") 大模型技術(shù)及趨勢總結(jié)
大模型技術(shù)及趨勢總結(jié)
本篇文章旨在希望大家對大模型的本質(zhì)、技術(shù)和發(fā)展趨勢有簡單的了解。由于近期大模型技術(shù)發(fā)展很快,這里對大模型的技術(shù)、本質(zhì)及未來趨勢進行總結(jié)和探討時,因為水平有限,疏漏在所難免。請大家諒解。
引言
大模型將成為通用人工智能的重要途徑。在這個由0和1編織的數(shù)字時代,人工智能的騰飛已不是科技夢想,而是日益切實的現(xiàn)實。其中,大模型作為人工智能的核心力量,正以前所未有的方式重塑著我們的生活、學習和工作。無論是智能語音助手、自動駕駛汽車,還是醫(yī)療診斷系統(tǒng),大模型都是幕后英雄,讓這些看似不可思議的事情變?yōu)榭赡堋?/p>
人工智能的發(fā)展歷史
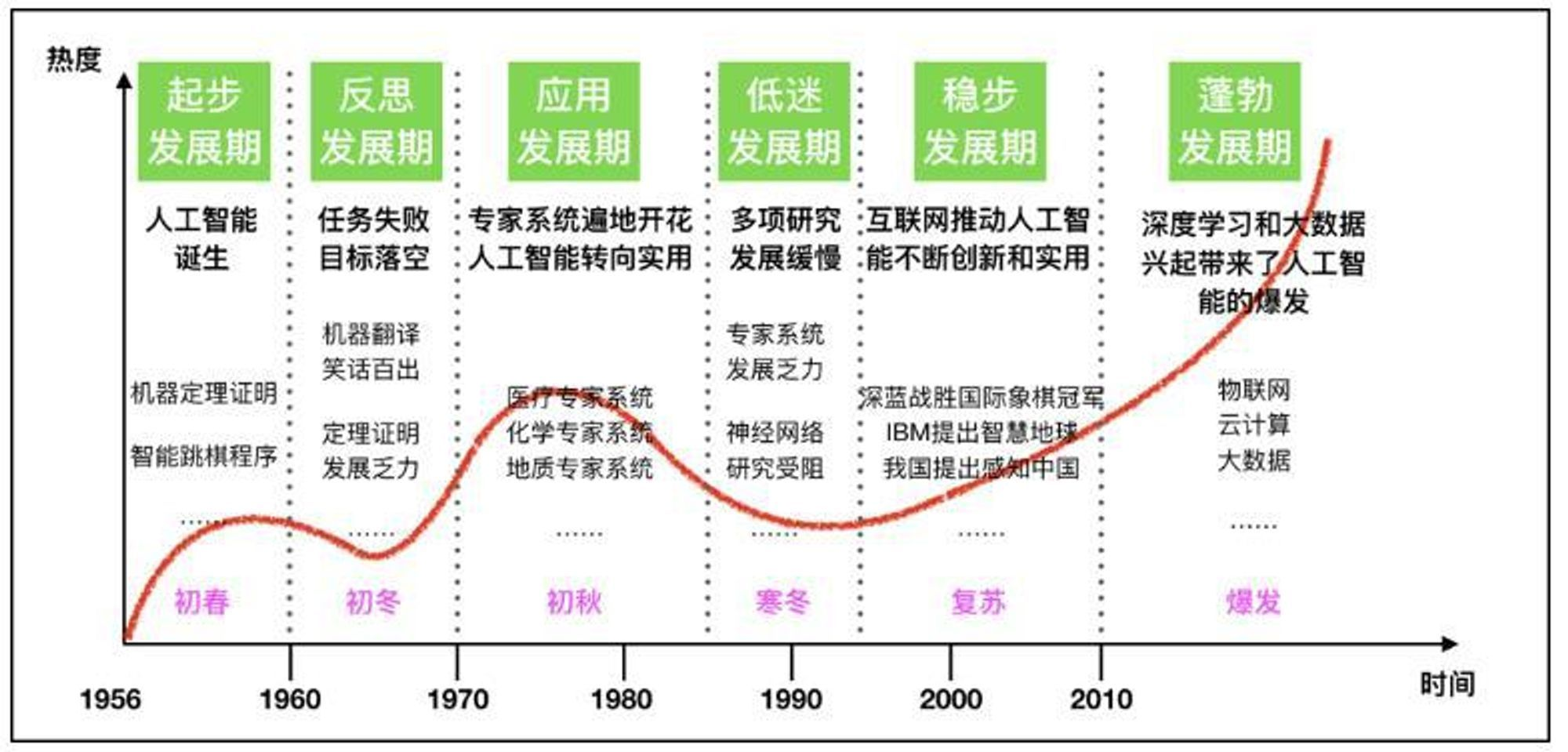
1.1950s-1970s:AI的誕生和早期發(fā)展
?1950年,圖靈測試的提出,為機器智能提供了一個評估標準。
?1956年,達特茅斯會議標志著人工智能作為一門學科的正式誕生。
?1960年代,早期的AI研究集中在邏輯推理和問題解決上。
2.1980s:專家系統(tǒng)的興起
?專家系統(tǒng)的成功應用,如MYCIN在醫(yī)學診斷領(lǐng)域的應用。
?機器學習算法開始發(fā)展,如決策樹和早期的神經(jīng)網(wǎng)絡(luò)。
3.1990s:機器學習的進展
?反向傳播算法的提出,極大地推動了神經(jīng)網(wǎng)絡(luò)的研究。
?1997年,IBM的深藍擊敗國際象棋世界冠軍,展示了AI在策略游戲中的能力。
4.2000s:大數(shù)據(jù)和計算能力的提升
?互聯(lián)網(wǎng)的普及帶來了海量數(shù)據(jù),為機器學習提供了豐富的訓練素材。
?計算能力的提升,尤其是GPU的廣泛應用,加速了深度學習的發(fā)展。
5.2010s:深度學習革命
?2012年,AlexNet在ImageNet競賽中的勝利,標志著深度學習在圖像識別領(lǐng)域的突破。
?深度學習在語音識別、自然語言處理等領(lǐng)域取得顯著進展。
6.2017年:Transformer和自注意力機制
?2017年,Transformer模型的提出,引入了自注意力機制,極大地提升了模型的性能。
?Transformer模型在自然語言處理任務中取得了革命性的成果,如BERT、GPT等模型。
7.2020s:大模型和多模態(tài)學習
?大模型如chatGPT、Claude、Gemini、Llama、chatglm、Kimi等等都展示了強大的能力。
?多模態(tài)學習的發(fā)展,如CLIP模型,能夠理解和生成跨模態(tài)內(nèi)容。
大模型的本質(zhì)
大模型是能夠從海量數(shù)據(jù)中學習、利用這些數(shù)據(jù)進行推理,并使用這些推理來回答用戶的問題或是執(zhí)行特定的任務。大模型(如ChatGPT、LLM等)在人工智能領(lǐng)域中被廣泛應用,其核心理念和工作原理可以總結(jié)為以下幾個方面:
1. LLM的組成 - 兩個文件
大模型由以下兩個關(guān)鍵部分構(gòu)成:一個是 參數(shù)集,另一個是 執(zhí)行代碼。
?參數(shù)集:這是模型的"大腦",包含了通過訓練學習到的神經(jīng)網(wǎng)絡(luò)權(quán)重。
?執(zhí)行代碼:這是模型的"引擎",包含用于運行參數(shù)集的軟件代碼,可以采用任何編程語言實現(xiàn)。
訓練大模型需要對大量互聯(lián)網(wǎng)數(shù)據(jù)進行有損壓縮,是一項計算量更大的任務,通常需要一個巨大的GPU集群。
有趣的是,你只需要一臺標準的計算機就可以運行像Llama-3這樣的LLM并得出推論。在本地服務器上運行,因此,甚至不需要互聯(lián)網(wǎng)連接。
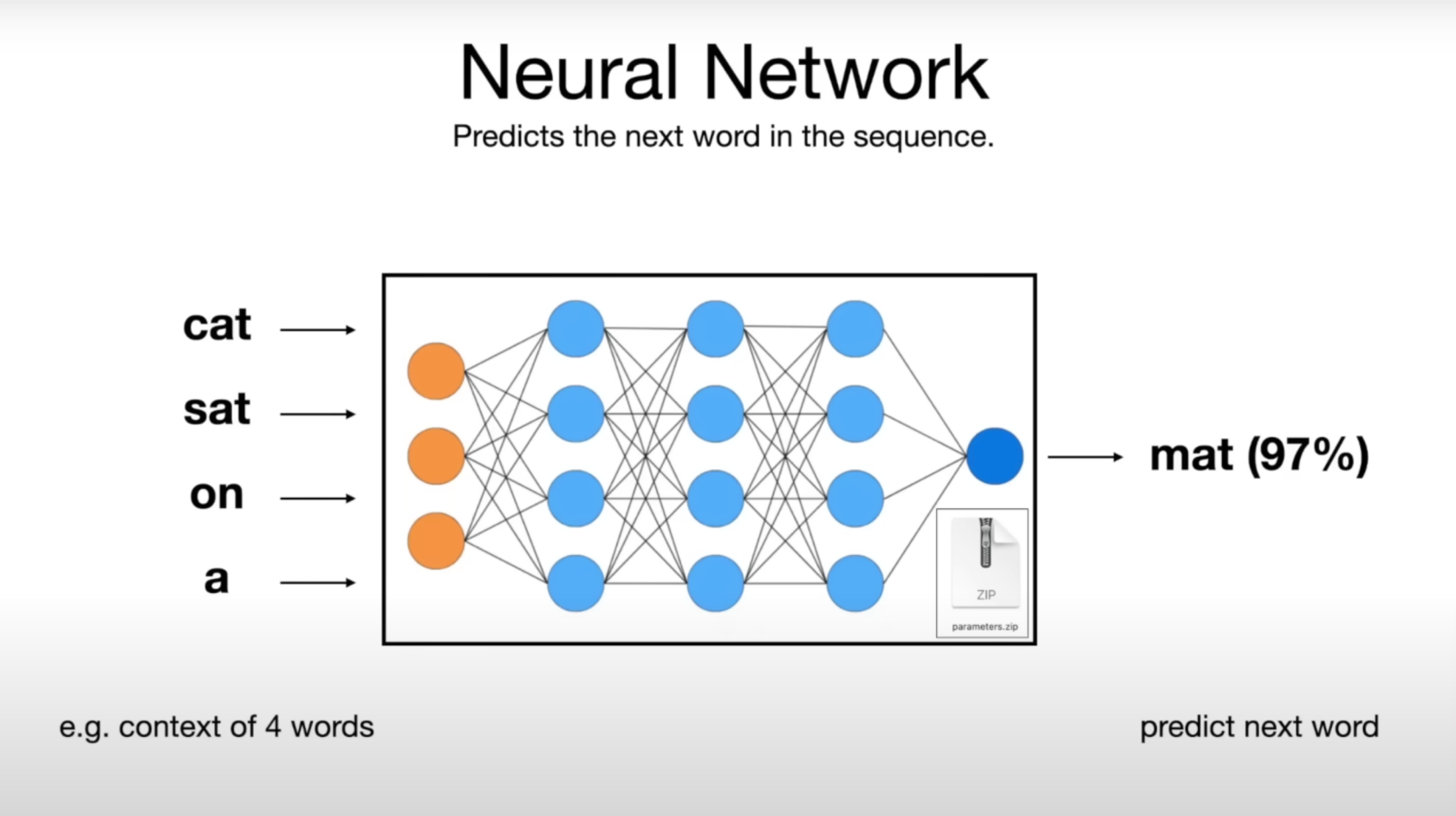
2. LLM的神經(jīng)網(wǎng)絡(luò)究竟在“想”什么 - 預測下一個單詞
大模型的核心功能之一是預測文本序列中的下一個單詞:
?輸入一個“部分”句子,如“cat sat on a”。
?利用分布在網(wǎng)絡(luò)中的參數(shù)及其連接關(guān)系預測下一個最可能的單詞,并給出概率。如“mat(97%)”
?模擬了人類語言生成的方式,使得模型能夠生成連貫和符合語境的句子,如生成完整的句子“cat sat on a mat”
模型根據(jù)它所獲得的大量訓練數(shù)據(jù),生成“合理的延續(xù)”,即生成符合人類語言習慣的文本。
注:Transformer架構(gòu)為這個神經(jīng)網(wǎng)絡(luò)提供了動力。
3. 神經(jīng)網(wǎng)絡(luò)“真正”的工作方式仍然是個謎
盡管我們可以將數(shù)十億個參數(shù)輸入到網(wǎng)絡(luò)中,并通過反復微調(diào)訓練這些參數(shù),從而獲得更好的預測效果,但我們并不完全理解這些參數(shù)在網(wǎng)絡(luò)中是如何準確協(xié)作的,以及為什么它們能夠生成如此準確的回答。科學上,這種現(xiàn)象被稱為涌現(xiàn)。
我們知道,這些參數(shù)構(gòu)建并維護了某種形式的知識數(shù)據(jù)庫。然而,這種數(shù)據(jù)庫有時表現(xiàn)得既奇怪又不完美。例如,一個大型語言模型(LLM)可能會正確回答“誰是小明的母親?”這個問題,但如果你問它“X的兒子是誰?”,它可能會回答“我不知道”。這種現(xiàn)象通常被稱為遞歸詛咒。
4. 訓練大模型的步驟
預訓練,訓練需要對大量互聯(lián)網(wǎng)數(shù)據(jù)進行有損壓縮,輸出參數(shù)文件
?收集大量互聯(lián)網(wǎng)文本數(shù)據(jù)。
?準備強大的計算資源,如GPU集群。
?執(zhí)行訓練,生成基本模型。
微調(diào)階段:
?準備高質(zhì)量的訓練數(shù)據(jù),如問答對。
?在這些數(shù)據(jù)上調(diào)整模型參數(shù),優(yōu)化性能。
?進行評估和部署,確保模型達到預期效果。

微調(diào)階段 - 比較
對于每個問題,人工標注者都會比較輔助模型的多個答案,并標注出最佳答案。這一步驟稱為從人類反饋中強化學習(RLHF)。
5. 模型性能提升
1.模型越大,能力越強:
?參數(shù)量:模型的規(guī)模通常與其參數(shù)量成正比。參數(shù)是模型學習到的知識的載體,參數(shù)越多,模型能夠捕捉的信息和模式就越豐富,從而能夠處理更復雜的任務。
?學習能力:大模型通常擁有更強的學習能力。它們能夠從大量數(shù)據(jù)中學習到更深層次的特征和規(guī)律,這使得它們在諸如自然語言處理、圖像識別等任務上表現(xiàn)更佳。
?泛化能力:大模型往往有更好的泛化能力,即在面對未見過的數(shù)據(jù)時,也能做出準確的預測和判斷。
2.工具越多,能力越強:
?功能擴展:為AI模型提供各種工具,可以使其功能得到顯著擴展。例如,集成搜索引擎可以讓模型訪問互聯(lián)網(wǎng)信息,增強其回答問題的能力。
?多任務處理:工具的集成使得AI模型能夠同時處理多種任務。例如,集成計算器功能可以讓模型執(zhí)行數(shù)學計算,集成編程接口則可以讓模型編寫代碼。
?靈活性和適應性:擁有多種工具的AI模型更加靈活和適應性強,能夠根據(jù)任務需求快速調(diào)整其行為和策略。類似于人類通過使用工具解決各種任務。
面臨的問題
幻覺
幻覺問題指的是大模型在生成文本時可能會產(chǎn)生與現(xiàn)實世界事實不一致的內(nèi)容。這種現(xiàn)象可以分為幾種類型:
1.事實性幻覺(Factuality Hallucination):模型生成的內(nèi)容與可驗證的現(xiàn)實世界事實不一致。大模型可能生成聽起來合理但實際上錯誤的信息,例如,生成一篇關(guān)于一個不存在的歷史事件的文章,模型可能生成一篇關(guān)于“拿破侖在月球上宣布法國勝利”的文章,盡管這在現(xiàn)實中從未發(fā)生過。
2.忠實性幻覺(Faithfulness Hallucination):模型生成的內(nèi)容與用戶的指令或上下文不一致。例如在一個關(guān)于健康飲食的討論中,模型可能突然開始討論健身運動,盡管這與用戶的問題不直接相關(guān)。
產(chǎn)生幻覺的原因可能包括:
?使用的數(shù)據(jù)集存在錯誤信息或偏見。
?模型過度依賴訓練數(shù)據(jù)中的模式,可能導致錯誤的關(guān)聯(lián)。
?預訓練階段的架構(gòu)缺陷,如基于前一個token預測下一個token的方式可能阻礙模型捕獲復雜的上下文關(guān)系。
?對齊階段的能力錯位,即模型的內(nèi)在能力與標注數(shù)據(jù)中描述的功能之間可能存在錯位。
為了緩解幻覺問題,研究者們提出了多種方法,如改進預訓練策略、數(shù)據(jù)清理以消除偏見、知識編輯、檢索增強生成(RAG)等。
安全性問題
安全性問題涉及大模型可能遭受的惡意攻擊和濫用,以及它們對用戶隱私和數(shù)據(jù)安全的潛在威脅:
1.對抗樣本攻擊:攻擊者可能構(gòu)造特殊的輸入樣本,導致模型做出錯誤的預測。
2.后門攻擊:在模型中植入后門,使得在特定觸發(fā)條件下模型表現(xiàn)出異常行為。
3.成員推斷攻擊:攻擊者嘗試推斷出訓練集中是否包含特定的數(shù)據(jù)點。
4.模型竊取:通過查詢模型來復制其功能,侵犯模型版權(quán)。
5.數(shù)據(jù)隱私泄露:模型可能泄露訓練數(shù)據(jù)中的敏感信息。
為了提高大模型的安全性,業(yè)界和研究界正在探索多種安全防護策略,包括:
?加強數(shù)據(jù)的采集和清洗過程,確保數(shù)據(jù)質(zhì)量和安全性。
?對模型進行加固,提高其抗攻擊能力。
?采用加密存儲和差分隱私技術(shù)來保護數(shù)據(jù)隱私。
?增強模型的可解釋性,以便更好地理解和控制模型行為。
相關(guān)技術(shù)
Prompt Engineering (提示詞工程)
是什么
提示詞(prompt)是人與大模型交互的重要媒介。因此,對提示詞的掌握、使用、研究,便具有非常重大的意義。從人機交互出發(fā),將大模型視為一種特殊的、很強大的計算設(shè)備,那么,提示詞之于我們:“prompt是一種新型的自然用戶界面”。
大多數(shù)的prompt具有以下的形式:由「指令」(instruction)和「內(nèi)容」(content)兩部分構(gòu)成。其中,指令部分為我們需要大模型做的事,如“判斷下列句子的情感”,而內(nèi)容則為真正的句子,如“我今天很高興”。注意,并不是所有的prompt都必須是這樣的形式,如比較簡短的prompt:“中國的首都在哪里”、“模仿百年孤獨的開頭寫一段話”等這種言簡意賅的prompt就只有指令、內(nèi)容為空。

?
Prompt的不同分類
Prompt千變?nèi)f化、不可名狀,其主要由以下幾種常見形式構(gòu)成:
?Zero-shot prompt:零樣本的prompt。此為最常見的使用形式。之所以叫zero-shot,是因為我們直接用大模型做任務而不給其參考示例。這也被視為評測大模型能力的重要場景之一。
?Few-shot prompt:與zero-shot相對,在與大模型交互時,在prompt中給出少量示例。
?Role prompt:與大模型玩“角色扮演”游戲。讓大模想象自己是某方面專家、因而獲得更好的任務效果。
?Instruction prompt:指令形式的prompt。
?Chain-of-thought prompt:常見于推理任務中,通過讓大模型“Let's think step by step”來逐步解決較難的推理問題。
?Multimodal prompt:多模態(tài)prompt。顧名思義,輸入不再是單一模態(tài)的prompt,而是包含了眾多模態(tài)的信息。如同時輸入文本和圖像與多模態(tài)大模型進行交互,現(xiàn)在的4o就能做到。
Prompt技巧(后續(xù)章節(jié)詳解)
Prompt或許并不是人類與大模型進行交互的唯一和最好的方式,但一定是當下使用最多的方式。
RAG(Retrieval-Augmented Generation)
什么是RAG
RAG(Retrieval-Augmented Generation)技術(shù)是一種結(jié)合檢索和生成的方法,用于提升大語言模型(LLM)在知識密集型任務中的性能。通過一個兩階段的過程提升LLMs的輸出質(zhì)量:
?檢索(Retrieval)階段,可以從各種數(shù)據(jù)源檢索相關(guān)信息;
?生成(Generation)階段,將檢索到的文檔與原始查詢,形成提示模板,一起輸入到生成模型中,產(chǎn)生最終的回答。
這種方法使模型擁有了利用實時和外部的知識庫(非訓練時使用的數(shù)據(jù))的能力,提高了其在特定問題處理上的靈活性和準確性。
?
RAG解決什么問題
大型語言模型(LLM)雖然在多個領(lǐng)域展現(xiàn)出了卓越的性能,但在實際業(yè)務場景中仍面臨一些挑戰(zhàn):
?知識的局限性:LLM的知識僅限于其訓練數(shù)據(jù),對于實時性、非公開或離線數(shù)據(jù)的獲取存在困難。
?幻覺問題:基于概率的輸出可能導致模型生成不準確的信息。
?數(shù)據(jù)安全性:企業(yè)對于數(shù)據(jù)泄露風險的擔憂限制了對第三方平臺的依賴。
為了解決這些問題,RAG作為一套有效的解決方案應運而生。
RAG工作原理
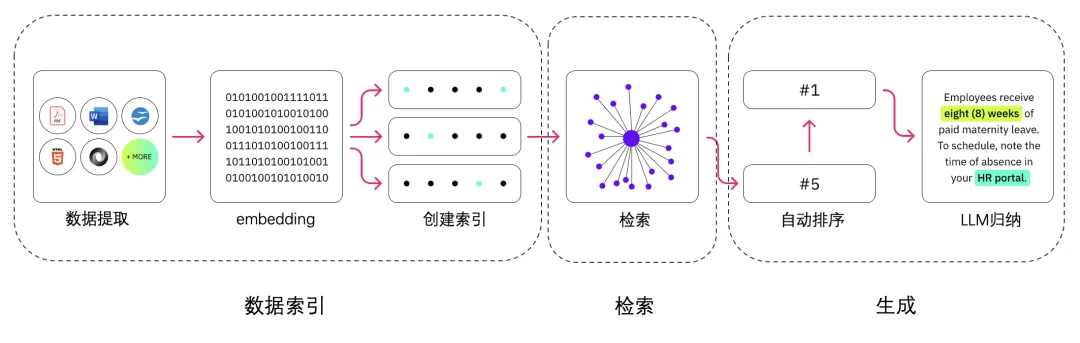
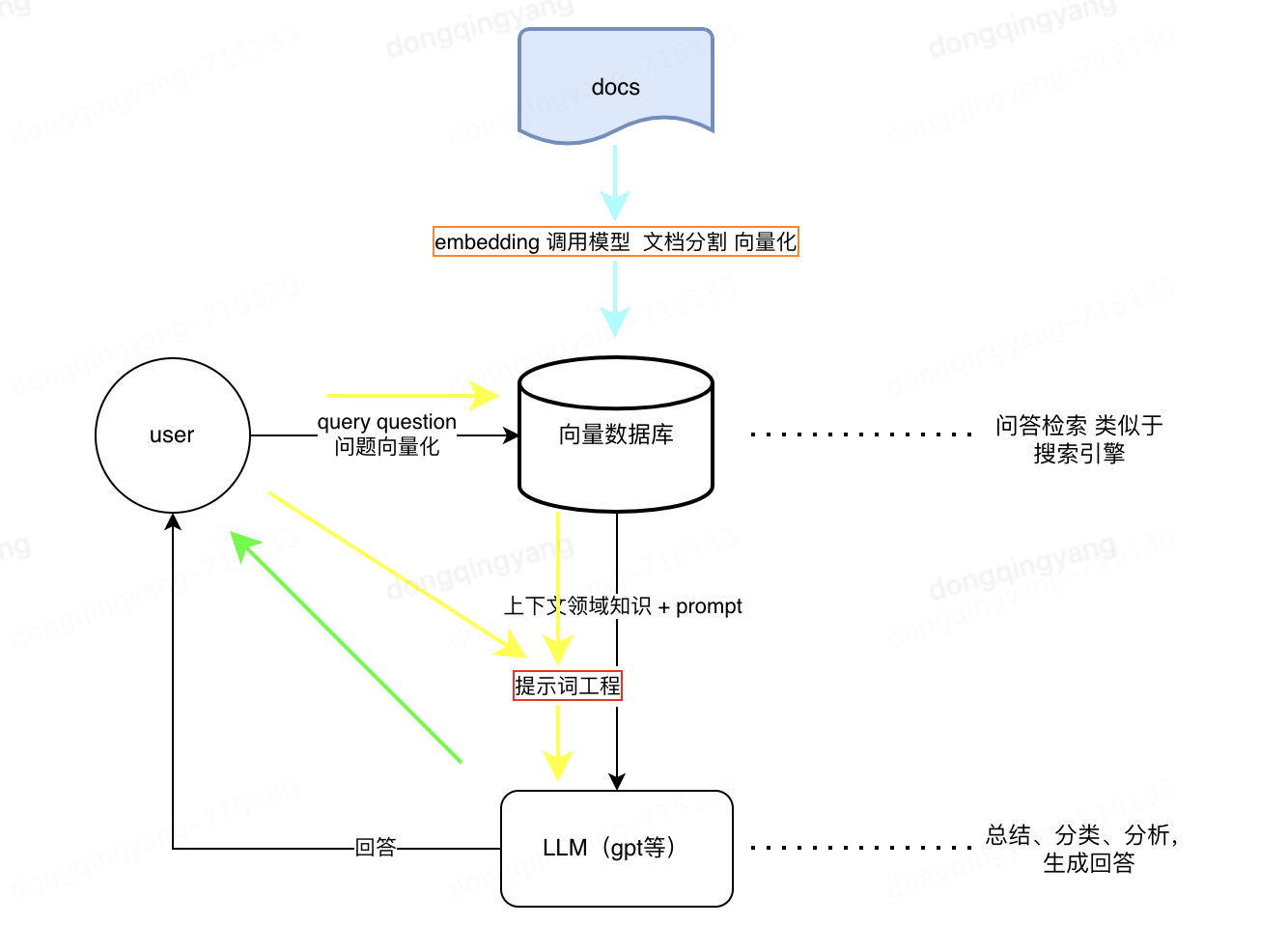
分為三個部分:索引、檢索、生成。
1.索引 Indexing:處理外部知識源,將知識源分割為chunk,編碼為向量,存儲在向量數(shù)據(jù)庫 Vetor-DataBase 中。
2.檢索 Retrieval: 接受用戶問題,將問題編碼為向量,用這些向量去向量數(shù)據(jù)庫中找到最相關(guān)的文檔庫 top-k chunks。
3.生成 Generation: 將檢索到的文檔與原始問題一起作為提示 (Promot)輸入到LLM中,生成回答。
?
RAG的優(yōu)勢
?知識豐富:RAG能夠訪問和利用大量的外部知識,提供更全面的回答。
?上下文相關(guān)性:通過檢索到的信息,RAG能夠生成與用戶查詢高度相關(guān)的響應。
?靈活性:適用于問答系統(tǒng)、內(nèi)容創(chuàng)作等多種應用場景。
?減少幻覺:結(jié)合實際數(shù)據(jù),降低生成錯誤信息的風險。
RAG 的應用場景
?問答系統(tǒng):RAG可以用于問答系統(tǒng),其中檢索模型可以根據(jù)用戶的問題從大規(guī)模的文本數(shù)據(jù)庫或者互聯(lián)網(wǎng)中檢索相關(guān)答案,生成模型則可以將檢索到的信息轉(zhuǎn)化為自然語言的回答。
?文本摘要:RAG可以用于文本摘要任務,其中檢索模型可以檢索與原文相關(guān)的摘要信息,生成模型則可以基于檢索到的信息生成更準確和完整的摘要。
?對話系統(tǒng):RAG可以應用于對話系統(tǒng),其中檢索模型可以檢索與對話歷史相關(guān)的信息,生成模型則可以基于檢索到的信息生成更連貫和準確的回復。
?事實核查:RAG 可以幫助識別和生成基于證據(jù)的解釋,以驗證陳述的真實性。
?內(nèi)容推薦:在推薦系統(tǒng)中,RAG 可以根據(jù)用戶的歷史行為和偏好,檢索并生成個性化的內(nèi)容推薦。
RAG 是一種強大的技術(shù),但它也有一些局限性,比如對檢索系統(tǒng)性能的依賴,以及可能生成的答案質(zhì)量受限于檢索到的文檔片段的質(zhì)量。隨著技術(shù)的進步,RAG 及其變體在處理復雜的認知任務方面展現(xiàn)出了巨大的潛力。
Agent智能體
為什么出現(xiàn)LLM Agent
近年來,人工智能(AI)和自然語言處理(NLP)技術(shù)迅猛發(fā)展,特別是大型語言模型(LLM)的出現(xiàn),如 OpenAI 的 GPT 系列。這些模型展示了在各種任務中的卓越表現(xiàn),從文本生成到對話系統(tǒng)。然而,盡管 LLM 擁有強大的處理和理解能力,它們的應用仍然需要進一步的優(yōu)化和具體化。LLM Agent 的出現(xiàn)正是為了解決這些需求,實現(xiàn)更靈活、更智能的自動化任務處理。
1.復雜任務需求:傳統(tǒng)的 AI 系統(tǒng)在處理復雜任務時往往需要大量的領(lǐng)域知識和手工調(diào)試。LLM Agent 通過預訓練模型和少量的微調(diào),可以更好地適應各種復雜任務。
2.人機交互提升:隨著用戶對于智能助手和對話系統(tǒng)的需求不斷增加,LLM Agent 可以提供更自然、更流暢的交互體驗。
3.自動化和效率:在企業(yè)和個人生活中,自動化任務需求逐漸增加。LLM Agent 能夠通過自然語言指令執(zhí)行多種任務,提升效率。
LLM Agent是什么
簡單來說,LLM Agent是基于大型語言模型(如GPT-4)開發(fā)的智能代理。它不僅能理解和生成自然語言,還能執(zhí)行一系列復雜的任務,如回答問題、生成文本、進行對話等。想象一下,你的計算機能夠像人類一樣理解你的問題并提供有用的答案。
LLM充當 Agent 大腦的角色,并由幾個關(guān)鍵組件組成:規(guī)劃(Planning)、記憶(Memory)、工具(Tool Use)
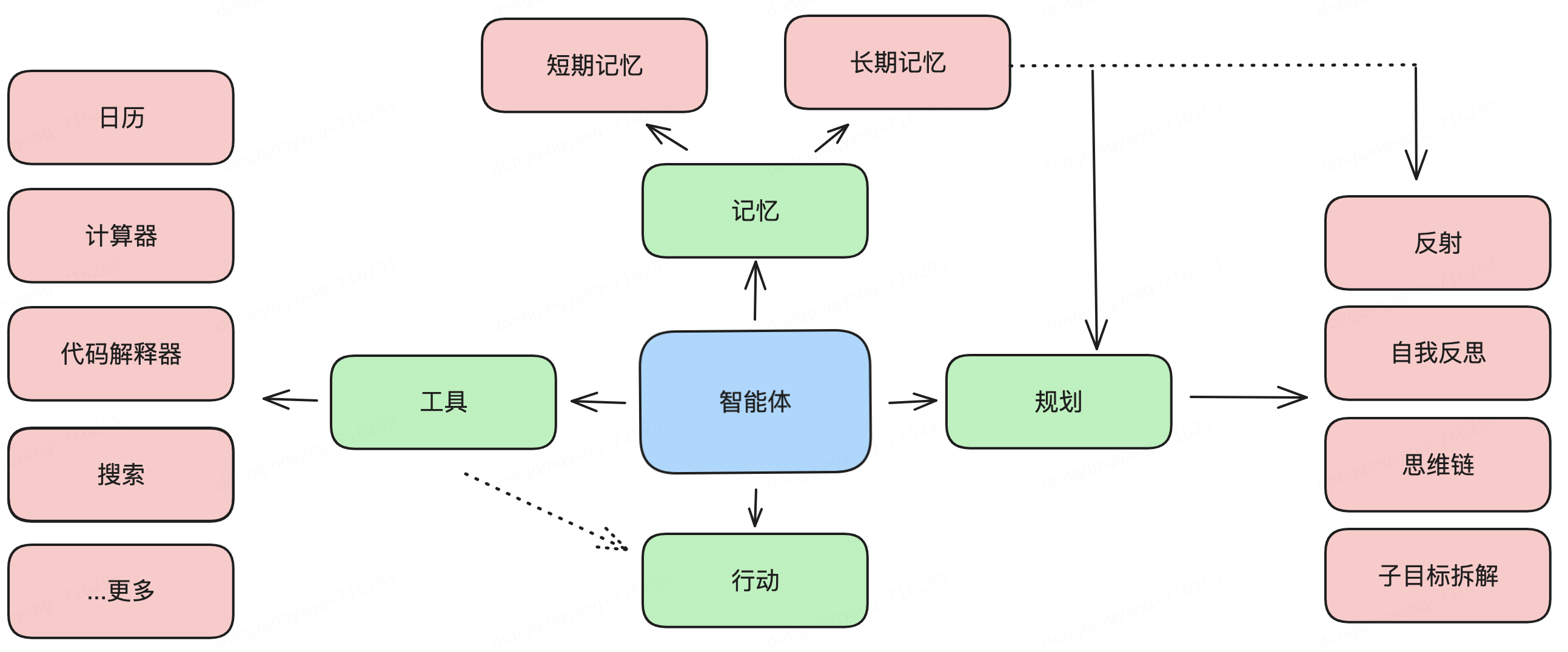
?規(guī)劃
?子目標拆解:復雜任務不是一次性就能解決的,需要拆分成多個并行或串行的子任務來進行求解,任務規(guī)劃的目標是找到一條最優(yōu)的、能夠解決問題的路線。
?反思和完善:智能體可以對過去的行為進行自我批評和自我反思,從錯誤中吸取教訓,并針對未來的步驟進行完善,從而提高最終結(jié)果的質(zhì)量。
?記憶
?短期記憶:所有的上下文學習(提示詞工程)都是利用模型的短期記憶來學習。
?長期記憶:為 Agent 提供了長時間保留和回憶(無限)信息的能力,通常是通過利用外部向量存儲和快速檢索。
?工具
?調(diào)用外部 API 來獲取模型權(quán)重中缺失的額外信息(通常在預訓練后很難更改),包括當前信息、代碼執(zhí)行能力、對專有信息源的訪問等。
LLM Agent 的優(yōu)勢
1.高效性:LLM Agent 可以快速理解和處理自然語言指令,減少了任務處理的時間和復雜度。
2.靈活性:通過少量的微調(diào),LLM Agent 可以適應不同的應用場景,從而具有很高的靈活性。
3.用戶體驗提升:得益于強大的自然語言處理能力,LLM Agent 能夠提供更加自然和智能的交互體驗,提升用戶滿意度。
4.可擴展性:LLM Agent 可以不斷學習和擴展新的功能和知識,使得它在長期使用中表現(xiàn)越來越好。
LLM Agent 的應用
?自動化客服:LLM Agent可以提供24/7的客戶服務,自動回答用戶的查詢,提高服務效率和用戶滿意度。
?內(nèi)容創(chuàng)作:從博客文章到營銷文案,LLM Agent可以幫助內(nèi)容創(chuàng)作者生成初稿或提供寫作靈感。
?數(shù)據(jù)分析與摘要:LLM Agent可以從大量文本數(shù)據(jù)中提取關(guān)鍵信息,生成報告摘要,幫助決策者快速獲取信息。
?教育和培訓:在教育領(lǐng)域,LLM Agent可以提供個性化的學習材料,輔助語言學習,或者作為智能輔導員。
?研究助手:對于研究人員,LLM Agent可以幫助文獻搜索、信息整理,甚至參與創(chuàng)造性的研究過程。
多模態(tài)
多模態(tài)定義
什么是多模態(tài)呢?簡單來說,多模態(tài)就像是一個多才多藝的藝術(shù)家,能夠同時使用多種藝術(shù)形式來創(chuàng)作作品。在AI領(lǐng)域,多模態(tài)模型能夠同時處理和理解多種類型的數(shù)據(jù),比如文字、圖像、聲音和視頻。
為什么需要多模態(tài)
為什么我們需要能夠處理多種數(shù)據(jù)類型的AI模型呢?原因很簡單:我們的世界是多模態(tài)的。我們交流和感知世界不僅僅通過語言,還包括視覺、聽覺等多種方式。多模態(tài)模型能夠更全面地理解和模擬人類的交流和感知方式,使得AI能夠更自然地與人類互動。
多模態(tài)的作用和特點
多模態(tài)模型就像是我們的大腦,能夠同時處理和理解來自眼睛(視覺信息)、耳朵(聽覺信息)和其他感官的數(shù)據(jù)。作用主要體現(xiàn)在以下幾個方面:
1.信息整合:能夠?qū)⒉煌愋偷男畔⒄显谝黄穑岣呃斫夂头治龅臏蚀_性。
2.增強表現(xiàn)力:通過結(jié)合多種數(shù)據(jù)源,模型可以表現(xiàn)出更強的感知和認知能力。
3.提高魯棒性:多模態(tài)模型可以在某種類型數(shù)據(jù)缺失或不完整的情況下,依靠其他數(shù)據(jù)類型來彌補,從而提高整體性能。
與單一模態(tài)的模型相比,多模態(tài)模型具有以下特點:
1.多源數(shù)據(jù)處理:能夠同時處理圖像、文字、聲音等多種數(shù)據(jù)類型。
2.更強的泛化能力:在不同的應用場景下表現(xiàn)更好,因為它們能夠整合更多的信息。
多模態(tài)模型的應用案例
多模態(tài)模型在很多領(lǐng)域有著廣泛的應用。以下是幾個典型的例子:
1.醫(yī)療診斷:通過結(jié)合病人的影像數(shù)據(jù)(如X光片)、文字數(shù)據(jù)(病歷)和生理數(shù)據(jù)(心電圖),多模態(tài)模型可以提供更準確的診斷結(jié)果。
2.自動駕駛:多模態(tài)模型可以結(jié)合攝像頭圖像、雷達數(shù)據(jù)和GPS信息,幫助自動駕駛汽車更好地理解周圍環(huán)境,提高安全性。
3.智能客服:通過整合語音識別、自然語言處理和情感分析,多模態(tài)模型可以提供更自然、更人性化的客服服務。
多模態(tài)大模型是人工智能領(lǐng)域的重要進展,它們通過整合多種類型的數(shù)據(jù),顯著提升了模型的表現(xiàn)力和魯棒性。這不僅使得人工智能系統(tǒng)能夠更好地理解復雜的現(xiàn)實世界,也為未來的技術(shù)發(fā)展帶來了無限可能。無論是在醫(yī)療、交通還是日常生活中,多模態(tài)大模型正逐步改變我們的生活方式。
應用實例(簡單列舉)
斯坦福小鎮(zhèn)
文生圖 圖生圖 圖生視頻
?
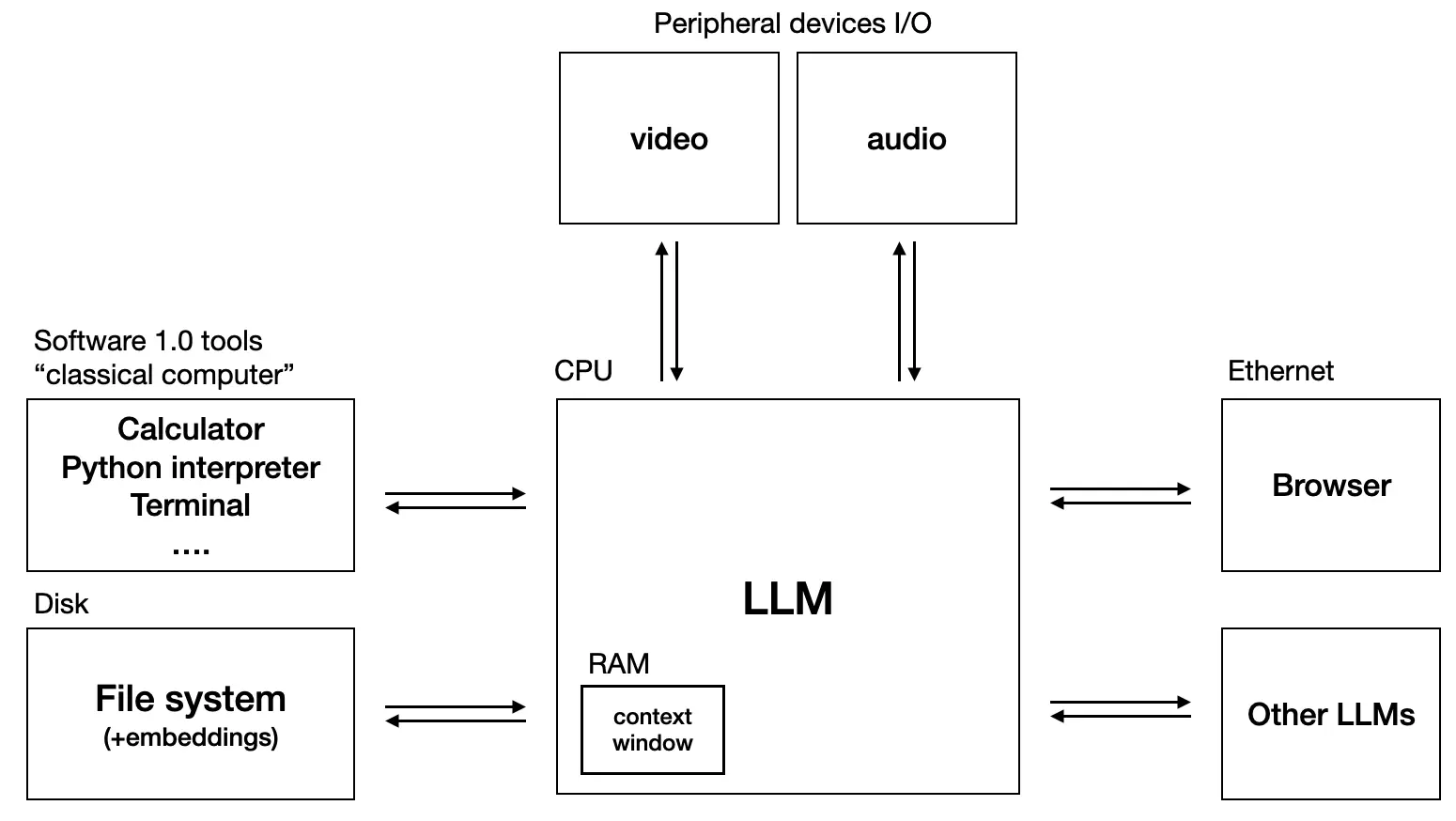
LLM OS
上古卷軸破解

未來
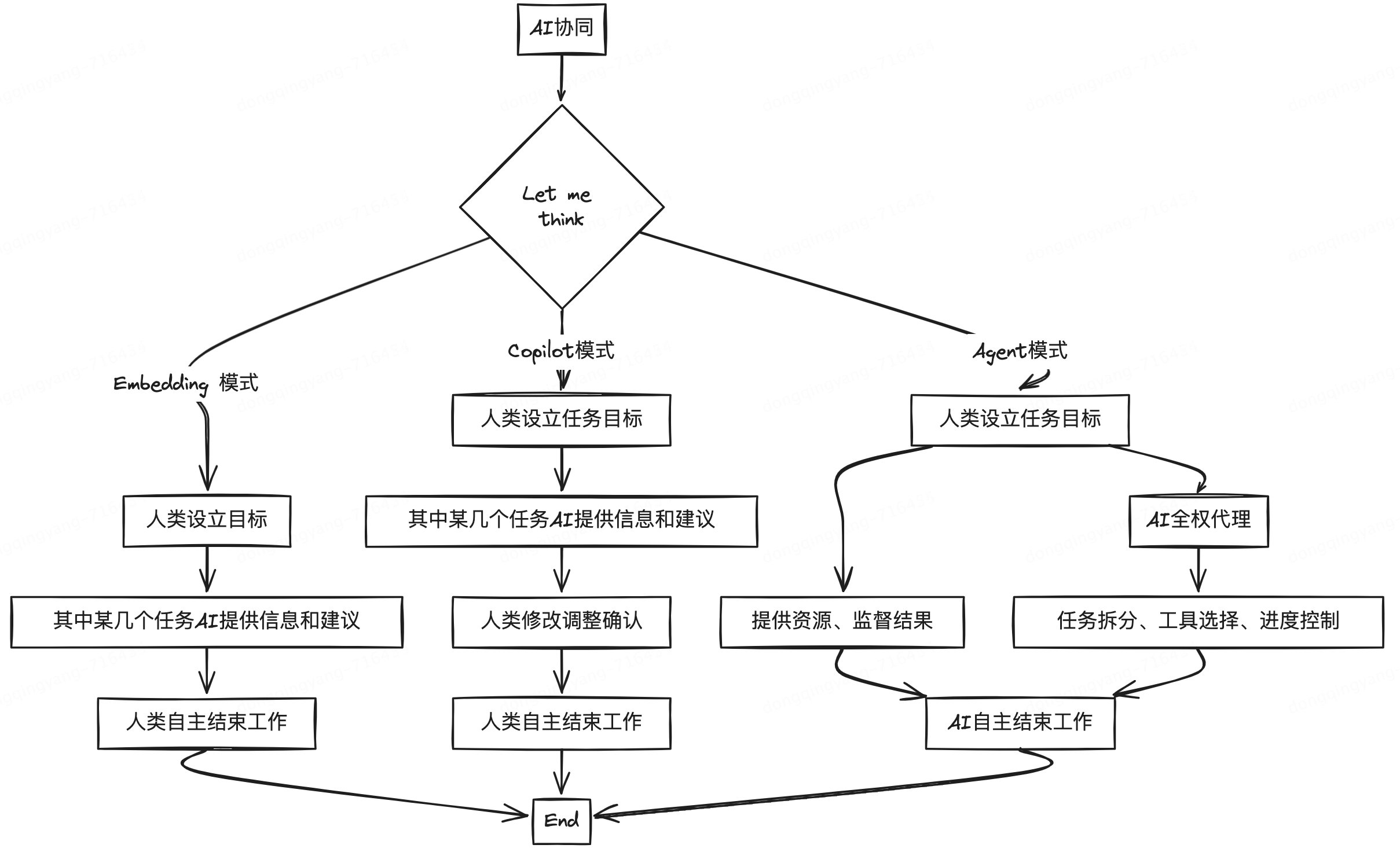
?
隨著AI技術(shù)的不斷發(fā)現(xiàn)和進步,AI與人類的協(xié)同關(guān)系將不斷演進和深化。我們期待著在未來,AI能夠成為我們最得力的助手和伙伴,共同迎接更加智能和高效的未來。我們可以預見以下幾個趨勢:
?更高的自主性:AI將逐步從輔助工具發(fā)展為能夠獨立完成復雜任務的智能代理。這將解放人類的生產(chǎn)力,使我們能夠?qū)W⒂诟邉?chuàng)造性和戰(zhàn)略性的工作。
?更緊密的協(xié)同:AI與人類的協(xié)同方式將更加多樣化和靈活化。通過改進人機交互界面和協(xié)同算法,AI將能夠更好地理解人類的意圖和需求,實現(xiàn)更高效的合作。
?廣泛的應用場景:AI技術(shù)將滲透到各行各業(yè),從醫(yī)療、教育到金融、制造業(yè),AI將成為推動行業(yè)變革的重要力量。特別是在Agent模式下,AI將能夠在更多領(lǐng)域中自主完成任務,帶來前所未有的效率提升和創(chuàng)新機會。
審核編輯 黃宇
-
AI
+關(guān)注
關(guān)注
87文章
30919瀏覽量
269171 -
人工智能
+關(guān)注
關(guān)注
1791文章
47294瀏覽量
238578 -
機器學習
+關(guān)注
關(guān)注
66文章
8419瀏覽量
132675 -
大模型
+關(guān)注
關(guān)注
2文章
2459瀏覽量
2737
發(fā)布評論請先 登錄
相關(guān)推薦
【「大模型啟示錄」閱讀體驗】營銷領(lǐng)域大模型的應用
【「大模型啟示錄」閱讀體驗】對大模型更深入的認知
揭示大模型剪枝技術(shù)的原理與發(fā)展
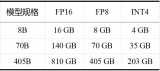
高效大模型的推理綜述







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論