 大語言模型的預訓練
大語言模型的預訓練
引言
隨著人工智能技術的飛速發展,自然語言處理(NLP)作為人工智能領域的一個重要分支,取得了顯著的進步。其中,大語言模型(Large Language Model, LLM)憑借其強大的語言理解和生成能力,逐漸成為NLP領域的研究熱點。大語言模型的預訓練是這一技術發展的關鍵步驟,它通過在海量無標簽數據上進行訓練,使模型學習到語言的通用知識,為后續的任務微調奠定基礎。本文將深入探討大語言模型預訓練的基本原理、步驟以及面臨的挑戰。
大語言模型的基本概念
大語言模型指的是具有數十億甚至數千億參數的神經網絡模型,這些模型能夠在海量文本數據上進行訓練,并學習到豐富的語言知識和語義信息。相比傳統的自然語言處理模型,大語言模型具有以下幾個顯著優勢:
- 強大的語言理解能力 :能夠理解復雜的語義信息,并生成高質量的文本內容。
- 廣泛的應用場景 :可以應用于機器翻譯、文本摘要、問答系統、對話生成等多個領域。
- 持續的性能提升 :隨著模型規模和訓練數據的不斷增加,大語言模型的性能也在持續提升。
預訓練的基本原理
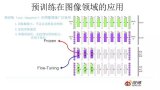
預訓練是遷移學習的一種形式,它通過在大規模無標簽數據上進行訓練,使模型學習到通用的語言知識,然后再針對特定任務進行微調。預訓練的主要目的是解決數據稀缺性和遷移學習問題,提高模型的泛化能力和訓練效率。
Transformer模型
在大語言模型中,Transformer模型因其強大的語言處理能力而備受青睞。Transformer是一種基于自注意力機制的神經網絡架構,它能夠有效地捕捉文本序列中的長距離依賴關系,從而提升模型的語言理解能力。Transformer架構包含多個編碼器層和解碼器層,每個編碼器層包含一個自注意力模塊和一個前饋神經網絡,解碼器層則在此基礎上增加了一個交叉注意力模塊,用于關注編碼器層的輸出。
自注意力機制
自注意力機制是Transformer架構的核心組成部分,它允許模型在處理每個詞語時,同時關注句子中的其他詞語,從而更好地理解詞語之間的語義聯系。
預訓練的具體步驟
大語言模型的預訓練過程通常包括以下幾個關鍵步驟:
數據收集與預處理
- 數據收集 :收集大量的文本數據,包括書籍、新聞、社交媒體、網頁等,以便訓練模型。
- 數據預處理 :對收集到的數據進行清洗、分詞、去除停用詞、詞干提取等處理,以提高模型的訓練效果。
模型設計
選擇合適的模型架構,如Transformer,并設置模型參數。在大語言模型中,Transformer模型因其高效性和強大的語言處理能力而被廣泛應用。
模型訓練
- 預訓練目標 :預訓練的主要目標是學習通用的語言知識,以便在后續的特定任務中進行微調。常見的預訓練目標包括語言模型(預測下一個詞語的概率)、掩碼語言模型(預測被掩蓋詞語的概率)和句子順序預測(判斷兩個句子的順序是否正確)。
- 訓練過程 :使用隨機梯度下降等優化算法對模型進行訓練,同時設置合適的學習率、批次大小等超參數。在訓練過程中,模型會學習到詞語的語義、句子的語法結構以及文本的一般知識和上下文信息。
模型評估與優化
- 模型評估 :使用測試數據對模型進行評估,以衡量其語言理解能力。常見的評估指標包括困惑度(衡量模型預測下一個詞語的不確定性)和下游任務性能(衡量模型在特定任務上的性能表現)。
- 模型優化 :根據評估結果對模型進行優化,如調整超參數、使用正則化技術、使用預訓練模型等,以提高模型的性能和泛化能力。
模型部署
將訓練好的模型部署到生產環境中,以便實現對文本的自然語言處理。在實際應用中,還需要對模型進行微調,以適應特定的任務需求。
預訓練的優勢與挑戰
優勢
- 提高模型的泛化能力 :通過大規模預訓練,模型可以學習到更多的數據和知識,從而提高其對未知數據的泛化能力。
- 減少訓練時間和數據量 :預訓練可以大幅減少后續任務所需的訓練時間和數據量,因為預訓練的結果可以直接應用到其它任務上。
- 提高算法的效率 :預訓練可以使得算法更加高效,因為預訓練的結果可以作為其它任務的初始值,避免從頭開始訓練的時間和計算資源浪費。
挑戰
- 計算成本高昂 :大語言模型由于參數量巨大,訓練過程中需要消耗大量的計算資源。隨著模型規模的增加,計算成本也呈指數級增長,這對硬件設備和能源效率提出了巨大挑戰。
- 數據隱私與偏見 :在收集和處理大量數據時,數據隱私成為一個關鍵問題。如何確保個人隱私不被泄露,同時避免模型學習到數據中的偏見和歧視性信息,是預訓練過程中必須面對的挑戰。
- 模型可解釋性 :盡管大語言模型在性能上取得了顯著進步,但其內部工作機制仍然相對不透明。這導致模型在做出決策時缺乏可解釋性,增加了在關鍵應用領域中應用的難度和風險。
- 優化超參數 :預訓練模型通常包含數以億計的參數,如何有效地優化這些參數以最大化模型性能是一個復雜的問題。超參數的調整需要大量的實驗和計算資源,且往往依賴于經驗和直覺。
- 持續學習與適應性 :現實世界的數據是不斷變化的,新的詞匯、表達方式和知識不斷涌現。大語言模型需要具備持續學習的能力,以適應這些變化,并保持其性能優勢。然而,如何在不破壞已學知識的前提下進行持續學習,仍然是一個未解難題。
- 模型壓縮與部署 :盡管大語言模型在性能上表現出色,但其龐大的體積限制了其在資源受限設備上的部署。因此,如何在保持模型性能的同時進行壓縮和優化,是另一個重要的研究方向。
未來展望
面對上述挑戰,未來的大語言模型預訓練研究將朝著以下幾個方向發展:
- 更高效的算法與架構 :研究人員將繼續探索更高效的算法和神經網絡架構,以降低計算成本并提高訓練效率。例如,通過引入稀疏連接、量化技術和混合精度訓練等方法來減少模型參數和計算量。
- 數據隱私保護與去偏見 :在數據收集和處理過程中,將更加注重隱私保護和去偏見技術的研究。例如,通過差分隱私、聯邦學習等技術來保護用戶隱私;通過數據增強、對抗性訓練等方法來減少模型偏見。
- 可解釋性增強 :為了提高模型的可解釋性,研究人員將探索更多的解釋性技術。例如,通過注意力可視化、知識蒸餾等方法來揭示模型的內部工作機制;通過構建可解釋性更強的模型架構來直接提高模型的可解釋性。
- 持續學習與自適應 :為了應對現實世界數據的變化,研究人員將研究更加高效的持續學習和自適應技術。例如,通過增量學習、元學習等方法來使模型能夠在線更新并適應新數據;通過引入記憶模塊來保存并利用歷史知識。
- 模型壓縮與優化 :在模型部署方面,研究人員將繼續探索模型壓縮與優化技術。例如,通過剪枝、量化、蒸餾等方法來減少模型體積并提高計算效率;通過優化模型架構來直接減少參數數量并保持性能優勢。
綜上所述,大語言模型的預訓練是自然語言處理領域的一個重要研究方向。雖然目前仍面臨諸多挑戰,但隨著技術的不斷進步和創新,相信未來大語言模型將在更多領域展現出其巨大的潛力和價值。
-
人工智能
+關注
關注
1791文章
47274瀏覽量
238469 -
模型
+關注
關注
1文章
3243瀏覽量
48836 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13561
發布評論請先 登錄
相關推薦
一文詳解知識增強的語言預訓練模型
【大語言模型:原理與工程實踐】大語言模型的預訓練
一套新的自然語言處理(NLP)評估基準,名為 SuperGLUE
微軟團隊發布生物醫學領域NLP基準
自然語言模型預訓練的發展史






 工商網監
工商網監
評論