 深度神經網絡中的前饋過程
深度神經網絡中的前饋過程
深度神經網絡(Deep Neural Networks,DNNs)中的前饋過程是其核心操作之一,它描述了數據從輸入層通過隱藏層最終到達輸出層的過程,期間不涉及任何反向傳播或權重調整。這一過程是神經網絡進行預測或分類任務的基礎。
一、引言
深度神經網絡作為深度學習領域的基石,通過多層非線性變換來捕捉數據中的復雜模式和特征,進而實現高精度的預測和分類任務。在前饋神經網絡(Feedforward Neural Networks,FNNs)中,信息嚴格地從輸入層流向輸出層,每一層都通過一系列的權重和偏置對輸入進行線性組合和非線性變換,最終生成網絡的輸出。本文將深入剖析深度神經網絡中的前饋過程,包括其基本原理、實現步驟、激活函數的作用以及實際應用中的挑戰與解決方案。
二、深度神經網絡的基本結構
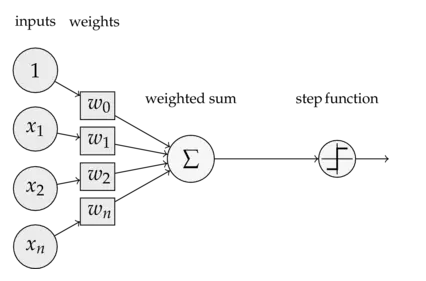
深度神經網絡由多個層次組成,包括輸入層、隱藏層和輸出層。每一層都包含一定數量的神經元(或稱節點),神經元之間通過權重和偏置相互連接。在前饋過程中,輸入數據首先被送入輸入層,然后逐層向前傳播,經過各隱藏層的線性組合和非線性變換,最終生成輸出層的結果。
- 輸入層 :接收原始數據作為輸入,不進行任何變換,僅將數據傳遞給下一層。
- 隱藏層 :位于輸入層和輸出層之間,是神經網絡中最重要的部分。隱藏層可以對輸入數據進行多次非線性變換,提取出數據中的高級特征。隨著隱藏層數的增加,網絡能夠學習到更加復雜和抽象的特征表示。
- 輸出層 :接收來自隱藏層的最后一組數據,經過適當的變換后輸出最終的結果。對于分類任務,輸出層通常采用softmax函數等將輸出轉換為概率分布;對于回歸任務,則直接輸出預測值。
三、前饋過程的實現步驟
深度神經網絡中的前饋過程可以概括為以下幾個步驟:
- 初始化參數 :在訓練開始前,需要隨機初始化網絡中的權重和偏置。這些參數將在訓練過程中通過反向傳播算法進行更新。
- 接收輸入數據 :將待處理的數據送入輸入層。在實際應用中,輸入數據通常需要經過預處理操作,如標準化、歸一化等,以加快訓練速度和提高模型性能。
- 前向傳播 :從輸入層開始,逐層計算每一層的輸出。對于隱藏層中的每一個神經元,其輸入為前一層所有神經元的輸出加權和加上偏置項;然后,通過激活函數對加權和進行非線性變換,得到該神經元的輸出。這一過程將一直持續到輸出層生成最終結果。
- 計算輸出 :在輸出層,根據具體任務的需求對最后一層神經元的輸出進行適當的變換(如softmax函數、sigmoid函數等),以得到最終的預測結果或分類概率。
四、激活函數的作用
激活函數是深度神經網絡中不可或缺的一部分,它引入了非線性因素,使得神經網絡能夠學習復雜的模式和表示。在前饋過程中,激活函數對每一層神經元的加權和進行非線性變換,從而生成該神經元的輸出。常見的激活函數包括Sigmoid、ReLU、Tanh等。
- Sigmoid函數 :將輸入映射到(0,1)區間內,常用于二分類問題的輸出層。然而,Sigmoid函數在深度網絡中容易出現梯度消失問題,且其輸出不是以0為中心的,這可能導致收斂速度變慢。
- ReLU函數 (Rectified Linear Unit):是目前最常用的激活函數之一。它對于所有正數輸入返回其本身,對于負數輸入則返回0。ReLU函數具有計算簡單、收斂速度快等優點,且在一定程度上緩解了梯度消失問題。然而,當輸入小于0時,ReLU函數的導數為0,這可能導致部分神經元在訓練過程中“死亡”,即不再對輸入數據產生任何響應。
- Tanh函數 :將輸入映射到(-1,1)區間內,其輸出是以0為中心的。與Sigmoid函數相比,Tanh函數在訓練初期收斂速度更快,但其計算復雜度和梯度消失問題仍然存在。
五、實際應用中的挑戰與解決方案
在將深度神經網絡應用于實際問題時,可能會遇到一系列挑戰,如梯度消失/爆炸、過擬合、計算資源限制等。針對這些問題,研究人員提出了多種解決方案:
- 梯度消失/爆炸 :通過選擇合適的激活函數(如ReLU)、使用批歸一化(Batch Normalization)等技術來緩解梯度消失/爆炸問題。此外,調整學習率、采用更先進的優化算法(如Adam)等也有助于改善梯度傳播效果。
- 過擬合 :通過增加數據集規模、采用正則化技術(如L1/L2正則化、Dropout等)、提前停止訓練等方法來防止過擬合。此外,還可以利用集成學習方法,如Bagging、Boosting等,通過結合多個模型的預測結果來提高整體模型的泛化能力。
- 計算資源限制 :隨著深度神經網絡層數的增加和模型復雜度的提升,對計算資源的需求也急劇增加。為了應對這一挑戰,研究人員開發了多種優化技術,包括模型剪枝(去除不重要的神經元和連接)、量化(將模型權重從浮點數轉換為整數或更低精度的浮點數)、知識蒸餾(將一個大型模型的知識遷移到一個小型模型中)等。此外,利用分布式計算和并行處理技術也是加速深度神經網絡訓練的有效手段。
- 數據不平衡 :在實際應用中,不同類別的樣本數量往往存在顯著差異,這會導致模型在少數類樣本上的性能較差。為了解決數據不平衡問題,可以采用過采樣(增加少數類樣本的數量)、欠采樣(減少多數類樣本的數量)、合成少數類過采樣技術(SMOTE)等方法來平衡各類樣本的數量。同時,調整損失函數,如使用加權交叉熵損失,也可以在一定程度上緩解數據不平衡帶來的問題。
- 可解釋性 :雖然深度神經網絡在許多任務上取得了卓越的性能,但其決策過程往往難以解釋,這在一些需要高度可解釋性的領域(如醫療、法律等)中成為了一個障礙。為了提高深度神經網絡的可解釋性,研究人員提出了多種方法,如特征可視化、注意力機制、LIME(Local Interpretable Model-agnostic Explanations)等。這些方法可以幫助我們理解模型是如何做出決策的,從而增加我們對模型預測結果的信任度。
六、前饋過程在深度學習框架中的實現
在現代深度學習框架(如TensorFlow、PyTorch等)中,前饋過程的實現變得非常簡便。這些框架提供了豐富的API和工具,使得我們可以輕松地構建、訓練和評估深度神經網絡。在這些框架中,前饋過程通常通過定義一個計算圖(Computational Graph)來實現,該圖描述了數據在網絡中的流動方向和變換過程。在訓練過程中,框架會自動執行前饋過程,并根據損失函數的梯度進行反向傳播和參數更新。
七、結論與展望
深度神經網絡中的前饋過程是神經網絡進行預測和分類任務的基礎。通過逐層傳遞和變換輸入數據,深度神經網絡能夠學習到數據中的復雜模式和特征,并生成準確的預測結果。然而,在實際應用中,我們還需要面對梯度消失/爆炸、過擬合、計算資源限制、數據不平衡和可解釋性等挑戰。為了解決這些問題,研究人員提出了多種優化技術和方法。未來,隨著深度學習技術的不斷發展和完善,我們有理由相信深度神經網絡將在更多領域發揮重要作用,并為人類帶來更多的便利和福祉。
同時,我們也應該注意到,雖然深度神經網絡在許多任務上取得了令人矚目的成績,但其背后仍存在許多未解之謎和待探索的領域。例如,如何進一步提高深度神經網絡的泛化能力、如何更好地理解和解釋深度神經網絡的決策過程、如何更有效地利用有限的計算資源等。這些問題的解決不僅需要我們不斷探索和創新,還需要我們加強跨學科合作和交流,共同推動深度學習技術的發展和進步。
-
函數
+關注
關注
3文章
4331瀏覽量
62618 -
深度學習
+關注
關注
73文章
5503瀏覽量
121162 -
深度神經網絡
+關注
關注
0文章
61瀏覽量
4527
發布評論請先 登錄
相關推薦
基于三層前饋BP神經網絡的圖像壓縮算法解析
深度神經網絡是什么
基于遞歸神經網絡和前饋神經網絡的深度學習預測算法
快速了解神經網絡與深度學習的教程資料免費下載





 工商網監
工商網監
評論