 英偉達和AMD新芯片,突破PCIe限制
英偉達和AMD新芯片,突破PCIe限制
學過微處理器的同學可能還記得,最初的8086/8088處理器沒有浮點單元。主板通常有一個額外的插槽,用于可選的8087 數學協處理器。數學協處理器進入了 CPU 本身,如今,CPU 沒有可選的數學協處理器。
然而, SIMD 處理器(例如GPU)有多種選擇。眾所周知,GPU 可以比 CPU 主機更快地加速數學處理(例如矩陣運算)。
隨著Nvidia GH-200 處理器 和AMD MI300A APU的推出,市場正在見證“8087 時刻”——即 CPU 吸收外部性能硬件。Nvidia 和 AMD 都已將 GPU 納入處理器中,其結果是 HPC 性能大幅躍升,并預示著未來的發展。
再見 PCI
AMD 和 Nvidia 的 GPU 都依賴 PCI 總線與 CPU 進行通信。CPU 和 GPU 有兩個不同的內存域,數據必須通過 PCI 接口從 CPU 域移動到 GPU 域(并返回)。
使用第 5 代 PCIe 總線中全部 16 個通道的 GPU 的最大帶寬約為 63GB/s。此瓶頸將限制 CPU 和 GPU 之間的內存移動。
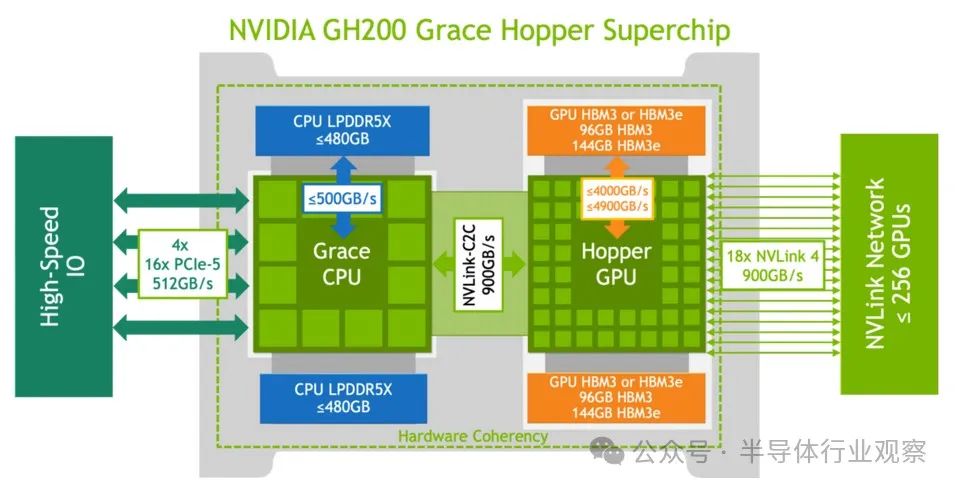
Nvidia GH200 通過 900 GB/s 雙向 NVLink-C2C 連接 Grace CPU 和 Hooper GPU。結果大約快了 14 倍。此外,GH200 還帶來了單一共享 CPU-GPU 內存域的優勢。無需通過 PCI 總線在 CPU 和 GPU 之間移動數據。如圖 1 所示,CPU 和 GPU 對所有內存具有一致的視圖。CPU內存高達480GB LPDDR5X(帶ECC),GPU具有96GB HBM3或144GB HBM3e。總的相干(單域)內存在 576GB 到 624GB 之間。
當前的 AMD Instinct MI300A APU 中采用單一內存域,具有 128 GB HBM3 內存,使用 Infinity Fabric 在 CPU 和 GPU 之間一致共享,封裝峰值吞吐量為 5.3 TB/s 。 雖然 MI300A 目前不支持像 GH200 那樣額外的 DDR 內存擴展,但 CXL 是一個值得將來記住的詞。
對于 GH200 和 MI300A,關鍵的突出短語是“呈現單個存儲域”。在傳統的CPU-PCIe-GPU組合中,GPU內存量通常小于CPU內存,數據必須通過PCIe接口進行混洗。這兩個新設計消除了這個瓶頸。單個大內存域一直對 HPC 有吸引力,而 GenAI 的增長加速了這種需求(即,能夠在內存中加載大型模型并使用 GPU 運行它們)。對于傳統 GPU,GPU 內存量限制了模型大小,需要采用分布式 GPU 方法。(注:GH200 可以通過外部 NVLink 連接,創建海量統一內存;例如,Nvidia-AWS NLV32可以提供高達 20 TB 的統一內存。)
離你的桌面并不遠
技術領域明顯的趨勢之一是從昂貴的新技術市場轉向低成本的大宗商品市場。高性能計算也不例外。隨著市場需求,從多核到高級內存的一切都已從高端轉移到“手機”。遷移到單個內存域就是這些變化之一。
最近,在 Linux 基準測試網站Phoronix上,杰出的測試員Michael Larabel在 GH200 工作站上運行了 HPC 基準測試。該系統由德國的GPTshop.ai提供。
據了解,系統塔式機箱配備 GH200 Grace Hopper Superchip,配備 576G 內存、雙 2000+ W 電源、QCT 主板以及多種配置選項,包括 SSD 和 NVIDIA Bluefield/Connect-X 適配器。一項有趣且有用的功能是 TDP 可以從 450W 編程到 1000W(CPU + GPU + 內存),這在非數據中心環境中應該很有用。另外,默認風冷噪音據稱為25分貝。液體冷卻也是一種選擇。
然而,桌面超級工作站并不便宜。目前可用的型號 GH200 576GB起價為 47,500 歐元(根據 Phoronix 的說法,由于在歐盟以外地區運輸時無需繳納 19% 的增值稅,因此該價格相當于 41,000 美元)
這個價格可能看起來很高,但考慮到具有 80 GB HBM2e 內存的 Nvidia H100 PCIe GPU 目前的市場價格在 3 萬美元到 3.5 萬美元之間。這不包括為 GPU 供電和運行的主機系統。此外,用戶還受到 80GB GPU 內存的限制,該內存通過 PCIe 總線與主內存域分開。
GPTshop工作站提供576GB的單域內存。HPC 和 GenAI 用戶會發現這半 TB 的 CPU-GPU 內存很有吸引力。
初步基準
借助 GPTshop,Phoronix 能夠遠程運行多個基準測試。基準應被視為初步的,而不是最終的績效衡量標準。特別是,基準測試僅針對 CPU,沒有使用 Hopper A100 GPU。因此,基準圖是不完整的。Phoronix 計劃在未來測試基于 GPU 的應用程序。
據 Phoronix 稱,Ubuntu 23.10 與 Linux 6.5 一起使用 GCC-13 作為標準編譯器。使用類似的環境來測試可比較的處理器,包括 Intel Xeon Scalable、AMD EPYC 和 Ampere Altra Max 處理器。完整的列表可以在Phoronix 網站上找到。
此外,沒有可用于基準測試運行的功耗數據。據 Phoronix 稱,NVIDIA GH200 目前似乎沒有在 Linux 下公開任何 RAPL/PowerCap/HWMON 接口,僅用于讀取 GH200 的功率/能源使用情況。系統上的BMC確實通過Web界面暴露了整個系統的功耗,并且功率數據沒有通過IPMI暴露。
盡管存在這些限制,一些重要的基準測試還是首次在 Nvidia 之外的 GH200 上運行。
好奧萊 HPCG
Phoronix 報告的第一個測試是標準HPCG內存帶寬基準測試,如圖 2 所示。
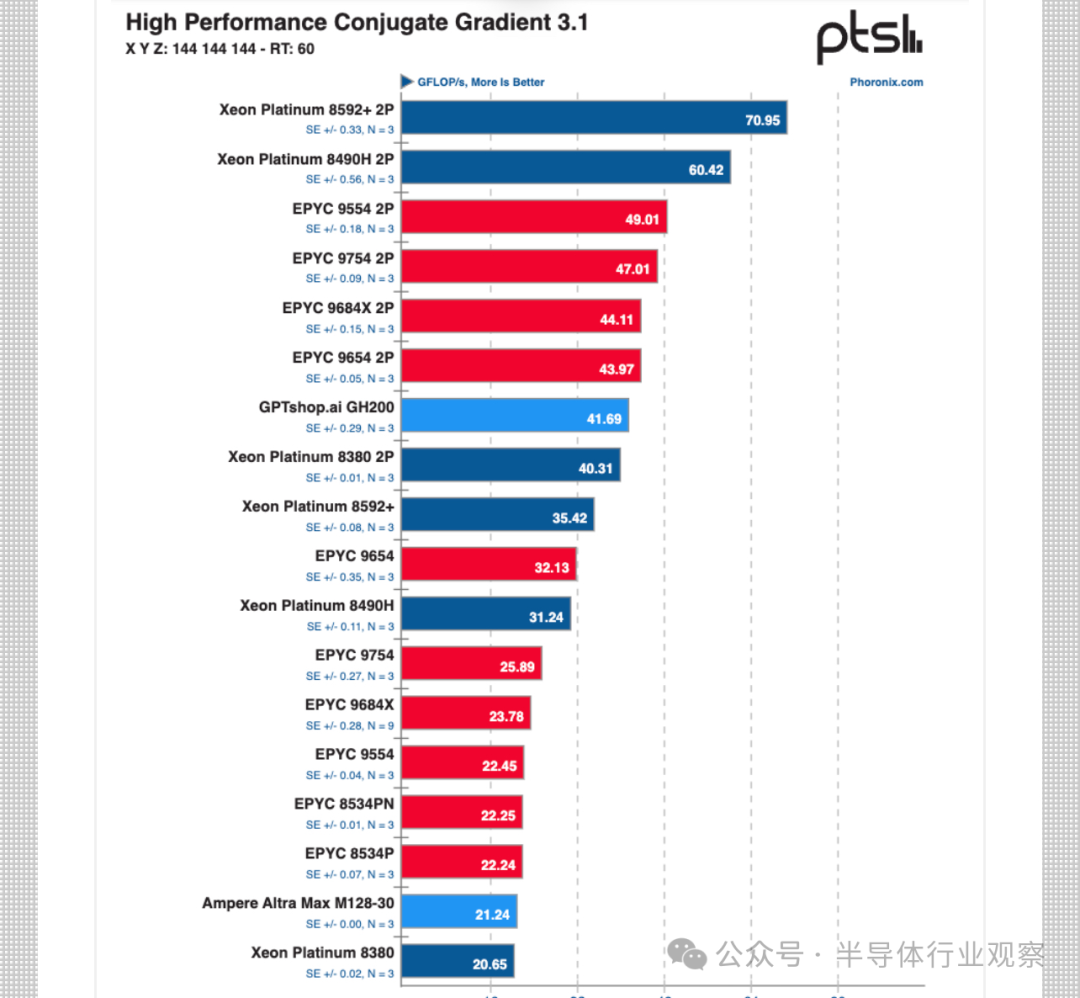
可以看出,GH200 Arm 的性能達到了可觀的 42 GFLOPS,略高于 Xeon Platinum 8380 2P(40 GFLOPS),略低于 EPYC 9654 Genoa 2P(44 GFLOPS)。另外值得注意的是 72 核 Arm Grace CPU,其性能幾乎是 Ampere Altra Max 128 核 Arm 處理器的兩倍。
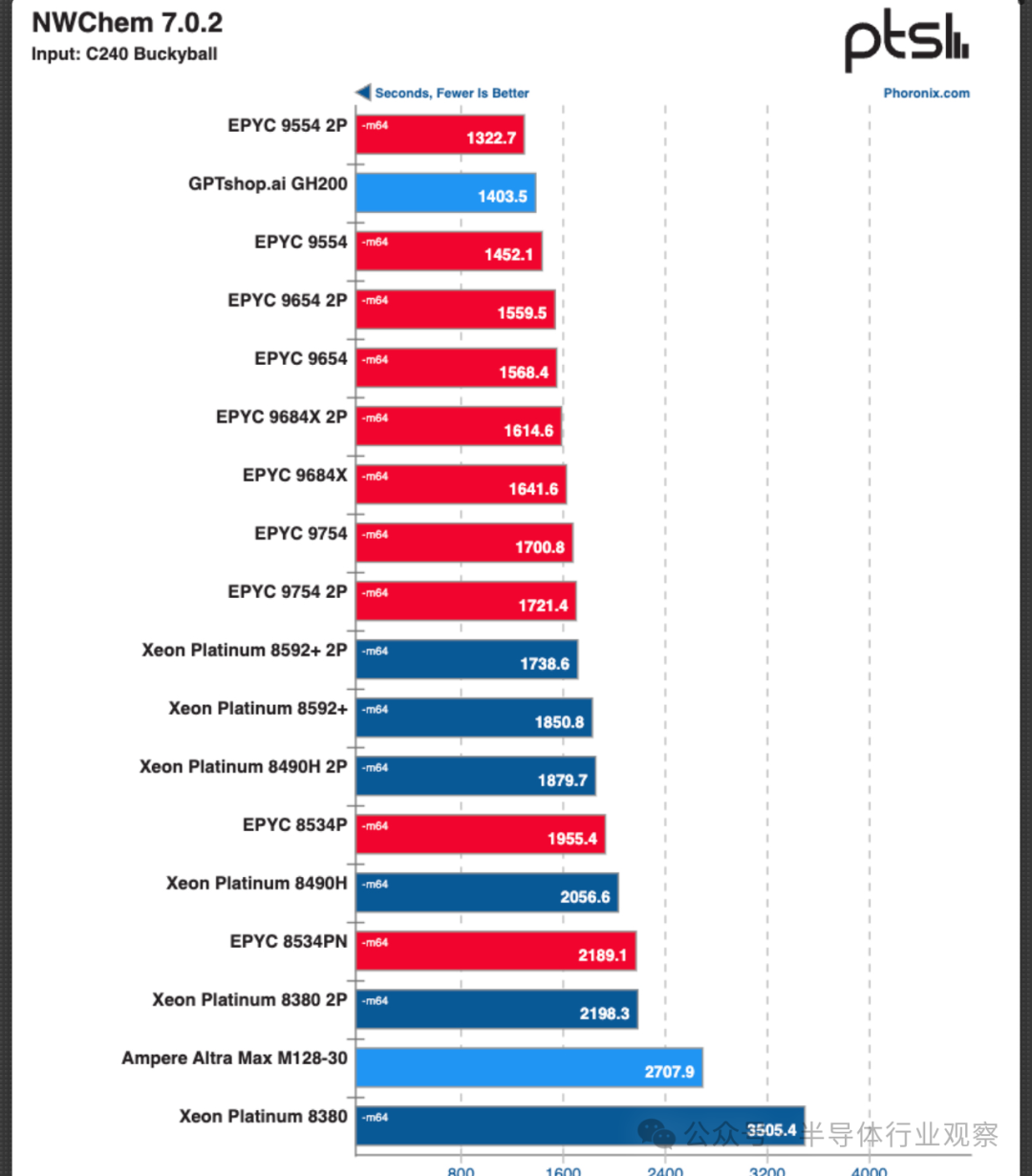
GH200 在其他基準測試中表現良好。最令人印象深刻的結果如圖 3 所示。使用 72 核 Arm GH200 的NWChem (C240-Bucky Ball) 運行時間為 1404 秒,僅落后于領先者 128 核 Epyc 9554 (2p),成績為 1323 秒。
即將發生的事情
Nvidia GH200 和 AMD MI300A 引入了新的處理器架構。與吸收 8087 數學協處理器類似,高端 CPU 也開始吸收 GPU(或 SIMD 處理單元)。然而,這個想法并不是全新的。自 2011 年以來,AMD 已將中等 GPU 集成到其臺式機/筆記本電腦APU 處理器中。雖然這些高端處理器可能被認為是“專用”的,因此價格昂貴,但隨著時間的推移,對 GenAI 的巨大興趣可能會將這些設計推向商品價格點。隨著更多基準的出現,這個故事將繼續發展。
此外,引入具有足夠內存的個人高性能工作站,可以在您的辦公桌旁運行一些最大的法學碩士,這是一個重要的里程碑。更不用說運行許多大內存 GPU 優化的 HPC 應用程序的能力了。數據中心和云仍將是當今的主力,但必須要說的是“擁有重置按鈕”。
-
微處理器
+關注
關注
11文章
2263瀏覽量
82453 -
PCIe
+關注
關注
15文章
1239瀏覽量
82655 -
英偉達
+關注
關注
22文章
3776瀏覽量
91104 -
AMD芯片
+關注
關注
0文章
14瀏覽量
2823
原文標題:英偉達和AMD新芯片,突破PCIe限制
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論