") 基于高光譜成像技術(shù)的山楂產(chǎn)地判別建模分析
基于高光譜成像技術(shù)的山楂產(chǎn)地判別建模分析
山楂(Crataegus Pinnatifida)是薔薇科山楂屬植物,是典型的“藥食同源”植物,在我國廣泛分布于吉林、遼寧、河北、河南、山東、山西等地區(qū)。我國山楂年產(chǎn)量超過 150萬噸,市場前景廣闊,但由于不同產(chǎn)地的山楂中各類營養(yǎng)成分含量存在差異,因此其在價格上也有所區(qū)分,而當(dāng)今山楂市場上產(chǎn)地混用、以次充好等現(xiàn)象屢見不鮮,使許多消費者上當(dāng)受騙,這些現(xiàn)象嚴(yán)重破壞了市場秩序。因此,目前市場亟需一種能夠快速準(zhǔn)確對山楂進行產(chǎn)地溯源的方法。
為滿足市場需求,本文旨在探究高光譜成像技術(shù)在山楂產(chǎn)地識別中的應(yīng)用及不同采樣方向?qū)τ谀P头诸愋阅艿挠绊懀酶吖庾V成像系統(tǒng)(410~2500 nm),分別采集山楂樣本果梗面、側(cè)面及底面的光譜數(shù)據(jù),結(jié)合多種機器學(xué)習(xí)算法分別建立產(chǎn)地識別模型,最終實現(xiàn)基于高光譜成像技術(shù)對山楂進行產(chǎn)地溯源的目的。
續(xù)
二、結(jié)果與分析
2.3 基于全波段的建模分析
2.3.1預(yù)處理及分類建模方法
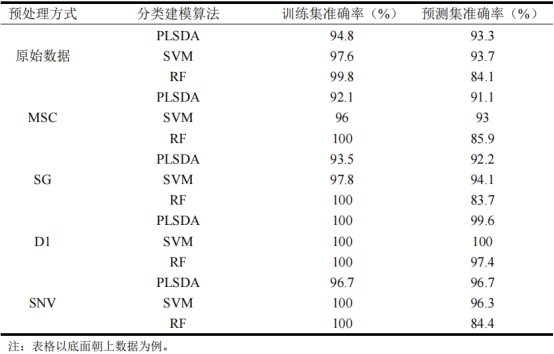
篩選為篩選出最佳預(yù)處理和分類建模方法,分別采用4種預(yù)處理方法和3種分類建模方法建立模型,以樣本底面數(shù)據(jù)為代表,各模型分類準(zhǔn)確率見表1。對比四種預(yù)處理數(shù)據(jù)分類模型準(zhǔn)確率可以發(fā)現(xiàn),引入預(yù)處理方法之后,大部分模型的分類精度得到了提高,而D1對于三種分類模型(PLSDA、SVM和RF)均為最優(yōu)預(yù)處理方式。對比三種不同模型(PLSDA、SVM和RF)分類準(zhǔn)確率,發(fā)現(xiàn)無論采用哪種預(yù)處理方式,采用RF建立的分類模型雖然有較高的訓(xùn)練集準(zhǔn)確率,但是預(yù)測集準(zhǔn)確率一般;采用PLSDA和SVM建立的分類模型訓(xùn)練集和預(yù)測集準(zhǔn)確率良好,其中以SVM模型分類準(zhǔn)確率最高。綜上所述,對于底面數(shù)據(jù),D1為最佳預(yù)處理方式,采用SVM建立的分類模型分類準(zhǔn)確率高,且具有優(yōu)秀的穩(wěn)定性和泛化能力。為進一步驗證結(jié)論,分別使用C和G數(shù)據(jù)集進行建模對比,均呈現(xiàn)相同的規(guī)律,故判斷D1為最優(yōu)預(yù)處理方式,SVM為最佳分類建模算法,后續(xù)均采用D1-SVM(經(jīng)D1預(yù)處理后建立的SVM模型)方式進行分類建模。
表1不同預(yù)處理分類模型準(zhǔn)確率
2.3.2不同采樣方式分類建模分析
本研究為探究不同采樣方向?qū)δP头诸惤Y(jié)果的影響,分別收集了樣本側(cè)面朝上(C)、果梗面朝上(G)和底面朝上(D)的高光譜圖像。同時為模擬實際應(yīng)用時隨機拍攝到的高光譜數(shù)據(jù),將三個數(shù)據(jù)集進行等比混合建立一個新數(shù)據(jù)集(R),使用四個數(shù)據(jù)集分別進行分類建模,建模方法均采用D1-SVM,綜合對比各項指標(biāo)篩選出最優(yōu)模型。各模型分類準(zhǔn)確率結(jié)果見表2。
對于使用R數(shù)據(jù)集建立的分類模型,其準(zhǔn)確率較高(100%,96.7%),根據(jù)圖4d并由公式(3)和公式(4)計算得出,不同產(chǎn)區(qū)的精確率和召回率均超過90%。對比四個數(shù)據(jù)集模型的準(zhǔn)確率可以發(fā)現(xiàn),三種單面數(shù)據(jù)集(C、D和G)模型準(zhǔn)確率均高于使用R數(shù)據(jù)集建立的模型,這說明對于山楂樣本,在高光譜數(shù)據(jù)采集時保持樣品方向一致可以有效提高分類模型準(zhǔn)確率,這一規(guī)律與研究人員在玉米真菌感染檢測中的發(fā)現(xiàn)一致。橫向?qū)Ρ菴、G和D三個模型,其中使用D數(shù)據(jù)集建立的分類模型準(zhǔn)確率最高,訓(xùn)練集和預(yù)測集準(zhǔn)確率均達到100%,各產(chǎn)區(qū)樣本全部預(yù)測正確。為避免過擬合現(xiàn)象,對D-D1-SVM模型進行十折交叉驗證,其平均準(zhǔn)確率為98.8%。綜上所述,D-D1-SVM模型對于不同產(chǎn)區(qū)山楂的分類效果最優(yōu)。
表2不同方向數(shù)據(jù)分類模型準(zhǔn)確率
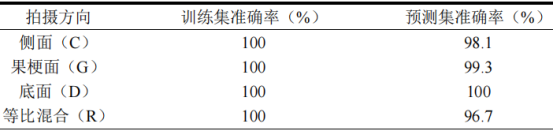
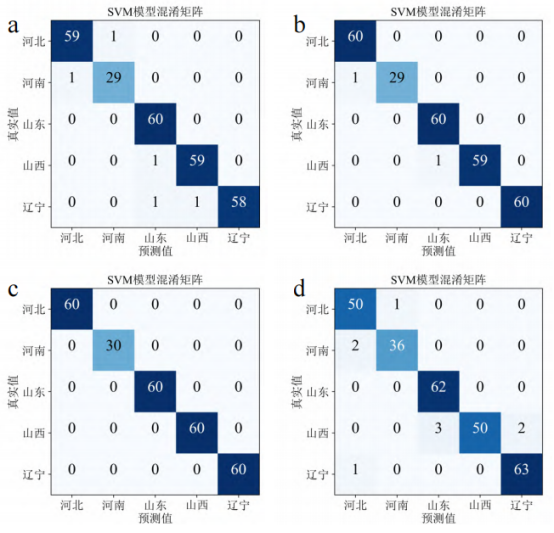
圖4全波段模型混淆矩陣
注:a、b、c、d分別為對應(yīng)C-D1-SVM、
G-D1-SVM、D-D1-SVM、R-D1-SVM四個模型
2.4 基于特征波長的建模分析
2.4.1特征波長的選擇
為篩選出最佳特征提取方法,分別使用2種提取方式提取4個數(shù)據(jù)集的特征波長,最終得到的波長見表3及圖5。對比兩種方法提取得到的特征波長數(shù)量發(fā)現(xiàn),使用SPA提取出的特征波長數(shù)量明顯少于CARS,進一步觀察特征波長分布(圖5),發(fā)現(xiàn)使用SPA提取出的特征波長分布均勻,各個波段均有涉及;而CARS提取的特征波長分布較為集中,主要分布于750nm、2000nm及2250nm處的三個特征峰。觀察各組特征波長重合的部分,發(fā)現(xiàn)750nm、1700nm和2200nm附近的重合波長較多,說明這三處吸收峰可能包含不同產(chǎn)區(qū)樣本的差異信息。對這些特征峰進行深入分析,700~800nm處的吸收峰來自于樣品內(nèi)部的葉綠素,也受樣品的外部顏色特征影響;1700nm附近的吸收峰可歸因于酰胺基團;2200nm處的吸收峰為C—H和C—O的聯(lián)合吸收峰。
表3不同方法提取特征波長數(shù)量


圖5不同數(shù)據(jù)集特征波長
注:a、c、e、g分別為G、C、D和R數(shù)據(jù)集經(jīng)SPA提取得到的特征波長;b、d、f、h分別為G、C、D和R數(shù)據(jù)集經(jīng)CARS提取得到的特征波長
2.4.2特征波長建模分析
使用4個數(shù)據(jù)集的特征波長分別建立SVM模型,其準(zhǔn)確率見表4。觀察發(fā)現(xiàn)使用SPA篩選特征波長建立的模型分類準(zhǔn)確率優(yōu)于CARS,這一現(xiàn)象在G和D數(shù)據(jù)集上尤為明顯。綜合考慮波長數(shù)量和模型準(zhǔn)確率,SPA篩選的波長數(shù)量更少,模型復(fù)雜度較低,且準(zhǔn)確率更高。與本研究得到的結(jié)果不同,有研究人員在基于特征波段建立紅景天分類模型時,發(fā)現(xiàn)CARS為最佳特征波段提取方法,這說明對于不同的檢測對象,應(yīng)當(dāng)選用不同的特征提取方法,而對于山楂樣本,SPA相比于CARS特征波長提取效果更好。
采用SPA提取特征波長的分類模型預(yù)測集混淆矩陣見圖6,對比四個數(shù)據(jù)集的準(zhǔn)確率(表4)看出,R-SPA模型預(yù)測集準(zhǔn)確率為87.8%,根據(jù)其混淆矩陣(圖6d)并由公式(3)和公式(4)計算得出,模型對于河北產(chǎn)區(qū)的精確率和召回率僅為79.2%和82.4%,分類能力一般。而C-SPA、G-SPA和D-SPA三個模型準(zhǔn)確率均超過90%(分別為90.3%、91.5%和93%),這一現(xiàn)象再次證明在高光譜數(shù)據(jù)采集時,保持樣品方向一致可以有效提高分類模型準(zhǔn)確率。綜合對比所有模型,D-SPA模型擁有最高的分類準(zhǔn)確率,訓(xùn)練集和預(yù)測集準(zhǔn)確率分別為95.2%和93%,根據(jù)其混淆矩陣(圖6c)并由公式(3)和公式(4)計算得出,模型對于各產(chǎn)區(qū)的精確率和召回率均超過90%(其中山東產(chǎn)區(qū)精確率和召回率最低,分別為91.6%和90%);且這一模型涉及的特征波長數(shù)量最少,在保證分類準(zhǔn)確率的情況下?lián)碛休^低的模型復(fù)雜度。
綜上所述,采集高光譜數(shù)據(jù)時保持樣品擺放方式一致有助于提高模型分類準(zhǔn)確率。采用SPA提取特征波長建立的產(chǎn)地分類模型復(fù)雜度較低且準(zhǔn)確率良好。可以在波長數(shù)量有限的情況下對山楂產(chǎn)地進行判別,為后續(xù)山楂專屬小型化高光譜設(shè)備的開發(fā)提供了方法參考。
表4特征波長建模準(zhǔn)確率
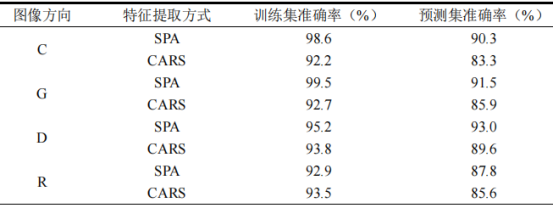
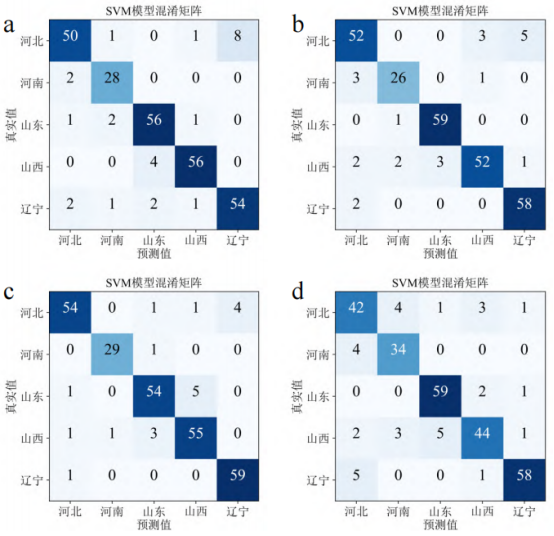
圖6特征波長模型混淆矩陣
注:a、b、c、d分別對應(yīng)C-SPA-SVM、G-SPA-SVM、D-SPA-SVM、R-SPA-SVM四個模型。
綜合考慮全波段模型和特征波長模型的分類結(jié)果,發(fā)現(xiàn)采集樣本光譜數(shù)據(jù)時,樣本的擺放方式會影響后續(xù)分類建模準(zhǔn)確率。無論全波段還是特征波長模型,使用D數(shù)據(jù)集建模分類效果都明顯優(yōu)于R數(shù)據(jù)集(提高了約5%),相對于C和G數(shù)據(jù)集也有所提高。觀察山楂樣品的外部特征,發(fā)現(xiàn)樣品底面存在萼片部位,結(jié)合寧素云等的研究報道:山楂不同部位的化學(xué)成分含量存在差異,推測不同產(chǎn)地山楂其萼片部位各成分含量的差異相比于其他部位更大,進而導(dǎo)致分類特征更加明顯。
三、結(jié)論
本研究基于高光譜成像技術(shù)建立了山楂產(chǎn)地識別模型。為探究樣本拍攝方向?qū)Ψ诸惤Y(jié)果的影響,采集了山楂樣本三個不同方向(C、G和D)的光譜數(shù)據(jù),分別使用偏最小二乘判別分析(PLSDA)、支持向量機(SVM)和隨機森林(RF)三種方法建立模型,通過對比模型分類準(zhǔn)確率得到最優(yōu)建模方法,最終成功區(qū)分了5個不同省級產(chǎn)區(qū)的山楂,為山楂無損檢測設(shè)備的開發(fā)提供了參考。經(jīng)過對比篩選發(fā)現(xiàn),一階導(dǎo)數(shù)(D1)為最優(yōu)預(yù)處理方式,SVM為最優(yōu)建模算法;使用連續(xù)投影算法(SPA)提取特征波長數(shù)量少且分類模型準(zhǔn)確率高。全波段最優(yōu)建模方法為D-D1-SVM,訓(xùn)練集和預(yù)測集準(zhǔn)確率均達到100%;特征波長最優(yōu)建模方法為D-SPA-SVM,訓(xùn)練集和預(yù)測集準(zhǔn)確率分別為95.2%和93%。本研究證明基于高光譜成像技術(shù)對山楂產(chǎn)地進行溯源是可行的,為維護山楂市場秩序提供一種新的識別方式;同時驗證高光譜圖像采集方向會對檢測結(jié)果產(chǎn)生影響,為后續(xù)開發(fā)山楂專屬高光譜檢測設(shè)備提供理論依據(jù)和參考。
推薦:
便攜式高光譜成像系統(tǒng) iSpecHyper-VS1000
專門用于公安刑偵、物證鑒定、醫(yī)學(xué)醫(yī)療、精準(zhǔn)農(nóng)業(yè)、礦物地質(zhì)勘探等領(lǐng)域的最新產(chǎn)品,主要優(yōu)勢具有體積小、幀率高、高光譜分辨率高、高像質(zhì)等性價比特點采用了透射光柵內(nèi)推掃原理高光譜成像,系統(tǒng)集成高性能數(shù)據(jù)采集與分析處理系統(tǒng),高速USB3.0接口傳輸,全靶面高成像質(zhì)量光學(xué)設(shè)計,物鏡接口為標(biāo)準(zhǔn)C-Mount,可根據(jù)用戶需求更換物鏡。
審核編輯 黃宇
-
成像
+關(guān)注
關(guān)注
2文章
240瀏覽量
30487 -
高光譜
+關(guān)注
關(guān)注
0文章
331瀏覽量
9944
發(fā)布評論請先 登錄
相關(guān)推薦
高光譜成像儀在農(nóng)業(yè)上的應(yīng)用

無人機機載高光譜成像系統(tǒng)的應(yīng)用及優(yōu)勢
實驗室高光譜成像儀的應(yīng)用與優(yōu)勢
高光譜成像儀的數(shù)據(jù)怎么看
高光譜成像技術(shù)在膚檢測、植被遙感與環(huán)境檢測中的應(yīng)用
高光譜成像系統(tǒng)解析
高光譜成像技術(shù):從原理到應(yīng)用的全面指南
高光譜成像系統(tǒng):光譜成像技術(shù)在海域目標(biāo)探測中的應(yīng)用
高光譜成像技術(shù)原理及其優(yōu)勢
基于高光譜成像技術(shù)的山楂產(chǎn)地判別方法

避免高光譜成像數(shù)據(jù)中的光譜混疊問題
如何使用高光譜成像技術(shù)進行作物健康監(jiān)測?

便攜式高光譜成像系統(tǒng)在遠程感知中的應(yīng)用探究
光譜成像技術(shù)分類及應(yīng)用
比較分析:便攜式高光譜成像系統(tǒng)與傳統(tǒng)成像技術(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論