") 以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載案例(六)
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載案例(六)
消除或減少無損以太網(wǎng)網(wǎng)絡(luò)擁塞的高級方法與光纖通道結(jié)構(gòu)相同。幾十年來,不同的傳輸類型都采用了類似的方法,只是略有不同。第6 章已詳細介紹了在光纖通道Fabric 中防止擁塞的方法。由于逐跳流量控制在兩種網(wǎng)絡(luò)中都會導(dǎo)致?lián)砣麛U散,因此盡管在實現(xiàn)上存在差異,但相同的概念也適用于無損以太網(wǎng)網(wǎng)絡(luò)。
Eliminating or Reducing Congestion — An Overview
回想一下,"罪魁禍首"是指造成存儲網(wǎng)絡(luò)擁塞的任何設(shè)備。受害者是受網(wǎng)絡(luò)擁塞不利影響的任何設(shè)備。
為了讓存儲網(wǎng)絡(luò)在發(fā)生擁塞時自動消除或減少擁塞,以下是高級方法:
斷開故障設(shè)備:斷開慢速設(shè)備的連接可消除擁塞源,從而恢復(fù)網(wǎng)絡(luò)擁塞。這通常需要監(jiān)控來自終端設(shè)備的入口暫停幀,并在邊緣交換端口長時間(如幾百毫秒)無法傳輸時禁用(或關(guān)閉)該端口。目前,許多生產(chǎn)網(wǎng)絡(luò)都采用這種方法,但這是一種"大錘"方法,因為斷開連接的設(shè)備無法實現(xiàn)其目的,也無法對其進行監(jiān)控以了解問題是否繼續(xù)存在。請參閱第6 章"通過斷開罪魁禍首設(shè)備的連接來恢復(fù)擁塞"一節(jié),了解更多注意事項以及必要時如何斷開連接。
提前丟棄幀:丟棄幀可釋放緩沖區(qū),使其可重新使用,從而恢復(fù)擁塞狀態(tài)。后面的章節(jié)將使用Cisco Nexus 9000 交換機上的暫停幀超時和PFC 看門狗功能解釋這種方法。
流量隔離:將流向罪魁禍首設(shè)備的流量與其他流量隔離,可以避免擁塞對其他設(shè)備的影響。可以通過創(chuàng)建多個VLAN 并將ISL 專用于VLAN 來隔離流量。另一種方法是創(chuàng)建多個無損類,并將流量分配給不同的類。在撰寫本文時,這些方法在無損以太網(wǎng)網(wǎng)絡(luò)中的使用情況尚不清楚。如果您想在無損以太網(wǎng)網(wǎng)絡(luò)中嘗試使用類似方法,請參閱第6 章"流量隔離"一節(jié),了解更多詳情。
通知終端設(shè)備擁塞情況:向終端設(shè)備發(fā)出擁塞通知可使其采取預(yù)防措施,如降低流量速率。本章將介紹在路由無損以太網(wǎng)網(wǎng)絡(luò)上使用顯式擁塞通知(ECN) 進行RoCEv2 擁塞管理(RCM)。IEEE 802.1Qau 標準化了第2 層域內(nèi)的類似方法,后來又將其納入IEEE 802.1Q。這種方法在RoCEv1(非路由)和FCoE 網(wǎng)絡(luò)中可能很有用,但在撰寫本文時,這種方法的實施并不常見,而且在未來發(fā)展的可能性也很小。因此,本章不對第2 層域內(nèi)的IEEE 802.1Qau 擁塞通知進行解釋。
限制流向擁塞設(shè)備的流量:限制流向慢速設(shè)備或過度使用鏈路的流量可以消除擁塞。
可在終端設(shè)備上配置流量速率限制器。在撰寫本文時,這種方法在無損以太網(wǎng)網(wǎng)絡(luò)中的應(yīng)用尚不清楚。當(dāng)有了這種實施方法后,第6 章"在存儲陣列上使用速率限制器防止擁塞"一節(jié)中的詳細信息也將適用于無損以太網(wǎng)網(wǎng)絡(luò)。
另外,網(wǎng)絡(luò)交換機還可以檢測擁塞情況,并動態(tài)調(diào)整流量速率,使其適應(yīng)擁塞設(shè)備。Cisco MDS 交換機使用這種動態(tài)入口速率限制(DIRL)方法來防止光纖通道結(jié)構(gòu)中的擁塞。雖然從理論上講,DIRL 也可以在無損以太網(wǎng)網(wǎng)絡(luò)中使用,但在本文撰寫時還沒有實現(xiàn)。有關(guān)詳細信息,請參閱第6 章"使用動態(tài)入口速率限制防止擁塞"一節(jié)。
重新設(shè)計網(wǎng)絡(luò):重新設(shè)計網(wǎng)絡(luò)可以消除或降低擁塞的嚴重程度或蔓延范圍。例如,將擁有數(shù)千臺設(shè)備的大型網(wǎng)絡(luò)轉(zhuǎn)換為較小的網(wǎng)絡(luò)孤島,可限制故障設(shè)備僅在孤島內(nèi)產(chǎn)生影響。有關(guān)詳細信息,請參閱第6 章"網(wǎng)絡(luò)設(shè)計注意事項"部分。
升級:很多時候,升級故障設(shè)備是解決擁塞的最終辦法。例如,當(dāng)鏈路使用率很高(可能因使用率過高而導(dǎo)致?lián)砣r,最終的解決方案是提高鏈路速度或增加額外的鏈路。詳情請參閱第6 章"鏈路容量"一節(jié)。
Congestion Recovery by Dropping Frames
在擁塞期間,幀在交換機中停留的時間比典型的端口到端口交換延遲時間要長得多。當(dāng)故障設(shè)備長時間無法接收幀時,與其讓幀永遠停留在交換機內(nèi),不如在超時后丟棄幀。丟棄這些幀后,緩沖區(qū)就可以重新使用,從而有助于從擁塞中恢復(fù)。丟棄這些幀至少有兩種方法。
Dropping Frames Based on their Age in the Switch
使用這種方法進行擁塞恢復(fù)時,如果幀在超時持續(xù)時間內(nèi)沒有離開出口端口,交換機就會丟棄該幀。
Cisco MDS 交換機的FCoE 端口可采用這種方法。可以使用MDS NX-OS 命令system timeout fcoe pause-drop 進行配置。這與光纖通道端口的擁塞-中斷超時類似。有關(guān)其優(yōu)缺點,請參閱第6 章"根據(jù)幀在交換機中的時間丟棄幀"一節(jié)。
Dropping the Frames based on Slow-Drain on an Edge Port
使用這種方法進行擁塞恢復(fù)時,交換機會丟棄發(fā)送到慢速設(shè)備的幀。通常,這種方法需要監(jiān)控邊緣交換端口因接收到連接設(shè)備的暫停幀而無法傳輸?shù)某掷m(xù)時間。如果該持續(xù)時間超過超時時間,則會丟棄前往該設(shè)備的幀。當(dāng)幀被丟棄時,緩沖區(qū)利用率最終會低于接收流量的端口的恢復(fù)閾值,這些流量將從與慢耗設(shè)備相連的端口發(fā)送出去。因此,交換機會停止向上游直接連接的設(shè)備發(fā)送暫停幀,允許其開始傳輸。罪魁禍首設(shè)備的流量可能仍然會被丟棄,但受害者可能會從中受益。
從理論上講,這種方法類似于Cisco MDS 交換機上光纖通道端口的無credit-drop 超時功能。有關(guān)受害設(shè)備如何從中受益的詳細解釋,請參閱第6 章"基于邊緣端口的慢排空丟棄幀"一節(jié)。本節(jié)不再重復(fù)所有這些細節(jié)。
無損以太網(wǎng)交換機上丟棄幀的實現(xiàn)方式(何時開始丟棄、何時停止丟棄以及粒度)各不相同。本節(jié)將介紹基于這種方法的兩種實現(xiàn)方式。
1. 暫停超時:針對FCoE 流量。
2. PFC 看門狗:主要針對RoCEv2 流量,但任何無損以太網(wǎng)流量(包括FCoE)都可能從中受益。
Pause Timeout
使用暫停超時功能,如果端口在超時時間內(nèi)因接收到暫停幀而無法傳輸,則會丟棄所有出口流量。此外,只要該端口一直處于Rx 暫停狀態(tài),交換機上其他端口上所有新到達的、注定要從該端口出去的幀都會被立即丟棄。如前所述,丟棄邊緣端口上的罪魁禍首流量可讓上游設(shè)備開始傳輸,從而使受害設(shè)備擺脫擁塞影響。
請注意以下幾點:
1. 在撰寫本文時,暫停超時僅適用于思科交換機上的FCoE 端口,但在不同平臺上的實施有所不同,下文將對此進行說明。
2.盡管使用了PFC,但暫停超時功能會丟棄端口上的所有流量,而不僅僅是FCoE 使用的無損類中的流量。如果端口專門用于無損類流量,如Cisco MDS 交換機上的FCoE 端口,那么這種行為是可以接受的。但如果端口承載的流量屬于無損類和其他類,則這種行為可能不可接受。
該功能的具體實現(xiàn)可能因交換機類型而異。例如:
1. Cisco MDS 交換機:對于Cisco MDS 交換機上的FCoE 端口,該功能稱為Pause-Drop超時,默認為500 ms。如有需要,可使用MDS NX-OS 命令system timeout fcoe pause-drop 進行更改。
2. Cisco Nexus 交換機:對于Cisco Nexus 交換機上的FCoE 端口,該功能稱為"暫停超時",默認情況下已禁用。使用NX-OS 命令系統(tǒng)默認接口暫停模式邊緣啟用時,超時值為500ms。可以使用命令system default interface pause timeout
3. 思科UCS:在Cisco UCS 服務(wù)器中,可通過慢耗計時器啟用此功能。默認超時值為500 毫秒,可在100 毫秒至1000 毫秒之間以100 毫秒為增量進行自定義。在早期版本的Cisco UCS Manager 中,該功能默認啟用500 毫秒超時值。后續(xù)版本默認禁用此功能并啟用PFC 看門狗。有關(guān)詳細信息,請參閱Cisco UCS Manager 發(fā)行說明。
PFC Watchdog
PFC 進程看門狗的工作原理與暫停超時類似,但它只會丟棄隊列中因收到PFC 暫停幀而無法在超時時間內(nèi)連續(xù)傳輸?shù)牧髁俊?/p>
根據(jù)實施情況,PFC 看門狗可觸發(fā)以下操作:
1. 端口翻轉(zhuǎn)或關(guān)閉:當(dāng)檢測到隊列上存在PFC 進程看門狗時,端口將被翻轉(zhuǎn)或關(guān)閉,從而影響該端口上的所有流量類別。這與暫停超時功能的作用相同。有人稱其為破壞性看門狗。
2. 僅警報:當(dāng)檢測到PFC 看門狗時,它會生成警報(如Syslog),但不會采取任何進一步措施來丟棄流量。有人稱其為日志看門狗。
3. 關(guān)閉隊列:這是本文撰寫時最常見的實現(xiàn)方式。當(dāng)檢測到PFC 看門狗處于無損隊列中時,將采取以下操作:
a. 該隊列中的所有幀都會被丟棄。
b. 只要該隊列仍處于Rx Pause(接收暫停)狀態(tài),該交換機其他端口上所有新到達的、注定要從該隊列流出的幀都會被立即丟棄。
c. 該端口上屬于相同流量類別(如出口無損類別)的所有入口流量也會被丟棄。所有入口暫停幀也會被丟棄。這是PFC 看門狗的獨特區(qū)別。請注意,暫停超時(在Cisco MDS、Nexus 和UCS 的FCoE 端口上可用)和無損信元超時(在Cisco MDS 交換機的FC 端口上可用)不會影響端口上的入口流量。這些功能無損入口流量的理由是,擁塞是定向的,因此反向流量不應(yīng)受到影響。與此相反,PFC 看門狗拒絕接收入口流量的理由是,在慢排空設(shè)備上運行的應(yīng)用程序不會因為單向流量(慢排空設(shè)備的出口流量與啟用了PFC 看門狗的交換端口的入口流量相同)而受益。事實上,如前面"I/O 操作、流量模式和網(wǎng)絡(luò)擁塞的相關(guān)性"一節(jié)所述,慢排空設(shè)備的出口流量可能會增加擁塞的持續(xù)時間和嚴重程度。
PFC 看門狗功能的具體實現(xiàn)可能因開關(guān)類型而異。例如:
1. Cisco MDS 交換機:在撰寫本文時,Cisco MDS 交換機上不提供PFC 看門狗功能。使用暫停超時功能是一種有效的替代方法,因為MDS 交換機只對FCoE 流量使用單一的無損類。
2. Cisco Nexus 交換機:Cisco Nexus 9000 和Nexus 3000 交換機上提供PFC 看門狗功能。支持和操作(端口翻轉(zhuǎn)、僅警報、隊列關(guān)閉)取決于型號類型和NX-OS 版本。有關(guān)最新信息,請參閱發(fā)布說明。
3. 思科UCS:Cisco UCS 服務(wù)器在4.2 版以后的UCS 管理器中支持PFC 看門狗。暫停超時和PFC 進程監(jiān)控相互排斥。在以后的版本中,PFC 看門狗默認已啟用。
以下是NX-OS 10.3(1) 中Cisco Nexus 9000 交換機上PFC 看門狗的配置詳情。
1. 使用NX-OS 命令priority-flow-control watch-dog-interval
2. 該命令允許軟件進程每隔一段時間輪詢一次禁丟隊列。默認情況下,輪詢間隔為100 毫秒。要更改輪詢間隔,請使用NX-OS 命令priority-flow-control watch-dog interval <100 - 1000>,在100 ms 和1000 ms 之間以100 ms 為增量。
3. 隊列關(guān)閉的快慢取決于shutdown-multiplier。默認情況下,其值為1,可使用NX-OS 命令priority-flow-control watch-dog shutdown-multiplier <1 - 10> 更改。無損隊列的關(guān)閉時間為(看門狗間隔x 關(guān)閉乘數(shù))。因此,默認情況下,隊列會在Rx 暫停狀態(tài)持續(xù)100 毫秒時關(guān)閉。當(dāng)關(guān)閉乘數(shù)為2 時,隊列將在200 毫秒時關(guān)閉,依此類推。
4. 隊列處于關(guān)閉狀態(tài)后,可以使用NX-OS 命令priority-flow-control recover interface
5. 另外,還可以使用兩種方案自動恢復(fù)隊列。
a. 固定恢復(fù)倍增器在(看門狗間隔x 固定恢復(fù)倍增器)之后恢復(fù)隊列,而與Rx 暫停無關(guān)。換句話說,即使設(shè)備仍然是慢耗空設(shè)備,隊列也會恢復(fù)。固定恢復(fù)乘數(shù)默認為禁用(值為0)。可以使用NX-OS 命令priority-flow-control fixed-restore multiplier <0 - 100> 啟用它。
b. 只有在該隊列連續(xù)(看門狗間隔x 自動恢復(fù)乘數(shù))未收到Rx Pause 后,自動恢復(fù)乘數(shù)才會恢復(fù)隊列。換句話說,只有在設(shè)備停止造成慢排空"之后",隊列才會恢復(fù)。自動恢復(fù)的默認值為10,可以使用NX-OS 命令priority-flow-control auto-restore multiplier <0 - 100> 進行更改。
考慮一臺設(shè)備,該設(shè)備在時間= T1 時開始造成慢排空。其連接的交換端口配置了PFC 看門狗,時間間隔為100ms,關(guān)機倍率為1,自動恢復(fù)倍率為10。設(shè)備連續(xù)發(fā)送暫停幀,從而停止所連接交換端口上的傳輸。當(dāng)交換端口在100 毫秒內(nèi)無法連續(xù)傳輸時,它會關(guān)閉隊列,從而丟棄隊列中的所有數(shù)據(jù)包,并執(zhí)行前面描述的其他操作。這發(fā)生在T1 + 100ms 時。時間= T2 時,設(shè)備停止發(fā)送PFC 暫停幀。如果交換端口在最后1 秒內(nèi)沒有收到該免丟包類的PFC 暫停幀,隊列將自動恢復(fù)。
如例7-12 所示,要驗證Cisco Nexus 9000 交換機上的PFC 進程看門狗配置和隊列的當(dāng)前狀態(tài),請使用NX-OS 命令show queuing pfc-queue。如圖所示,以太網(wǎng)1/3 和以太網(wǎng)1/5 啟用了PFC 進程監(jiān)視。如VL bmap 所示,兩個接口上的CoS 1 流量都啟用了PFC。只有在以太網(wǎng)1/5 上,分配給CoS 1 流量的無損隊列處于關(guān)閉狀態(tài)。
Example 7-12Verifying PFC watchdog on Cisco Nexus 9000 switches
switch# show queuing pfc-queue
+----------------------------------------------------+
Global watch-dog interval [Enabled]
+----------------------------------------------------+
+----------------------------------------------------+
Global PFC watchdog configuration details
PFC watch-dog poll interval : 100 ms
PFC watch-dog shutdown multiplier : 1
PFC watch-dog auto-restore multiplier : 10
PFC watch-dog fixed-restore multiplier : 0
PFC watchdog internal-interface multiplier : 2
+----------------------------------------------------+
+-------------------------------------------------------------+
| Port PFC Watchdog (VL bmap) State (Shutdown) |
+-------------------------------------------------------------+
Ethernet1/1 Disabled ( 0x0 ) - - - - - - - -
Ethernet1/2 Disabled ( 0x0 ) - - - - - - - -
Ethernet1/3 Enabled ( 0x2 ) - - - - - - N -
Ethernet1/4 Disabled ( 0x0 ) - - - - - - - -
Ethernet1/5 Enabled ( 0x2 ) - - - - - - Y -
Ethernet1/6 Disabled ( 0x0 ) - - - - - - - -
使用NX-OS 命令show queuing pfc-queue interface(顯示隊列pfc-queue 接口)查找PFC 進程看門狗導(dǎo)致的數(shù)據(jù)包丟棄統(tǒng)計。例7-13 顯示了該命令的輸出。按以下方式解釋Stats 列:
1.關(guān)閉:分配給QoS 組1 (CoS 1) 流量的隊列被關(guān)閉的次數(shù)。
2.恢復(fù):分配給QoS 組1 (CoS 1) 流量的隊列被恢復(fù)的次數(shù)。
3.已排空的數(shù)據(jù)包總數(shù):上次關(guān)閉隊列時隊列中已丟棄的數(shù)據(jù)包數(shù)量。
4.丟棄的總數(shù)據(jù)包數(shù):上次關(guān)閉隊列后,交換機上其他端口到達Eth1/5 上試圖通過此隊列退出并被丟棄的數(shù)據(jù)包數(shù)量。
5.排空的總件數(shù)+ 丟失的總件數(shù):排空的數(shù)據(jù)包總數(shù)(3) + 丟失的數(shù)據(jù)包總數(shù)(4)。
6.累計丟失的pkts:這與(4) 相同,但它顯示的是之前多個關(guān)閉/未關(guān)閉實例的總計數(shù)。
7.丟棄的入口數(shù)據(jù)包總數(shù):屬于同一QoS 組1 (CoS 1) 的數(shù)據(jù)包到達Eth 1/5 的入口時被丟棄
8.丟棄的入口pkts 總量:這與(7) 相同,但它顯示的是多個先前關(guān)閉/未關(guān)閉實例的總計數(shù)。
Example 7-13PFC watchdog counters on Cisco Nexus 9000 switches
switch# show queuing pfc-queue interface e1/5 detail
+----------------------------------------------------+
Ethernet1/5 Interface PFC watchdog: [Enabled]
+----------------------------------------------------+
+----------------------------------------------------+
| QOS GROUP 1 [Active] PFC [YES] PFC-COS [1]
+----------------------------------------------------+
| | Stats |
+----------------------------------------------------+
| Shutdown| 4|
| Restored| 4|
| Total pkts drained| 752|
| Total pkts dropped| 2197357321|
| Total pkts drained + dropped| 2197358073|
| Aggregate pkts dropped| 53487546587|
| Total Ingress pkts dropped| 66649|
| Aggregate Ingress pkts dropped| 34987434|
+----------------------------------------------------+
要清除這些計數(shù)器,請使用NX-OS 命令clear queuing pfc-queue。
Cisco Nexus 9000 交換機通過Syslog 消息通知PFC 看門狗隊列關(guān)閉/恢復(fù)操作。例7-14 顯示了隊列關(guān)閉Syslog 消息。
Example 7-14Syslog message when a queue is shut down due to PFC watchdog
2021 Aug 18 1051 N9K %$ VDC-1 %$ %TAHUSD-SLOT1-2-
TAHUSD_SYSLOG_PFCWD_QUEUE_SHUTDOWN: Queue 1 of Ethernet1/5 is shutdown due to PFC
watchdog timer expiring
例7-15 顯示了隊列恢復(fù)Syslog 消息。請注意入口和出口丟棄數(shù)據(jù)包的數(shù)量。
Example 7-15Syslog message when a queue is restored after being shut down by PFC watchdog
2021 Aug 18 1058 N9K %$ VDC-1 %$ %TAHUSD-SLOT1-2-
TAHUSD_SYSLOG_PFCWD_QUEUE_RESTORED: Queue 1 of Ethernet1/5 is restored due to PFC
watchdog timer expiring; 2197358073 egress packets/66649 ingress packets dropped
during the event
The Granularity of Pause Timeout and PFC Watchdog
暫停超時的配置粒度為100 毫秒,與PFC 看門狗間隔相同。這兩個功能都依賴于軟件每100 毫秒輪詢一次。因此,兩者都會將動作和恢復(fù)時間延遲長達99 毫秒。換句話說,PFC看門狗關(guān)機動作可能需要長達199 毫秒,而不是在100 毫秒時準確執(zhí)行。
請參閱第6 章"行動中的無貸記掉線超時"一節(jié)和第3 章"TxWait、Slowport-monitor 和Tx-credit-not-available 之間的差異"一節(jié),了解使用軟件輪詢的結(jié)果和基于ASIC 實現(xiàn)的額外優(yōu)勢。在Cisco MDS 交換機上,光纖通道無credit-drop 超時功能于2015 年轉(zhuǎn)為基于ASIC 的實現(xiàn)。在撰寫本文時,基于ASIC 的暫停超時和PFC 進程看門狗實施尚未推出。
The Benefits and the Limitations
暫停超時和PFC 看門狗會丟棄發(fā)送給慢速設(shè)備的幀,從而釋放緩沖區(qū),使受害設(shè)備擺脫擁塞影響。丟棄幀偏離了無損網(wǎng)絡(luò)的無丟棄行為,但當(dāng)罪魁禍首設(shè)備無法接收幀時,與其永遠等待并讓其他設(shè)備受害,不如丟棄罪魁禍首設(shè)備的幀。由于上述原因,我們建議根據(jù)環(huán)境的可用性和設(shè)備供應(yīng)商推薦的閾值啟用這些功能。
在使用這些方法時,請注意以下限制:
1. 在撰寫本文時,暫停超時和PFC 看門狗的大多數(shù)實現(xiàn)都基于軟件輪詢,這可能會延遲操作并降低恢復(fù)的有效性。請參閱前面的"暫停超時和PFC 看門狗的粒度"部分。
2. 暫停超時和PFC 看門狗有助于從慢排空造成的擁塞中恢復(fù)。如果擁塞是由邊緣鏈路的過度使用造成的,這些方法就無能為力了。
3. 暫停超時和PFC 看門狗的最小粒度為100 毫秒。因此,當(dāng)傳輸停止的時間較短時(如50 毫秒),這些方法就無能為力了。
4. 暫停超時和PFC 看門狗超時僅對連續(xù)停止傳輸?shù)臅r段起作用。即使暫停幀不連續(xù),慢速設(shè)備也會造成嚴重擁塞。
這些限制不應(yīng)妨礙使用暫停超時和PFC 看門狗。但要注意它們能實現(xiàn)什么,不能實現(xiàn)什么。
Congestion Notification in Routed Lossless Ethernet Networks
終端設(shè)備及其應(yīng)用程序可能無法察覺網(wǎng)絡(luò)擁塞。肇事設(shè)備可能會繼續(xù)在網(wǎng)絡(luò)上發(fā)送(或請求)更多流量,使擁塞的嚴重程度惡化或持續(xù)時間延長。為了解決這個問題,網(wǎng)絡(luò)交換機可以在檢測到擁塞時立即"明確"通知終端設(shè)備。作為回應(yīng),肇事設(shè)備可采取預(yù)防措施。
這種通過通知終端設(shè)備來防止擁塞的方法適用于各種網(wǎng)絡(luò),其實施和采用程度各不相同。第6 章"通過通知終端設(shè)備防止擁塞"一節(jié)詳細介紹了在光纖通道Fabric 中使用Fabric Performance Impact Notifications (FPIN) 和Congestion Signals 的實施情況。第8 章"TCP 存儲網(wǎng)絡(luò)中的擁塞通知"一節(jié)介紹了TCP/IP 存儲網(wǎng)絡(luò)中的這種方法。
如前所述,這種方法在FCoE 和RoCE 環(huán)境中的實施和采用并不常見。因此,本節(jié)不對其進行解釋。本節(jié)的重點是RoCEv2 擁塞管理(RCM) 路由無損以太網(wǎng)網(wǎng)絡(luò)中的擁塞通知。
Solution Components
通過通知終端設(shè)備來防止擁塞的方法是否成功取決于以下因素:
1. 擁塞檢測:交換機(稱為擁塞點)必須能夠檢測到擁塞癥狀。
2. 發(fā)送通知:檢測到擁塞后,交換機必須能夠?qū)⑵渫ㄖK端設(shè)備。為此,光纖通道交換機會發(fā)送特殊幀(稱為FPIN)和擁塞信號。相比之下,RoCEv2 和TCP/IP 網(wǎng)絡(luò)通過在報頭中標記特殊位,將此信息編碼到數(shù)據(jù)包中。
3. 接收通知:終端設(shè)備必須能夠理解交換機發(fā)出的通知。這取決于終端設(shè)備的硬件和/或軟件能力。
4. 預(yù)防擁塞行動:在收到網(wǎng)絡(luò)擁塞通知后,終端設(shè)備必須采取預(yù)防措施,如降低速率。這是最重要的組成部分。
以下各節(jié)將使用RoCEv2 擁塞管理(RCM) 對這些組件進行說明。
RoCEv2 Transport Overview
RoCEv2 數(shù)據(jù)包有一個IP 報頭,因此可以使用IPv4 或IPv6 報頭中的DSCP 字段進行分類。請參閱前面的"優(yōu)先級流量控制"一節(jié),了解在路由第3 層網(wǎng)絡(luò)中如何對流量進行分類并將其分配到無損類。第1 章圖1-10 顯示了RoCEv2 數(shù)據(jù)包格式。
為了通知終端設(shè)備擁塞情況,使用了IP 報頭中的"顯式擁塞通知"(ECN)字段。
請注意以下幾點:
1. 通常,以太網(wǎng)VLAN CoS 值會映射到IP 報頭中的DSCP 字段。表7-1 提供了這種映射。
2. 在路由網(wǎng)絡(luò)中,以太網(wǎng)報頭在每一跳都會改變,因此除非另行配置,否則不會保留CoS 值。但IP 報頭中的DSCP 字段在源和目的地之間保持不變。
3. 在不使用VLAN 的網(wǎng)絡(luò)中,使用IP 標頭中的DSCP 字段是對流量進行分類的唯一選擇,因為CoS 是VLAN 標頭的一部分。
4. 重疊網(wǎng)絡(luò)(如虛擬可擴展局域網(wǎng)(VXLAN))通常會在封裝原始數(shù)據(jù)包之前將DSCP 和ECN 值復(fù)制到外部IP 標頭,并將這些值從外部標頭復(fù)制到解封裝數(shù)據(jù)包,因此在使用IP 標頭對流量進行分類時,會保留不丟棄行為和ECN。有關(guān)詳情,請參閱"使用VXLAN 的無損以太網(wǎng)"一節(jié)。
RoCEv2 Congestion Management
交換機檢測到擁塞時,會在IP 報頭的ECN 字段中標記擁塞。目的地接收到帶有ECN 標記的數(shù)據(jù)包后,會將此信息反映給信源,信源會通過限制流量速率做出反應(yīng)。RFC 3168 解釋了使用TCP 作為第4 層協(xié)議的顯式擁塞通知(ECN)。RCM 依賴于相同的機制,但由于RoCEv2 使用的是UDP(而非TCP),因此有一些不同之處,下文將對此進行說明。
請參考圖7-17,它是圖7-8 所解釋的脊葉網(wǎng)絡(luò)的一個子集。以下是概要步驟:
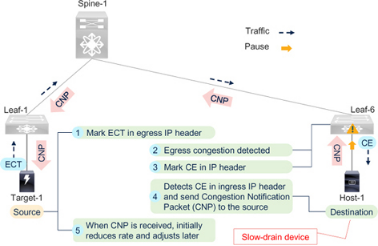
Figure 7-17RoCEv2 Congestion Management (RCM)
1.是否愿意使用RCM:終端設(shè)備(Target-1 和Host-1)支持RCM 時,會在IPv4 或IPv6 標頭中設(shè)置ECN-capable Transport(ECT)標志。ECT 標志在IP 報頭的ECN 字段中用b'01' 或b'10' 設(shè)置。ECN 字段中的b'00' 表示端點不支持ECN,也不支持RCM。
2. 擁塞檢測:當(dāng)隊列利用率超過配置的閾值時,端到端數(shù)據(jù)路徑中的交換機(Leaf-6)會檢測到擁塞。隊列利用率增加的原因是慢排空(出口交換端口上的Rx 暫停)或交換端口利用率過高。
3. 發(fā)送通知:交換機檢測到隊列擁塞時,會在IPv4 或IPv6 報頭中設(shè)置擁塞體驗(CE) 標志。CE 標志在ECN 字段中用b'11' 設(shè)置。擁塞交換端口只為啟用了ECT 標志(b'01' 或b'10')的數(shù)據(jù)包設(shè)置CE 標志。非ECN 功能數(shù)據(jù)包(ECN 值為b'00')將保持不變地轉(zhuǎn)發(fā)。與光纖通道不同,在RoCEv2 網(wǎng)絡(luò)中,交換機不會發(fā)送任何特殊數(shù)據(jù)包(或幀或信號)來通知終端設(shè)備。
4. 接收通知:目的地(主機-1)在收到帶有CE 標志的數(shù)據(jù)包時會檢測到網(wǎng)絡(luò)擁塞。由于CE 標志是標準IP 報頭的一部分,因此主機-1 不需要任何特殊機制來解釋新型數(shù)據(jù)包。但是,它必須能夠檢測到CE 標志并對其采取行動。當(dāng)主機-1 接收到CE 標記數(shù)據(jù)包時,它會向啟用了CE 標記的入口數(shù)據(jù)包的源端(目標-1)發(fā)送擁塞通知數(shù)據(jù)包(CNP),從而向源端反映擁塞情況。由于CNP 是一種特殊的數(shù)據(jù)包,因此目標和源都必須能夠發(fā)送和接收CNP,以及發(fā)送CNP 的頻率、停止發(fā)送的時間和內(nèi)容等其他細節(jié)。此外,還要配置網(wǎng)絡(luò)QoS 策略,以高優(yōu)先級對CNP 進行分類和轉(zhuǎn)發(fā)。
5. 預(yù)防擁塞行動:發(fā)送方(目標-1)收到CNP 后,會降低發(fā)送CNP 的目的地的流量。如前所述,由于CNP 是一種特殊數(shù)據(jù)包,發(fā)送方必須能夠監(jiān)聽并采取行動。此外,在初始降低速率行動后,發(fā)送方必須能夠調(diào)整其速率,以便在未充分利用和過度利用之間達到最佳平衡。
RoCEv2 Congestion Management Considerations
圖7-17 對RCM 進行了過于簡化的解釋。但是,在生產(chǎn)環(huán)境中,成百上千臺設(shè)備可能會以多對一的流量模式連接到同一個Fabric。
本節(jié)介紹了RoCEv2 網(wǎng)絡(luò)的一些重要注意事項。這些注意事項在新建環(huán)境中可能并不明顯,但隨著網(wǎng)絡(luò)的發(fā)展或成熟,應(yīng)了解其局限性并采取積極措施。
請參考圖7-8,并思考圖7-17 所解釋的RCM 如何運行。然后,考慮以下幾點:
1. 混合環(huán)境:根據(jù)RoCEv2 標準,RCM 是可選項。需要特別注意支持RCM 和不支持RCM 終端設(shè)備的混合環(huán)境。當(dāng)許多設(shè)備向同一設(shè)備發(fā)送流量時,如果少數(shù)發(fā)送方不支持RCM,它們的流量不會被CE 標記,而來自其他支持RCM 的設(shè)備的流量則會被CE 標記。因此,慢耗設(shè)備(目的地)只向支持RCM 的設(shè)備發(fā)送CNP。因此,支持RCM 的設(shè)備會降低流量速率,而不支持RCM 的設(shè)備則不會。這種情況可能會導(dǎo)致支持RCM 的設(shè)備流量不足,因為它們可能會不斷降低速率,而不支持RCM 的設(shè)備可能會消耗掉所有鏈路容量。在混合TCP 和UDP 流量的IP 網(wǎng)絡(luò)中,這種情況類似于UDP 流量導(dǎo)致的TCP 饑餓。通常情況下,較新的設(shè)備更有可能支持RCM。如果現(xiàn)有設(shè)備不支持RCM,較新的設(shè)備可能會受到更多懲罰。
2. 速率降低算法:RoCEv2 標準提到,發(fā)送方應(yīng)在收到CNP 后降低流量速率,但沒有解釋速率降低或恢復(fù)的算法。由于缺乏標準方法,供應(yīng)商只能開發(fā)不同的實施方案,在相同的環(huán)境中做出不同的反應(yīng)。用戶只能承受非統(tǒng)一實施的結(jié)果,或被迫鎖定供應(yīng)商以實現(xiàn)統(tǒng)一。
3. 同步:接收CNP 的流量源不知道其他向同一目的地發(fā)送流量的流量源。多個此類源的集體行動可能會導(dǎo)致反應(yīng)過度或反應(yīng)不足。例如,在圖7-8 中,如果每個目標將速率降低5%,則五個目標的集體速率降低行動會導(dǎo)致速率降低25%(反應(yīng)過度)。之后,當(dāng)目標調(diào)整/提高速率時,五個獨立工作的此類設(shè)備可能會再次導(dǎo)致最初的問題,從而引發(fā)最初的擁塞事件。在TCP/IP 網(wǎng)絡(luò)中,這種情況類似于TCP 全局同步。
4. 延遲行動:在某些突發(fā)流量模式的存儲環(huán)境中,RCM(以及其他通過通知終端設(shè)備來防止擁塞的方法)可能無法奏效,因為從檢測到擁塞到采取預(yù)防措施之間存在延遲。在圖7-17 中,Leaf-6 檢測到擁塞,Host-1 接收到CE 標記數(shù)據(jù)包,向源發(fā)送CNP,最后源降低速率。這些步驟在Leaf-6 觀察到變化時都會產(chǎn)生延遲。此時,原來的擁塞癥狀可能會自行消失。引用RFC 3168(這與RCM 使用的機制相同)的一句話:"CE 數(shù)據(jù)包表示持續(xù)性擁塞,而不是瞬時性擁塞,因此收到CE 數(shù)據(jù)包時的反應(yīng)應(yīng)與持續(xù)性擁塞相適應(yīng)"。
5.配置復(fù)雜:RCM 的成功與否取決于其在網(wǎng)絡(luò)中的配置。在交換機上標記CE 標志通常使用加權(quán)隨機早期檢測(WRED) 等檢測方案。有關(guān)詳細信息,請參閱第8 章"主動隊列管理"一節(jié)。應(yīng)配置這些機制的閾值,以便在隊列滿之前在交換機上觀察到降低速率的操作。這些值還取決于交換機的類型,因為不同的交換機有不同的架構(gòu)和緩沖區(qū)容量。在終端設(shè)備上,CNP 的頻率是一個重要的考慮因素。過多的CNP 可能會增加終端設(shè)備的負載,而過少的CNP 可能會延遲終端設(shè)備的操作。此外,速率降低算法也可能存在變數(shù)。
這些問題不應(yīng)妨礙RCM 的啟用。請遵循供應(yīng)商的建議,并根據(jù)您的環(huán)境完善配置。需要記住的重要一點是,不能因為某些東西在較新(新建環(huán)境)中運行良好,就不再需要監(jiān)控擁塞癥狀。
打個比方,新車的輪胎充有氮氣。起初,它們可能幾個月甚至一年都不需要充氣。這些新車工作得非常好,以至于有些司機幾乎忘記了輪胎需要氣壓檢查,結(jié)果導(dǎo)致他們的不太新的汽車爆胎。他們本可以通過每月主動檢查來避免這一問題。不要成為這樣的司機。問題會隨著環(huán)境的成長或成熟而顯現(xiàn)。如果您已經(jīng)意識到潛在的問題,那么當(dāng)問題出現(xiàn)時,就能幫助您更快地解決問題。
PFC and ECN
PFC 是一種逐跳流量控制機制。相比之下,ECN 會通知目的地,而目的地又會通知發(fā)送方降低流量速率以防止擁塞。如前所述,從檢測到擁塞(標記CE 標志時)到擁塞交換端口觀察到降低的速率之間存在延遲。這大約是往返時間和終端設(shè)備處理延遲的兩倍。在此期間,擁塞交換端口上的隊列可能會填滿。逐跳PFC 可能會被激活,而不是丟棄數(shù)據(jù)包,從而導(dǎo)致?lián)砣诓粊G棄類中擴散。
同時使用ECN 和PFC 可以發(fā)揮兩者的優(yōu)勢。ECN 基于流量,但其效果可能會延遲。與此相反,PFC 基于優(yōu)先級(類別或類型),但其及時行動可避免丟包。同時使用這兩種方法,可以使操作既迅速又基于流量。
Configuring PFC and ECN Parameters
通知終端設(shè)備(通過ECN 和CNP)后的速率降低操作應(yīng)消除擁塞原因。沒有擁塞時,就沒有必要調(diào)用PFC。因此,正常工作的ECN 應(yīng)能很快減少PFC 暫停。但在交換機上配置ECN 門限需要特別考慮。具體數(shù)值取決于交換機類型,請參考供應(yīng)商文檔。本節(jié)僅解釋概念性概述。
Note the following points.請注意以下幾點。
1.入口隊列/緩沖區(qū)只有在出口隊列被大量使用后才會開始填滿。這一點在前面的"入口和出口隊列及微突發(fā)檢測"一節(jié)中已有解釋。
2.ECN 標記(如WRED)的閾值應(yīng)用于出口隊列,而PFC 暫停閾值和恢復(fù)閾值則應(yīng)用于入口隊列/緩沖區(qū)。
3.暫停閾值和恢復(fù)閾值應(yīng)根據(jù)前面"暫停閾值和恢復(fù)閾值"一節(jié)中的詳細說明進行配置。對于距離較短的數(shù)據(jù)中心內(nèi)鏈路,通常不需要更改默認的暫停閾值和恢復(fù)閾值。
4. ECN 門限應(yīng)足夠低,以便更早地標記CE 標志,從而有足夠的時間在擁塞端口上觀察到速率降低操作。
5. 閾值應(yīng)足夠大,至少能容納幾個數(shù)據(jù)包。例如,在啟用巨型幀時,9000 字節(jié)的最小大小甚至無法在隊列中保留一個完整大小的巨型數(shù)據(jù)包。
圖7-18 至圖7-23 展示了PFC 和ECN 的共同功能。需要了解的一個要點是,即使調(diào)整了閾值,也不能完全消除逐跳擁塞傳播。如果瞬間調(diào)用PFC,擁塞擴散是可以接受的。PFC 本身是有益的,因為它可以避免數(shù)據(jù)包丟棄,但它的副作用是會降低所有具有相同優(yōu)先級的流量的速度。如果ECN 能盡快降低部分流量的傳輸速率,就能限制PFC 造成的逐跳擁塞擴散和持續(xù)時間。如前所述,配置時應(yīng)力求兩種方法的最佳效果,而不是以消除PFC 為目標。
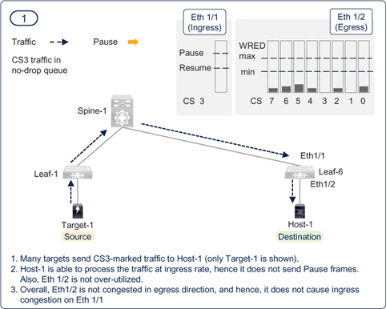
Figure 7-18PFC and ECN working together in a RoCEv2 network — Step — 1
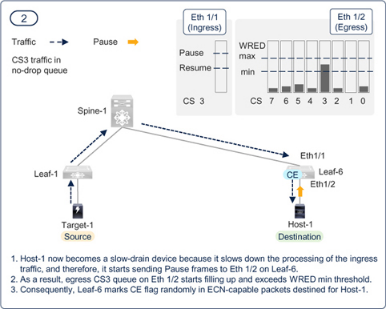
Figure 7-19PFC and ECN working together in a RoCEv2 network — Step — 2
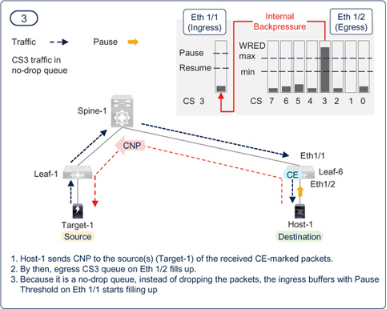
Figure 7-20PFC and ECN working together in a RoCEv2 network — Step — 3
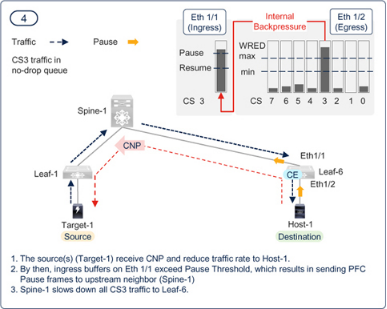
Figure 7-21PFC and ECN working together in a RoCEv2 network — Step — 4
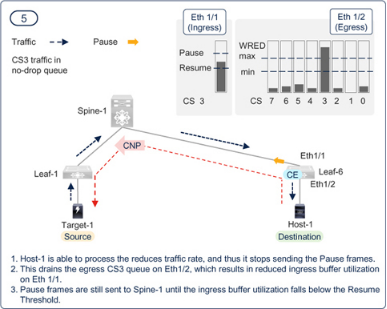
Figure 7-22PFC and ECN working together in a RoCEv2 network — Step — 5
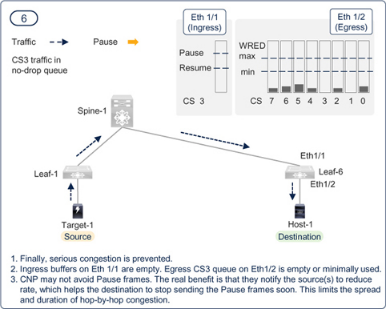
Figure 7-23PFC and ECN working together in a RoCEv2 network — Step — 6
Lossless Traffic with VXLAN
虛擬可擴展局域網(wǎng)(VXLAN)可傳輸無損流量,與任何其他路由IP/ 以太網(wǎng)網(wǎng)絡(luò)類似。因此,擁塞檢測、故障排除和預(yù)防都與此類似。
VXLAN Overview
虛擬可擴展局域網(wǎng)(VXLAN)將第2 層域擴展到第3 層數(shù)據(jù)中心網(wǎng)絡(luò)。這樣就可以靈活部署需要跨第3 層邊界的第2 層鄰接的工作負載。VXLAN 的另一個優(yōu)點是規(guī)模更大。以太網(wǎng)VLAN ID 是一個12 位字段,這將VLAN 的數(shù)量限制在4096 個。相比之下,VXLAN 網(wǎng)絡(luò)標識符(VNI)是一個24 位字段,允許多達1600 萬個第2 層域。VXLAN 還得益于第3 層底層網(wǎng)絡(luò)的等成本多路徑(ECMP)路由,從而實現(xiàn)第2 層域之間的高速無阻塞連接。
VXLAN Transport
VXLAN 采用MAC-in-UDP 封裝,將第2 層域擴展到第3 層網(wǎng)絡(luò)。有關(guān)VXLAN 幀格式,請參閱圖7-24。兩個獨立的第2 層網(wǎng)絡(luò)通過VXLAN 隧道端點(VTEP)連接到第3 層網(wǎng)絡(luò)。顧名思義,VTEP 通過VXLAN 隧道連接。它們知道本地第2 層域中可到達的MAC 地址以及通過遠程VTEP 可到達的MAC 地址。當(dāng)VTEP 接收到要發(fā)送給遠程第2 層域中設(shè)備的第2 層幀時,它會將第2 層幀封裝到IP/UDP 數(shù)據(jù)包中,并通過路由網(wǎng)絡(luò)發(fā)送給遠程VTEP。遠程VTEP 對數(shù)據(jù)包進行解封裝,并將底層第2 層幀發(fā)送到目的地。
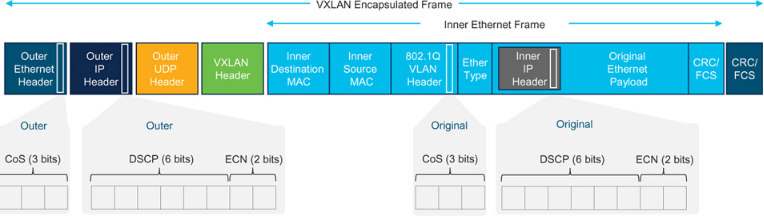
Figure 7-24VXLAN frame format
Physical Topology
VXLAN 第3 層網(wǎng)絡(luò)通常采用脊葉拓撲部署(類似于圖7-8)。這就是所謂的底層網(wǎng)絡(luò)。底層網(wǎng)絡(luò)中的數(shù)據(jù)包轉(zhuǎn)發(fā)由IS-IS 和OSPF 等IP 路由協(xié)議之一啟用。
Cisco Nexus 9000 等葉子交換機可充當(dāng)基于硬件的VTEP。每個VTEP 有兩個接口。一個是第2 層接口,用于連接本地端點通信的本地第2 層域。另一個是路由底層網(wǎng)絡(luò)上的第3 層接口。
兩個VTEP 之間的流量通過多個骨干交換機使用ECMP。終端設(shè)備可能不知道,VTEP 會將發(fā)往目的地的數(shù)據(jù)包封裝在VXLAN 數(shù)據(jù)包中。同樣,位于入口和出口VTEP 之間的脊柱交換機也可能不知道數(shù)據(jù)包屬于VXLAN 隧道。它只會查找外部IP 報頭,然后發(fā)送到目的地VTEP。
審核編輯:劉清
-
以太網(wǎng)
+關(guān)注
關(guān)注
40文章
5449瀏覽量
172171 -
看門狗
+關(guān)注
關(guān)注
10文章
565瀏覽量
70874 -
交換機
+關(guān)注
關(guān)注
21文章
2647瀏覽量
99868 -
VLAN
+關(guān)注
關(guān)注
1文章
279瀏覽量
35705 -
存儲網(wǎng)絡(luò)
+關(guān)注
關(guān)注
0文章
31瀏覽量
8127
原文標題:以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載(六)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載方案(一)
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載方案(二)
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載方案(三)
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載案例(五)
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載案例(七)


車載以太網(wǎng)基礎(chǔ)培訓(xùn)——車載以太網(wǎng)的鏈路層#車載以太網(wǎng)

車載以太網(wǎng)基礎(chǔ)培訓(xùn)——網(wǎng)絡(luò)層#車載以太網(wǎng)
以太網(wǎng)和工業(yè)以太網(wǎng)的不同
以太網(wǎng)供電新標準促熱網(wǎng)絡(luò)化電源管理應(yīng)用市場
以太網(wǎng)光纖通道(FCoE)技術(shù)問答
以太網(wǎng)的分類及靜態(tài)以太網(wǎng)交換和動態(tài)以太網(wǎng)交換、介紹
萬兆以太網(wǎng)和IP SAN的融合
光纖通道到以太網(wǎng)存儲結(jié)構(gòu)解析
以太網(wǎng)光模你了解多少
優(yōu)化網(wǎng)絡(luò)管理與監(jiān)控——工業(yè)以太網(wǎng)交換機的智能化之路






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論