") 動態(tài)線程池思想學習及實踐
動態(tài)線程池思想學習及實踐
相關文檔
美團線程池實踐:https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html 線程池思想解析:https://www.javadoop.com/post/java-thread-pool?
引言
在后臺項目開發(fā)過程中,我們常常借助線程池來實現(xiàn)多線程任務,以此提升系統(tǒng)的吞吐率和響應性;而線程池的參數配置卻是一個難以合理評估的值,雖然業(yè)界也針對cpu密集型,IO密集型等場景給出了一些參數配置的經驗與方案,但是實際業(yè)務場景中通常會因為流量的隨機性,業(yè)務的更迭性等情況出現(xiàn)預計和實際運行情況偏差較大的情況;而不合理的線程池參數,可能導致服務器負載升高,服務不可用,內存溢出等嚴重問題;一旦遇到參數不合理的問題,還需要重新上線修改,并且存在反復修改的情況,而這期間花費的時間可能帶來更大的風險,甚至導致嚴重業(yè)務事故;那么有沒有一種方式能有效感知上述問題并及時避免以上問題呢?或許動態(tài)線程池可以。
什么是動態(tài)線程池
簡單來說,動態(tài)線程池就是能在不重新部署應用的情況下動態(tài)實時變更其核心參數,并且能對其核心參數及運行狀態(tài)進行監(jiān)控及告警;以便開發(fā)人員可以及時感知到實際業(yè)務中因為各種隨機情況導致線程池異常的場景,并依據動態(tài)變更能力快速調整并驗證參數的合理性。
為什么需要動態(tài)線程池,存在什么痛點
線程池在給我們業(yè)務帶來性能和吞吐提升的同時,也存在諸多風險和問題,其中主要原因就在于我們難以設置出合理的線程池參數,一方面線程池的運行機制不是很好理解,配置合理強依賴開發(fā)人員的個人經驗和知識;另一方面,線程池執(zhí)行的情況和任務類型相關性較大,同時實際場景中流量的隨機性,業(yè)務的更迭性也導致業(yè)界難以有一套成熟或開箱即用的經驗策略來幫助開發(fā)人員參考。而線程池參數難以合理設置的特性又不得不讓我們關注以下三個痛點問題:
1.運行情況難感知:在業(yè)務使用線程池的過程中,線程池的運行情況對于開發(fā)人員來說很難感知,我們難以知道每個線程池創(chuàng)建了多少個線程,是否有隊列積壓,線程池運行狀態(tài)怎么樣,線程池是否已經耗盡... 直到出現(xiàn)線上問題或收到客訴才后知后覺;(我們能否對系統(tǒng)中用到的線程池進行一個整體的把控,在線程池任務積壓,任務拒絕等問題發(fā)生時,甚至問題發(fā)生前進行及時感知,讓開發(fā)人員能未雨綢繆,盡早發(fā)現(xiàn)和解決問題呢?-線程池監(jiān)控,異常告警)
流量突增導致預估和實際情況偏差較大,同時由于未能及時感知并解決積壓情況,最終引發(fā)客訴 case1:廣告主大批量刪除物料后異步清理附屬表出現(xiàn)任務積壓 問題描述:廣告主批量刪除計劃物料后,對應物料附屬表數據未及時刪除,導致廣告主關鍵詞等物料數上限得不到釋放而影響創(chuàng)建新物料,引發(fā)線上客訴。 問題原因:廣告主刪除計劃物料后,系統(tǒng)會同步刪除計劃物料主表信息,然后通過線程池的方式異步刪除計劃物料附屬表數據。臨近大促廣告主物料增刪頻率及單次批量操作的物料數量都有明顯增加,由于核心線程設置較小同時隊列設置過長,導致計劃主表同步刪除后異步刪除附屬表的任務出現(xiàn)隊列積壓,對應的關鍵詞等物料數上限得不到釋放而影響新物料創(chuàng)建,引發(fā)線上客訴。
?
2.線程拒絕難定位:當拒絕發(fā)生后,即使我們迅速感知到了線程池運行異常,也經常會因為拒絕持續(xù)時間較短而拿不到問題發(fā)生時的線程堆棧,因此通常難以快速定位甚至無法定位到是哪里的原因導致的拒絕,比如是流量的突增將線程池打滿,還是某個業(yè)務邏輯耗時較長將線程池中的線程拖住;(我們有沒有一種方式能在線程池拒絕后去更容易的定位到問題呢?-自動觸發(fā)線程池堆棧打印,分析工具)
case2: 線程池拒絕具有隨機性,當拒絕時長較短時,難以定位問題原因 問題描述:某業(yè)務接口內部計算邏輯較多,且存在多處外部接口調用邏輯,上線后不定時出現(xiàn)線程池拒絕異常,由于持續(xù)時間不長,問題發(fā)生后無法通過jstack去獲取問題發(fā)生時現(xiàn)場的線程堆棧, 很難定位是什么原因導致了線程池拒絕;由于沒有較好的排查手段,只能通過逐步摟日志的方式排查,而排查過程又可能因為日志較多或者日志不全出現(xiàn)問題定位時間長或者是根本無法定位的情況。 問題原因:某外部某接口不穩(wěn)定,在性能較差且流量較大時就容易把調用線程池打滿,導致可用率下降
?
3.參數問題難以快速調整:在定位到某個線程池參數設置不合理的情況后,我們需要根據情況隨即進行調整,但是"修改->打包->審批->發(fā)布"的時間很可能會擴大問題的影響甚至是事故嚴重程度;同時因為線程池參數難以合理設置的原因,可能導致我們要重復進行上述"修改->打包->審批->發(fā)布"的流程...(有沒有一種方法能快速修改并驗證參數設置的合理性呢?-參數動態(tài)調整)
線程池參數設置不合理,難以快速調整參數,業(yè)務風險上升 case3:應用JSF接口修改為異步調用后出現(xiàn)可用率下降 問題描述:將應用中部分JSF接口切換為異步模式后,對應可用率有明顯下降 問題原因:在修改為異步模式的JSF接口中,部分業(yè)務在拿到future對象后使用ThenApply做了一些耗時的操作,另外還有一部分在ThenApply里面又調用了另外一個異步方法;而thenApply的執(zhí)行會使用jsf的callBack線程池,由于線程池線程配置較小,并且部分回調方法耗時較長,導致callBack線程池被打滿,子任務請求線程時進入阻塞隊列排隊,出現(xiàn)接口超時可用率下降。
業(yè)界動態(tài)線程池動態(tài)線程池調研
當前業(yè)界已存在部分動態(tài)線程池組件,其主體功能及大體思想類似,但存在以下幾個問題
1.與外部中間件耦合較多,難以二次開發(fā)加以使用;
2.使用靈活性受限,難以根據業(yè)務自身特點進行定制化(自動觸發(fā)線程池堆棧打印,一鍵清空隊列,callback線程池等)
綜合考慮上述問題,決定結合公司中間件及自身業(yè)務特點實現(xiàn)一套集線程池監(jiān)控,異常告警,線程棧自動獲取,動態(tài)刷新為一體的動態(tài)線程池組件。
如何實現(xiàn)動態(tài)線程池
整體方案
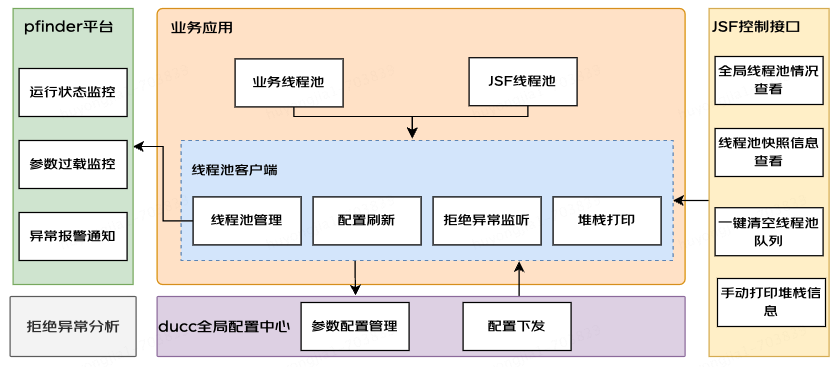
線程池監(jiān)控及告警
要實現(xiàn)線程池監(jiān)控及告警,我們需要關注以下幾個要點
1.如何獲取到待監(jiān)控的線程池信息
在實際業(yè)務中我們通常想要知道應用中有哪些線程池,每個線程池各個參數在每個時刻的運行情況是怎么樣的;對于第一種場景,我們可以構建一個線程池管理器,用于管理應用中使用到的業(yè)務線程池,為此我們可以在應用初始化時將這些線程池按名稱和實際對象注冊到管理器;后續(xù)使用時就可以根據名稱從管理中心拉取到對應線程池;
public class ThreadPoolManager {
// 線程池管理器
private static final ConcurrentHashMap REGISTER_MAP_BY_NAME = new ConcurrentHashMap();
private static final ConcurrentHashMap REGISTER_MAP_BY_EXECUTOR = new ConcurrentHashMap();
// 注冊線程池
public static void registerExecutor(String threadPoolName, Executor executor) {
REGISTER_MAP_BY_NAME.putIfAbsent(threadPoolName, executor);
REGISTER_MAP_BY_EXECUTOR.putIfAbsent(executor, threadPoolName);
}
// 根據名稱獲取線程池
public static Executor getExecutorByName(String threadPoolName) {
return REGISTER_MAP_BY_NAME.get(threadPoolName);
}
// 根據線程池獲取名稱
public static String getNameByExecutor(Executor executor) {
return REGISTER_MAP_BY_EXECUTOR.get(executor);
}
// 獲取所有線程池名稱
public static Set getAllExecutorNames() {
return REGISTER_MAP_BY_NAME.keySet();
}
}
對于第二種場景,線程池的核心實現(xiàn)類ThreadPoolExecutor提供了多個參數查詢方法,我們可以借助這些方法查詢某一時刻該線程池的運行快照
getCorePoolSize() // 核心線程數 getMaximumPoolSize() // 最大線程數 getQueue() // 阻塞隊列,獲取隊列大小,容量等 getActiveCount() // 活躍線程數 getTaskCount() // 歷史已完成和正在執(zhí)行的任務數量 getCompletedTaskCount() // 已完成任務數
2.如何將監(jiān)控的信息保存和展示出來
監(jiān)管了應用中的業(yè)務線程池,也能獲取到某一時刻各線程池的運行情況快照,但要實現(xiàn)線程池數據監(jiān)控還需要我們在每個時刻去采集線程池運行信息,并將其保存下來,同時還需要將這些數據用一個可視化頁面展示出來供我們觀察才行,否則我們只知道某一時刻的線程池情況也意義不大。為此,我們需要考慮上面看到的過程,例如使用Micrometer采集性能數據,使用Prometheus時序數據庫存儲指標數據,使用Grafana展示數據;而現(xiàn)在,我們只需要根據pfinder的埋點要求將對應要監(jiān)控的線程池指標配置到上報邏輯即可,剩下的數據分時采集,數據存儲,數據展示可以完全交給pfinder來完成。
// 已經設置埋點的線程池
public static ConcurrentHashSet monitorThreadPool = new ConcurrentHashSet();
// 監(jiān)控埋點注冊
public static void monitorRegister() {
log.info("===> monitor register start...");
// 1.獲取所有線程池
Set allExecutorNames = ThreadPoolManager.getAllExecutorNames();
// 2.遍歷線程池,注冊埋點
allExecutorNames.forEach(executorName-> {
if (!monitorThreadPool.contains(executorName)) {
monitorThreadPool.add(executorName);
Executor executor = ThreadPoolManager.getExecutorByName(executorName);
collect(executor, executorName);
}
});
log.info("===> monitor register end...");
}
// pfinder指標埋點
public static void collect(Executor executorService, String threadPoolName) {
ThreadPoolExecutor executor = (ThreadPoolExecutor)executorService;
String prefix = "thread.pool."+threadPoolName;
gauge1 = PfinderContext.getMetricRegistry().gauges(prefix)
.gauge(() -> executor.isShutdown() ? 0 : executor.getCorePoolSize())
.tags(MetricTag.of("type_dimension", "core_size")).build();
gauge2 = PfinderContext.getMetricRegistry().gauges(prefix)
.gauge(() -> executor.isShutdown() ? 0 : executor.getMaximumPoolSize())
.tags(MetricTag.of("type_dimension", "max_size"))
.build();
gauge4 = PfinderContext.getMetricRegistry().gauges(prefix)
.gauge(() -> executor.isShutdown() ? 0 : executor.getQueue().size())
.tags(MetricTag.of("type_dimension", "queue_size"))
.build();
}
3.如何監(jiān)聽到異常并告警
線程池運行過程中,我們可能更多關注線程池拒絕前感知線程池隊列是否有積壓,線程數是否已達設置核心或最大線程數高點以及線程池拒絕異常;由于使用pfinder作為線程池監(jiān)控組件,其中線程池隊列是否有積壓,線程數是否已達設置核心,最大線程數高點等異常監(jiān)聽及告警可以直接依賴pfinder的告警配置來實現(xiàn); 例如下圖中配置隊列積壓超過閾值時的報警
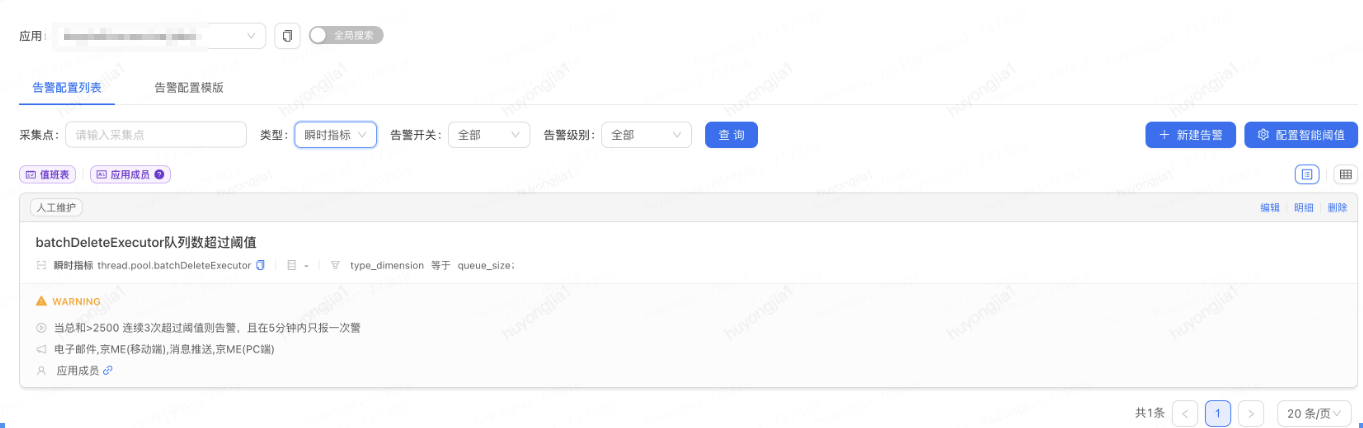
而線程池拒絕異常,我們可以在線程池初始化時包裝線程池的拒絕策略,在執(zhí)行實際拒絕策略前拋出告警;
@Slf4j
public class RejectInvocationHandler implements InvocationHandler {
private final Object target;
@Value("${jtool.pool.reject.alarm.key}")
private String key;
public RejectInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
ExecutorService executor = (ExecutorService)args[1];
if (Strings.equals(method.getName(), "rejectedExecution")) {
try {
rejectBefore(executor);
}
catch (Exception exp) {
log.error("==> Exception while do rejectBefore for pool [{}]", executor, exp);
}
}
return method.invoke(target, args);
}
private void rejectBefore(ExecutorService executor) {
// 觸發(fā)報警
rejectAlarm(executor);
}
/**
* 拒絕報警
*/
private void rejectAlarm(ExecutorService executor) {
String alarmKey = Objects.nonNull(key) ? key : ThreadPoolConst.UMP_ALARM_KEY;
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor)executor;
String threadPoolName = ThreadPoolManager.getNameByExecutor(threadPoolExecutor);
String errorMsg = String.format("===> 線程池拒絕報警 key: [%s], cur executor: [%s], core size: [%s], max size: [%s], queue size: [%s], curQueue size: [%s]",
alarmKey, threadPoolName, threadPoolExecutor.getCorePoolSize(), threadPoolExecutor.getMaximumPoolSize(), threadPoolExecutor.getQueue().size()+threadPoolExecutor.getQueue().remainingCapacity(), threadPoolExecutor.getQueue().size());
log.error(errorMsg);
Profiler.businessAlarm(alarmKey, errorMsg);
}
}
自動觸發(fā)線程堆棧打印
感知到拒絕線程池拒絕異常后,我們需要及時去定位線程池拒絕原因,但現(xiàn)在我們可能只知道是哪個線程池發(fā)生了線程池拒絕異常,卻難以知道是什么原因導致的,我們常常希望在線程池拒絕時能拿到應用的線程堆棧信息,并依據其分析拒絕原因;但是線程拒絕常常發(fā)生速度很快,我們很難捕捉到拒絕時刻的全局線程堆棧快照;為此,我們考慮在線程池拒絕發(fā)生時自動觸發(fā)線程池堆棧打印到日志;
public class RejectInvocationHandler implements InvocationHandler {
...
private void rejectBefore(ExecutorService executor) {
// 打印線程堆棧到日志的間隔條件
if (CommonProperty.canPrintStackTrace()) {
// 觸發(fā)報警
rejectAlarm(executor);
// 觸發(fā)線程堆棧打印
printThreadStack(executor);
}
}
...
}
...
/**
* 打印線程堆棧信息
*/
public static void printThreadStack(Executor executor) {
if (!CommonProperty.logPrintFlag) {
log.info("===> 線程池堆棧打印關閉:[{}]", CommonProperty.logPrintFlag);
return;
}
logger.info("n=================>>> 線程池拒絕堆棧打印start,觸發(fā)提交拒接處理的線程池:【{}】", executor);
Map allStackTraces = Thread.getAllStackTraces();
log.info("===> allStackTraces size :[{}]", allStackTraces.size());
StringBuilder stringBuilder = new StringBuilder();
allStackTraces.entrySet().stream()
.sorted(Comparator.comparing(entry -> entry.getKey().getName()))
.forEach(threadEntry -> {
Thread thread = threadEntry.getKey();
stringBuilder.append(Strings.format("n線程:[{}] 時間: [{}]n", thread.getName(), new Date()));
stringBuilder.append(Strings.format("tjava.lang.Thread.State: {}n", thread.getState()));
StackTraceElement[] stack = threadEntry.getValue();
for (StackTraceElement stackTraceElement : stack) {
stringBuilder.append("tt").append(stackTraceElement.toString()).append("n");
}
stringBuilder.append("n");
logger.info(stringBuilder.toString());
stringBuilder.delete(0, stringBuilder.length());
});
logger.info("==============>>> end");
}
...
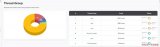
打印后的信息如下所示
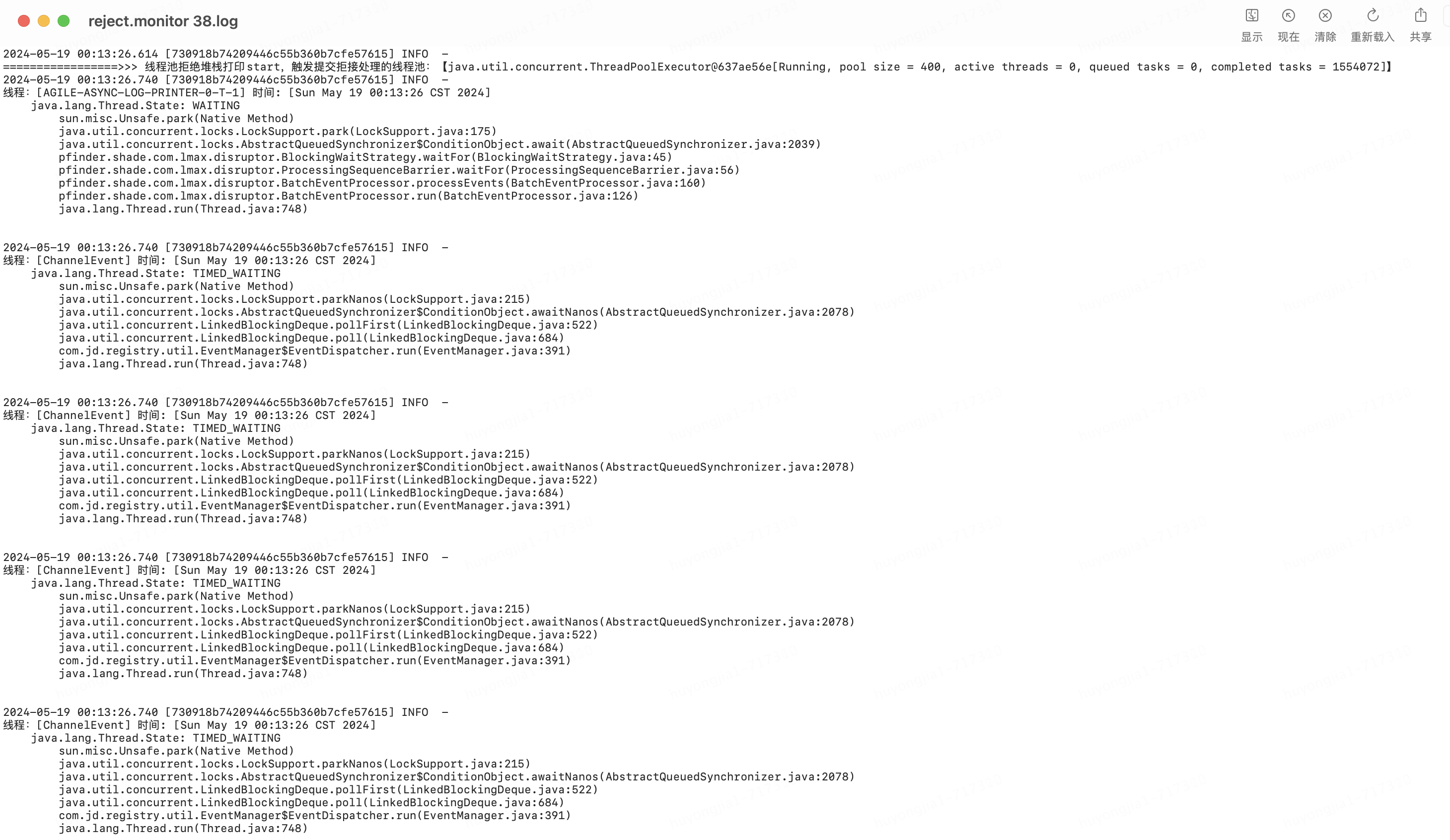
拿到問題發(fā)生時的堆棧信息后,我們就可以根據拒絕線程的名稱去分析拒絕原因了,看看是否有什么原因導致線程被卡住;為了更方便的分析,可以根據簡單的根據日志規(guī)則去分析拒絕線程池問題發(fā)生時各線程池的運行狀態(tài)是什么,大部分都集中到了哪個方法的哪個位置
public class ThreadLogAnalyzer {
public static void main(String[] args) {
String logFilePath = "/Users/huyongjia1/Desktop/huyongjia/demo/jsfdemo/MyJtool/src/main/resources/reject.monitor 21.log";
String threadPoolNameLike = "simpleTestExecutor";
int threadCount = 0;
HashMap statusMap = new HashMap();
HashMap methodMap = new HashMap();
try (BufferedReader br = new BufferedReader(new FileReader(logFilePath))) {
String line;
while ((line = br.readLine()) != null) {
if (line.contains("=================>>> 線程池拒絕堆棧打印start,觸發(fā)提交拒接處理的線程池")) {
System.out.println("開始讀整個線程");
}
if (line.contains(threadPoolNameLike)) {
threadCount++;
String curStatus = br.readLine();
if (curStatus.contains("java.lang.Thread.State")) {
statusMap.put(curStatus, (statusMap.getOrDefault(curStatus, 0) + 1));
String methodTrace = br.readLine();
methodMap.put(methodTrace, (methodMap.getOrDefault(methodTrace, 0) + 1));
}
}
if (line.contains("==============>>> end")) {
System.out.println("結束讀整個線程");
}
}
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(Strings.format("===> 當前線程名[{}]共計:{}", threadPoolNameLike, threadCount));
System.out.println("n===> 狀態(tài)分析結果:");
for (Map.Entry statusEntry : statusMap.entrySet()) {
System.out.println(Strings.format("t {} {}", statusEntry.getKey(), statusEntry.getValue()));
}
System.out.println("n===> 方法分析結果:");
ArrayList> methodEntryList = Lists.newArrayList(methodMap.entrySet());
methodEntryList.sort(new Comparator>() {
@Override
public int compare(Map.Entry o1, Map.Entry o2) {
return o2.getValue() - o1.getValue();
}
});
for (Map.Entry methodEntry : methodEntryList) {
System.out.println(Strings.format("{} {} {}%", methodEntry.getKey(), methodEntry.getValue(), (methodEntry.getValue() / (double)threadCount) * 100));
}
}
}
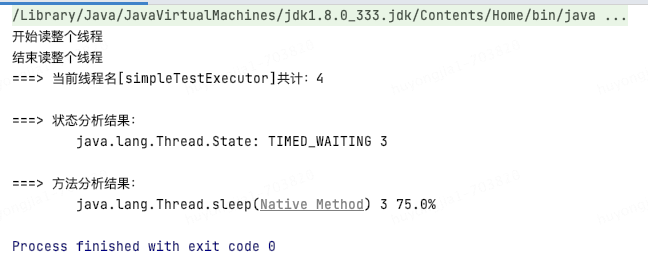
例如當前收到simpleTestExecutor線程池拒絕告警,利用堆棧信息分析如下,可以看到該線程池共4個線程,其中3個的運行狀態(tài)為TIMED_WAITING,并且都停在了sleep邏輯處
線程池參數動態(tài)刷新
要實現(xiàn)線程池參數動態(tài)刷新,我們需要關注以下幾個要點:
1.哪些參數需要變更
在使用線程池時,我們通常需要配置多個參數,但是實際上我們只需要靈活配置好corePoolSize(核心線程數),maximumPoolSize(最大線程數),workQueue(隊列長度)這三個核心參數就可以應對大部分場景了;
2.運行中的線程池如何變更參數
從前面我們可以知道線程池的核心實現(xiàn)類ThreadPoolExecutor提供了改變corePoolSize,maximumPoolSize的兩個快捷方法:
1. setCorePoolSize(int corePoolSize)
2. setMaximumPoolSize(int maximumPoolSize)
我們只需要通過rpc或者http的方式將想要變更的參數傳遞到應用再利用上述方法設置進去即可;而隊列長度的變更卻相對麻煩點,因為我們常使用的阻塞隊列LinkedBlockingQueue將隊列大小設置為成了一個final類型的變量,我們無法快捷變更,那該怎么辦呢,其中一個思想就是自定義一個LinkedBlockQueue,修改capacity為非final類型,同時考慮并發(fā)問題對其中涉及到的方法進行修改;(可參考RabbitMq中的VariableLinkedBlockingQueue)
3.應用集群場景下如何實現(xiàn)一鍵參數變更
實際情況下,我們的應用是已集群的方式部署的,這時我們可以借助ducc全局配置工具將要變更的參數傳遞到集群的各個機器,各機器根據再根據參數中的線程池名稱去線程池管理中心拿到對應的線程進行參數變更即可;
/**
* ducc控制線程池刷新方法, 需要動態(tài)刷新的線程池信息列表,舉例如下:
* value:
* [
* {
* "threadPoolName": "my_pool",
* "corePoolSize": "10",
* "maximumPoolSize": "20",
* "queueCapacity": "100"
* }
* ]
*/
@LafValue("jtool.pool.refresh")
public void refresh(@JsonConverter List threadPoolProperties) {
String jsonString = JSON.toJSONString(threadPoolProperties);
log.info("===> refresh thread pool properties [{}]", jsonString);
threadPoolProperties = JSONObject.parseArray(jsonString, ThreadPoolProperties.class);
refresh(threadPoolProperties);
}
public static boolean refresh(List threadPoolProperties) {
if (Objects.isNull(threadPoolProperties)) {
log.warn("refresh param is empty!");
return false;
}
log.info("Executor refresh param: [{}]", threadPoolProperties);
// 1.根據參數獲取對應的線程池
threadPoolProperties.forEach(threadPoolProperty -> {
String threadPoolName = threadPoolProperty.getThreadPoolName();
Executor executor = ThreadPoolManager.getExecutorByName(threadPoolName);
if (Objects.isNull(executor)) {
log.warn("Register not find this executor: {}", threadPoolName);
return;
}
// 2. 線程池刷新
refreshExecutor(executor, threadPoolName, threadPoolProperty);
log.info("Refresh thread pool finish, threadPoolName: [{}]", threadPoolName);
});
return true;
}
實踐效果
線程池監(jiān)控
達成目的:對應用中的線程池情況做整體把控,能方便獲取各線程池的運行情況
接入pfinder監(jiān)控后的效果如下
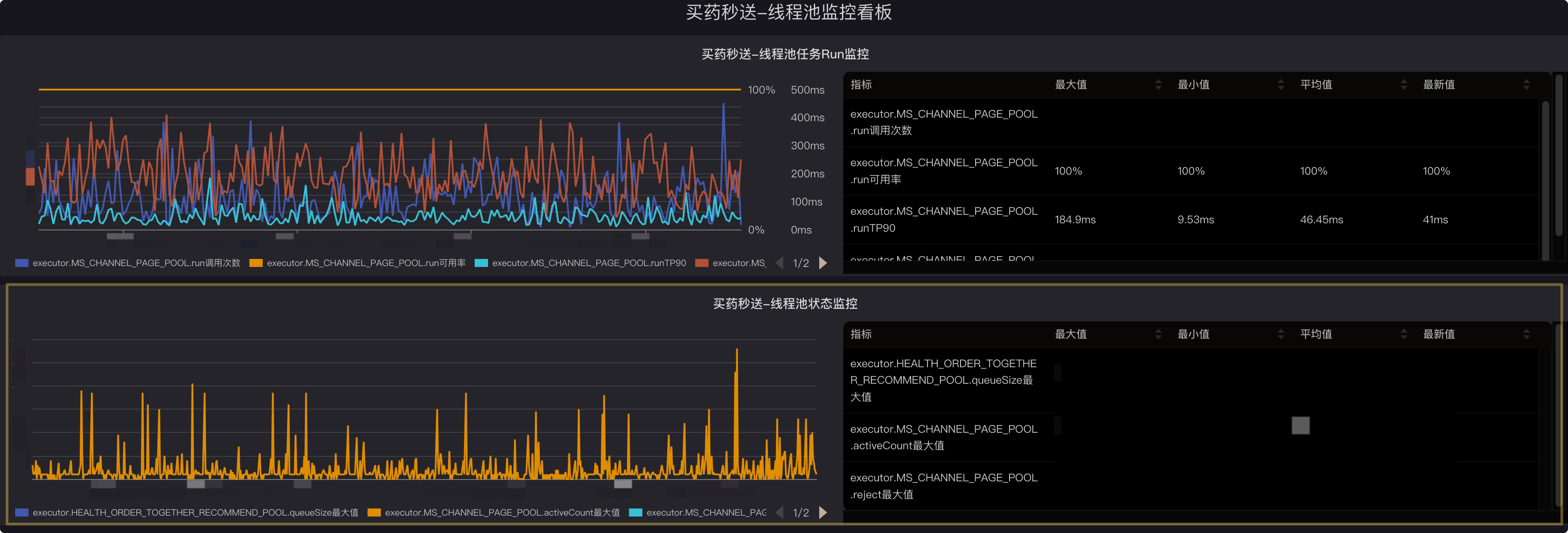
1.pfinder監(jiān)控:注冊的監(jiān)控線程池會自動上報線程池的活躍,核心,最大,隊列大小,隊列容量,任務數等指標;監(jiān)控地址在pfinder當前服務的業(yè)務監(jiān)控中,正確接入后可以看到已經被監(jiān)控的線程池列表,監(jiān)控埋點名稱: thread.pool.{線程池名稱}
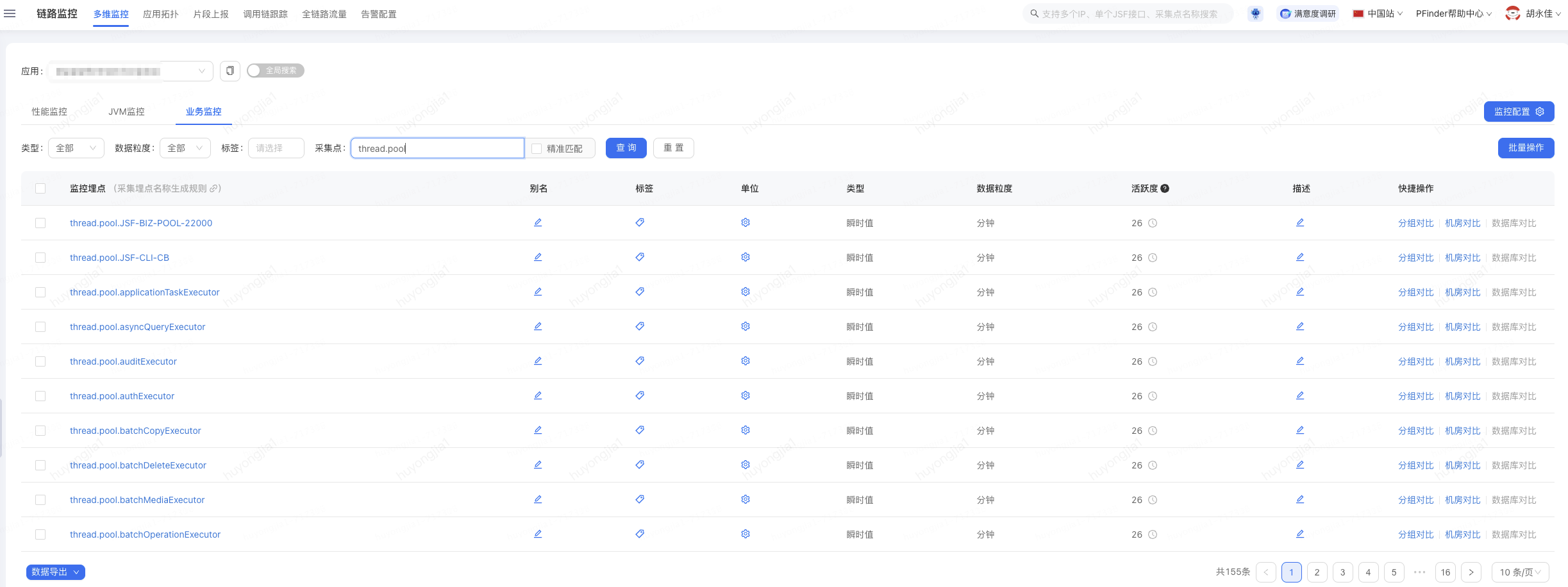
如果要看某一個線程池的指標數據,可以單獨進入某個線程池的監(jiān)控,其中通過數據選擇要看的指標(type_dimension)
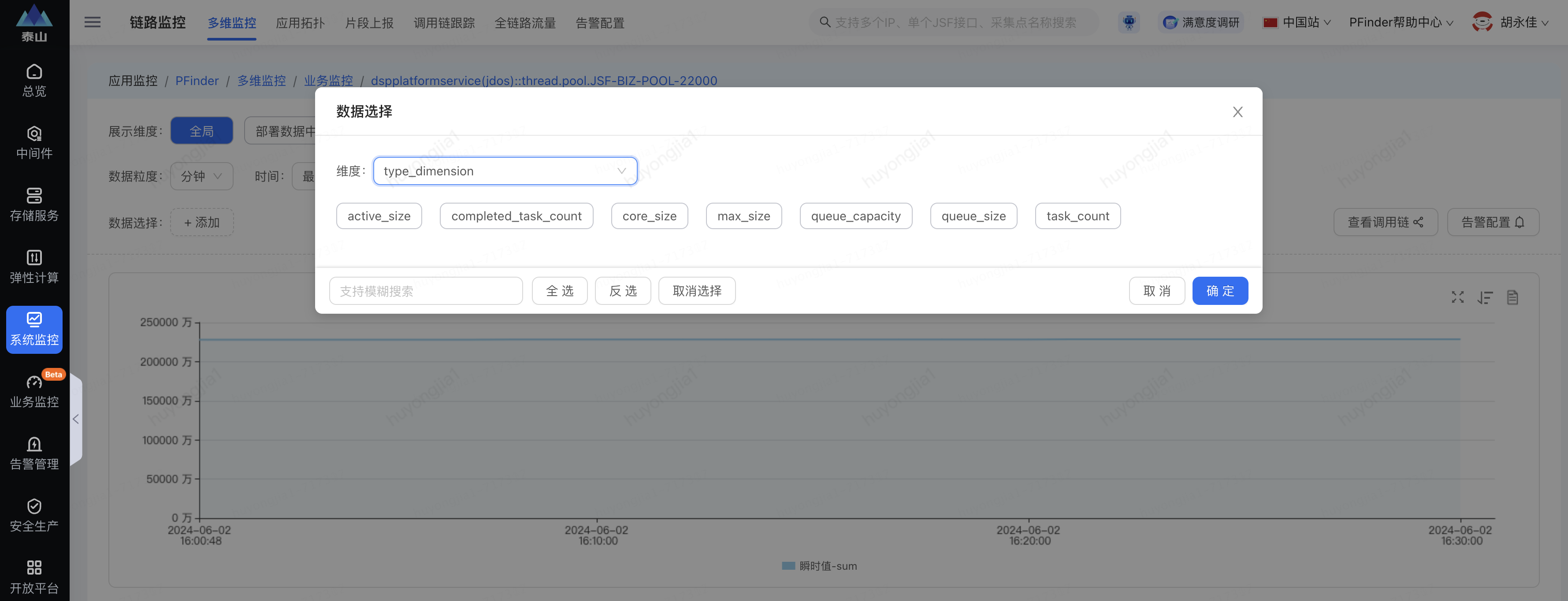
可在展示維度中選擇要具體展示的維度,比如分組,實例等
1.當前監(jiān)控數據為分鐘級維度,即按分鐘粒度展示線程池參數的瞬時值,如果需要更精細化的數據,可以選擇pfinder的秒級監(jiān)控
2.支持監(jiān)控指標:
| 監(jiān)控指標 | 指標值 |
| 線程池核心參數 | core_size |
| 線程池最大線程參數 | max_size |
| 當前活躍線程數 | active_size |
| 阻塞隊列容量(設置的大小) | queue_capacity |
| 阻塞隊列當前大小(是否有排隊) | queue_size |
| 線程池完成任務數 | completed_task_count |
此外,可以通過JSF接口查看當前時刻應用中的線程信息快照,當前時刻被監(jiān)控的線程池有哪些:
感知異常告警
達成目的:及時感知線程池異常情況,避免問題放大
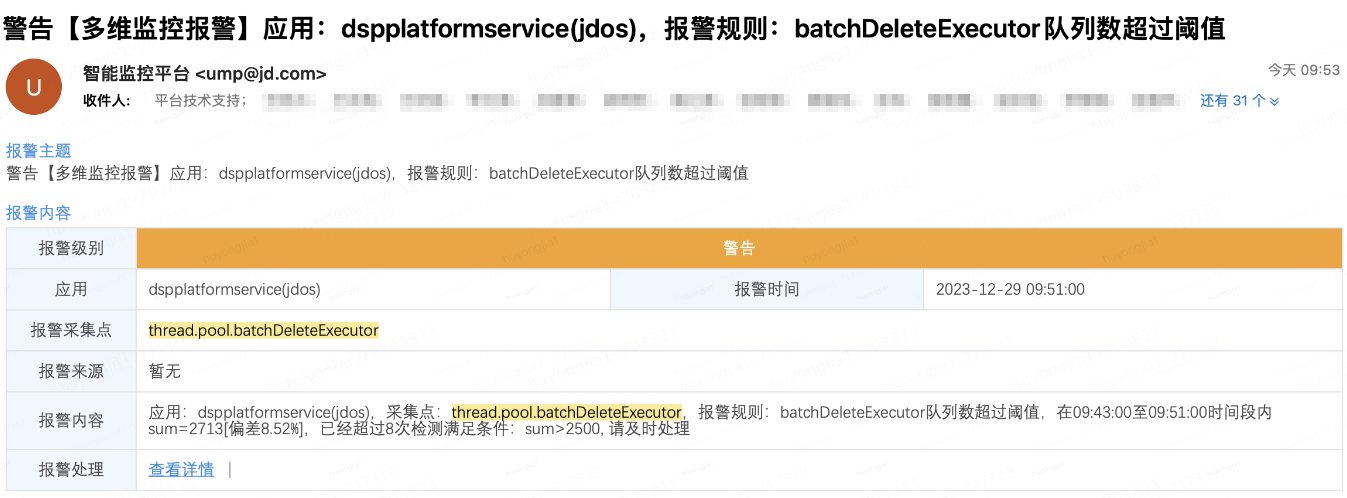
以隊列積壓和線程池拒絕告警為例
隊列積壓告警(郵件):
線程池拒絕告警(咚咚):

自動觸發(fā)線程堆棧打印
達成目的:自動記錄問題發(fā)生時的線程堆棧,為線程池拒絕異常排查提供思路,并加快問題定位
實踐案例1:
大促期間對核心接口的壓測途中,突然收到偶發(fā)機器的JSF線程池拒絕告警

實際分析發(fā)現(xiàn)拒絕時間較短,整體持續(xù)時間不到1分鐘
下圖因為線程不夠瞬間打上去的線程數持續(xù)時間
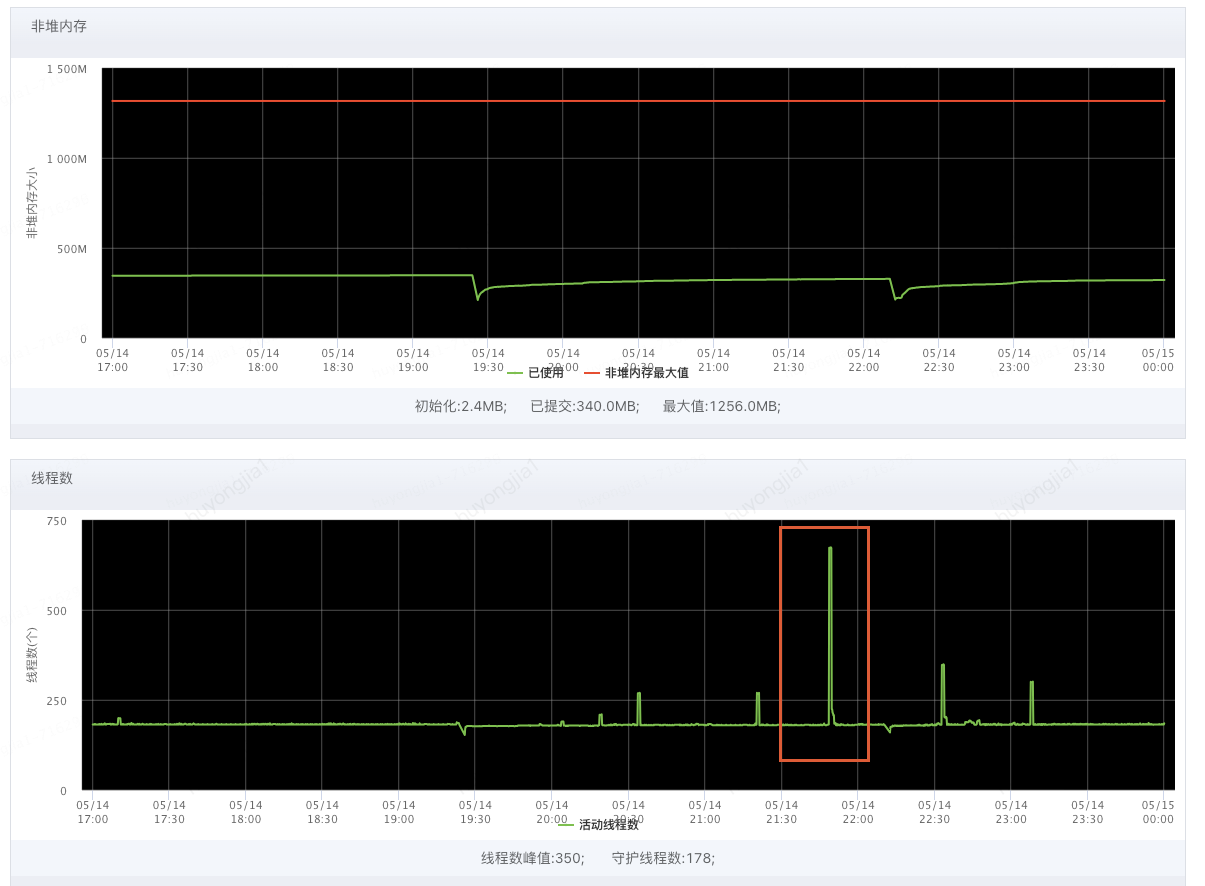
由此來看我們難以通過人工觸發(fā)jstack的方式在短時間內獲取到問題發(fā)生時的線程堆棧,也因此無法定位到具體拒絕原因;因此我們嘗試借助線程池拒絕時自動打印的線程堆棧分析,自動打印機制會在線程池發(fā)生拒絕策略的同時將全局線程堆棧打印到機器對應的日志目錄
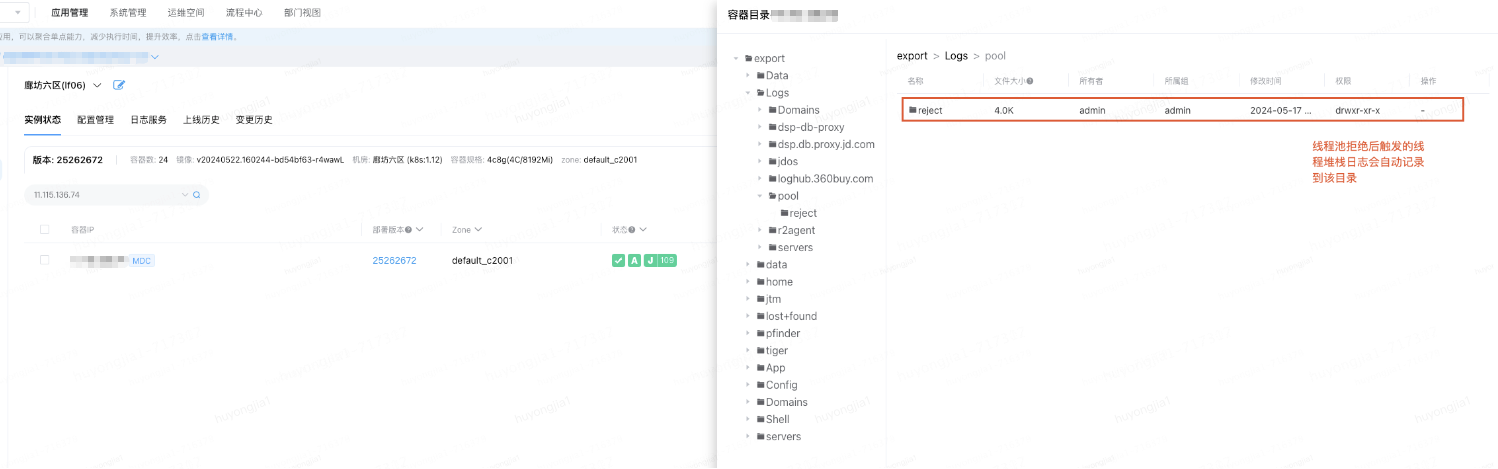
下圖為問題發(fā)生時自動打印的堆棧日志
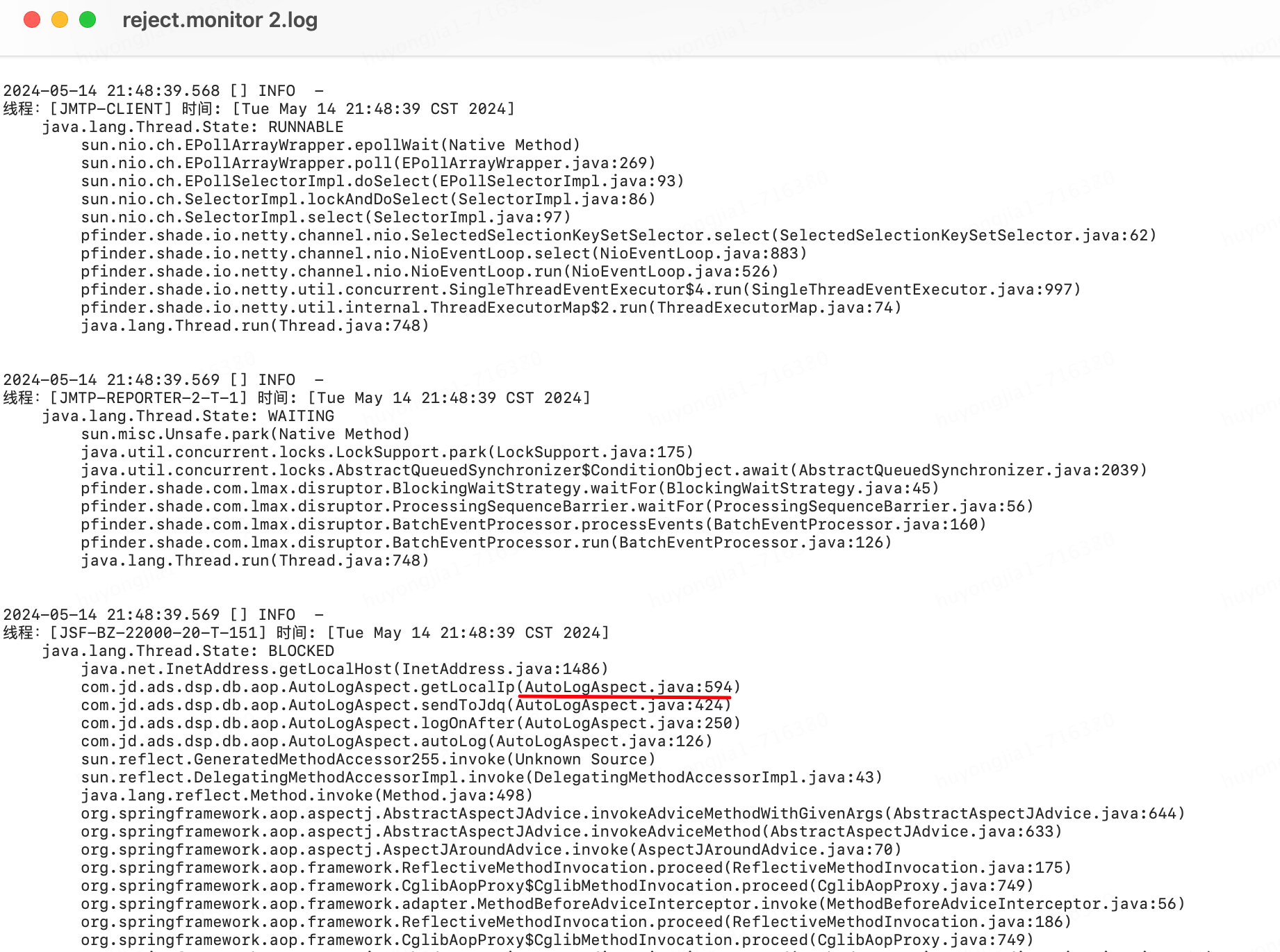




借助分析工具發(fā)現(xiàn)512個線程,511個都卡在了同一位置
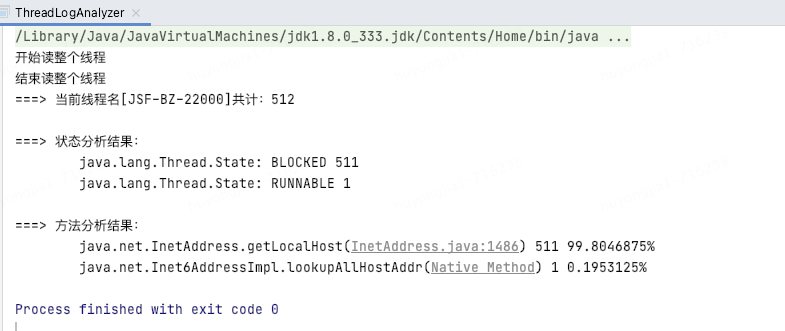
從堆棧和分析結果可以比較容易的定位到時哪里出現(xiàn)了問題,最終發(fā)現(xiàn)我們在每次記錄關鍵日志時通過InetAddress.getLocalHost()方法獲取了本機ip,由于獲取的方法在特定情況下可能出現(xiàn)加鎖的情況,所以可能會先間歇性的線程阻塞;(網上相似案例:https://qa.1r1g.com/sf/ask/4489560281/)
實踐案例2:
業(yè)務中某線程池偶爾會出現(xiàn)線程池拒絕異常,同樣時間僅持續(xù)秒級,報警信息如下

通過自動觸發(fā)的線程堆棧進行分析,發(fā)現(xiàn)該線程池中大量線程在拒絕時積壓在某接口的jsf調用等待上
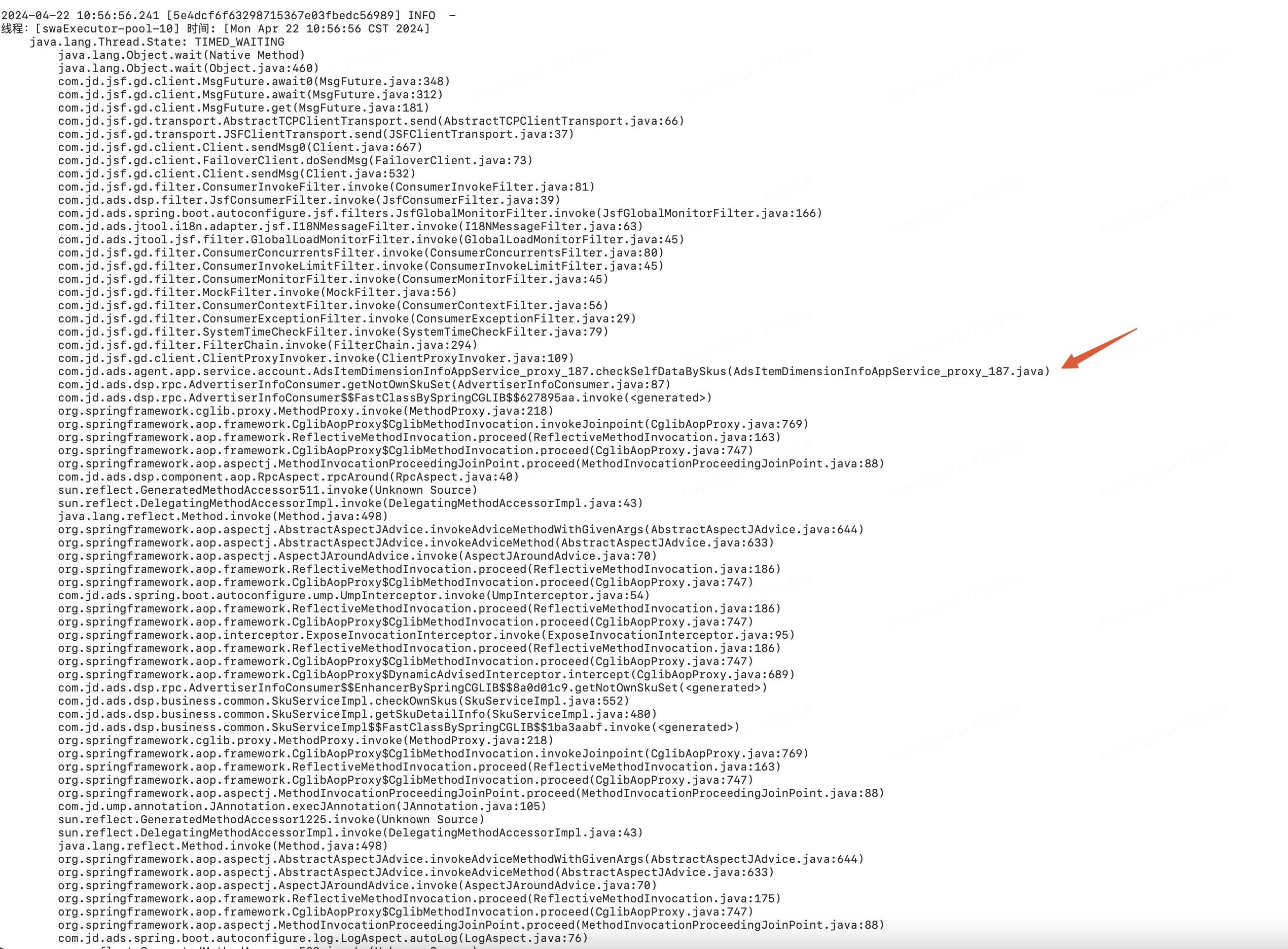
由此再結合方法監(jiān)控及日志可以比較容易定位到該時刻接口性能波動導致
參數動態(tài)刷新
達成目的:迅速修改線程池參數,降低問題風險
如果需要對某線程池的參數做變更,只需將修改后的參數設置到ducc并重新發(fā)布即可
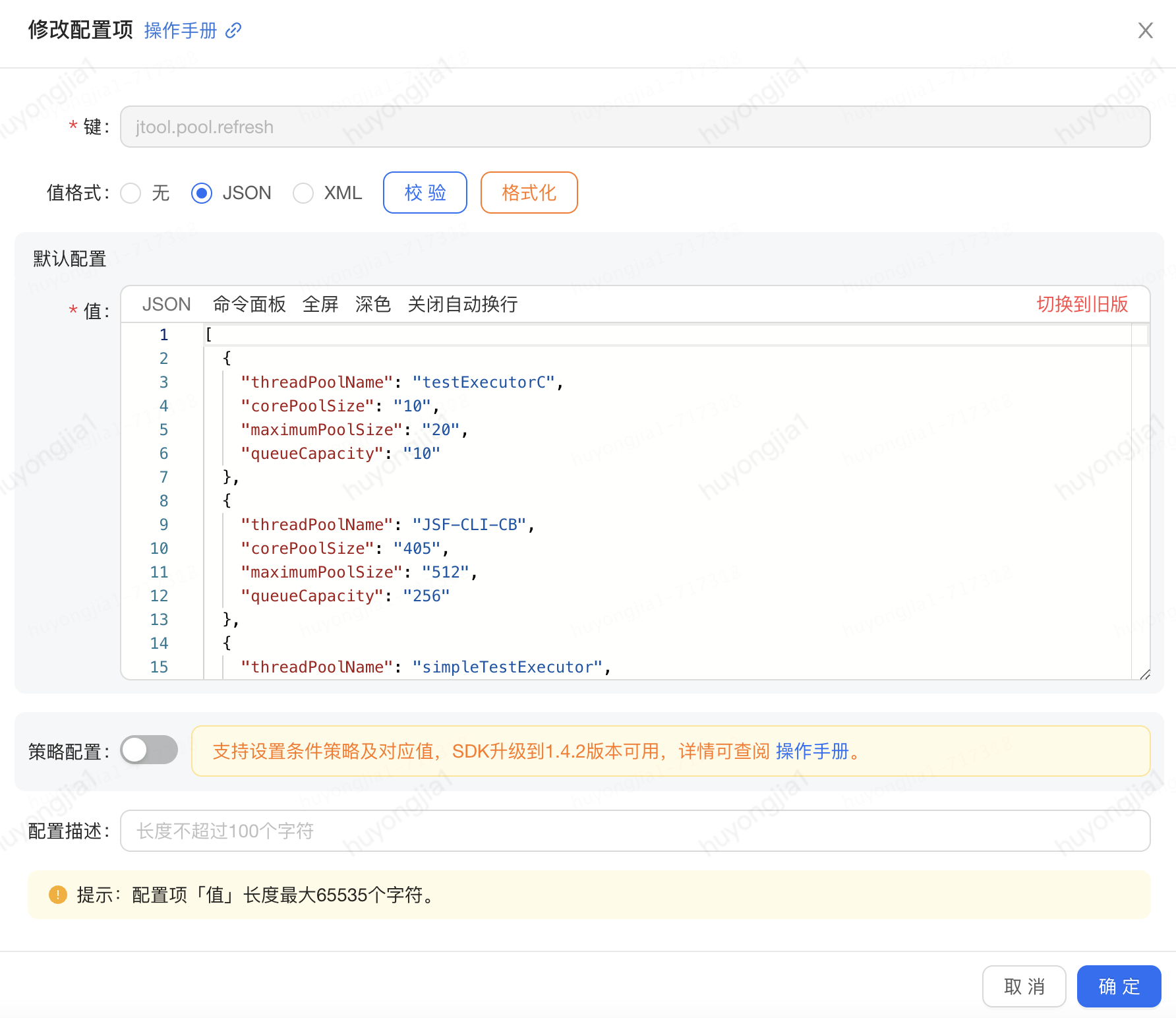
實踐案例:
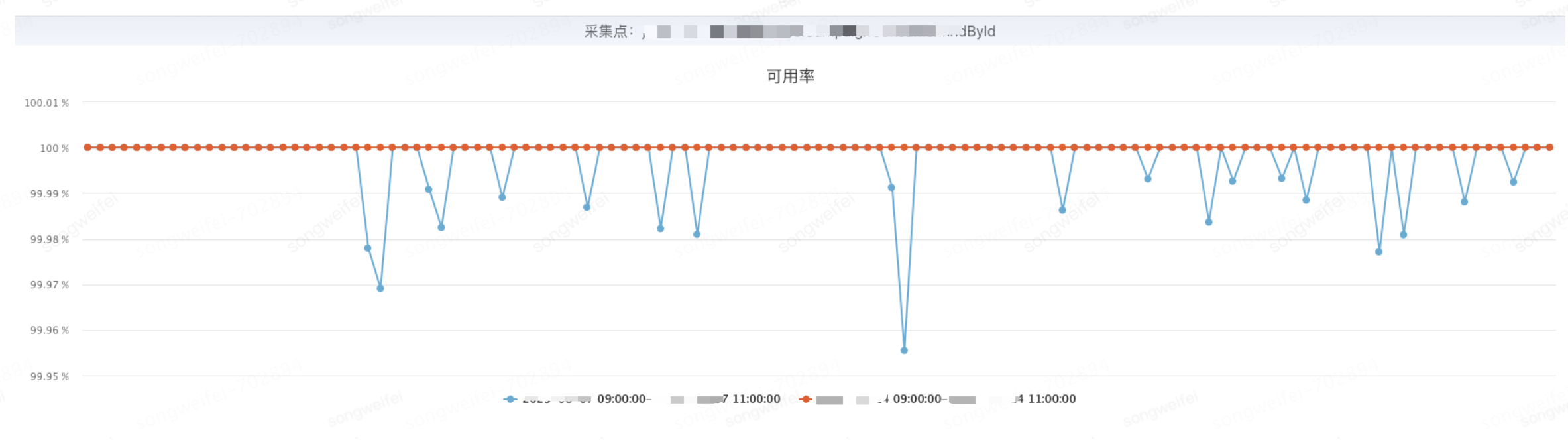
業(yè)務中部分場景從同步JSF調用改為異步后,可用率出現(xiàn)下降,通過分析發(fā)現(xiàn)是JSF的JSF-CLI-CB線程池設置較小,出現(xiàn)等待超時導致;借助動態(tài)線程池的動態(tài)配置能力修改對應ducc發(fā)布后問題得到改善
調整前后對比
審核編輯 黃宇
-
監(jiān)控
+關注
關注
6文章
2208瀏覽量
55197 -
線程池
+關注
關注
0文章
57瀏覽量
6846
發(fā)布評論請先 登錄
相關推薦
C語言線程池的實現(xiàn)方案
Java中的線程池包括哪些
買藥秒送 JADE動態(tài)線程池實踐及原理淺析
基于Nacos的簡單動態(tài)化線程池實現(xiàn)
多線程之線程池

線程池的線程怎么釋放
Spring 的線程池應用





 工商網監(jiān)
工商網監(jiān)
評論