") 智譜AI領(lǐng)跑司南OpenCompass 2.0月度榜單,GLM-4展示強大實力
智譜AI領(lǐng)跑司南OpenCompass 2.0月度榜單,GLM-4展示強大實力
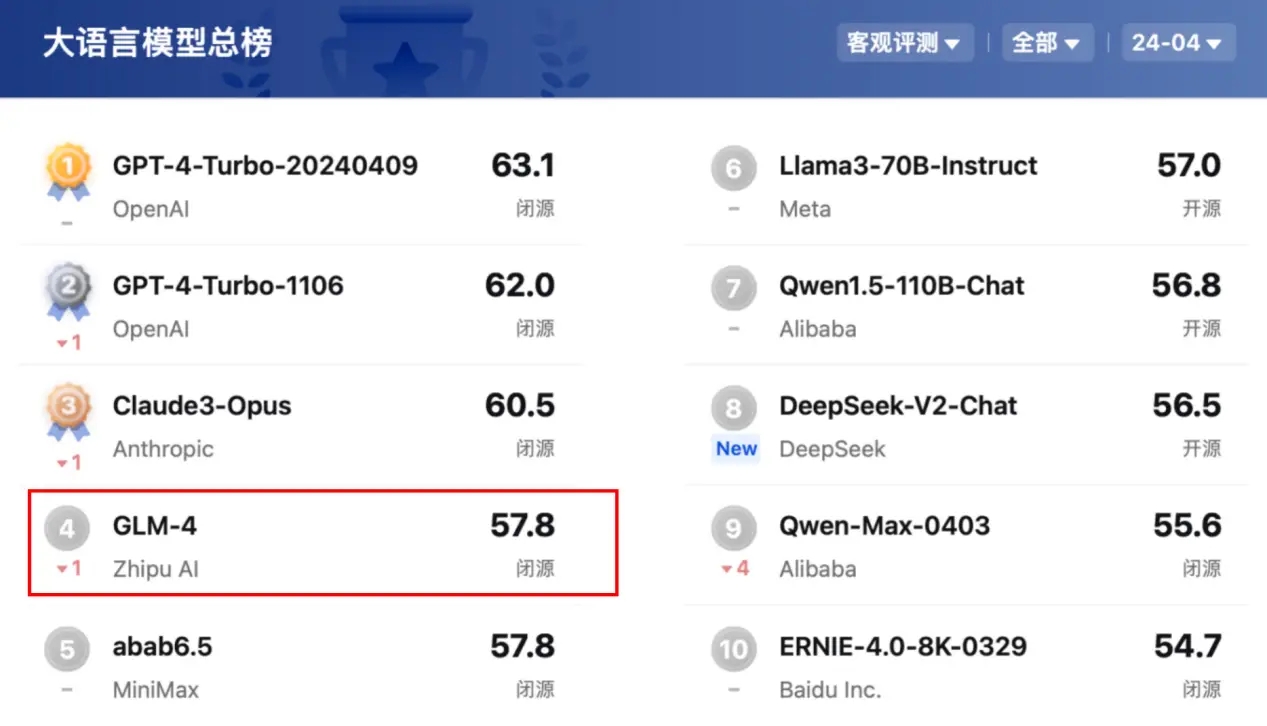
近期,大模型開源開放評測體系司南(OpenCompass 2.0)公布了2024年4月大語言模型最新評測榜單,智譜AI的GLM-4繼續(xù)保持國產(chǎn)大模型第一的領(lǐng)先身位。
大模型開源開放評測體系司南(OpenCompass 2.0)由上海人工智能實驗室發(fā)布。其月度榜單從基礎(chǔ)能力和綜合能力的設(shè)計出發(fā),構(gòu)建了一套高質(zhì)量的中英文雙語評測基準(zhǔn)體系,對主流開源模型和商業(yè)API模型進行了全面評測分析。評測榜單涉及的大語言模型和多模態(tài)大模型超過150個,更有包括Meta、阿里巴巴、騰訊、百度等30余家國內(nèi)外企業(yè)和科研機構(gòu)采用OpenCompass助力開展技術(shù)研發(fā)。
在4月客觀評測榜單中,OpenCompass基于語言、知識、推理、數(shù)學(xué)、代碼、智能體六個維度構(gòu)建了15000余道高質(zhì)量中英文雙語問題,并引入OpenCompass團隊首創(chuàng)的循環(huán)評估 (Circular Evalution) 策略,系統(tǒng)性分析了國內(nèi)外大模型的客觀性能。其中,GLM-4位列第四名,僅次于GPT-4-Turbo系列與Claude3-Opus,成為國內(nèi)大模型客觀評測月度總榜第一名。在語言維度方面,GLM-4分?jǐn)?shù)達到57.7分表現(xiàn)突出,超過GPT-4-Turbo系列與Claude3-Opus。在知識維度上,GLM-4得到68.9分,超過第二名的GPT-4-Turbo-1106,與第三名Claude3-Opus不相上下。
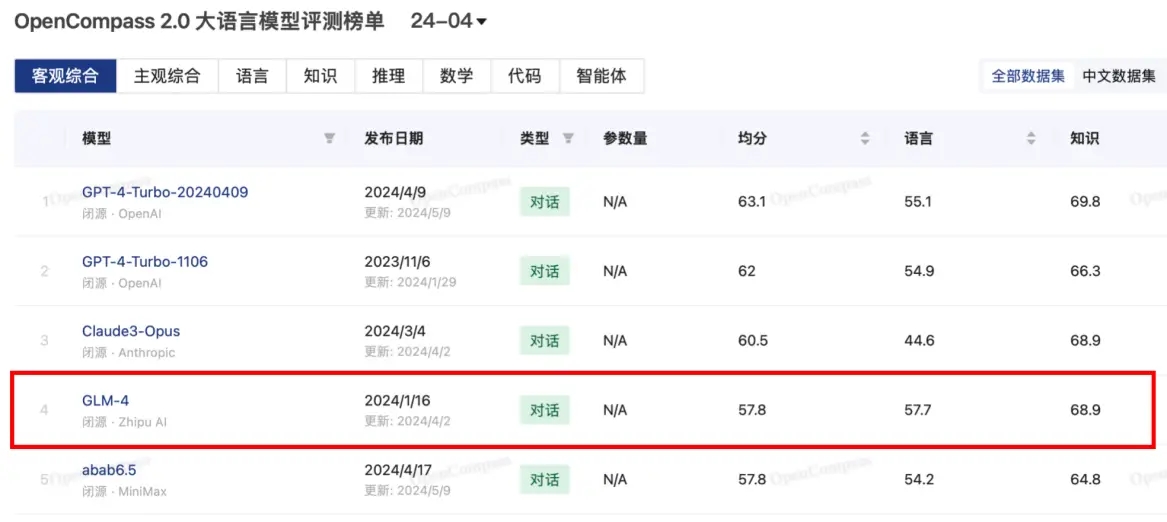
值得一提的是,GLM-4此前便長期占據(jù)OpenCompass 2.0榜單前列,并多次在權(quán)威榜單與全球頂級大模型一較高下。清華《SuperBench大模型綜合能力評測報告》顯示,GLM-4在語義理解等方面的能力表現(xiàn)超過了GPT-4-Turbo等國際一流模型,在代碼、智能體等方面,排名國內(nèi)第一。在SuperCLUE-Fin(SC-Fin)中文原生金融大模型測評基準(zhǔn)中,GLM-4斬獲一項A+及多項A級評價,在國內(nèi)大模型中排名第一。
據(jù)了解,GLM-4是由智譜AI于今年1月推出的新一代基座大模型。GLM-4整體性能逼近GPT-4,它可以支持更長的上下文,具備更強的多模態(tài)能力。同時,它的推理速度更快,支持更高的并發(fā),大大降低推理成本。依托GLM-4 All Tools能力,GLM-4智能體能夠?qū)崿F(xiàn)自主根據(jù)用戶意圖,自動理解、規(guī)劃復(fù)雜指令,自由調(diào)用網(wǎng)頁瀏覽器、Code Interpreter代碼解釋器和多模態(tài)文生圖大模型以完成復(fù)雜任務(wù)。
開發(fā)者可以通過智譜AI大模型開放平臺bigmodel.cn接入GLM-4模型開放API,便捷高效地體驗GLM-4的強大能力。
審核編輯 黃宇
-
API
+關(guān)注
關(guān)注
2文章
1501瀏覽量
62026 -
AI
+關(guān)注
關(guān)注
87文章
30896瀏覽量
269110 -
開源
+關(guān)注
關(guān)注
3文章
3349瀏覽量
42501 -
大模型
+關(guān)注
關(guān)注
2文章
2451瀏覽量
2714
發(fā)布評論請先 登錄
相關(guān)推薦
中科曙光的“數(shù)智化”領(lǐng)跑實力
利用OpenVINO部署GLM-Edge系列SLM模型
智譜推出四個全新端側(cè)模型 攜英特爾按下AI普及加速鍵
高通與智譜推動多模態(tài)生成式AI體驗的終端側(cè)部署
鈦動科技榮耀入選2024 CHINA AIGC 100榜單,彰顯AIGC應(yīng)用領(lǐng)先實力

智譜AI成立科技新公司
智譜AI宣布GLM-4-Flash大模型免費開放
智能硬件接入主流大模型做語音交互(附文心一言、豆包、kimi、智譜glm、通義千問示例)
2024世界人工智能大會:智譜AI引領(lǐng)"智譜小鎮(zhèn)"新紀(jì)元
智譜AI發(fā)布全新多模態(tài)開源模型GLM-4-9B
智譜AI獲沙特基金4億美元投資,估值達30億美元
智譜AI亮相2024 ICLR,分享面向AGI的三大技術(shù)趨勢






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論