 詳解GPU硬件架構及運行機制
詳解GPU硬件架構及運行機制
為什么我們總說GPU比CPU要強大,既然GPU強大,為什么不能取代CPU呢?
答案就是CPU工作方式和GPU的工作方式截然不同,下面的兩張圖有助于幫助我們理解CPU和GPU的工作方式的不同。

上圖有幾個重點的元素,也是我們下文重點要闡述的概念,綠色代表的是computational units(可計算單元) 或者稱之為 cores(核心),橙色代表memories(內存) ,黃色代表的是control units(控制單元)。
因此想要理解GPU的底層核心構成,就必須明確這幾個元素的作用,下文會逐一講解每個元素的作用。
01.計算單元(cores)
總的來看,我們可以這樣說:CPU的計算單元是“大”而“少”的,然而GPU的計算單元是“小”而“多”的。
這里的大小是指的計算能力,多少指的是設備中的數量。通過觀察上圖,顯然可以看出,計算單元(綠色的部分),CPU“大少”,GPU“小多”的特點。
CPU的cores 比GPU的cores要更加聰明(smarter),這也是所謂“大”的特點。
在過去的很長時間里,CPU的core計算能力增長是得益于主頻時鐘最大的頻率增長。
相反,GPU不僅沒有主頻時鐘的提升,而且還經歷過主頻下降的情況,因為GPU需要適應嵌入式應用環境,在這個環境下對功耗的要求是比較高的,不能容忍超高主頻的存在。
例如英偉達的Jetson NANO, 安裝在室內導航機器人身上,就是一個很好的嵌入式環境應用示例,安裝在機器人身上,就意味著使用電池供電,GPU的功耗不可以過高。
CPU比GPU聰明,很大一個原因就是CPU擁有"out-of-order exectutions"(亂序執行)功能。
出于優化的目的,CPU可以用不同于輸入指令的順序執行指令,當遇到分支的時候,它可以預測在不久的將來哪一個指令最有可能被執行到(multiple branch prediction 多重分支預測)。
通過這種方式,它可以預先準備好操作數,并且提前執行他們(soeculative execution 預測執行),通過上述的幾種方式節省了程序運行時間。
顯然現代CPU擁有如此多的提升性能的機制,這是比GPU聰明的地方。
相比之下,GPU的core不能做任何類似out-of-order exectutions那樣復雜的事情。
總的來說,GPU的core只能做一些最簡單的浮點運算,例如 multiply-add(MAD)或者 fused multiply-add(FMA)指令。
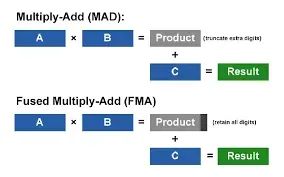
通過上圖可以看出MAD指令實際是計算A*B+C的值。
實際上,現代GPU結構,CORE不僅僅可以結算FMA這樣簡單的運算,還可以執行更加復雜的運算操作,例如tensor張量(tensor core)或者光線追蹤(ray tracing core)相關的操作。
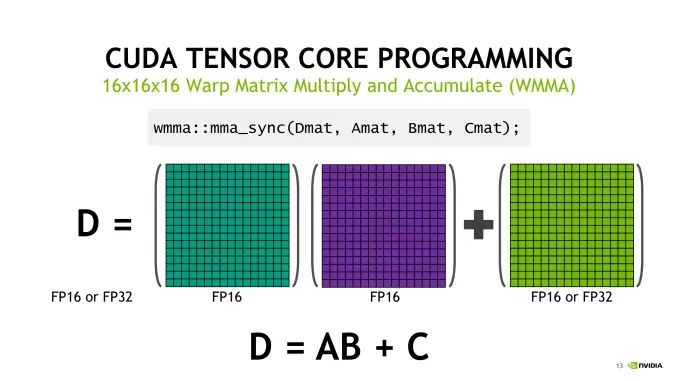
張量核心 (tensor cores) 的目的在于服務張量操作在一些人工智能運算場合,光纖追蹤(ray tracing) 旨在服務超現實主義(hyper-realistic)實時渲染的場合。
上文說到,GPU Core最開始只是支持一些簡單的浮點運算FMA, 后來經過發展又增加了一些復雜運算的機制tensor core以及ray trace,但是總體來說GPU的計算靈活性還是比不上CPU的核心。
值得一提的是,GPU的編程方式是SIMD(Single Instruction Multiple Data)意味著所有Core的計算操作完全是在相同的時間內進行的,但是輸入的數據有所不同。
顯然,GPU的優勢不在于核心的處理能力,而是在于他可以大規模并行處理數據。
GPU中每個核心的作用有點像羅馬帆船上的槳手:鼓手打著節拍(時鐘),槳手跟著節拍一同滑動帆船。
SIMT編程模型允許加速運行非常多的應用,對圖像進行縮放就是一個很好的例子。
在這個例子中,每個core對應圖像的一個像素點,這樣就可以并行的處理每一個像素點的縮放操作,如果這個工作給到CPU來做,需要N的時間才可以做完,但是給到GPU只需要一個時鐘周期就可以完成。
當然,這樣做的前提是有足夠的core來覆蓋所有的圖像像素點。這個問題有個顯著的特點,就是對一張圖像進行縮放操作,各個像素點之間的信息是相互獨立的,因此可以獨立的放在不同的core中進行并行運算。
我們認為不同的core操作的信息相互獨立,是符合SIMT的模型的,使用SIMT來解決這樣的問題非常方便。
但是,也不是所有的問題都是符合SIMT模型的,尤其在異步問題中,在這樣的問題中,不同的core之間要相互交互信息,計算的結構不規則,負載不均衡,這樣的問題交給GPU來處理就會比較復雜。
02.內存memory
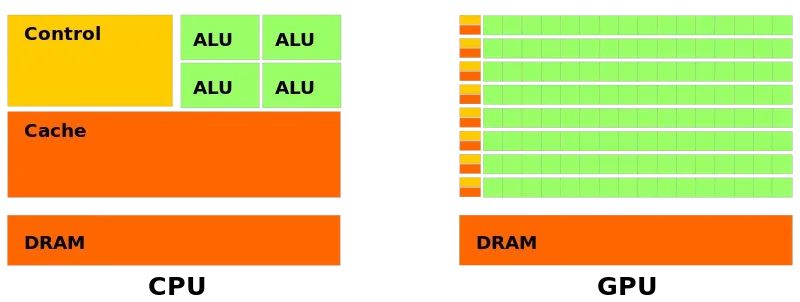
回到這個文章的第一張圖中來,我們接下來會討論GPU和CPU內存方面的差別。
CPU的memory系統一般是基于DRAM的,在桌面PC中,一般來說是8G,在服務器中能達到數百(256)Gbyte。
CPU內存系統中有個重要的概念就是cache,是用來減少CPU訪問DRAM的時間。cache是一片小的內存區域,但是訪問速度更快,更加靠近處理器核心的內存段,用來儲存DRAM中的數據副本。
cache一般有一個分級,通常分為三個級別L1,L2,L3 cache,cache離核心越近就越小訪問越快,例如 L1可以是64KB L2就是256KB L3是4MB。
CPU Cache的內容不再這里展開講解,感興趣的讀者可以自行查閱資料。
從第一張圖可以看到GPU中有一大片橙色的內存,名稱為DRAM,這一塊被稱為全局內存或者GMEM。
GMEM的內存大小要比CPU的DRAM小的多,在最便宜的顯卡中一般只有幾個G的大小,在最好的顯卡中GMEM可以達到24G。
GMEM的尺寸大小是科學計算使用中的主要限制。十年前,顯卡的容量最多也就只有512M,但是,現在已經完全克服了這個問題。
關于cache,從第一張圖中不難推斷,左上角的小橙色塊就是GPU的cache段。然而GPU的緩存機制和CPU是存在一定的差異的,稍后將會證明這一點。
03.GPU的底層結構
為了充分理解GPU的架構,讓我們在返回來看下第一張圖,一個顯卡中絕大多數都是計算核心core組成的海洋。
在圖像縮放的例子中,core與core之間不需要任何協作,因為他們的任務是完全獨立的,然而,GPU解決的問題不一定這么簡單,讓我們來舉個例子。
假設我們需要對一個數組里的數進行求和,這樣的運算屬于reductuin family類型,因為這樣的運算試圖將一個序列“reduce”簡化為一個數。
計算數組的元素總和的操作看起來是順序的,我們只需要獲取第一個元素,求和到第二個元素中,獲取結果,再將結果求和到第三個元素,以此類推。
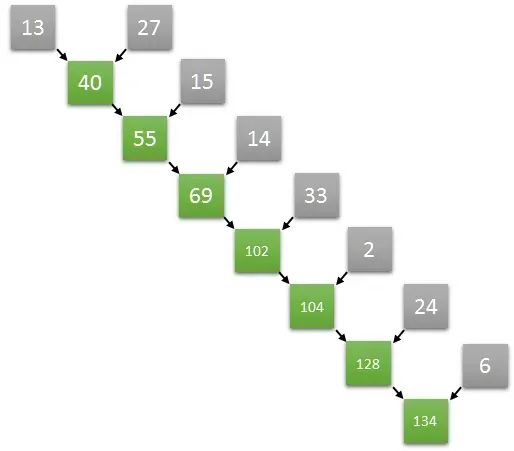
令人驚訝的是,一些看起來本質是順序的運算,其實可以再并行算法中轉化。
假設一個長度為8的數組,在第一步中完全可以并行執行兩個元素和兩個元素的求和,從而同時獲得四個元素,兩兩相加的結果,以此類推,通過并行的方式加速數組求和的運算速度。具體的操作如下圖所示:
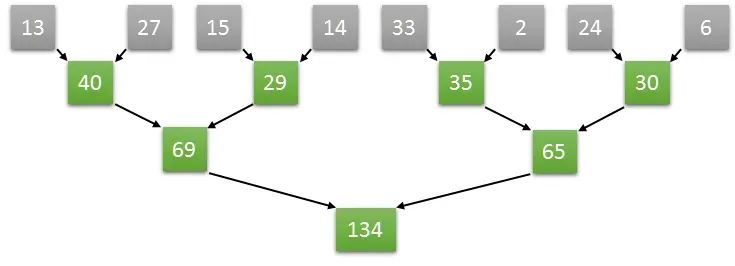
如上圖計算方式,如果是長度為8的數組兩兩并行求和計算,那么只需要三次就可以計算出結果。
如果是順序計算需要8次。如果按照兩兩并行相加的算法,N個數字相加,那么僅需要log2(N)次就可以完成計算。
從GPU的角度來講,只需要四個core就可以完成長度為8的數組求和算法,我們將四個core編號為0,1,2,3。
那么第一個時鐘下,兩兩相加的結果通過0號core計算,放入了0號core可以訪問到的內存中,另外兩兩對分別由1號2號3號core來計算,第二個個時鐘繼續按照之前的算法計算,只需要0號和1號兩個core即可完成。
以此類推,最終的結果將在第三個時鐘由0號core計算完成,并儲存在0號core可以訪問到的內存中。這樣實際三次就能完成長度為8的數組求和計算。
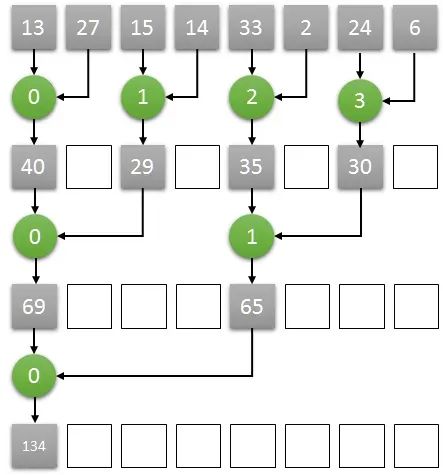
如果GPU想要完成上述的推理計算過程,顯然,多個core之間要可以共享一段內存空間以此來完成數據之間的交互,需要多個core可以在共享的內存空間中完成讀/寫的操作。
我們希望每個Cores都有交互數據的能力,但是不幸的是,一個GPU里面可以包含數以千計的core,如果使得這些core都可以訪問共享的內存段是非常困難和昂貴的。
出于成本的考慮,折中的解決方案是將各類GPU的core分類為多個組,形成多個流處理器(Streaming Multiprocessors )或者簡稱為SMs。
04.GPU架構
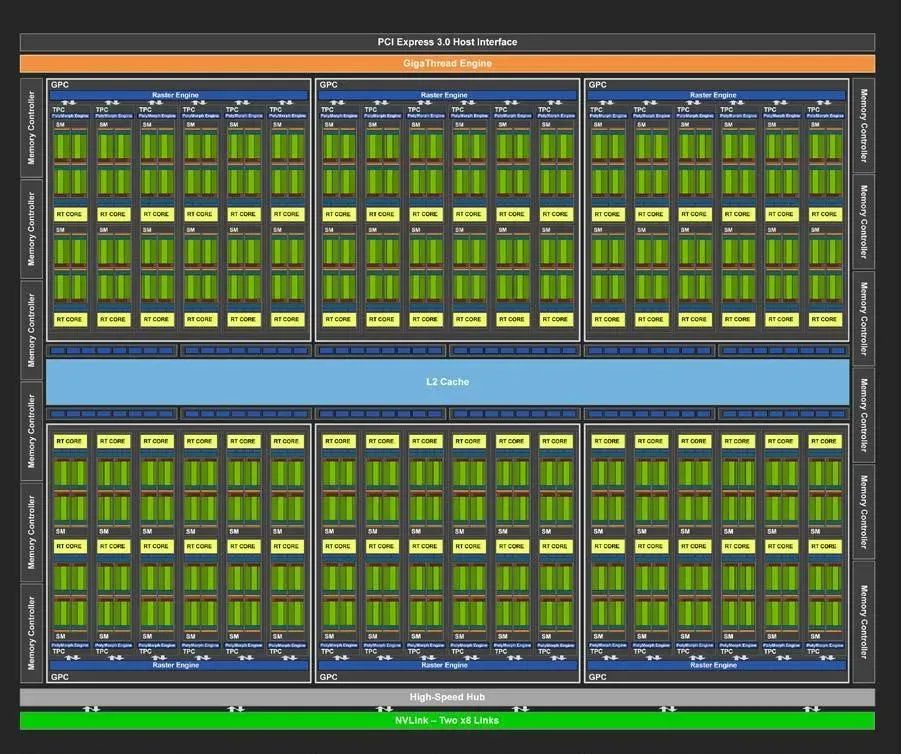
上圖的綠色部分意味著Core計算單元,綠色的塊就是上文談到的Streaming Multiprocessors,理解為Core的集合。
黃色的部分名為RT COREs畫的離SMs非常近。單個SM的圖靈架構如下圖所示

在SM的圖靈結構中,綠色的部分CORE相關的,我們進一步區分了不同類型的CORE。主要分為INT32,FP32,TENSOR CORES。
1. FP32 Cores,執行單進度浮點運算,在TU102卡中,每個SM由64個FP32核,圖靈102由72個SM因此,FP32 Core的數量是 72 * 64。
2. FP64 Cores. 實際上每個SM都包含了2個64位浮點計算核心FP64 Cores,用來計算雙精度浮點運算,雖然上圖沒有畫出,但是實際是存在的。
3. Integer Cores,這些core執行一些對整數的操作,例如地址計算,可以和浮點運算同時執行指令。在前幾代GPU中,執行這些整型操作指令都會使得浮點運算的管道停止工作。TU102總共由4608個Integer Cores,每個SM有64個intCores。
4. Tensor Cores,張量core是FP16單元的變種,認為是半精度單元,致力于張量積算加速常見的深度學習操作。
圖靈張量Core還可以執行INT8和INT4精度的操作,用于可以接受量化而且不需要FP16精度的應用場景,在TU102中,我們每個SM有8個張量Cores,一共有8 * 72個Tensor Cores。
在大致描述了GPU的執行部分之后,讓我們回到上文提出的問題,各個核心之間如何完成彼此的協作?
在四個SM塊的底部有一個96KB的L1 Cache,用淺藍色標注的。這個cache段是允許各個Core都可以訪問的段,在L1 Cache中每個SM都有一塊專用的共享內存。
作為芯片上的L1 cache他的大小是有限的,但它非常快,肯定比訪問GMEM快得多。
實際上L1 CACHE擁有兩個功能,一個是用于SM上Core之間相互共享內存,另一個則是普通的cache功能。
當Core需要協同工作,并且彼此交換結果的時候,編譯器編譯后的指令會將部分結果儲存在共享內存中,以便于不同的core獲取到對應數據。
當用做普通cache功能的時候,當core需要訪問GMEM數據的時候,首先會在L1中查找,如果沒找到,則回去L2 cache中尋找,如果L2 cache也沒有,則會從GMEM中獲取數據,L1訪問最快 L2 以及GMEM遞減。
緩存中的數據將會持續存在,除非出現新的數據做替換。從這個角度來看,如果Core需要從GMEM中多次訪問數據,那么編程者應該將這塊數據放入功能內存中,以加快他們的獲取速度。
其實可以將共享內存理解為一段受控制的cache,事實上L1 cache和共享內存是同一塊電路中實現的。編程者有權決定L1 的內存多少是用作cache多少是用作共享內存。
最后,也是比較重要的是,可以儲存各個core的計算中間結果,用于各個核心之間共享的內存段不僅僅可以是共享內存L1,也可以是寄存器,寄存器是離core最近的內存段,但是也非常小。
最底層的思想是每個線程都可以擁有一個寄存器來儲存中間結果,每個寄存器只能由相同的一個線程來訪問,或者由相同的warp或者組的線程訪問。
05.總結
GPU的基本底層構成,主要是以GPU計算核心 Cores,以及Memory以及控制單元,三大組成要素組成。
Core是計算的基本單元,既可以用作簡單的浮點運算,又可以做一些復雜的運算例如,tensor 或者ray tracing。
多個core之間通訊的方式:
在特定的應用場合多個core之間是不需要的通訊的,也就是各干各的(例如 圖像縮放)。但是也有一些例子,多個core之間要相互通訊配合(例如上文談到的數組求和問題),每個core之間都可以實現交互數據是非常昂貴的,因此提出了SM的概念,SM是多個core的集合,一個SM里面的cores可以通過L1 Cache進行交互信息,完成使用GPU處理數組求和問題的時候,多個核心共享數據的功能。
關于memory,存在全局的內存GMEM,但是訪問較慢,Cores當需要訪問GMEM的時候會首先訪問L1,L2如果都miss了,那么才會花費大代價到GMEM中尋找數據。
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19286瀏覽量
229854 -
cpu
+關注
關注
68文章
10863瀏覽量
211786 -
gpu
+關注
關注
28文章
4740瀏覽量
128951
原文標題:深入理解GPU硬件架構及運行機制
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
蘋果宣布iPhone OS 4 多任務運行機制詳解
Arduino為什么只有loop和setup函數,揭開Arduino的神秘面紗--運行機制
NVIDIA火熱招聘GPU高性能計算架構師
ARM架構的GPU和臺式機的GPU有什么區別
CPU的基本結構和運行機制
Linux系統的fork運行機制分析

SSL和TLS協議運行機制的資料詳細概述
深入GPU硬件架構及運行機制(下)
GPU硬件架構及運行機制(下)
php運行機制和原理
揭秘GPU: 高端GPU架構設計的挑戰






 工商網監
工商網監
評論