 擊碎摩爾定律!英偉達和AMD將一年一款新品,均提及HBM和先進封裝
擊碎摩爾定律!英偉達和AMD將一年一款新品,均提及HBM和先進封裝
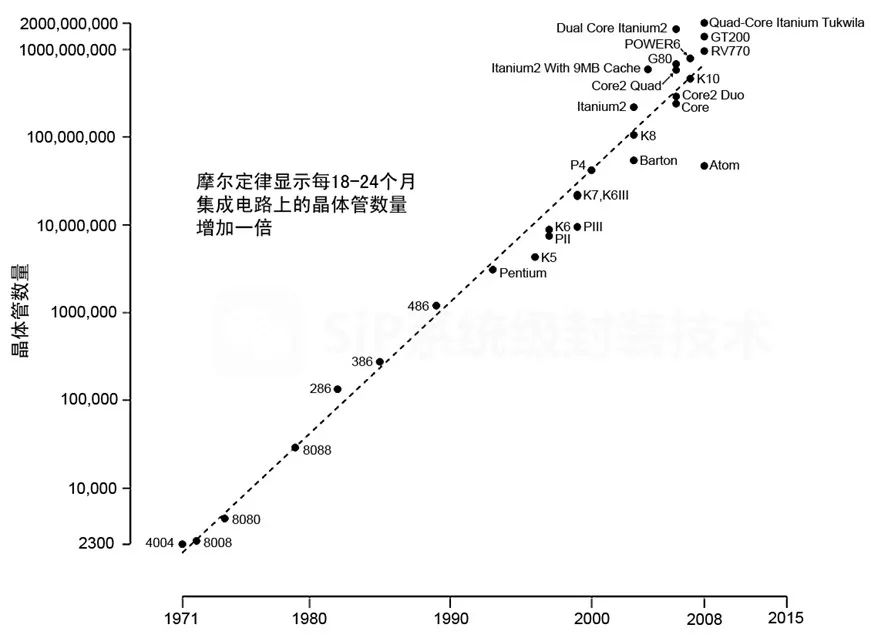
電子發燒友網報道(文/吳子鵬)摩爾定律是由英特爾創始人之一戈登·摩爾提出的經驗規律,描述了集成電路上的晶體管數量和性能隨時間的增長趨勢。根據摩爾定律,集成電路上可容納的晶體管數目約每隔18個月便會增加一倍,性能也將提升一倍。過去很長一段時間,摩爾定律被認為是全球半導體產業進步的基石。如今,這一定律已經逐漸失效,延續摩爾和超越摩爾路線紛紛出現。
6月2日晚間,英偉達創始人兼首席執行官黃仁勛在臺北國際電腦展(COMPUTEX)開幕前發表主題演講。他直言,英偉達承諾將以“一年一代”的節奏推出新的AI芯片。這一速度將明顯超越摩爾定律,因為英偉達每一代AI芯片的發布,相較于上一代,都能夠帶來數倍的性能提升。

隨后在6月3日,AMD首席執行官蘇姿豐在主題演講中同樣表示,AMD將于2025年推出MI350系列,再過一年會推出MI400。大約一年發布一款的速度與英偉達的計劃看齊。
一年一平臺,一年一產品
在演講中,黃仁勛透露了英偉達后續兩年的平臺路線,2025年英偉達AI芯片將基于Blackwell Ultra平臺,2026年是Rubin平臺,2027年則是Rubin Ultra平臺。
今年GTC大會上,英偉達發布了新一代的GPU架構平臺Blackwell和B200芯片產品。從架構來看,Blackwell架構用于數據中心,針對當前火爆的AI大模型優化,訓練、推理性能和能效均大幅提升。基于Blackwell架構,英偉達B200芯片由兩個超大型Die封裝而成,內含超過2080億個晶體管,是前一代800億個晶體管的兩倍以上,推理速度提升30倍以上,成本和能耗降低高達25倍。
黃仁勛表示,“Blackwell計算能力的增長是驚人的。但更重要的是,每當我們的計算能力提高時,成本卻在不斷下降。基于Blackwell平臺的芯片,用于訓練GPT-4模型(2萬億參數和8萬億Token)的能量下降了350倍。”
同時,黃仁勛稱,Blackwell芯片現已開始生產。不過,根據產業界的消息,量產上市的Blackwell芯片并不便宜,匯豐銀行分析師透露的數據顯示,GB200 NVL36/NVL72計算平臺的定價分別為180萬美元和300萬美元,GB200的定價為6萬至7萬美元,B100的定價為3萬至3.5萬美元。
不過,黃仁勛依舊是相同的觀點:英偉達的芯片,買得越多就會越便宜!

按照英偉達的規劃,2025年該公司將推出Blackwell Ultra AI芯片,將繼續引領全球AI 芯片的發展。和Blackwell Ultra平臺一起發布的還有下一代頻譜交換機。
然后到2026年,英偉達將推出Rubin架構,2027年推出Rubin Ultra AI芯片。雖然Ultra可能只是擴展,不過就像這個詞所代表的意思,預計英偉達將會在Ultra代上顯著增加芯片的規模和能力。
和英偉達一樣,AMD雖然加快了創新速度,但是創新質量卻很有保障。AMD將于今年推出采用第四代高帶寬內存(HBM)HBM3E的MI 325X芯片,內存帶寬提高一倍,效能提升1.3倍。明年推出的MI 350X將會采用3nm工藝基于CDNA 4架構,預計同系列性能增幅將創造AMD歷史之最。
HBM芯片和先進封裝成為革新要點
既然英偉達和AMD的AI芯片迭代已經在速度上超越了摩爾定律,也就代表著先進制程對于英偉達AI芯片有用,但又不是那么有用。能夠實現如此巨大的性能飛躍,有兩點是非常重要的:HBM顯存和先進封裝,前者突破了傳輸的限制,后者讓芯片規模超越了制程。無論是黃仁勛和蘇姿豐的演講,還是兩家公司近來的動作都體現了這一點。
上文提到,AMD將會在MI 325X芯片中使用HBM3E。根據黃仁勛的描述,英偉達將會在Rubin架構產品上首次支持8層HBM4高帶寬存儲,隨后在Rubin Ultra AI芯片上升級為12層HBM4。SK海力士總裁兼AI基礎設施負責人Justin Kim表示,該公司計劃和臺積電合作,采用臺積電的先進封裝技術,以打造出業界性能最佳的HBM4。
此前,作為AI芯片里HBM內存的主要供應商,SK海力士基本是采用專有的技術。據悉,SK海力士已使用專有技術制造高達HBM3E的基礎芯片。從技術細節來看,以硅通孔技術(TSV:Through Silicon Via)、批量回流模制底部填充(MR-MUF:Mass Reflow-Molded Underfill)先進封裝工藝作為核心技術,通過MR-MUF技術,SK海力士能打造出性能穩定且層數領先的HBM內存。
如果SK海力士也采用臺積電的先進封裝,那么將有助于英偉達和AMD的AI芯片更好地融合HBM4內存。根據臺灣媒體此前的報道,英偉達、AMD 兩家公司包下臺積電今明兩年CoWoS與SoIC先進封裝產能。英偉達目前的主力產品H100芯片主要采用臺積電4納米制程和CoWoS先進封裝,與SK海力士的高帶寬內存(HBM)以2.5D封裝形式提供給客戶。目前,英偉達芯片主要采用的CoWoS技術具備提供更高的存儲容量和帶寬的優勢,是目前高端先進封裝的主流方案。
將InfiniBand的性能帶到以太網架構中
除了平臺和芯片的劇透以外,此次英偉達黃仁勛演講還有一則值得關注的消息,那就是InfiniBand和以太網的融合。從生態來說,CUDA、NVLink和InfiniBand等多項私有方案的存在,也是英偉達和AMD等其他公司最明顯的不同,如今看來InfiniBand將率先擁抱開放。
英偉達的InfiniBand是一種高速網絡和輸入/輸出(I/O)技術,旨在連接數據中心和高性能計算(HPC)環境中的服務器、存儲系統和其他計算設備,具有低延遲、高帶寬、可擴展和高可靠等優勢。以太網則是一種廣泛用于局域網(LAN)的技術,基于IEEE 802.3以太網網絡標準,具有簡單性、靈活性和可擴展性。
可以說InfiniBand是英偉達專門為機器間信息傳輸打造的私有協議,屬于三類RDMA網絡其中之一,另外兩個是RoCE、iWARP。目前,英偉達已經在先進的芯片、超級計算架構和復雜的交換機方面形成產品體系,因此InfiniBand具有很高的價值。英偉達的InfiniBand技術來自邁絡思(Mellanox ),后者于2020年4月被英偉達收購。目前,英偉達提供全面的InfiniBand系統,包括InfiniBand交換機、InfiniBand網卡、InfiniBand以太網網關、InfiniBand線纜和光模塊、InfiniBand遙測和軟件管理以及InfiniBand加速軟件。目前,QUANTUM QM8700交換機單通道速度可達200Gb/s,整機的傳輸速度可達16Tb/s。
雖然InfiniBand技術性能強大,但是其兼容性并不好,以英偉達AI設備為主體的計算平臺很難融入其他的設備,這讓高性能計算的用戶很困擾,他們希望英偉達能夠支持更通用的協議——以太網。
目前,以太網技術已經支持RDMA,但是只限于RoCE和iWARP。就像黃仁勛所言,InfiniBand想要和以太網融合并不容易。在協議棧方面,InfiniBand 擁有自己定義的1-4層格式(物理層、鏈路層、傳輸層和網絡層),是一個完整的網絡協議,這些核心底層和以太網存在很大的差異,兩者的融合確實不易。
不過,受迫于客戶方的壓力,英偉達也在努力推進支持InfiniBand的以太網技術的發展,比如 Spectrum X。英偉達Spectrum以太網是一個端到端平臺,包括交換機、DPU、SmartNIC、線纜、收發器和網絡軟件。目前,英偉達以太網交換機系列包括涵蓋1GbE至800GbE的全面交換機和軟件產品組合。英偉達首席財務官Collette Kress此前表示,“Spectrum-X的銷量正在不斷增長,客戶包括多個客戶,其中包括一個擁有100,000個GPU的大型集群,Spectrum-X為英偉達網絡開辟了一個全新的市場,并使以太網數據中心能夠容納大規模 AI。我們預計Spectrum-X將在一年內躍升至數十億美元的產品線。”
對于InfiniBand和以太網的融合,黃仁勛介紹稱,英偉達的策略是將InfiniBand的性能帶到以太網架構中,“我們關注的焦點并非平均吞吐量,而是確保最后一個數據包能夠準時、無誤地抵達。然而,傳統的以太網并未針對這種高度同步化、低延遲的需求進行優化。為了滿足這一需求,我們創造性地設計了一個端到端的架構,使NIC(網絡接口卡)和交換機能夠通信。”
結語
過去很多年,摩爾定律都是芯片性能提升的主要手段,最新的工藝也會和頂級的芯片產品掛鉤。然而,隨著摩爾定律逐漸放緩和失效,目前英偉達和AMD等頭部廠商已經摸索出一條自己的更新路徑,這條路徑里工藝制程只是助力之一,更多源于HBM技術和異構集成的系統級創新。
-
amd
+關注
關注
25文章
5468瀏覽量
134151 -
摩爾定律
+關注
關注
4文章
634瀏覽量
79026 -
英偉達
+關注
關注
22文章
3776瀏覽量
91082 -
HBM
+關注
關注
0文章
380瀏覽量
14757 -
先進封裝
+關注
關注
2文章
404瀏覽量
246
發布評論請先 登錄
相關推薦
觀點評論 | 芯片行業,神奇的一年

三星電子或向英偉達供應先進HBM
高算力AI芯片主張“超越摩爾”,Chiplet與先進封裝技術迎百家爭鳴時代

“自我實現的預言”摩爾定律,如何繼續引領創新
封裝技術會成為摩爾定律的未來嗎?

英偉達CEO贊譽三星HBM內存,計劃采購
功能密度定律是否能替代摩爾定律?摩爾定律和功能密度定律比較
AMD將推新GPU,效能媲美英偉達RTX 4080
摩爾定律的終結:芯片產業的下一個勝者法則是什么?

中國團隊公開“Big Chip”架構能終結摩爾定律?





 工商網監
工商網監
評論