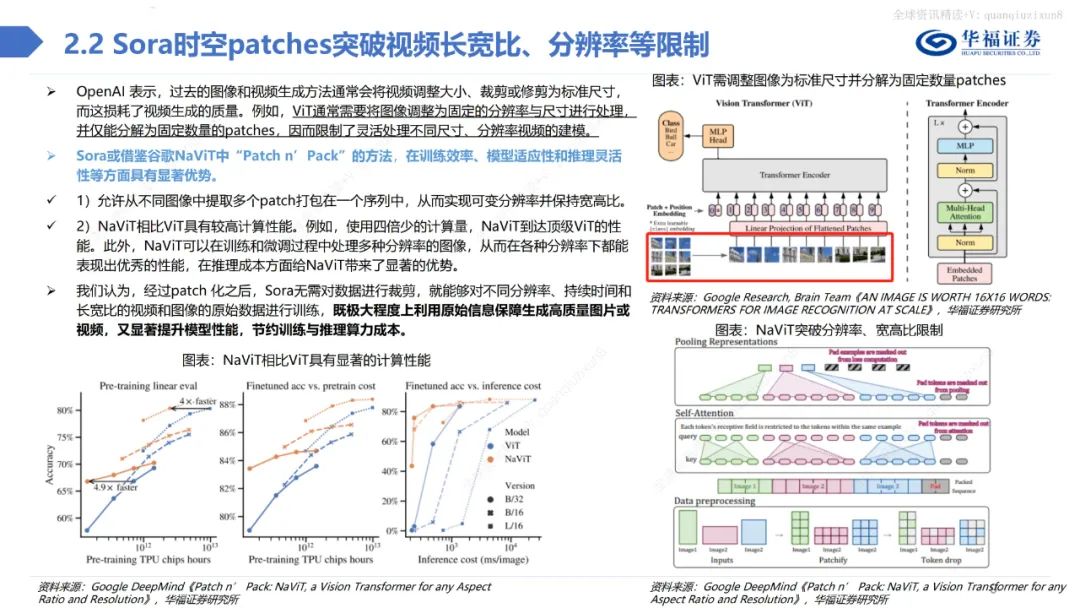
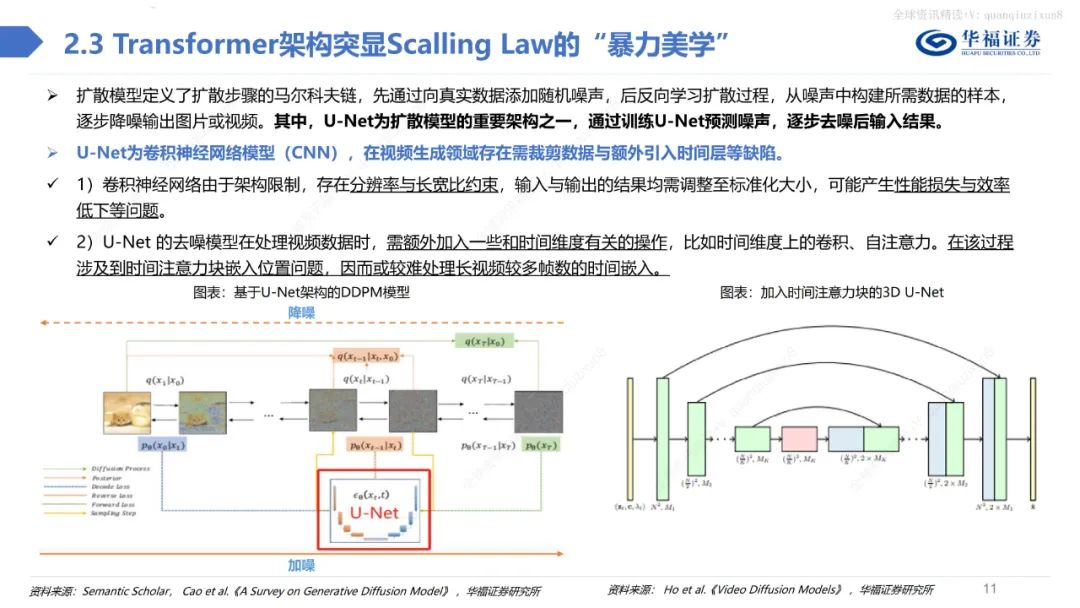
 深度剖析Sora技術的核心原理與應用
深度剖析Sora技術的核心原理與應用
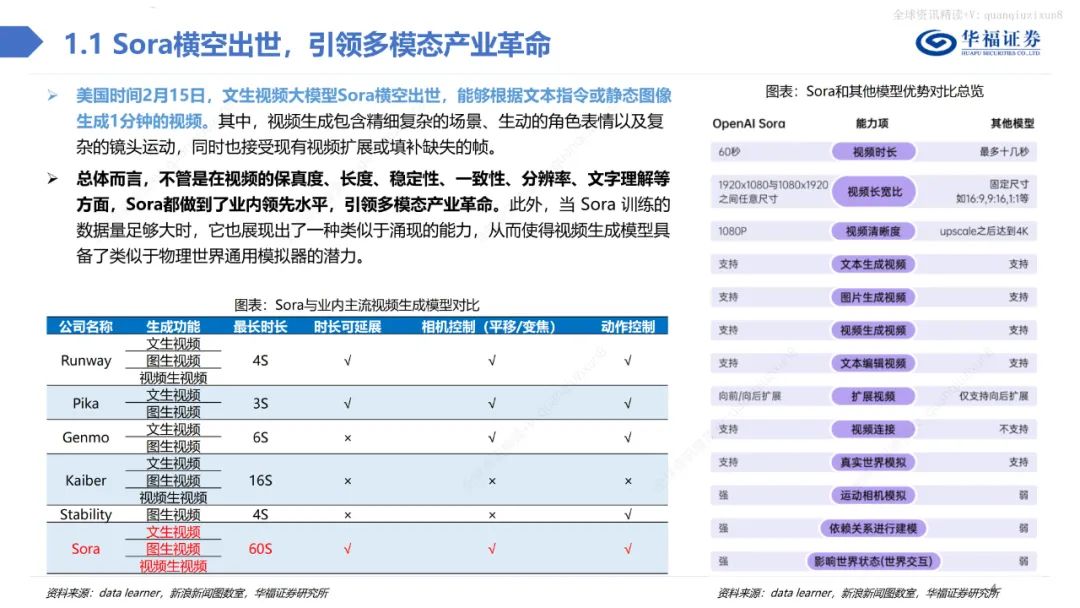
?文生視頻大模型Sora橫空出世,能夠根據文本指令或靜態圖像生成1分鐘的視頻。其中,視頻生成包含精細復雜的場景、生動的角色表情以及復雜的鏡頭運動,同時也接受現有視頻擴展或填補缺失的幀。
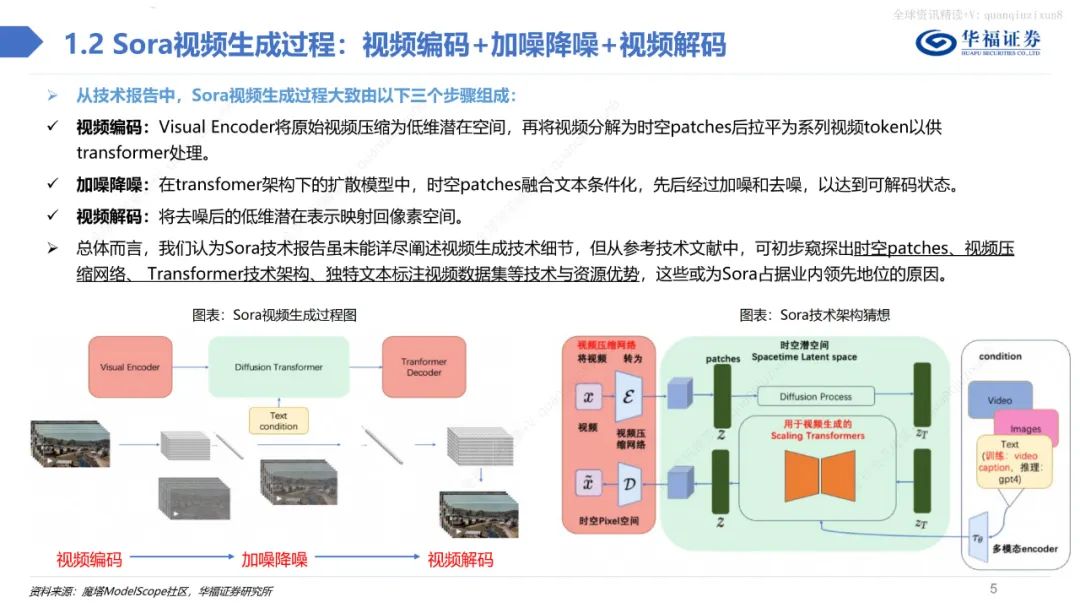
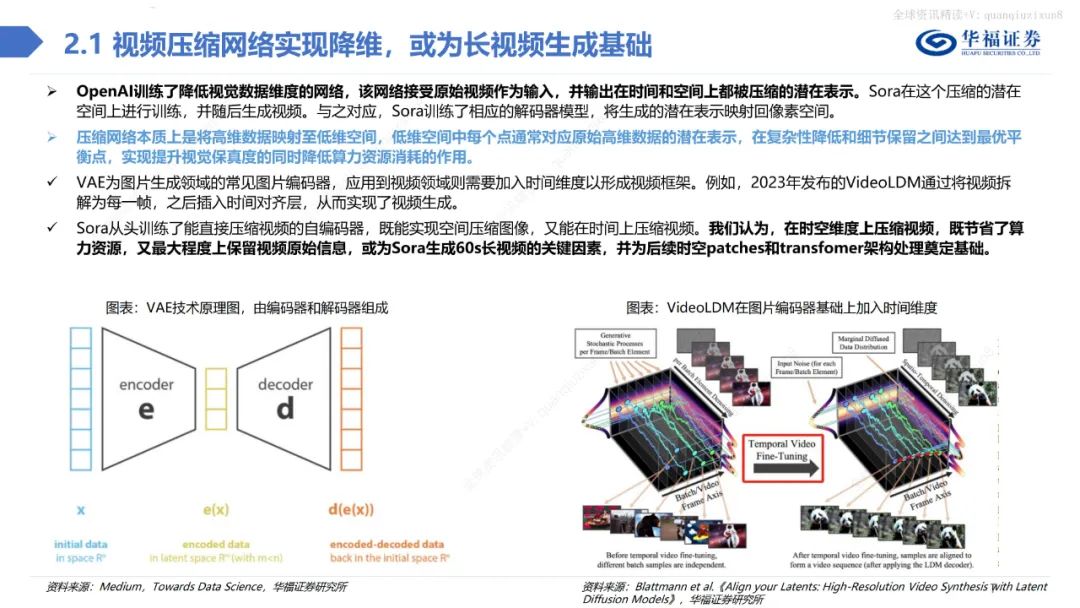
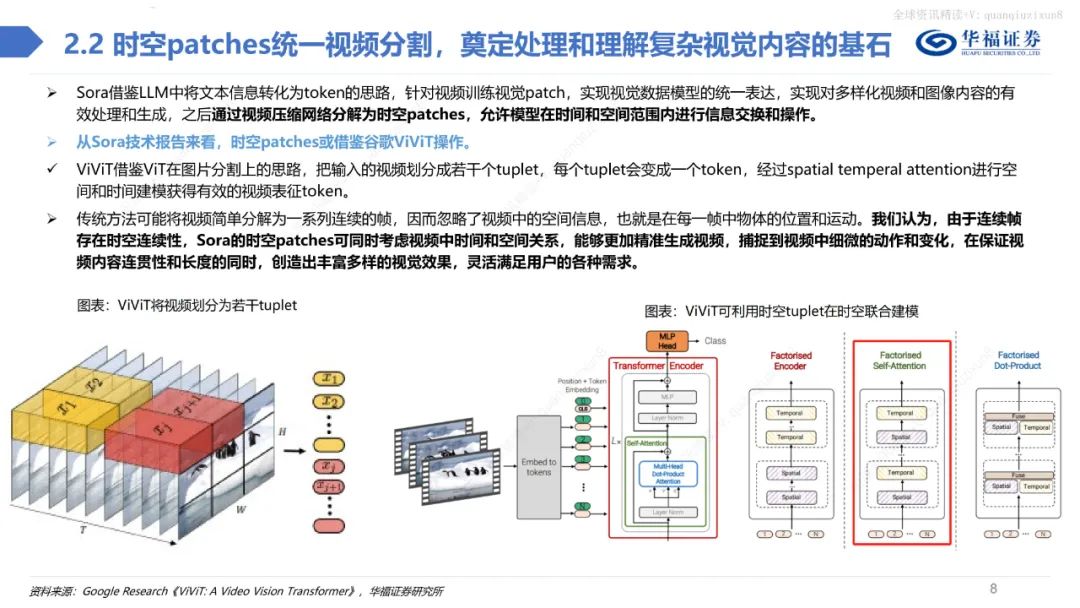
總體而言,不管是在視頻的保真度、長度、穩定性、一致性、分辨率、文字理解等方面,Sora都做到了業內領先水平,引領多模態產業革命。此外,當Sora訓練的數據量足夠大時,它也展現出了一種類似于涌現的能力,從而使得視頻生成模型具備了類似于物理世界通用模擬器的潛力。 Sora借鑒LLM中將文本信息轉化為token的思路,針對視頻訓練視覺patch,實現視覺數據模型的統一表達,實現對多樣化視頻和圖像內容的有效處理和生成,之后通過視頻壓縮網絡分解為時空patches,允許模型在時間和空間范圍內進行信息交換和操作。
從Sora技術報告來看,時空patches或借鑒谷歌ViViT操作。ViViT借鑒ViT在圖片分割上的思路,把輸入的視頻劃分成若干個tuplet,每個tuplet會變成一個token,經過spatial temperal attention進行空間和時間建模獲得有效的視頻表征token。 傳統方法可能將視頻簡單分解為一系列連續的幀,因而忽略了視頻中的空間信息,也就是在每一幀中物體的位置和運動。我們認為,由于連續幀存在時空連續性,Sora的時空patches可同時考慮視頻中時間和空間關系,能夠更加精準生成視頻,捕捉到視頻中細微的動作和變化,在保證視頻內容連貫性和長度的同時,創造出豐富多樣的視覺效果,靈活滿足用戶的各種需求。






審核編輯:黃飛
-
LLM
+關注
關注
0文章
296瀏覽量
356 -
Sora
+關注
關注
0文章
82瀏覽量
230
原文標題:分享:Sora技術深度解析
文章出處:【微信號:架構師技術聯盟,微信公眾號:架構師技術聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論