 機器學習的經典算法與應用
機器學習的經典算法與應用
關于數據
機器學習就是喂入算法和數據,讓算法從數據中尋找一種相應的關系。Iris 鳶尾花數據集是一個經典數據集,在統計學習和機器學習領域都經常被用作示例。數據集內包含 3 類共 150 條記錄,每類各 50 個數據,每條記錄都有 4 項特征:花萼長度、花萼寬度、花瓣長度、花瓣寬度,可以通過這4個特征預測鳶尾花卉屬于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品種。
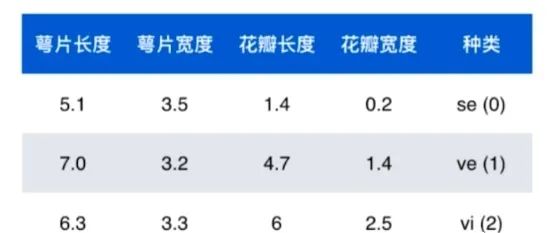
數據的整體成為數據集(dataset),數據中的每一行為1個樣本(sample),除最后一行,每一列表達樣本的一個特征(feature),最后一列,通常稱為標記(label)。在鳶尾花的數據集中,每個樣本有4個特征:萼片長度、萼片寬度、花瓣長度、花瓣寬度,下面每一行數據稱為一個樣本的特征向量。所有的特征向量組成的空間稱為特征空間(feature space),而分類任務的本質就是對特征空間的一種切分方式。
特征可以很具體也可以很抽象,在圖像中,每一個像素點都是一個特征,一個28*28的圖像有784個特征。所以,特征將很大程度上決定了算法結果的準確性和可靠性。這就是特征工程。
機器學習的基本任務1. 分類
- 二分類,在實際生活中其實大多數都可以用二分類解決,比如垃圾郵件分類,腫瘤辨別等。
- 多分類,比如手寫數字識別,比如更加復雜的圖像識別。在實際的生活中,很多復雜問題都可 以被轉換為是一種多分類問題,但并不是說使用多分類是最佳的一種解決方式。
2. 回歸
回歸任務的特點:結果是一個數字的值,而非一個類別。比如預測房子價格,比如預測一個學生成績,股票價格等等。在一些情況下,回歸任務可以簡化成分類任務,比如預測一個學生的成績,可以將成績分為幾個不同的等級,這樣就能將一個連續的回歸問題轉換為分類問題。
什么是機器學習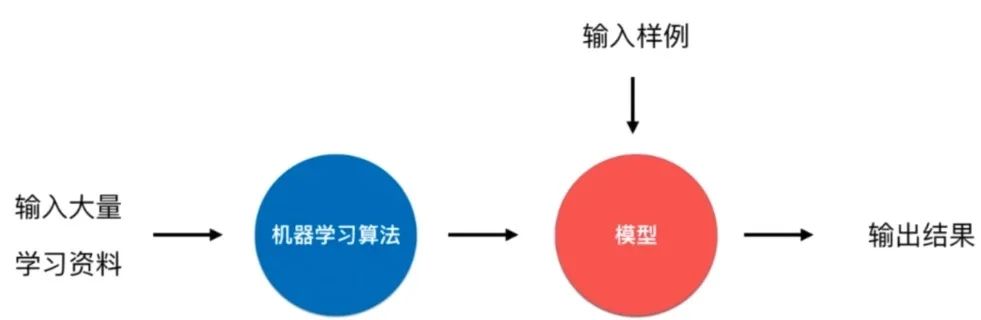
機器學習算法的目的就是幫助我們建立一個模型f(x),而不是我們人為建模得到的。其實分類和回歸問題大多都是在監督學習中完成的。
二、機器學習的分類
1、監督學習
所謂監督學習其實就是給機器的訓練數據擁有"標記"或者"答案"。比如圖像擁有一定的標定信息,可能是類別,也可能是定位框等。機器學習的算法中大多都是監督學習,比如k近鄰、線性回歸和多項式回歸、邏輯回歸、SVM、決策樹和隨機森林等。
2、非監督學習
相對于監督學習,非監督學習就是給機器訓練的數據沒有"標記"或者"答案",通常情況下,非監督學習用來輔助監督學習。非監督學習一般對沒有“標記”的數據進行分類,這就是聚類。比如電商網站使用非監督學習,根據顧客的瀏覽記錄,對顧客進行分類,從而完成一些類似推薦的任務。非監督學習的意義、聚類、異常檢測
降維
- 特征提取
- 特征壓縮,比如剛剛提到的28*28的圖像有784個特征,那么就可以考慮進行一下特征壓縮。
- 特征壓縮就是在盡可能損失少的信息,將高維向量壓縮成低維向量,這樣可以大大提高機器學習的運算效率。
- 降維處理的另外一個目的就是對數據進行可視化,對自己數據有一個大致了解。
3、半監督學習
所謂的半監督學習就是我們面對的任務一部分是有"標記"或者"答案",另一部分沒有。因為在現實生活中很多任務都因為各種不同原因造成標記的缺失。比如我們手機中的相冊中照片一些可能是在上海拍的,一些是在北京拍的,但是也會存在一些照片根本沒有標記,那么手機相冊中所有的照片就滿足半監督學習的這個形態。通常都是先使用無監督學習手段對數據做處理,之后使用監督學習手段做模型的訓練與預測。其實就是這兩種學習模式的結合。
4、強化學習
強化學習是根據周圍環境的情況,采取行動,根據采取行動的結果,學習行動的方式。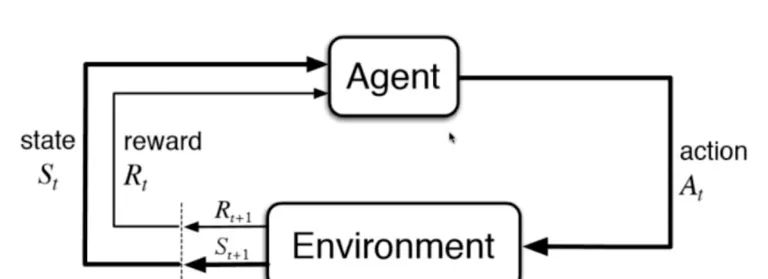
比如AlphaGo,無人駕駛都會用到增強學習
三、機器學習的其他分類1、批量學習(離線學習)和在線學習
- 批量學習(batch learning)、又叫離線學習
 優點:簡單問題:如何適應環境的變換。比如垃圾郵件的樣式。解決方案:定時重新批量學習,來適應環境的整體變換。缺點:每次重新批量學習,運算量巨大。在某些環境變換非常快的情況下,甚至是不可能的。比如股市的變化。
優點:簡單問題:如何適應環境的變換。比如垃圾郵件的樣式。解決方案:定時重新批量學習,來適應環境的整體變換。缺點:每次重新批量學習,運算量巨大。在某些環境變換非常快的情況下,甚至是不可能的。比如股市的變化。
- 在線學習(online learning)
 優點:及時反映新的環境變換問題:新的數據帶來不好的變化?解決方案:需要加強對數據的監控,比如異常檢測。其他適用范圍:數據量巨大,無法批量學習的環境。2、參數學習與非參數學習
優點:及時反映新的環境變換問題:新的數據帶來不好的變化?解決方案:需要加強對數據的監控,比如異常檢測。其他適用范圍:數據量巨大,無法批量學習的環境。2、參數學習與非參數學習
- 參數學習(Parameteric learning)
比如一個線性擬合問題y=wx+b,我們需要學習的參數就是w和b,參數學習的一個特點就是一旦學習到了參數,就不再需要原來的數據集。
- 非參數學習(Noneparameteric learning)
相對的非參數學習,不需要對模型進行過多的假設,通常在預測的過程中,喂給機器學習算法的那些數據集也要參數預測的過程,此外,需要特別注意的一點就是,非參數學習不等于沒參數!
四、機器學習的“哲學”思考
數據越多越好?
2001年,微軟的一篇論文,對比了四個不同的機器學習算法,給予足夠多的數據時,四種算法的表現都是隨著數據集的不斷增大,準確率越高,當數據量大到一定程度的時候,算法結果準確度基本差不多。
這就帶來一個問題,就是如果數據足夠多,那么數據即算法?由此,就拉開了大數據的帷幕,人們對數據也越來月重視。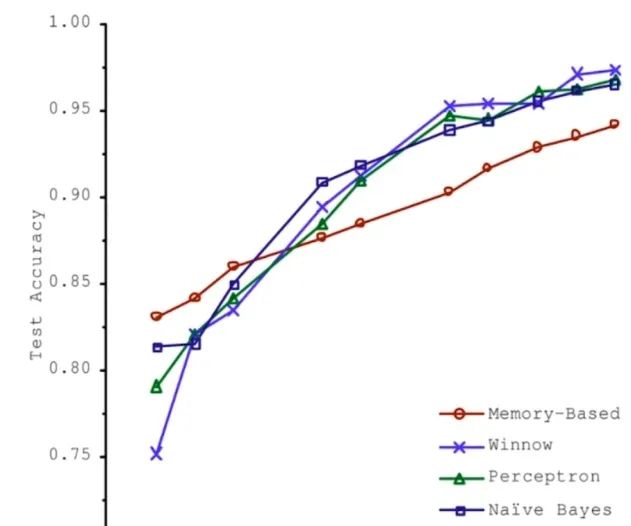 首先,由此可以得出結論,數據確實非常重要,而且現階段使用到的機器學習算法大多都是以數據為驅動的,高度地依賴數據的質量,那么由此就需要收集更多的數據,提高數據的質量。也就有了數據清理、數據 預處理之說。那么從數據層面,我們需要考慮,如何提高數據的代表性,研究更重要的特征。算法為王?Alpha Zero的出現,之所以非常的突破,其原因在于我們并沒有給Alpha Zero任何數據,所有的數據都是由算法產生的,這樣的一個突破似乎打破了之前的數據越多越好,數據集算法的這么一個說法。也是由于圍棋這個環境的特殊性導致算法能夠自己產生數據,于是就有算法為王這么一種狀況,可能在其他領域并不適用,但是它給予了我們一個啟示:算法依然很重要。再好的數據都需要有高效、優秀的算法作為輔助,才能最大成都發揮數據本身的作用。如何選擇機器學習算法?在機器學習算法中,遠不止下面幾種,那么如何選擇合適的機器學習算法完成自己既定的任務呢?
首先,由此可以得出結論,數據確實非常重要,而且現階段使用到的機器學習算法大多都是以數據為驅動的,高度地依賴數據的質量,那么由此就需要收集更多的數據,提高數據的質量。也就有了數據清理、數據 預處理之說。那么從數據層面,我們需要考慮,如何提高數據的代表性,研究更重要的特征。算法為王?Alpha Zero的出現,之所以非常的突破,其原因在于我們并沒有給Alpha Zero任何數據,所有的數據都是由算法產生的,這樣的一個突破似乎打破了之前的數據越多越好,數據集算法的這么一個說法。也是由于圍棋這個環境的特殊性導致算法能夠自己產生數據,于是就有算法為王這么一種狀況,可能在其他領域并不適用,但是它給予了我們一個啟示:算法依然很重要。再好的數據都需要有高效、優秀的算法作為輔助,才能最大成都發揮數據本身的作用。如何選擇機器學習算法?在機器學習算法中,遠不止下面幾種,那么如何選擇合適的機器學習算法完成自己既定的任務呢? 那么和選擇相關的問題,最簡單也就是最深刻的就是奧卡姆的剃刀,簡單的就是好的?那么在機器學習的領域中,什么叫簡單?第二個就是沒有免費午餐的定理。可以嚴格地數學推導出:任意兩個算法他們的期望性能是相同的!!!這也就是說其實沒有那種算法從嚴格意義上比另外一種算法好,只是都在各自的領域中表現突出。相當于是說所有的算法是等價的,但這有一個前提,就是任意兩個算法,把他們作用于所有的問題中,那么對于有些問題A算法比B算法好,但對于有些問題B算法比A算法好,但平均來說,這兩個算法是一樣的。這就是說需要具體到某個特定問題的時候,有些算法可能更好。整體而言,沒有一種算法絕對的比另外一種算法好。也就說脫離具體問題去談哪個算法好是沒有意義的。最終的結論就是,我們在面對一個具體問題的時候,嘗試使用多種算法進行對比實驗是必要的!面對不確定的世界,怎樣看待機器學習算法進行預測的結果?最典型的問題就是比如預測股市,預測世界經濟趨勢扥等等等。我們到底應該怎樣看待這個結果?到底是機器學習算法本身起到了決定性作用,使得我們得到了一個準確的預測結果,還是其實只是一個巧合,機器學習本身并沒有起到太大的作用。在使用機器學習的過程中存在的機器倫理問題?比如無人駕駛決策的過程中存在的一個無法避免的問題是車的道路左邊是小孩,右邊是老人,此時車輛無法避免,必須要做出決策,是老人還是孩子?如果選擇自毀,那么車里坐的是一個孕婦,此時就牽涉到倫理問題。甚至還會有人說人工智能威脅論等等。
那么和選擇相關的問題,最簡單也就是最深刻的就是奧卡姆的剃刀,簡單的就是好的?那么在機器學習的領域中,什么叫簡單?第二個就是沒有免費午餐的定理。可以嚴格地數學推導出:任意兩個算法他們的期望性能是相同的!!!這也就是說其實沒有那種算法從嚴格意義上比另外一種算法好,只是都在各自的領域中表現突出。相當于是說所有的算法是等價的,但這有一個前提,就是任意兩個算法,把他們作用于所有的問題中,那么對于有些問題A算法比B算法好,但對于有些問題B算法比A算法好,但平均來說,這兩個算法是一樣的。這就是說需要具體到某個特定問題的時候,有些算法可能更好。整體而言,沒有一種算法絕對的比另外一種算法好。也就說脫離具體問題去談哪個算法好是沒有意義的。最終的結論就是,我們在面對一個具體問題的時候,嘗試使用多種算法進行對比實驗是必要的!面對不確定的世界,怎樣看待機器學習算法進行預測的結果?最典型的問題就是比如預測股市,預測世界經濟趨勢扥等等等。我們到底應該怎樣看待這個結果?到底是機器學習算法本身起到了決定性作用,使得我們得到了一個準確的預測結果,還是其實只是一個巧合,機器學習本身并沒有起到太大的作用。在使用機器學習的過程中存在的機器倫理問題?比如無人駕駛決策的過程中存在的一個無法避免的問題是車的道路左邊是小孩,右邊是老人,此時車輛無法避免,必須要做出決策,是老人還是孩子?如果選擇自毀,那么車里坐的是一個孕婦,此時就牽涉到倫理問題。甚至還會有人說人工智能威脅論等等。
來源:小白學視覺
-
人工智能
+關注
關注
1791文章
47279瀏覽量
238498 -
機器學習
+關注
關注
66文章
8418瀏覽量
132635 -
數據集
+關注
關注
4文章
1208瀏覽量
24701
發布評論請先 登錄
相關推薦









 工商網監
工商網監
評論