 商湯小浣熊榮獲中國信通院代碼大模型能力評估“三好生”
商湯小浣熊榮獲中國信通院代碼大模型能力評估“三好生”
“通用能力突出,專用場景全面,應用成熟度優秀”。
近日,商湯小浣熊代碼大模型在中國信通院“可信AI代碼大模型評估”中,榮獲4+級最高評級,成為國內首批通過該項評估的企業之一。
商湯小浣熊在代碼通用能力、專用場景和應用成熟度等多個評估維度中表現優秀。

依據中國信通院《智能化軟件工程技術和應用要求 第1部分:代碼大模型》,此次評估聚焦大模型的通用能力、專用場景能力和應用成熟度三大部分,包括16個能力項、100多個能力要求,從輸入多樣性、任務多樣性、語言完備度、結果可接收性、結果準確度等維度,考核代碼大模型的全棧技術能力。
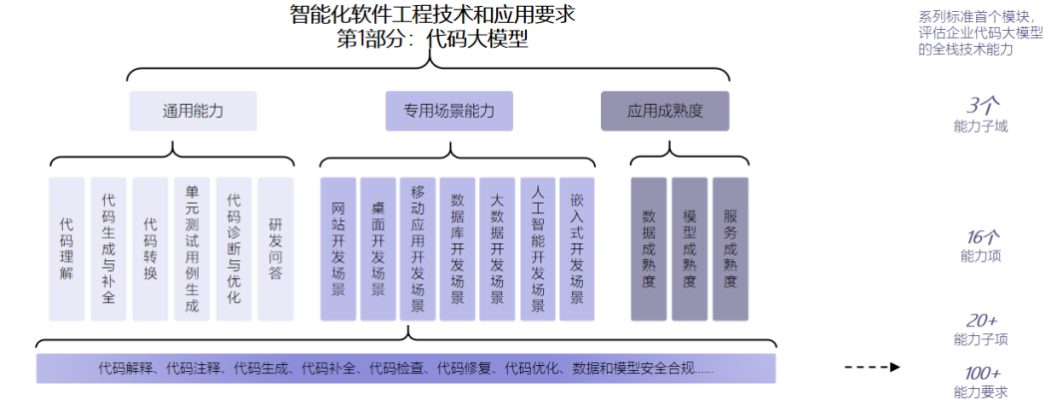
圖片來源:中國信通院
商湯小浣熊作為首批參評企業獲得4+級評級,是本次評分最高的代碼大模型之一。中國信通院測評結果顯示:
通用能力方面,小浣熊在代碼解釋、代碼轉換等方面表現突出;
專用場景方面,小浣熊支持網站開發、桌面應用開發、移動應用開發、數據庫開發等多個場景的開發能力;
應用成熟度方面,小浣熊在數據分類分級、模型性能、模型服務可維護性、風險可控性等方面均表現優秀。
「小浣熊家族」是基于商湯“日日新SenseNova”大模型體系打造的 AI Native 生產力系列工具,覆蓋軟件開發、數據分析、編程教育等多個場景,旨在通過先進的人工智能技術優化和提升工作效率。現已推出代碼小浣熊和辦公小浣熊兩位產品成員。
代碼小浣熊是基于大模型的軟件智能研發助手,覆蓋軟件需求分析、架構設計、代碼編寫、軟件測試等環節,滿足用戶代碼編寫、編程學習等各類需求,現已支持Python、Java、JavaScript、C++、Go、SQL等90+主流編程語言和VS Code、JetBrains全家桶、Android Studio等主流IDE。
辦公小浣熊是基于大模型的大模型原生數據分析產品,可以通過用戶的自然語言輸入,自動將數據轉化為有意義的分析和可視化結果。
小浣熊家族背后的「小浣熊代碼大模型」,在權威測試集HumanEval Coding測試中一次通過率達到78.1%,在數據分析場景下的數據測試集(1000+題目)中以85.71%的正確率超過GPT-4。
自上線以來,小浣熊代碼大模型累計為10萬+個人用戶提供服務,單日代碼生成數量達到10億+Tokens,總體平均代碼采納率超過30%,用戶編碼能效提升達到20%~78%。
目前,商湯小浣熊代碼大模型已經被包括金融、新能源汽車等行業在內的200+企業客戶使用,憑借突出的數理能力覆蓋多元落地場景。
例如,在與金山辦公的合作中,小浣熊代碼大模型助力WPS 365打造更高效釋放場景能力的智能辦公平臺,為用戶多元、碎片化的辦公需求提供新質生產力。
此外,基于小浣熊代碼大模型,商湯科技與海通證券合作打造智能研發助手,輔助金融企業研發人員進行代碼編程,為開發者提供代碼智能補全與對話問答服務,可輔助生產約20%代碼,降低開發技術門檻,有效提高開發效率。
未來,商湯小浣熊將持續降低大模型技術的開發和應用門檻,賦能更多場景創新。
-
代碼
+關注
關注
30文章
4788瀏覽量
68616 -
商湯
+關注
關注
0文章
55瀏覽量
3946 -
大模型
+關注
關注
2文章
2451瀏覽量
2714
原文標題:首批通過,最高評級,商湯小浣熊喜提中國信通院代碼大模型能力評估“三好生”
文章出處:【微信號:SenseTime2017,微信公眾號:商湯科技SenseTime】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
華為云云原生中間件 DCS?&?DMS?通過中國信通院與全球 IPv6 測試中心雙重能力檢測

權威認證 “圖撲軟件數字孿生低代碼平臺”獲中國信通院檢測認證
中國信通院發布“2024云計算十大關鍵詞”

中交興路入選中國信通院“卓信大數據計劃”

商湯AI大模型與中國國家籃球隊達成戰略合作
商湯科技與泰國DTGO集團聯合發布泰語大模型

華為云盤古研發大模型榮獲最高評級,引領行業創新
首批!數勢科技SwiftAgent完成中國信通院大模型驅動的智能數據分析工具專項測試
中國信通院主導制定首個代碼大模型國際標準
業界首個一云多芯遷移標準 中國信通院聯合浪潮云海發布

首家!數勢科技通過中國信通院數據指標管理平臺技術要求專項測試

IBM助力客戶贏得中國信通院“可信AI案例”獎
商湯科技發布5.0多模態大模型,綜合能力全面對標GPT-4 Turbo
加速布局智能制造 三菱電機與中國信通院共建重慶智能制造科創中心






 工商網監
工商網監
評論