 打破定制加速器的桎梏:在邊緣AI中擁抱靈活性
打破定制加速器的桎梏:在邊緣AI中擁抱靈活性
先進計算技術如今已成為提升生產力和改變日常體驗的普遍工具。以汽車領域為例,高級駕駛輔助系統(ADAS)具備處理大量計算密集型任務的能力,從攝像頭數據預處理直到傳感器融合和路徑規劃,而且這些均不影響車輛的正常行駛里程。
邊緣計算方面的最新創新包括Wayve的LINGO-2,這是一個基礎模型,將視覺、語言和行動聯系起來,用以解釋和確定駕駛行為。這類解決方案正推動汽車行業走向新的方向,其中車輛中的AI能夠提供諸如直覺、語言響應界面、個性化駕駛風格以及協同駕駛等功能,從而增強自動駕駛體驗。
在邊緣計算的其他領域,AI筆記本電腦提供了諸多優勢,從借助AI賦能的內容創作工具以提高生產效率,到能夠在本地運行而無需與云共享用戶數據的協同駕駛。這些筆記本電腦將需要比以往任何移動PC更強的AI性能;微軟新推出的Copilot+PC就采用了GPT-4模型和40+TOPS的配置,同時具備輕薄設計和全天候續航能力。
邊緣基礎模型
AI達到這一能力水平并非因為程序員最終成功地將人腦轉化為代碼,而是研究人員成功地將云中可用的大量加速計算應用于通用模型,正如Rich Sutton在其《苦澀的教訓》(The Bitter Lesson)論文中所討論的那樣。基于上述提到的GPT-4等通用基礎模型進行微調的解決方案,正成為普及AI的首選方法。與其創建特定領域的算法,不如使用功能強大、可跨多個領域應用的模型,這些模型利用云資源與大量多模態數據進行訓練,然后針對特定應用和設備進行微調。
為了適應邊緣環境,這些經過調整的模型需要在更小、功能極具受限的設備上運行,這些設備具有嚴格的安全標準、有限的電源供應和不穩定的互聯網連接。它們不僅要提供基本的推理能力,還要支持設備上的微調和終身持續學習。此外,它們還需要與維護最佳用戶體驗的關鍵日常功能共享系統級芯片(SoC),如用戶界面、圖像處理和音頻處理。
然而,盡管在可用性能、熱管理技術甚至是商業模式方面存在差異,邊緣AI仍可借鑒AI在云計算中成功的理念:即從加速器硬件到AI框架的所有方面都使用通用方法。隨著晶體管縮放和新封裝技術的進步,計算量即便大幅增加也可輕松擴展。是以,為支持客戶在邊緣AI取得成功,Imagination同時采用了以下兩種方案策略:
基于開放標準開發軟件
- 提升通用計算加速器的硬件能力
基于開放標準開發軟件
Imagination在邊緣AI的交付中采取軟件優先的方法,以最大化硬件的可編程性和靈活性。啟用優化庫等軟件和工具包提供了一種機制,以實現最高效率和對調度及內存管理的嚴格控制。目前已經有一個不斷增長的框架和庫生態系統,它們以OpenCL后端為基礎,加速上市時間,并提供了作為異構計算系統子集進行更高級優化和集成的機會。它涵蓋了AI部署環境以及計算機視覺和其他通用計算庫。
合作是成功的關鍵。去年,Imagination與其他領先科技公司一起,作為創始成員加入了UXL基金會,這是一個被稱為與NVIDIA封閉CUDA語言相抗衡的開放、跨平臺、供應商中立組織。該基金會正在開發oneAPI編程模型和DPC++ SYCL實現。通過使這一計劃成為Linux基金會下真正的開源項目,UXL基金會為像Imagination 這樣的公司提供了催化劑,將已經在高性能計算領域廣泛應用的oneAPI標準的優勢,擴展到邊緣計算領域。這將在應對計算應用的程序快速開發和跨平臺復用的挑戰中發揮重要作用。
Imagination正通過UXL基金會積極參與并影響oneAPI標準的制定,同時我們也在為邊緣平臺開發和推出下一代計算工具和軟件堆棧。我們與合作伙伴和客戶緊密合作,鼓勵更廣泛地參與并采用這一標準。我們旨在為開發過程中的所有利益相關者,提供易于訪問的適用于Imagination平臺的工具包,這些工具包將提供符合當前邊緣計算應用開發周期典型需求的“功能性到高性能再到最優”的工作流程,同時也利用構建和運行時目標獨立性的優勢。
提升通用計算加速器的能力
Imagination幫助客戶在邊緣AI領域取得成功第二個策略,主要通過保持硬件靈活性和可編程性的同時,向邊緣設備注入更強的計算性能。目前,邊緣計算加速通常在以下處理器類型中進行:
中央處理器(CPUs):SoC的傳統控制中心和主要工作組件;CPU越來越具備AI能力,擁有一定程度的并行性(例如多核)并支持相關數據格式;它們可以根據需要卸載更專業的計算處理器。
數字信號處理器(DSPs):廣泛應用于汽車、電信等多個市場,用于音頻、視頻、攝像頭和連接性處理,最近還通過矢量處理支持AI應用。
圖形處理器(GPUs):GPU本質上是可編程和通用的。雖然它們傳統上僅用于圖形加速,但近年來其并行性已應用于諸如超分辨率、點云處理和非機器學習算法等計算應用中,并且越來越多地采用低精度算術功能。
神經處理單元(NPUs):高度優化的領域特定加速器,專注于低精度算術,以有效處理深度學習算法訓練中常見的密集矩陣乘法代碼。
未來的問題是:這些處理器類型中哪一種為下一代邊緣AI加速器提供了最佳基礎?
這是Imagination擅長解決的問題。我們的工程師通過創造創新解決方案來解決技術難題,使客戶能夠成功。我們在四個市場中出貨超過130億顆芯片,產品范圍涵蓋GPU、CPU、AI IP以及軟件。我們的工程團隊在設計用于計算和AI的半導體技術方面擁有豐富的經驗,從針對CNN風格工作負載優化的NNA產品線開始,目前該產品線已運用于多個汽車和消費市場的SoC中,例如玄鐵TH1520 SoC。
盡管客戶在NNA上取得了許多成功,但Imagination認識到邊緣AI將需要開發新一代更靈活和可編程的NPU,或是新一代GPU加速器,這些加速器在保持能效的同時提供更強的計算性能。這與依賴通用而非過度定制化方法的原則相一致,正是這一原則使得AI在云端取得了成功,而這一目標的實現將得益于半導體市場上幾個關鍵趨勢的推動。
打破定制加速器(ASIC)的桎梏
首先,值得更詳細地探討為什么通用加速器比高度定制化的硬件更受歡迎。當前邊緣AI的處理方式,特別是在注重性能的設備如汽車和筆記本電腦中,聚焦于NPU:這是一種高度優化的處理器,能在較小的面積或功耗預算內實現高效率。與傳統的GPU張量核心相比,NPU具有更大的矩陣片規模,具有專門為神經網絡加速設計的固定功能硬件,關注低精度數值格式,進行graph編譯和優化以減少數據的搬運和增強數據的本地性。
低精度數字格式
半導體計算中關鍵趨勢之一是,提升通用加速器(如GPU)計算性能的是低精度數字格式的激增。這些格式歷來是NPU領域的專屬,但現在在GPU等其他加速器中也越來越常見。像開放計算項目(Open ComputeProject,簡稱OCP, 這樣的組織正開始推動從FP32到FP4及微縮比例(MX)兼容格式的標準化工作,這些格式適用于CPU、GPU、NPU等多種處理器。預期這些數字格式將從數據中心領域擴展到整個軟件生態系統中。
先進工藝節點帶來的機遇與挑戰
此外,多年以來,半導體行業一直受益于摩爾定律:在相同硅片面積上每代性能的提升。英特爾、三星和臺積電等晶圓廠,對于挖掘這種邏輯電路尺寸縮小帶來的好處起到了根本性作用。先進工藝節點是通用加速器提升計算性能至邊緣AI所需水平的關鍵之一。
然而,SRAM(靜態隨機存取存儲器)被證明很難縮小。隨著AI模型對性能、數據本地性和低延遲要求的提高,實際上任何給定處理器,特別是如NPU這樣的領域特定加速器,對SRAM的需求反而增加了。未來的疑問是,我們是否真的能承受將如此昂貴的資源專門分配給僅在其功能需要時才激活的單一處理器?
與此同時,隨著晶體管密度的增加,熱管理問題比現在變得更加嚴峻。高度優化且能耗大的加速器加劇了這一挑戰,在SoC內部形成了工作負載特定的熱點,難以緩解。
然而,如果像CPU和GPU這樣的通用加速器在保持能效的同時增加其計算能力,那么基于少量高效、通用、可擴展加速器的邊緣SoC,將是解決先進工藝節點熱管理挑戰的一個有前景的方案。這種方法最小化了暗硅現象,為系統設計師提供了在整個核心中分布處理而非創建特定應用熱點的機會,并保證了集成、系統和編程復雜度的可控性。
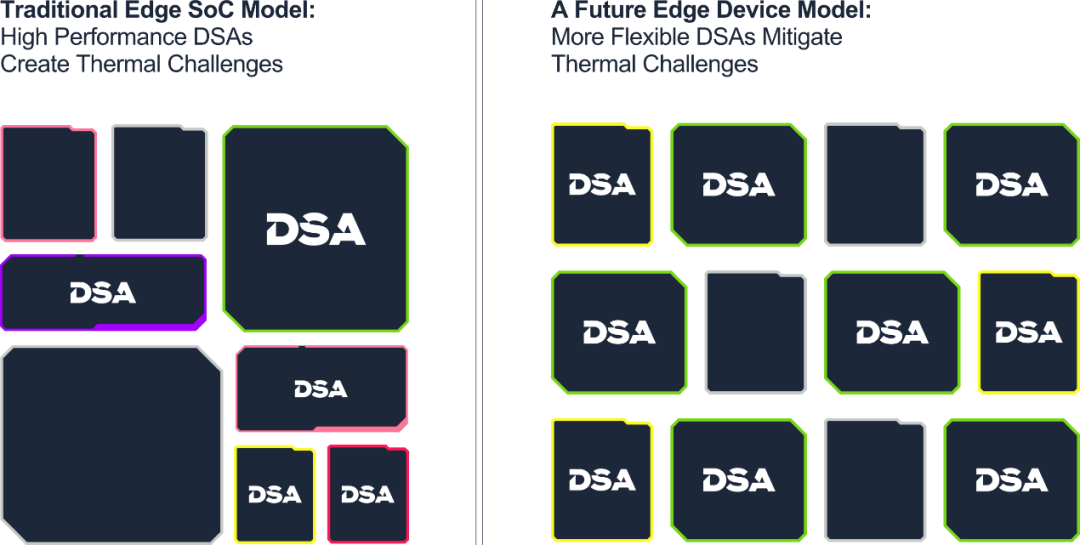
邊緣AI的下一代技術
考慮到這些發展,基于GPU和RISC-V架構的下一代處理器正逐步成為提供高性能、低功耗且適用于通用目的的加速器,這是邊緣AI所必需的。Imagination在邊緣圖形和計算技術領域處于世界領先地位。我們的GPU徹底改變了智能手機市場,并且從未停止開拓創新,比如生產出了首款能夠在移動設備上實現的實時光線追蹤的高效架構。隨著GPU和RISC-V CPU成為實現邊緣AI的首選處理器,我們的工程師正在開發客戶及更廣泛技術生態系統取得成功所需的技術解決方案。未來幾個月將有確切內容發布。在此期間,如果:
您是一家開發具備AI能力SoC的半導體公司
您是對即將改變用戶體驗的技術感興趣的原始設備制造商(OEM)
您是一家開發基于AI應用的軟件公司
都可以通過與我們銷售團隊預約會議來提前了解Imagination的計算產品路線圖。
-
加速器
+關注
關注
2文章
804瀏覽量
37968 -
自動駕駛
+關注
關注
784文章
13895瀏覽量
166688 -
邊緣AI
+關注
關注
0文章
98瀏覽量
5041
發布評論請先 登錄
相關推薦

RISC-V,即將進入應用的爆發期
下一代高功能新一代AI加速器(DRP-AI3):10x在高級AI系統高級AI中更快的嵌入處理

OPSL 優勢1:波長靈活性
Imagination 引領邊緣計算和AI創新,擁抱AI未來發展

8芯M16公頭如何提升靈活性

Arm推動生成式AI落地邊緣!全新Ethos-U85 AI加速器支持Transformer 架構,性能提升四倍






 工商網監
工商網監
評論