 數據中心AI芯片上升趨勢能夠持續多久呢?
數據中心AI芯片上升趨勢能夠持續多久呢?
有預測稱,今年AI芯片可能會迎來強勁甚至迅猛的增長。然而,一個令人關注的問題是,這種上升趨勢能夠持續多久呢?
2023年底,AMD大膽地宣稱,到2027年,數據中心AI芯片的總潛在市場(TAM)將達到4000億美元,復合年增長率(CAGR)超過70%。這一預測引起了不同的反應,但也從側面說明了大型語言模型(LLM)作為處理生成式人工智能(GenAI)應用核心的驅動力。
作為圖形處理單元(GPU)市場的領導者,英偉達的成功證明了這些芯片的潛在市場規模。英偉達過去一年的股價上漲了217%,在過去三年增長了140%。
在最新的11月財報中,英偉達公布的營收為181.2億美元,其中數據中心營收為145.1億美元。整體銷售額同比增長206%,而數據中心銷售額同期增長了279%。所有這些都證實了數據中心芯片的銷售正經歷急劇上升的趨勢。然而,關鍵問題是,這個增長趨勢是否能夠達到4000 億美元的高度。
英偉達在數據中心AI GPU市場至少占據80%的份額,未來三年預計將迎來巨大增長。然而,要實現高達4000億美元的市場規模,英偉達的表現需要比目前更出色,同時其他廠商也需要超出預期。
競爭者不甘示弱
AMD
AMD 認為其將在未來三年內實現大幅增長。2023 年 12 月,AMD發布了MI300 系列芯片,旨在在推理方面超越英偉達的GPU。同時發布的另一款產品AMD Instinct MI300A加速處理單元(APU),將CPU和GPU核心與內存集成在一個平臺中。
MI300X 專為云提供商和企業設計,專為生成式 AI 應用而打造,MI300X GPU 擁有超過 1500 億個晶體管,以 2.4 倍的內存超越了英偉達的 H100。峰值內存帶寬達到 5.3 TB/s ,是H100 3.3 TB/s 的 1.6 倍。
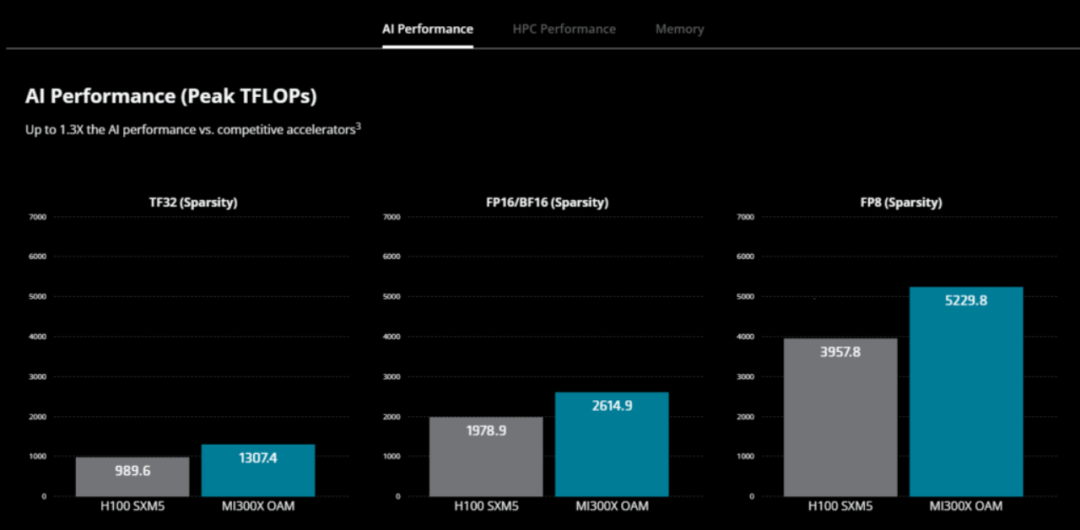
AMD Instinct MI300A APU 配備 128GB HBM3 內存。據稱,與之前的 M250X 處理器相比,MI300A 在 HPC 和 AI 工作負載上的每瓦性能提高了 1.9 倍。
AMD 總裁兼首席執行官蘇姿豐 (Lisa Su) 在去年 10 月的公司第三季度電話會議上表示:“隨著 2024 年的到來,我們預計收入將持續增長,而且主要來源將是AI。”“在AI領域,我們的客戶覆蓋面很廣,包括從超大規模企業到原始設備制造商、企業客戶以及一些新的人工智能初創企業。從工作負載的角度來看,我們希望 MI300 能夠同時處理訓練和推理工作負載。”
英特爾上個月推出了AI芯片 Gaudi3 以及第五代 Xeon 處理器,作為進一步進軍數據中心AI市場的一部分。
英特爾表示,Gaudi3 是專為深度學習和創建大規模生成人工智能模型而設計的下一代人工智能加速器,將與英偉達的 H100 和 AMD 的 MI300X 展開競爭。
英特爾聲稱Xeon 是唯一內置 AI 加速的主流數據中心處理器,全新第五代 Xeon 在多達 200 億個參數的模型上提供高達 42% 的推理和微調能力。它也是唯一一款具有一致且不斷改進的 MLPerf 訓練和推理基準測試結果的 CPU。
Xeon的內置人工智能加速器,加上優化的軟件和增強的遙測功能,可以為通信服務提供商、內容交付網絡和包括零售、醫療保健和制造在內的廣泛垂直市場實現更易于管理、更高效的高要求網絡和邊緣工作負載部署。
云廠商各顯神通
AWS、谷歌等云廠商一直在為自己的大型數據中心打造定制芯片。一方面是不想過度依賴英偉達,另外針對自身需求定制芯片也有助于提高性能和降低成本。
AWS
亞馬遜的AI芯片Trainium和Inferentia專為訓練和運行大型人工智能模型而設計。
AWS Trainium2是 AWS 專門為超過 1000 億個參數模型的深度學習訓練打造的第二代機器學習 (ML) 加速器。AWS CEO Adam Selipsky 表示,近期推出的Trainium2的速度是其前身的4倍,能源效率是其之前的2倍。Tranium2 將在 AWS 云中由 16 個芯片組成的集群中的 EC Trn2 實例中使用,在 AWS 的 EC2 UltraCluster 產品中可擴展到多達 10萬個芯片。AWS表示,10萬個 Trainium 芯片可提供 65 exaflops 的計算能力,相當于每個芯片可提供 650 teraflops 的計算能力。
AWS Inferentia2 加速器與第一代相比在性能和功能方面實現了重大飛躍。Inferentia2 的吞吐量提高了 4 倍,延遲低至 1/10。
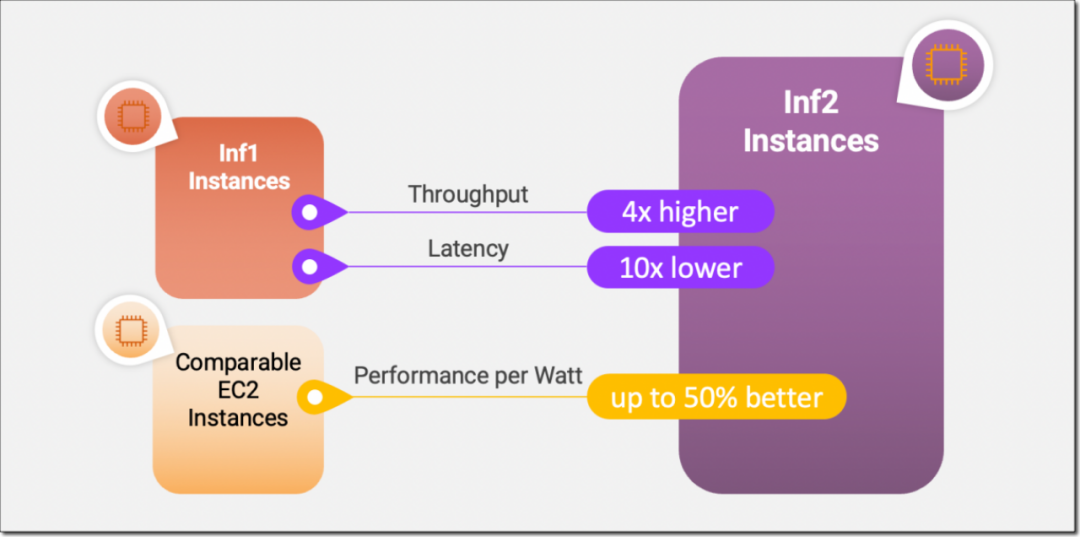
AWS Inferentia2 支持多種數據類型,包括 FP32、TF32、BF16、FP16 和 UINT8,還支持新的可配置 FP8 (cFP8) 數據類型,因為它減少了模型的內存占用和 I/O 要求。AWS Inferentia2 具有嵌入式通用數字信號處理器 (DSP),可實現動態執行,因此無需在主機上展開或執行控制流運算符。AWS Inferentia2 還支持動態輸入形狀,這對于輸入張量大小未知的模型(例如處理文本的模型)至關重要。AWS Inferentia2 支持用 C++ 編寫的自定義運算符。
谷歌
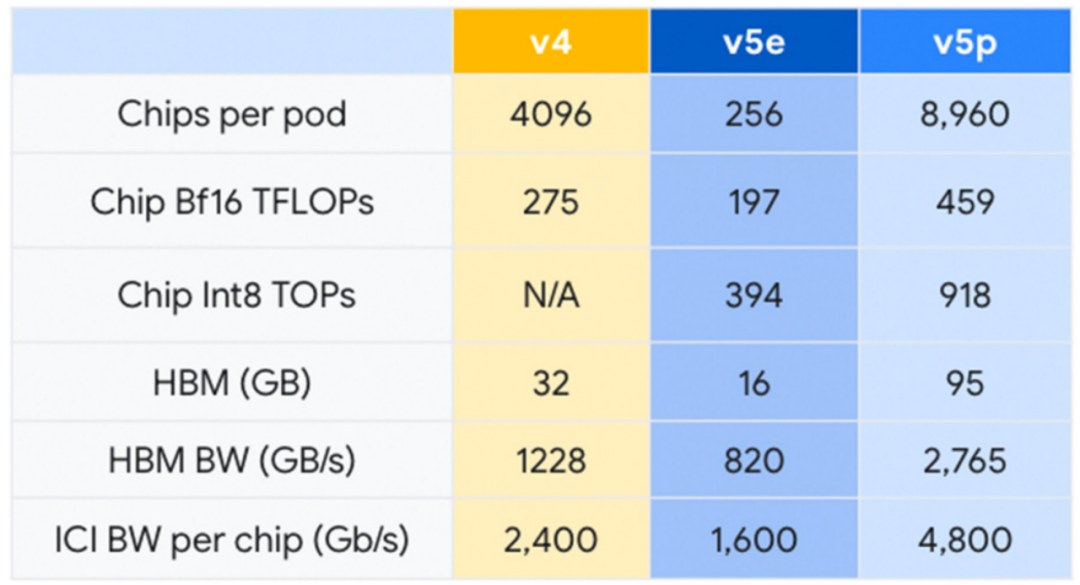
2023 年 12 月,谷歌發布最新的Cloud TPU v5p,并號稱是迄今最強大的TPU。每個 TPU v5p Pod由 8,960 個芯片組成,采用 3D 環面拓撲,互連速度達 4,800 Gbps。與 TPU v4 相比,TPU v5p 的FLOPS 提高了 2 倍以上,高帶寬內存 (HBM) 提高了 3 倍以上。
TPU v5p 專為性能、靈活性和規模而設計,訓練大型 LLM 模型的速度比上一代 TPU v4 快 2.8 倍。此外,借助第二代SparseCores,TPU v5p訓練嵌入密集模型的速度比 TPU v4 2快 1.9 倍。
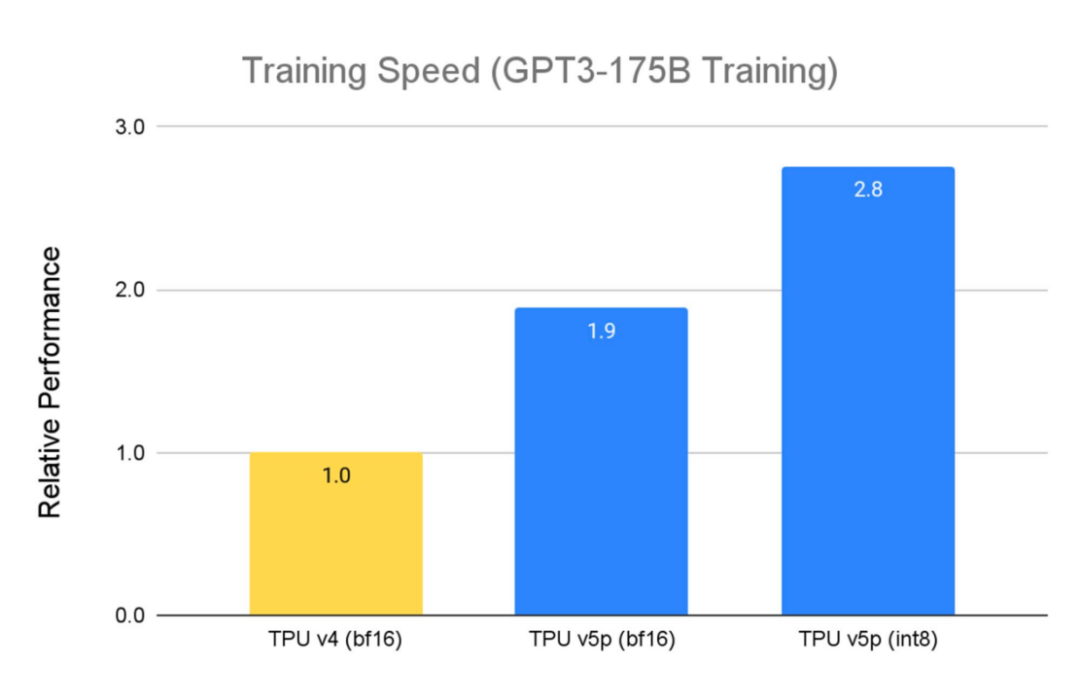
除了性能改進之外,TPU v5p 在每個 pod 的總可用 FLOP 方面的可擴展性也比 TPU v4 高 4 倍。與 TPU v4 相比,每秒浮點運算次數 (FLOPS) 加倍,并且單個 Pod 中的芯片數量加倍,可顯著提高訓練速度的相對性能。
微軟
2023 年 11 月,微軟推出了AI芯片Azure Maia 100。Maia 100 是 Maia AI 加速器系列中的首款產品。
Maia 采用 5 nm臺積電工藝制造,擁有 1050 億個晶體管,比 AMD MI300X AI GPU的 1530 億個晶體管少約 30% 。微軟表示,“Maia 支持我們首次實現低于 8 位數據類型(MX 數據類型),以便共同設計硬件和軟件,這有助于我們支持更快的模型訓練和推理時間。”
Maia 100 目前正在 GPT 3.5 Turbo 上進行測試,該模型也為 ChatGPT、Bing AI 工作負載和 GitHub Copilot 提供支持。微軟正處于部署的早期階段,還不愿意發布確切的 Maia 規范或性能基準。
總的來說,從AMD 4000億美元市場的預測中至少可以得出三個結論:首先,數據中心仍是短期內AI芯片的焦點;其次,數據中心 AI芯片領域正急劇上升,盡管上升的幅度仍然是一個問題;第三, 英偉達將繼續在該領域占據主導地位,但包括 AMD 在內的其他供應商正努力削弱其地位。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19286瀏覽量
229842 -
gpu
+關注
關注
28文章
4740瀏覽量
128948 -
晶體管
+關注
關注
77文章
9693瀏覽量
138189 -
HPC
+關注
關注
0文章
316瀏覽量
23772 -
AI芯片
+關注
關注
17文章
1887瀏覽量
35021
原文標題:數據中心AI芯片市場有多大?
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI與數據中心驅動下 芯片電感的技術革命

AmpereOne如何滿足現代數據中心需求
Meta AI數據中心網絡用了哪家的芯片
AI數據中心的能源危機,需要更高效的PSU
當今數據中心新技術趨勢
數據中心的AI時代轉型:挑戰與機遇

AI時代,我們需要怎樣的數據中心?AI重新定義數據中心

HNS 2024:星河AI數據中心網絡,賦AI時代新動能

蘋果正在開發用于數據中心的AI芯片
蘋果正在研發全新數據中心AI芯片
蘋果自研數據中心AI芯片

數據中心存儲的趨勢
英飛凌推出高密度功率模塊,為AI數據中心降本增效
讓數字世界堅定運行 | 華為發布2024數據中心能源十大趨勢






 工商網監
工商網監
評論