 Net5.5G智能云網即將全面發布,打造新一代數字基礎設施
Net5.5G智能云網即將全面發布,打造新一代數字基礎設施
中科大團隊開發首個通用的大語言模型分子交互學習框架,在多個數據集超 4,000,000 個分子對上驗證了其可靠性。
簡述
分子關系學習(Molecular Relational Learning)旨在理解和建模分子對的交互作用,如分子對交互(Drug-drug Interaction,DDI)、溶液-溶劑交互(Solution-solvent Interaction)。近來,憑借豐富的知識儲備和優秀的推演能力,大型語言模型(LLMs)已成為實現分子關系高效學習的重要工具。
盡管這一方法頗有成效,但當前范式的主要問題是數據利用的不充分。如下圖(a)所示,當前范式主要依賴于文本數據(如 SMILES),未能充分且顯式地利用分子圖中固有的豐富結構信息。
加劇這一問題的是統一學習框架的缺失,因為其阻礙了從各個數據集中學習到的關鍵交互信息與底層交互邏輯的高效共享和整合。如下圖 b 所示,這一缺失擴大了數據利用的不充分的影響,使得 LLMs 因高度過擬合的風險而無法建模那些廣泛存在的、數據量較少的分子交互任務。
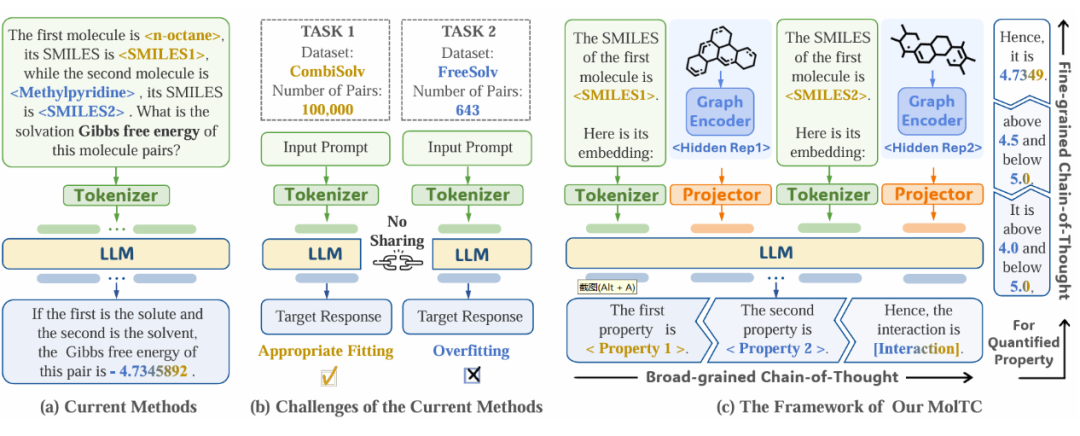
▲ 圖1:當前基于 LLMs 的分子交互學習范式與 MolTC 的比較。(a)現行方法的通用范式;(b)將當前范式應用于樣本量較少的任務時所帶來的挑戰;(c)我們的 MolTC 的架構。
為了緩解這一問題,我們提出了一個通用的、基于 LLM 的多模態分子交互學習框架,MolTC(Molecular inTeraction Modeling enhanced by Chain-of-thought theory)。如上圖 c 所示,MolTC 通過圖編碼器(Encoder)和映射器(Projector)高效地建模分子圖信息,并創新性地提出了多層級思維鏈(Multi-hierarchical Chain-of-thought)的概念來引導訓練范式的優化。
此外,為了加強數據間的信息共享,我們為其設計了一個新穎的動態參數共享策略,以實現效率和精度的雙贏。同時,鑒于這一領域數據集的缺失,我們還構建了一個全面的分子交互指令數據集,MoT-instructions,用于提高當前基于 LLMs 的學習框架(包擴我們的 MolTC)對分子交互任務的理解能力。
我們在涉及超過 4,000,000 個分子對的十二個不同領域數據集上進行了驗證實驗。結果表明,我們的方法優于當前基于 GNN 的、基于(除 GNN 外)其它傳統深度學習架構的、和基于 LLMs 的基線方法。
多模態輸入框架
我們首先簡要介紹上圖 c 中所示的 MolTC 框架。其中,Graph Encoder 采用傳統的圖神經網絡(GNN)架構;Projector 采用在視覺領域常用于多模態對齊的 Querying Transformers (Q-Former)架構,作為 backbone 的 LLM 則是采用在生化任務中表現突出的 Galactica。更多細節勞請移步我們的論文和代碼。
基于多層級思維鏈的訓練范式
我們重點介紹基于多層級思維鏈的 MolTC 訓練范式。首先,考慮到從分子對中直接生成復雜相互作用的挑戰性,處于上層的思維鏈指導 MolTC 的預訓練過程優先識別并按次序輸出輸入分子對中,每個分子的關鍵生化性質,為準確預測它們的交互奠定基礎。具體而言,在預訓練階段,Prompts 的統一設計如下:

預訓練階段的數據來自多個權威的、包含分子-性質對的生化數據庫如 Drugbank 和 PubChem。為了提高 MolTC 在不同分子交互場景下的泛化能力,我們對上述數據庫中的分子進行隨機組合,來構造不同的分子對。
隨后,在微調階段,針對定性分子交互分析任務,Prompts 直接根據特定的下游任務進行定制。而針對傳統 LLMs 較難處理的定量分析任務,下層的思維鏈指導 MolTC 優先為目標數值預估一個大致的范圍,然后逐步將其細化到一個精確的值。以溶液-溶劑交互任務為例,其 Prompts 的設計如下:

動態參數共享策略
為了提高上述訓練范式的效率,MolTC 引入了一種新穎的參數共享策略。具體而言,我們首先考慮分子交互任務的以下關鍵屬性:
(1)交互中分子角色的重要性。例如,在溶液-溶劑交互場景中,水和乙醇互為溶劑會產生不同的能量釋放。某些時候,角色的顛倒甚至會導致交互反應的停滯。
(2)交互中分子順序的重要性。例如,在藥物對交互場景中,藥物引入順序的不同可能會導致不同的治療效果。
(3)分子角色/順序帶來的特征重要性的差異。例如,在發色團-溶液對中,一個化學基團在溶液內會對交互屬性產生關鍵的影響,但其在發色團中時,則可能對交互無足輕重。
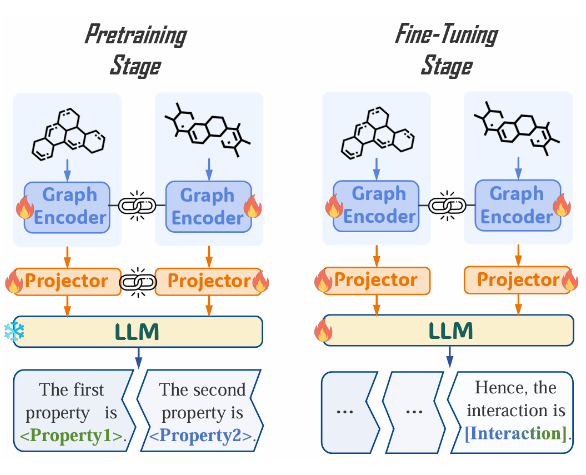
▲ 圖2:應用動態參數共享策略后的的 MolTC 訓練范式。其中,鏈環表示兩個模塊之間的參數共享;雪花表示參數凍結;火焰表示參數更新。
這些屬性自然地啟發 MolTC 適應性地優先考慮倆個分子內的不同信息,即根據角色和順序為分子創建獨特的編碼。具體而言,為了學習到這種差異性,同時維持分子對中學習到的共性信息的共享,我們引入了如下參數共享策略:
(1)考慮 Graph Encoder 專注于提取底層的分子圖結構,并未將語義與分子結構進行對齊,因此,在預訓練和微調階段,MolTC 共享倆個 Graph Encoder 的參數,以增強其學習效率。
(2)考慮 Projector 專注于實現分子結構與語義信息的對齊,因此,在預訓練階段,MolTC 共享倆個 Projector 的參數以提高系統的泛化性和魯棒性;在微調階段,MolTC 終止這一共享,實現根據不同下游任務中的分子角色和順序量身定制的語義映射。
MoT-instruction數據集開發
在 MolTC 的訓練過程中,鑒于當前缺乏一個通用的、為大模型分子關系學習量身定制的指令數據集,我們首先給出這一數據集應當滿足的關鍵性質:(1)它應包含橫跨多個領域的、可以進行交互的大量分子對;(2)它應詳細描述這些分子對中每個分子的重要生化屬性,以及(3)它應根據思維鏈的形式闡述分子對的交互性質。
具體來說,我們通過以下三步構建上述 MoT-instructions 數據集:
(1)我們首先收集多個具有代表性的分子交互數據集,并從 DrugBank 和 PubChem 等權威生化數據庫中獲取這些交互所涉及分子的生化屬性;
(2)隨后,我們進行最優指令確定。具體而言,我們根據訓練 MolTC 得到的預測性能作為指標,來對定量交互 instructions 中的數值區間進行設定。并結合該值的統計數據(如均值和方差)得出最優區間設定和統計數據之間的規律,推廣至更多的定量交互數據集中;
(3)最后,我們將交互涉及的每個屬性單獨抽取至一個獨立的數據空間,以在排除交互屬性中缺失值、模糊值的干擾下,不浪費分子對所提供的其他有用信息。
實驗
為了更全面地評估 MolTC 的有效性,我們將基線算法分為三類:基于 GNN 的、基于其他深度學習模型的以及基于 LLMs 的方法。部分定性和定量的實驗結果如下表所示。更多結果如消融實驗結果煩請移步我們的文章或代碼。
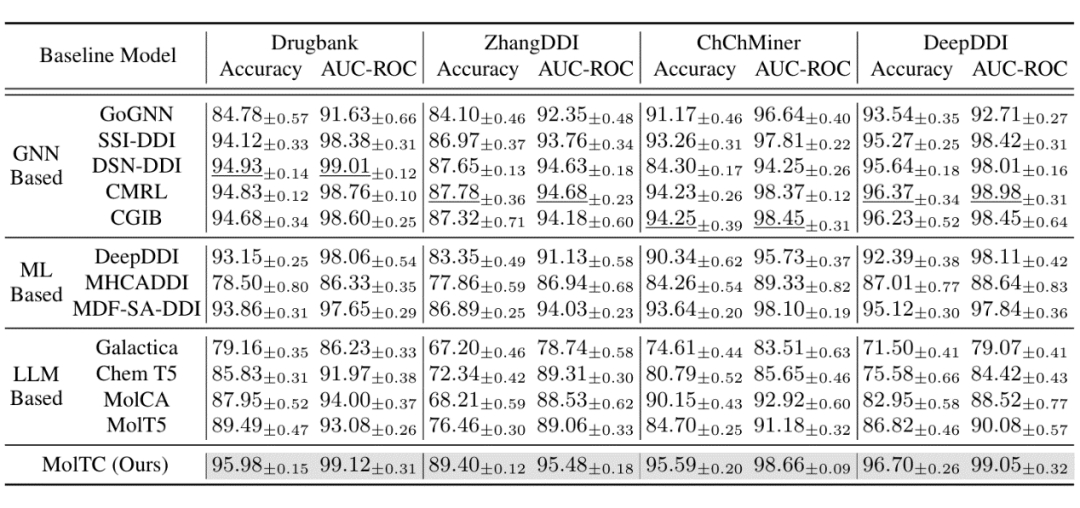
▲ 表1:定性實驗結果(以藥物對交互任務為例)
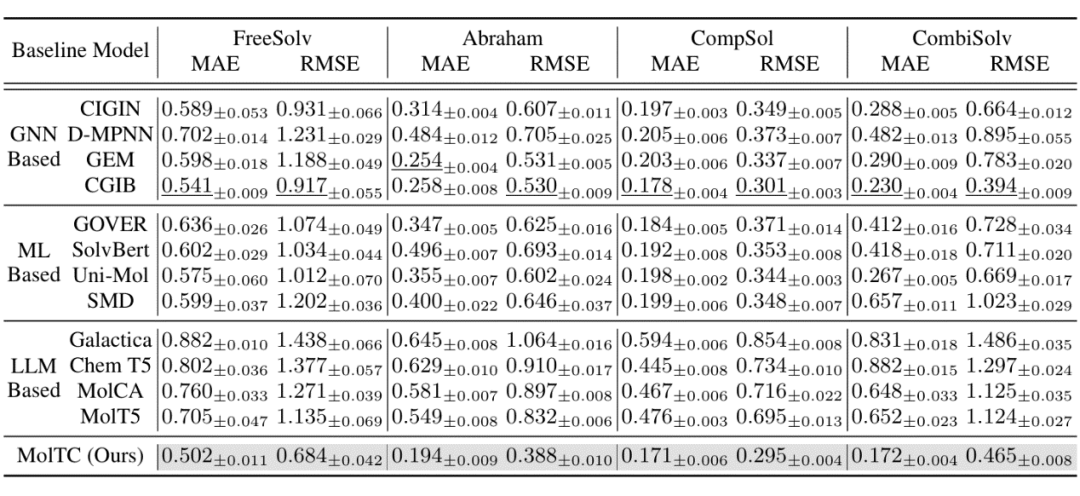
▲ 表2:定量實驗結果(以溶液溶劑交互任務為例)
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3645瀏覽量
134625 -
語言模型
+關注
關注
0文章
527瀏覽量
10281 -
GNN
+關注
關注
1文章
31瀏覽量
6354 -
LLM
+關注
關注
0文章
289瀏覽量
351
原文標題:MWC 2024 | 倒計時1天!Net5.5G智能云網即將全面發布,打造新一代數字基礎設施
文章出處:【微信號:Huawei_Fixed,微信公眾號:華為數據通信】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

Net5.5G智能IP網絡峰會成功舉辦,全球Net5.5G加速商用部署

華為亮相Net5.5G智能IP網絡峰會

華為發布Net5.5G時代《IP自動駕駛網絡白皮書》
南非MTN與華為簽署Net5.5G戰略合作MoU

深圳工信局與華為簽署戰略協議,打造下一代互聯網Net5.5G標桿城市

深圳工信局與華為簽署打造下一代互聯網Net5.5G標桿城市協議







 工商網監
工商網監
評論