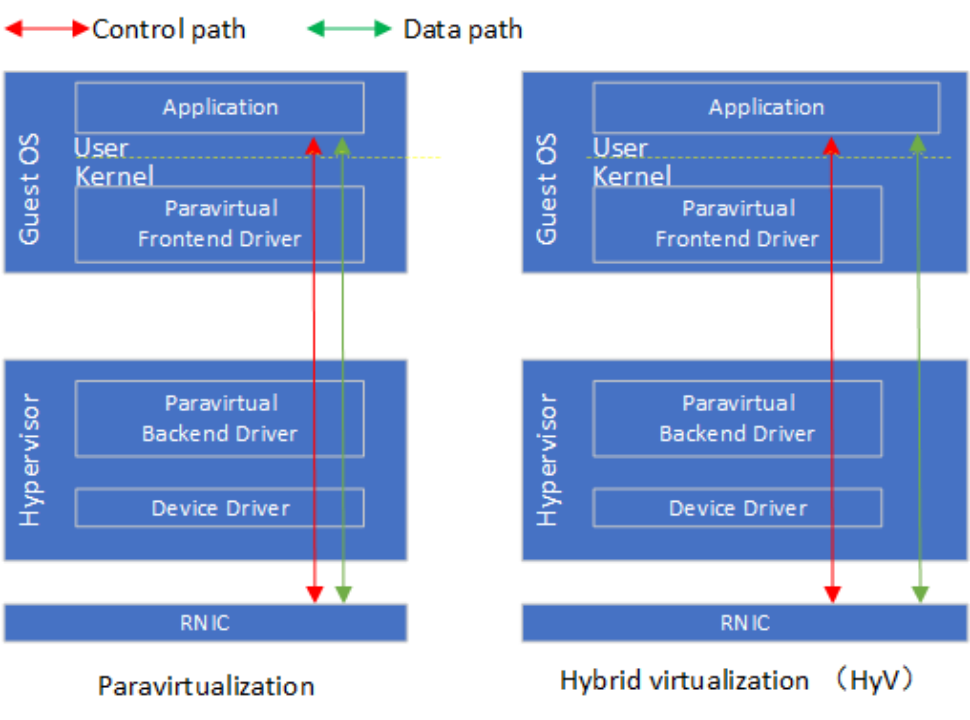
Figure 8 HyV混合虛擬化和半虛擬對比
04針對容器的RDMA虛擬化技術
容器可以看作是在主機操作系統上執行的進程,由主機操作系統提供資源隔離和命名空間(Namespace)的隔離。Namespace是Linux內核提供的資源隔離技術,可以實現網絡、文件系統以及進程資源等的隔離。針對容器的RDMA虛擬化技術,本質上是在網絡Namespace的基礎上創建虛擬RDMA設備接口的過程。針對虛擬機的RDMA虛擬化技術是可以直接遷移到容器上的。Mellanox公司在2018年推出出了針對Docker容器網絡設備SR-IOV和Passthrough插件 [10],該插件能夠在容器內部創建虛擬RDMA設備或將物理設備綁定到某一個具體的容器。此外,Mellanox SR-IOV/Passthrough插件還利用網卡的的VLAN卸載功能對容器提供基于VLAN的虛擬網絡支持。
SR-IOV能夠提供良好的性能,但是不能完全滿足云計算所需要的靈活性需求。特別地,容器對虛擬化方案的靈活性需求更高,現有研究工作主要從這個角度入手。微軟的研究人員認為基于SR-IOV的虛擬化方案不能滿足容器需要的便攜性(Portability)要求。在基于SR-IOV的方案種,更新容器的IP需要同時更新網卡上的VLAN路由表。此外,基于SR-IOV的方案使得容器可以直接訪問物理RDMA網卡,云服務提供商不能靈活地對容器的RDMA業務進行管控。
FreeFlow [11]是微軟提出的容器虛擬化方案,該方案包括FreeFlow NetLib、FreeFlow Router以及FreeFlow Orchestrator。FreeFlow可以看作是半虛擬化設計,FreeFlow Netlib相當于容器內部的前端,而FreeFlow Router相當于主機上的后端。FreeFlow Netlib以標準的用戶態Verbs API作為基礎,從而保持對應用透明。FreeFlow Netlib通過劫持控制路徑上的RNIC文件描述符請求,避免直接劫持Verbs API調用帶來的RDMA數據結構序列化復雜度。FreeFlow Netlib將劫持到的RNIC文件描述符請求通過Unix Socket File Descriptor或者共享內存的方式轉發到FreeFlow Router。FreeFlow Netlib和FreeFlow Router都是兩個進程,通過Unix Socket File Descriptor可以實現兩個進程之間的通信,但是這種通信方式延遲開銷在5us以上,不能維持RDMA的低延遲要求。FreeFlow同時設計了基于共享內存的進程間通信方式,這種通信延遲低但是需要CPU資源輪詢共享內存。FreeFlow Route是位于主機的一個進程,代替同一主機上的容器和物理RDMA網卡交互。為了實現數據路徑上的零拷貝,FreeFlow Router將其內部的共享數據緩沖區(Shared Memory)和容器內應用緩沖區映射到同一塊物理內存。為了實現這種映射,FreeFlow提供主動分配和被動重映射的方法。主動分配方法需要應用主動調用FreeFlow自定義的ibv_malloc和ibv_free接口分配和釋放FreeFlow Router內部預留的Shared Memory。被動重映射需要FreeFlow Netlib在FreeFlow Router處理完內存注冊請求后,將應用通過malloc申請的內存物理頁重新映射到FreeFlow Router返回的Shared Memory。FreeFlow Orchestrator負責集群內全部容器的網絡編排,例如編址、訪問控制。此外,FreeFlow Orchestrator還需要管理容器內應用緩沖區虛擬地址到FreeFlow Router內部Shared Memory指針的映射關系。
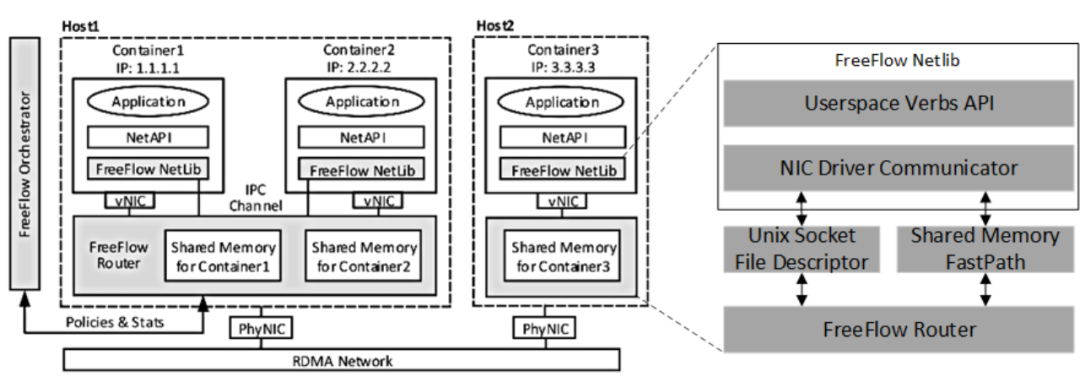
Figure 9 FreeFlow的總體架構
在標準的容器生產中,容器網絡接口應遵循云原生計算基金會(Cloud Native Computing Foundation,CNCF)規定的容器網絡接口(Container Network Interface,CNI)規范 [12],然而FreeFlow和CNI標準并不兼容。Mellanox在2021年推出了針對K8s容器編排平臺的CNI插件RDMA CNI plugin [13],使得基于SR-IOV的RDMA網絡設備資源池能夠集成到K8s。Container Runtime (例如Docker)在創建容器時,先創建好Network Namespace (netns),然后調用RDMA CNI plugin為這個netns配置RDMA網絡,其后再啟動容器內的應用。
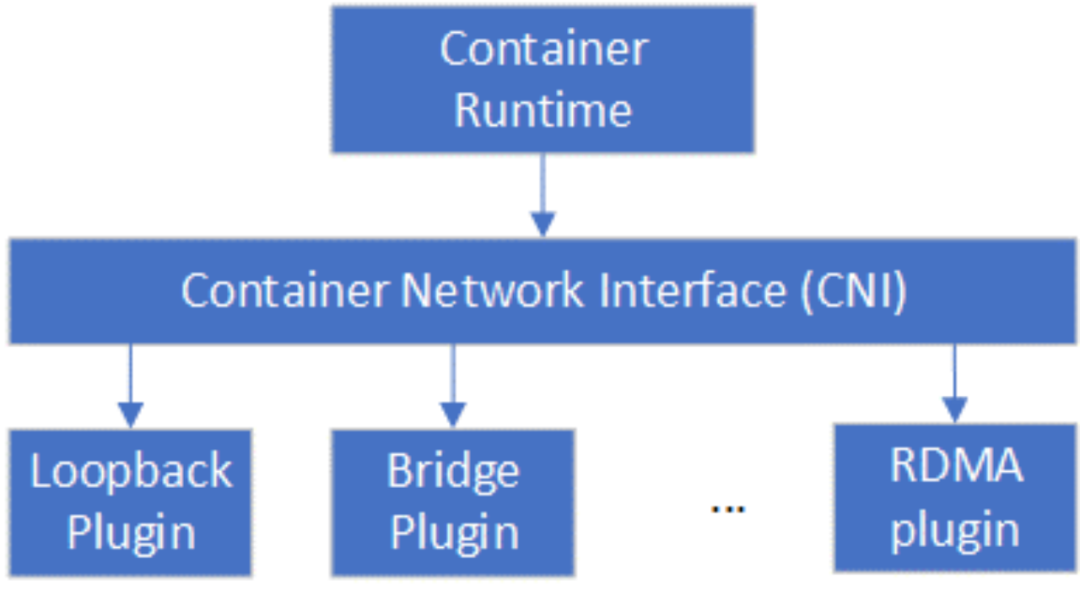
Figure 10 CNI插件關系圖
05總結與展望
本文分別從虛擬機和容器2個方面闡述了對RDMA虛擬化的相關研究。從虛擬機角度來看,以HyV為代表的混合虛擬化方案利用了RDMA控制-數據分離的設計特征,能夠在控制面的靈活性和數據面的性能上取得很好的權衡。未來的研究應該重點關注控制面的靈活性,面向云計算業務實際需求優化。從容器角度來看,容器和物理RDMA網卡之間的軟件中間層比虛擬機更輕薄,但是容器網絡的復雜性是要高于虛擬機的,同時容器的規模也要比虛擬機大。容器網絡和容器規模要求網絡2層交換層具有高靈活性,高可擴展性,因此目前主流的SR-IOV的容器虛擬化方案必須要在網卡硬件上實現滿足容器部署需求的交換層。DPU上同時具備了靈活可編程網絡引擎,RDMA引擎以及SR-IOV的支持,有潛力能夠在性能、靈活性以及可擴展性層面取得比較好的權衡。
-
cpu
+關注
關注
68文章
10863瀏覽量
211781 -
計算機
+關注
關注
19文章
7494瀏覽量
87961 -
內存
+關注
關注
8文章
3025瀏覽量
74055 -
硬件
+關注
關注
11文章
3328瀏覽量
66224 -
RDMA
+關注
關注
0文章
77瀏覽量
8949
原文標題:RDMA RNIC虛擬化
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電力短缺的救星:虛擬化?
u***server虛擬化識別加密狗解決方案
虛擬化使用加密狗解決方案案例
虛擬化方案識別加密狗技術介紹
虛擬化使用加密狗及共享方案案例
幾種主要的虛擬化技術有什么不同?
Minos嵌入式虛擬化方案分享
數字電路實驗的虛擬化設計方案
openEuler Summit 2021-云/虛擬化分論壇:混合多云管理平臺—兼容虛擬化方案





 工商網監
工商網監
評論