") Vision Mamba:速度與內存的雙重突破
Vision Mamba:速度與內存的雙重突破
Vision Mamba 不是個普通模型。
號稱「全面包圍 Transformer」的 Mamba,推出不到兩個月就有了高性能的視覺版。 來自華中科技大學、地平線、智源人工智能研究院等機構的研究者提出了 Vision Mamba(Vim)。
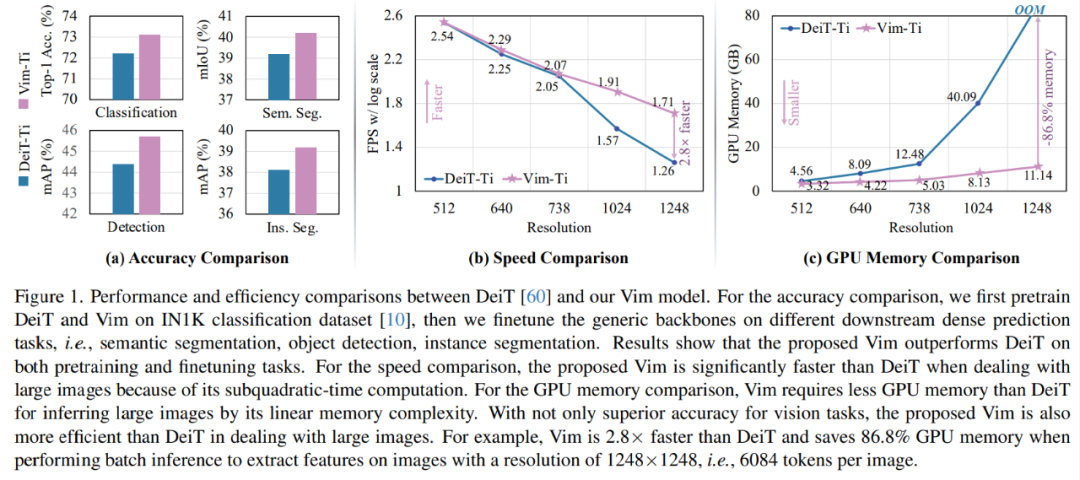
效果如何呢?在 ImageNet 分類任務、COCO 對象檢測任務和 ADE20k 語義分割任務上,與 DeiT 等成熟的視覺 Transformers 相比,Vim 實現(xiàn)了更高的性能,同時還顯著提高了計算和內存效率。例如,在對分辨率為 1248×1248 的圖像進行批量推理提取特征時,Vim 比 DeiT 快 2.8 倍,并節(jié)省 86.8% 的 GPU 內存。結果表明,Vim 能夠克服對高分辨率圖像執(zhí)行 Transformer 式理解時的計算和內存限制,并且具有成為視覺基礎模型的下一代骨干的巨大潛力。
接下來我們看看論文內容。 Mamba 的提出帶動了研究者對狀態(tài)空間模型(state space model,SSM)興趣的增加,不同于 Transformer 中自注意力機制的計算量會隨著上下文長度的增加呈平方級增長,由于 SSM 擅長捕捉遠程依賴關系,因而開始受到大家追捧。 在此期間,一些基于 SSM 的方法如線性狀態(tài)空間層(LSSL)、結構化狀態(tài)空間序列模型(S4)、對角狀態(tài)空間(DSS)和 S4D 都被研究者提出來,用于處理各種序列數(shù)據,特別是在建模遠程依賴關系方面。 Mamba 將時變參數(shù)納入 SSM 中,并提出了一種硬件感知算法來實現(xiàn)高效的訓練和推理。Mamba 卓越的擴展性能表明它在語言建模方面是 Transformer 有前途的替代品。 然而,到目前為止,研究者還尚未在視覺任務中探索出通用的基于純 SSM 的骨干網絡。 受 Mamba 在語言建模方面成功的激勵,研究者開始設想能否將這種成功從語言轉移到視覺,即用先進的 SSM 方法設計通用且高效的視覺主干。
然而,由于 Mamba 特有的架構,需要解決兩個挑戰(zhàn),即單向建模和缺乏位置感知。 為了應對這些問題,研究者提出了 Vision Mamba (Vim) 塊,它結合了用于數(shù)據依賴的全局視覺上下文建模的雙向 SSM 和用于位置感知視覺識別的位置嵌入。 與其他基于 SSM 的視覺任務模型相比,Vim 是一種基于純 SSM 的方法,并以序列方式對圖像進行建模。與基于 Transformer 的 DeiT 相比,Vim 在 ImageNet 分類上取得了優(yōu)越的性能。此外,Vim 在 GPU 內存和高分辨率圖像的推理時間方面更加高效。 方法介紹 Vision Mamba (Vim) 的目標是將先進的狀態(tài)空間模型 (SSM),即 Mamba 引入到計算機視覺。 Vim 的概述如圖 2 所示,標準的 Mamba 是為 1-D 序列設計的。為了處理視覺任務,首先需要將二維圖像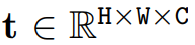 轉換成展開的 2-D patch?
轉換成展開的 2-D patch?
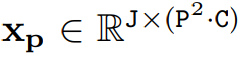
。式中 (H, W) 為輸入圖像的大小,C 為通道數(shù),P 為圖像 patch 的大小。接下來,需要將 x_p 線性投影到大小為 D 的向量上,并添加位置嵌入
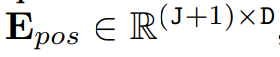
得到如下公式:
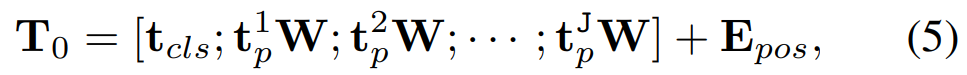
Vim 塊 原始的 Mamba 塊是為一維序列設計的,不適合需要空間感知理解的視覺任務。Vim 塊集成了用于視覺任務的雙向序列建模,Vim 塊如上圖 2 所示。 Vim 塊的操作算法如下所示。

架構細節(jié) 架構的超參數(shù)如下:
L:塊數(shù)
D:隱藏狀態(tài)維度
E:擴展狀態(tài)維度
N:SSM 維度
遵循 ViT 和 DeiT,該研究首先采用 16×16 內核大小的投影層來獲得非重疊 patch 嵌入的一維序列。隨后直接堆疊 L 個 Vim 塊。默認情況下塊數(shù) L 設置為 24,SSM 維度 N 設置為 16。為了與 DeiT 系列模型大小保持一致,該研究將小( tiny)尺寸變體的隱藏狀態(tài)維度 D 設置為 192,將擴展狀態(tài)維度 E 設置為 384。對于小(small)尺寸變體,該研究將 D 設置為 384,將 E 設置為 768。
實驗
該研究在 ImageNet-1K 數(shù)據集上對 Vim 進行了基準測試。
圖像分類
表 1 將 Vim 與基于 ConvNet、基于 Transformer 和基于 SSM 的骨干網絡進行了比較。與基于 ConvNet 的 ResNet 相比,Vim 表現(xiàn)出更優(yōu)越的性能。例如,當參數(shù)大致相似時,Vim-Small 的 top-1 準確率達到 80.3,比 ResNet50 高 4.1 個百分點。與傳統(tǒng)的基于自注意力的 ViT 相比,Vim 在參數(shù)數(shù)量和分類準確率方面都有相當大的優(yōu)勢。與高度優(yōu)化的 ViT 變體(即 DeiT )相比,VimTiny 比 DeiT-Tiny 高 0.9 個點,Vim-Small 比 DeiT 高 0.5 個點。與基于 SSM 的 S4ND-ViTB 相比,Vim 以減少 3 倍的參數(shù)實現(xiàn)了類似的 top-1 準確率。

圖 1 (b) 和 (c) 比較了小型 Vim 和 DeiT 的 FPS 和 GPU 內存。隨著圖像分辨率的提高,Vim 在速度和內存方面表現(xiàn)出更好的效率。具體來說,當圖像大小為 512 時,Vim 實現(xiàn)了與 DeiT 相似的 FPS 和內存。當圖像大小增長到 1248 時,Vim 比 DeiT 快 2.8 倍,并節(jié)省 86.8% 的 GPU 內存。Vim 在序列長度上的線性擴展的顯著優(yōu)勢使其為高分辨率下游視覺應用和長序列多模態(tài)應用做好了準備。
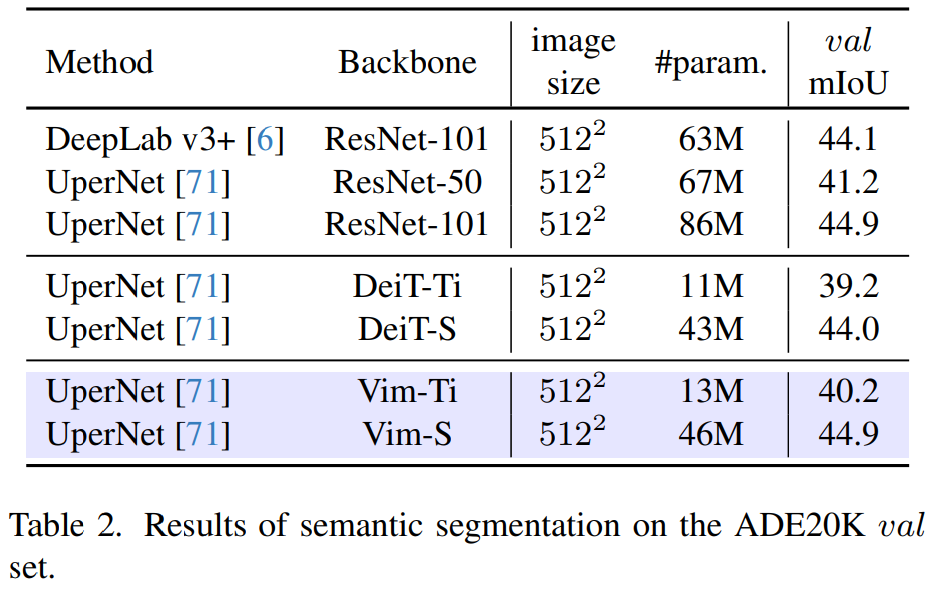
語義分割 如表 2 所示,Vim 在不同尺度上始終優(yōu)于 DeiT:Vim-Ti 比 DeiT-Ti 高 1.0 mIoU,Vim-S 比 DeiT-S 高 0.9 mIoU。與 ResNet-101 主干網絡相比,Vim-S 以減少近 2 倍的參數(shù)實現(xiàn)了相同的分割性能。
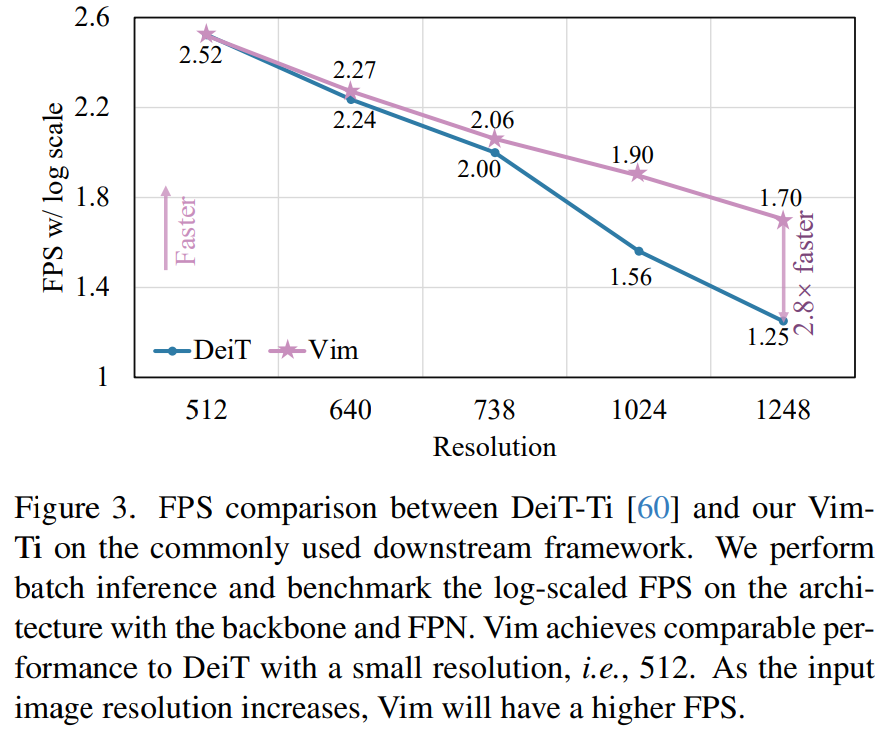
為了進一步評估研究方法在下游任務上(即分割、檢測和實例分割)的效率,本文將骨干網與常用的特征金字塔網絡(FPN)模塊結合起來,并對其 FPS 和 GPU 內存進行基準測試。 如圖 3 和圖 4 所示,盡管該研究在主干網上附加了一個 heavy FPN,但效率曲線與純主干網(圖 1)的比較結果相似。

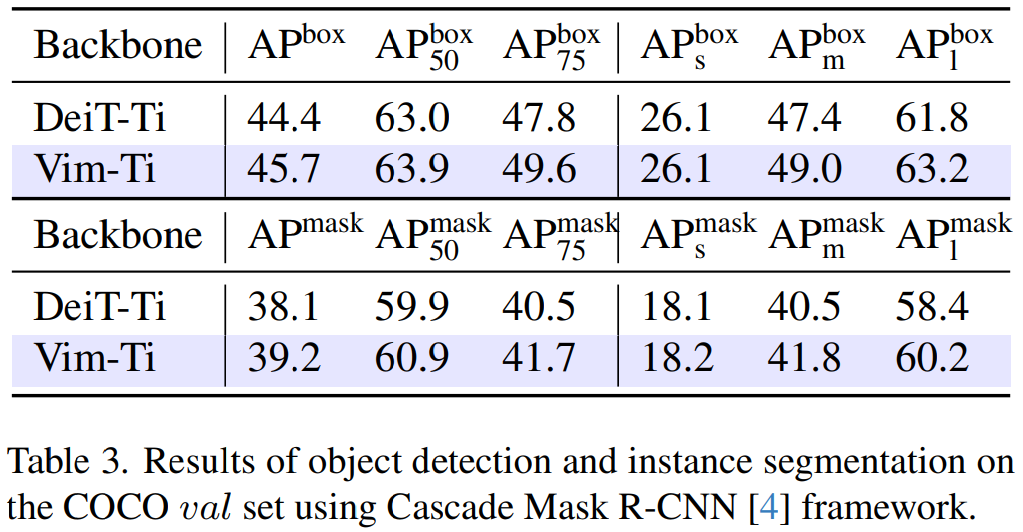
目標檢測和實例分割 表 3 使用 Cascade Mask R-CNN 框架對 Vim-Ti 和 DeiT-Ti 進行了比較。Vim-Ti 超過 DeiT-Ti 1.3 box AP 和 1.1 mask AP。
審核編輯:黃飛
-
gpu
+關注
關注
28文章
4740瀏覽量
128951 -
感知算法
+關注
關注
0文章
19瀏覽量
7644 -
Transformer
+關注
關注
0文章
143瀏覽量
6007
原文標題:視覺新主干!Vision Mamba:高效視覺表示學習,速度提升2.8倍,內存能省87%
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
芯片業(yè)遭雙重打擊:經濟低迷技術難突破
內存救星-極大提高系統(tǒng)速度的工具
繼電保護雙重保護的要求
為什么寄存器的速度比內存快
vision如何安裝
vision acquisition采集圖像速度很低
VISION軟件在汽車發(fā)動機標定中的應用

阿里擬香港紐約雙重主要上市 雙重主要上市是什么?
HUAWEI Vision Glass多少錢?HUAWEI Vision Glass價格2999元
Transformer迎來強勁競爭者 新架構Mamba引爆AI圈!






 工商網監(jiān)
工商網監(jiān)
評論