") 中文大模型測(cè)評(píng)基準(zhǔn)SuperCLUE:商湯日日新5.0,刷新國(guó)內(nèi)最好成績(jī)
中文大模型測(cè)評(píng)基準(zhǔn)SuperCLUE:商湯日日新5.0,刷新國(guó)內(nèi)最好成績(jī)
編者按:日前,中文大模型測(cè)評(píng)基準(zhǔn)SuperCLUE發(fā)布最新榜單,對(duì)商湯科技全新升級(jí)「日日新SenseNova 5.0」大模型進(jìn)行了全方位綜合性測(cè)評(píng),結(jié)果顯示在SuperCLUE綜合基準(zhǔn)上,日日新 5.0表現(xiàn)不俗,以總分80.03分的優(yōu)異成績(jī)刷新國(guó)內(nèi)最好成績(jī),并在中文綜合成績(jī)上超過(guò)GPT-4-Turbo-0125。
SuperCLUE是由創(chuàng)立于2019年的CLUE學(xué)術(shù)社區(qū)最新發(fā)布的中文通用大模型綜合性評(píng)測(cè)基準(zhǔn),是被行業(yè)廣泛認(rèn)可的AI大模型權(quán)威評(píng)測(cè)榜單。以下評(píng)測(cè)報(bào)告轉(zhuǎn)載自 SuperCLUE官方發(fā)布報(bào)道。
4月23日,商湯科技正式發(fā)布全新大模型日日新5.0(SenseChat V5),采用混合專家架構(gòu)(MoE),參數(shù)量高達(dá)6000億,支持200K的上下文窗口。據(jù)官方披露,SenseChat V5具備更強(qiáng)的知識(shí)、數(shù)學(xué)、推理及代碼能力,綜合性能全面對(duì)標(biāo)GPT-4 Turbo。
那么,SenseChat V5在SuperCLUE中文基準(zhǔn)上的表現(xiàn)如何?與國(guó)內(nèi)外代表性大模型相比處于什么位置?在各項(xiàng)基礎(chǔ)能力上如計(jì)算推理、長(zhǎng)文本、代碼生成、生成創(chuàng)作上會(huì)有怎樣的表現(xiàn)?
SuperCLUE團(tuán)隊(duì)對(duì)SenseChat V5在SuperCLUE通用大模型綜合性中文測(cè)評(píng)基準(zhǔn)上,進(jìn)行了全方位綜合性測(cè)評(píng)。
測(cè)評(píng)環(huán)境
參考標(biāo)準(zhǔn):SuperCLUE綜合性測(cè)評(píng)標(biāo)準(zhǔn)
評(píng)測(cè)模型:SenseChat V5(官方于5月11日提供的內(nèi)測(cè)API版本)
評(píng)測(cè)集:SuperCLUE綜合性測(cè)評(píng)基準(zhǔn)4月評(píng)測(cè)集,2194道多輪簡(jiǎn)答題,包括計(jì)算、邏輯推理、代碼、長(zhǎng)文本在內(nèi)的基礎(chǔ)十大任務(wù)。
模型GenerationConfig配置:
temperature=0.01
repetition_penalty=1.0
top_p=0.8
max_new_tokens=2048
stream=false
測(cè)評(píng)方法:
本次測(cè)評(píng)為自動(dòng)化評(píng)測(cè),具體評(píng)測(cè)方案可點(diǎn)擊查閱SuperCLUE綜合性測(cè)評(píng)標(biāo)準(zhǔn)。本次測(cè)評(píng)經(jīng)過(guò)人工抽樣校驗(yàn)。


先說(shuō)結(jié)論
結(jié)論1:在SuperCLUE綜合基準(zhǔn)上,SenseChat V5表現(xiàn)不俗,以總分80.03分的優(yōu)異成績(jī)刷新國(guó)內(nèi)最好成績(jī),并且在中文綜合成績(jī)上超過(guò)GPT-4-Turbo-0125有0.9分。
結(jié)論2:在本次測(cè)評(píng)中,理科任務(wù)上SenseChat V5取得國(guó)內(nèi)最好成績(jī),較GPT-4-Turbo-0125低4.35分,還有一定提升空間;文科任務(wù)上SenseChat V5表現(xiàn)十分出色,以82.20分取得國(guó)內(nèi)外最高分。
結(jié)論3:在本次測(cè)評(píng)中,SenseChat V5在各項(xiàng)能力上表現(xiàn)較為均衡,尤其在長(zhǎng)文本、生成創(chuàng)作、角色扮演、安全能力、工具使用上處于全球領(lǐng)先位置,適用于智能體、內(nèi)容創(chuàng)作、長(zhǎng)程對(duì)話等應(yīng)用場(chǎng)景。代碼能力還有一定提升空間。
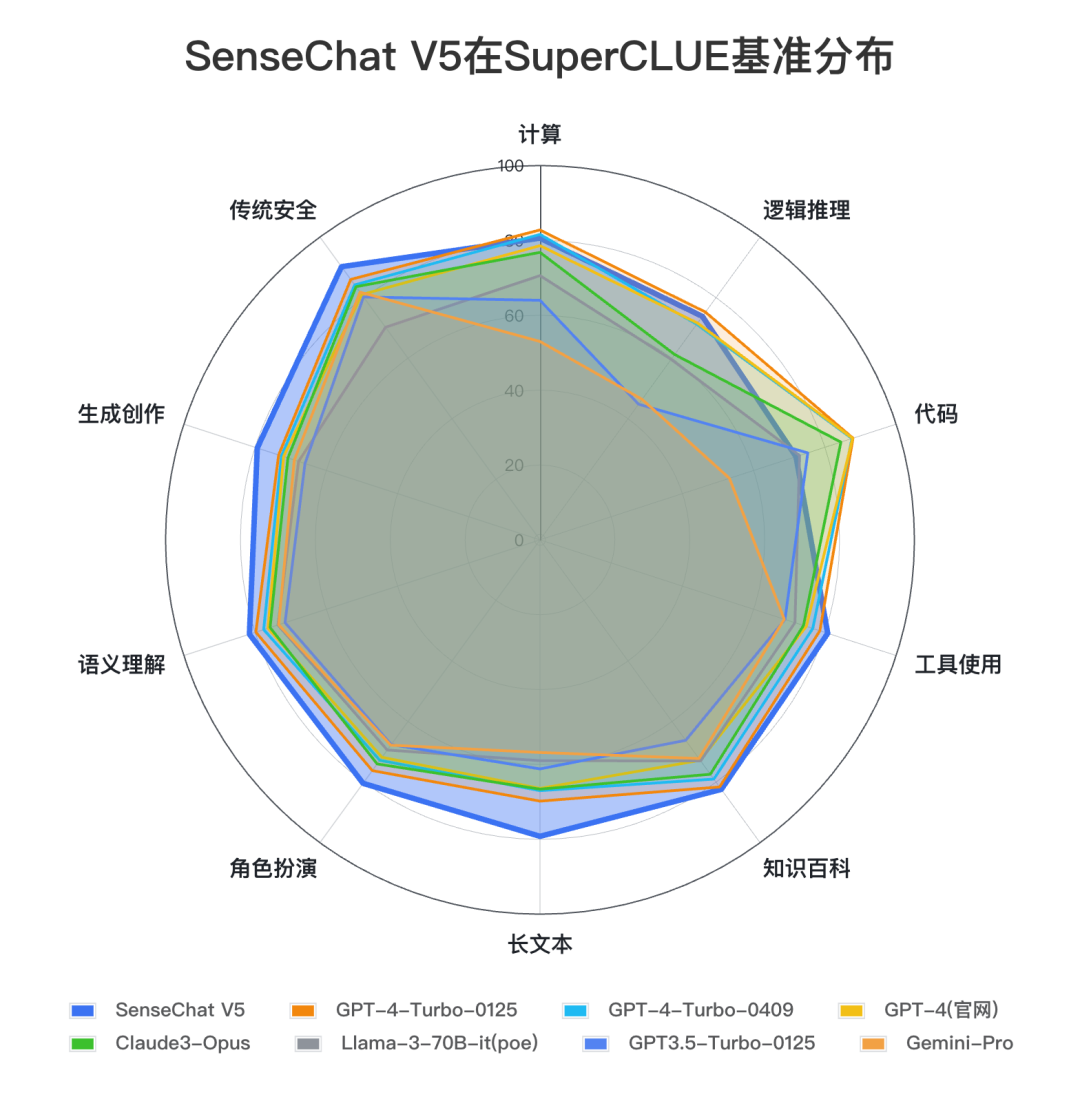
對(duì)比模型數(shù)據(jù)來(lái)源: SuperCLUE, 2024年4月30日
以下是我們從定量和定性兩個(gè)角度對(duì)模型進(jìn)行的測(cè)評(píng)分析。
測(cè)評(píng)分析
1定量分析
在SuperCLUE測(cè)評(píng)中,SenseChat V5總體表現(xiàn)如下:
SenseChat V5總體表現(xiàn)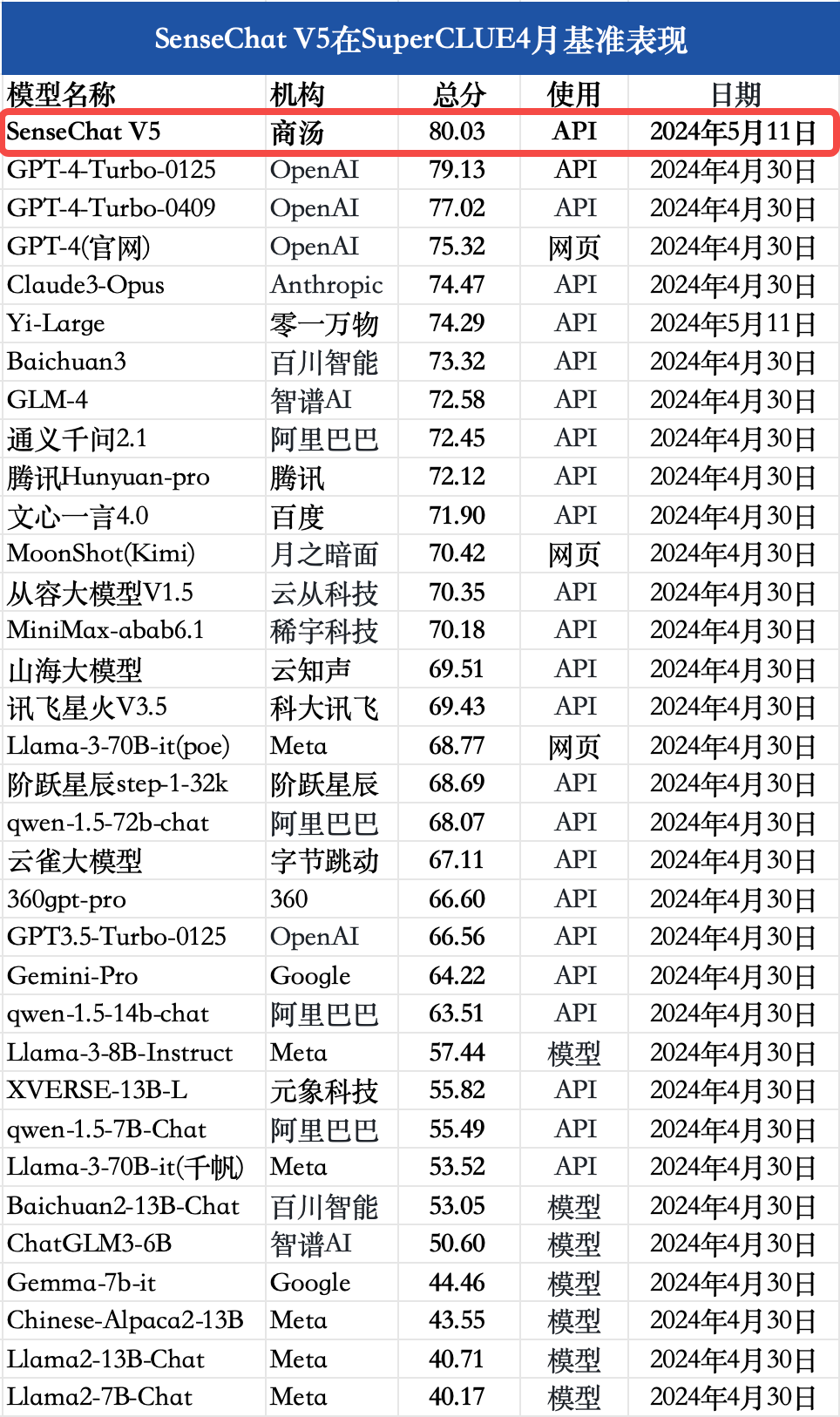
注:對(duì)比模型數(shù)據(jù)均來(lái)源于SuperCLUE,SenseChat V5和Yi-Large取自2024年5月11日,其余所有模型取自2024年4月30日。由于部分模型分?jǐn)?shù)較為接近,為了減少問(wèn)題波動(dòng)對(duì)排名的影響,本次測(cè)評(píng)將相距0.25分區(qū)間的模型定義為并列,以上排序不代表實(shí)際排名。
在SuperCLUE通用綜合測(cè)評(píng)基準(zhǔn)上,SenseChat V5取得80.03分,表現(xiàn)出色,刷新國(guó)內(nèi)大模型最好成績(jī)。并且,SenseChat V5在中文綜合能力上較GPT-4-Turbo-0125高0.9分。
SenseChat V5在理科任務(wù)上的表現(xiàn)
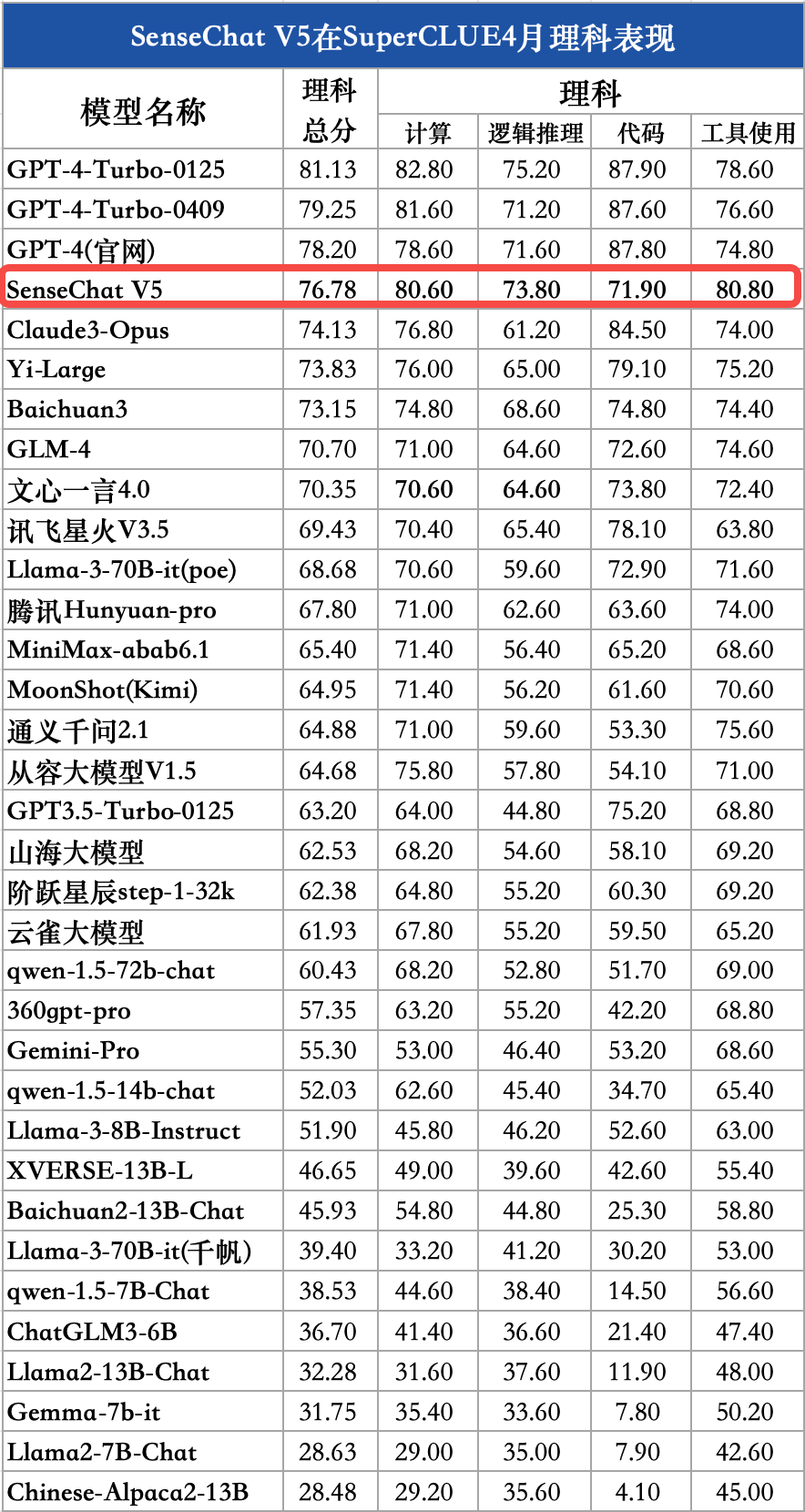
對(duì)比模型數(shù)據(jù)來(lái)源:SuperCLUE SenseChat V5在理科任務(wù)上表現(xiàn)不俗,取得76.78分,國(guó)內(nèi)模型中排名第一,較GPT-4-Turbo-0125低4.35分,還有一定提升空間。其中,計(jì)算(80.6)、邏輯推理(73.8)、工具使用(80.8)均刷新國(guó)內(nèi)最好成績(jī);在代碼能力上還有一定優(yōu)化空間。
SenseChat V5在文科任務(wù)上的表現(xiàn)
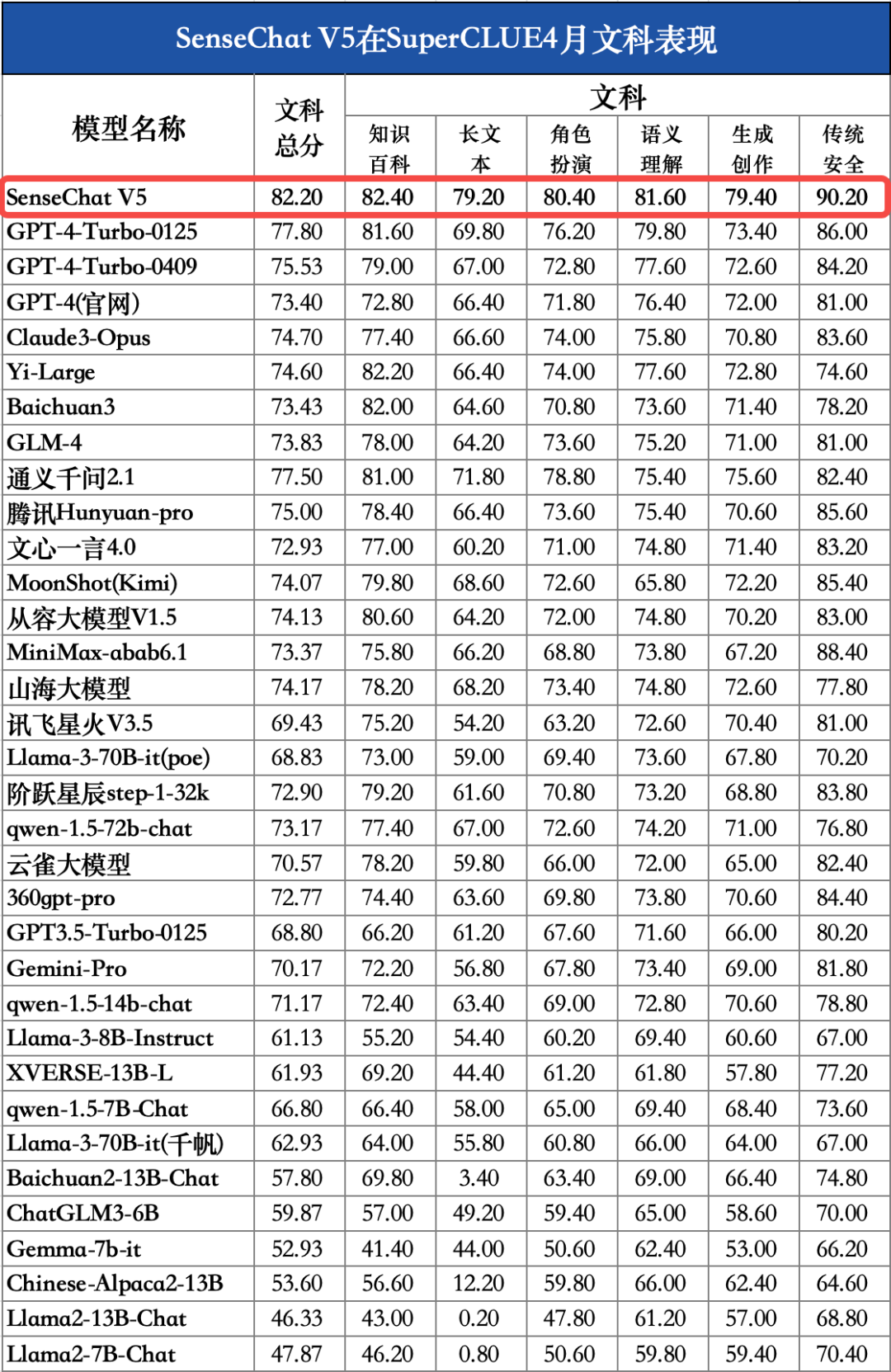
對(duì)比模型數(shù)據(jù)來(lái)源:SuperCLUE SenseChat V5在文科任務(wù)上表現(xiàn)出色,取得82.20的高分,國(guó)內(nèi)外模型中排名第一,較GPT-4-Turbo-0125高4.40分。其中,知識(shí)百科(82.4)、長(zhǎng)文本(79.2)、角色扮演(80.4)、語(yǔ)義理解(81.6)、生成創(chuàng)作(79.4)、傳統(tǒng)安全(90.2)均刷新國(guó)內(nèi)最好成績(jī);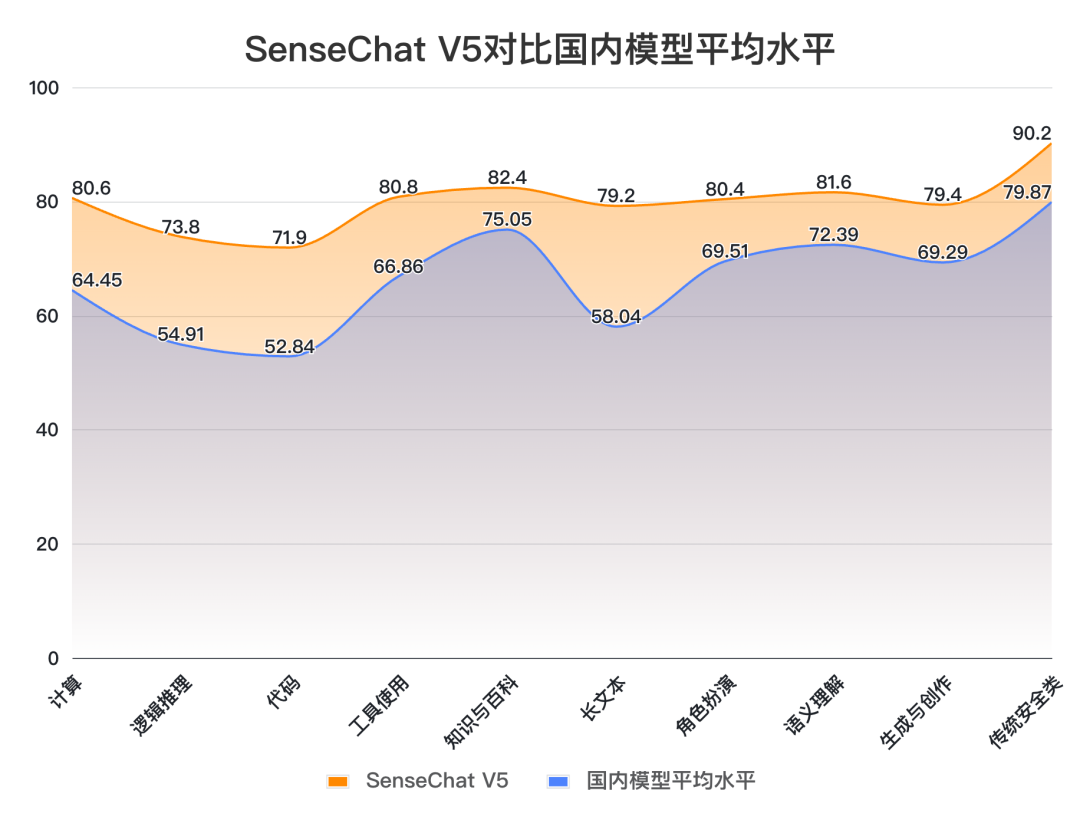
對(duì)比數(shù)據(jù)來(lái)源:SuperCLUE, 2024年4月30日 將SenseChat V5與國(guó)內(nèi)大模型平均得分對(duì)比,我們可以發(fā)現(xiàn),SenseChat V5在所有能力上均高于平均線,展現(xiàn)出較均衡的綜合能力。尤其在計(jì)算(+16.15)、邏輯推理(+18.89)、代碼(+19.06)、長(zhǎng)文本(+21.16)能力上遠(yuǎn)高出平均線15分以上。
SenseChat V5與國(guó)外代表模型對(duì)比
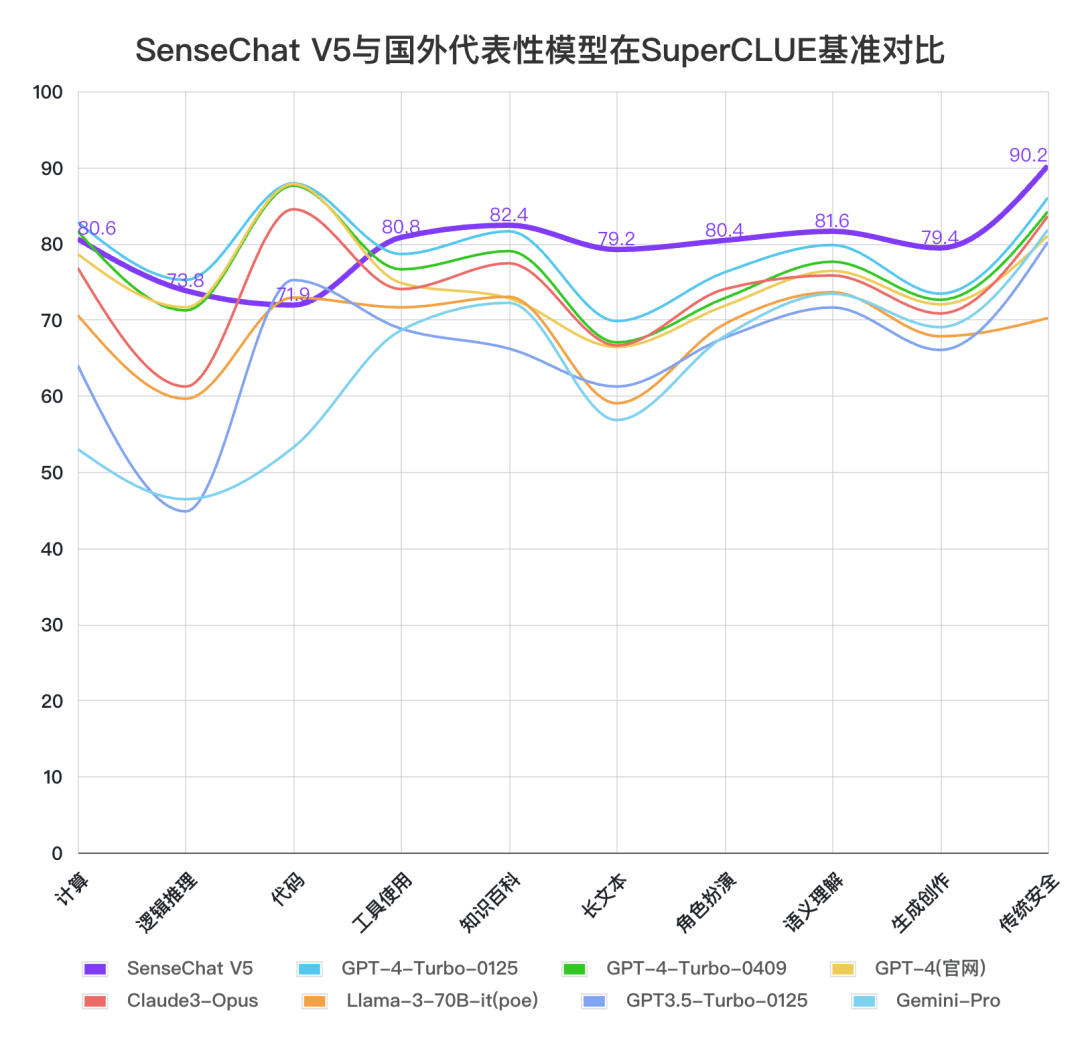
將SenseChat V5與國(guó)外代表大模型對(duì)比,SenseChat V5在文科類(lèi)中文任務(wù)上好于國(guó)外大模型,尤其在長(zhǎng)文本、生成創(chuàng)作能力較為領(lǐng)先。在理科如計(jì)算、邏輯推理、代碼能力上與GPT-4-Turbo-0125還有一定提升空間。
小結(jié):
從評(píng)測(cè)結(jié)果我們發(fā)現(xiàn),SenseChat V5綜合能力上表現(xiàn)不俗,在總分上刷新了國(guó)內(nèi)外最好成績(jī),其中文科任務(wù)上有超過(guò)GPT-4 Turbo的表現(xiàn),理科任務(wù)上刷新國(guó)內(nèi)最好成績(jī),與GPT-4 Turbo還有一定距離。 2定性分析
通過(guò)一些典型示例,對(duì)比定性分析SenseChat V5的特點(diǎn)。
示例1:長(zhǎng)文本

示例2:生成創(chuàng)作

示例3:邏輯推理

模型技術(shù)特點(diǎn)
據(jù)官方介紹,SenseChat V5模型能力顯著提升,其背后是訓(xùn)練數(shù)據(jù)的全面升級(jí)與訓(xùn)練方法的有效提升。
在數(shù)據(jù)方面,SenseChat V5采用了新一代數(shù)據(jù)生產(chǎn)管線,生產(chǎn)了10T tokens的高質(zhì)量訓(xùn)練數(shù)據(jù)。通過(guò)多個(gè)模型進(jìn)行數(shù)據(jù)的過(guò)濾和提煉,顯著提升了預(yù)料質(zhì)量和信息密度;基于精細(xì)聚類(lèi)的均衡采樣確保對(duì)世界知識(shí)覆蓋的完整性。同時(shí),SenseChat V5還大規(guī)模采用了思維型的合成數(shù)據(jù)(數(shù)千億tokens量級(jí)),這對(duì)于模型在邏輯推理、數(shù)學(xué)和編程等方面的能力提升起到了關(guān)鍵作用。
SenseChat V5采用了自研的多階段訓(xùn)練鏈路,包括三階段預(yù)訓(xùn)練、雙階段SFT和在線RLHF。通過(guò)在每個(gè)階段設(shè)定更加清晰聚焦的目標(biāo),實(shí)現(xiàn)更敏捷的調(diào)優(yōu),也避免了不同目標(biāo)之間的相互干擾。其中在預(yù)訓(xùn)練階段,分階段培養(yǎng)模型的基礎(chǔ)語(yǔ)言和知識(shí)能力、長(zhǎng)文建模能力、以及復(fù)雜邏輯推理能力(規(guī)模化采用合成數(shù)據(jù));在 SFT 階段,把任務(wù)指令遵循和對(duì)話體驗(yàn)優(yōu)化分解到雙階段進(jìn)行;在 RLHF 階段,采用統(tǒng)一的多維度獎(jiǎng)勵(lì)模型和動(dòng)態(tài)系統(tǒng)提示詞對(duì)多維度偏好進(jìn)行打分,從而更好地實(shí)現(xiàn)模型在多個(gè)維度和人類(lèi)期望對(duì)齊。
審核編輯:劉清
-
GPT
+關(guān)注
關(guān)注
0文章
354瀏覽量
15446 -
AI大模型
+關(guān)注
關(guān)注
0文章
318瀏覽量
332
原文標(biāo)題:中文大模型測(cè)評(píng)基準(zhǔn)SuperCLUE:商湯「日日新5.0」總分80.03刷新最好成績(jī),文科能力領(lǐng)跑
文章出處:【微信號(hào):SenseTime2017,微信公眾號(hào):商湯科技SenseTime】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論