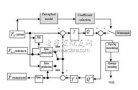
") 多層感知機(jī)模型結(jié)構(gòu)
多層感知機(jī)模型結(jié)構(gòu)
多層感知機(jī)(MLP,Multilayer Perceptron)是一種基本且廣泛應(yīng)用的人工神經(jīng)網(wǎng)絡(luò)模型,其結(jié)構(gòu)由多個層次組成,包括輸入層、一個或多個隱藏層以及輸出層。MLP以其強(qiáng)大的非線性映射能力和靈活的結(jié)構(gòu)設(shè)計,在分類、回歸、模式識別等多個領(lǐng)域展現(xiàn)出卓越的性能。以下是對多層感知機(jī)模型結(jié)構(gòu)的詳細(xì)闡述。
一、基本組成
1. 輸入層(Input Layer)
輸入層是MLP的第一層,負(fù)責(zé)接收外部輸入數(shù)據(jù)。輸入層中的神經(jīng)元數(shù)量通常與輸入數(shù)據(jù)的特征維度相對應(yīng)。例如,在圖像識別任務(wù)中,輸入層可能包含與圖像像素數(shù)量相等的神經(jīng)元;在文本分類任務(wù)中,則可能根據(jù)詞嵌入的維度來確定輸入層神經(jīng)元數(shù)量。輸入層的主要作用是將原始數(shù)據(jù)傳遞給后續(xù)的隱藏層進(jìn)行處理。
2. 隱藏層(Hidden Layer)
隱藏層是MLP中位于輸入層和輸出層之間的層次,負(fù)責(zé)提取輸入數(shù)據(jù)的潛在特征并進(jìn)行非線性變換。MLP可以包含一個或多個隱藏層,每個隱藏層由多個神經(jīng)元組成。隱藏層中的神經(jīng)元通過加權(quán)連接接收來自前一層神經(jīng)元的輸出作為輸入,并產(chǎn)生自己的輸出作為下一層神經(jīng)元的輸入。隱藏層的數(shù)量和每層神經(jīng)元的數(shù)量是MLP設(shè)計中的重要參數(shù),它們決定了網(wǎng)絡(luò)的復(fù)雜度和學(xué)習(xí)能力。
3. 輸出層(Output Layer)
輸出層是MLP的最后一層,負(fù)責(zé)產(chǎn)生最終的預(yù)測結(jié)果。輸出層神經(jīng)元的數(shù)量通常與任務(wù)的目標(biāo)數(shù)量相對應(yīng)。例如,在二分類任務(wù)中,輸出層可能包含一個神經(jīng)元,其輸出值表示屬于某個類別的概率;在多分類任務(wù)中,則可能包含與類別數(shù)量相等的神經(jīng)元,每個神經(jīng)元的輸出值表示屬于對應(yīng)類別的概率。輸出層通常使用softmax函數(shù)等激活函數(shù)來將神經(jīng)元的輸出轉(zhuǎn)換為概率分布形式。
二、神經(jīng)元與連接
1. 神經(jīng)元結(jié)構(gòu)
MLP中的每個神經(jīng)元都是一個基本的處理單元,它接收來自前一層神經(jīng)元的加權(quán)輸入,并通過激活函數(shù)產(chǎn)生輸出。神經(jīng)元的結(jié)構(gòu)通常包括線性變換部分和激活函數(shù)部分。線性變換部分通過加權(quán)求和的方式計算輸入信號的加權(quán)和;激活函數(shù)部分則用于引入非線性因素,使得神經(jīng)元能夠處理復(fù)雜的非線性關(guān)系。
2. 連接方式
MLP中的神經(jīng)元之間通過加權(quán)連接相互連接。每個連接都有一個權(quán)重值,用于表示該連接對神經(jīng)元輸出的影響程度。在訓(xùn)練過程中,這些權(quán)重值會根據(jù)反向傳播算法進(jìn)行更新,以最小化預(yù)測輸出與真實輸出之間的誤差。除了權(quán)重連接外,每個神經(jīng)元還有一個偏置項(bias),用于調(diào)整神經(jīng)元的激活閾值。
三、激活函數(shù)
激活函數(shù)是MLP中非常重要的組成部分,它用于引入非線性因素,使得神經(jīng)網(wǎng)絡(luò)能夠處理復(fù)雜的非線性關(guān)系。常見的激活函數(shù)包括sigmoid函數(shù)、tanh函數(shù)和ReLU函數(shù)等。這些函數(shù)具有不同的特性和應(yīng)用場景,可以根據(jù)具體任務(wù)的需求進(jìn)行選擇。
- Sigmoid函數(shù) :將輸入值映射到(0,1)區(qū)間內(nèi),適用于二分類任務(wù)的輸出層。然而,由于其梯度消失的問題,在深度神經(jīng)網(wǎng)絡(luò)中較少使用。
- Tanh函數(shù) :將輸入值映射到(-1,1)區(qū)間內(nèi),具有比sigmoid函數(shù)更好的梯度特性,因此在隱藏層中較為常用。
- ReLU函數(shù) (Rectified Linear Unit):是當(dāng)前深度學(xué)習(xí)中最為常用的激活函數(shù)之一。它對于所有正輸入值都輸出其本身,對于負(fù)輸入值則輸出0。ReLU函數(shù)具有計算簡單、梯度不會消失等優(yōu)點,在深度神經(jīng)網(wǎng)絡(luò)中表現(xiàn)出色。
四、訓(xùn)練過程
MLP的訓(xùn)練過程通常包括前向傳播和反向傳播兩個階段。
- 前向傳播 :在前向傳播階段,輸入數(shù)據(jù)從輸入層經(jīng)過隱藏層逐層傳遞到輸出層,每一層的神經(jīng)元根據(jù)當(dāng)前權(quán)重和偏置計算輸出值。最終,輸出層產(chǎn)生預(yù)測結(jié)果。
- 反向傳播 :在反向傳播階段,根據(jù)預(yù)測結(jié)果與真實結(jié)果之間的誤差,通過反向傳播算法逐層更新權(quán)重和偏置。反向傳播算法基于鏈?zhǔn)椒▌t計算誤差關(guān)于每個權(quán)重和偏置的梯度,并使用優(yōu)化算法(如隨機(jī)梯度下降SGD、Adam等)來更新這些參數(shù)。通過不斷迭代前向傳播和反向傳播過程,MLP能夠逐漸學(xué)習(xí)到輸入數(shù)據(jù)與輸出之間的映射關(guān)系。
五、模型設(shè)計與優(yōu)化
1. 模型設(shè)計
MLP的模型設(shè)計包括確定隱藏層的數(shù)量、每層神經(jīng)元的數(shù)量以及激活函數(shù)等。這些設(shè)計參數(shù)的選擇對模型的性能有重要影響。一般來說,增加隱藏層的數(shù)量和每層神經(jīng)元的數(shù)量可以提高模型的復(fù)雜度和學(xué)習(xí)能力,但也可能導(dǎo)致過擬合和計算量增加的問題。因此,在實際應(yīng)用中需要根據(jù)具體任務(wù)和數(shù)據(jù)集的特點進(jìn)行權(quán)衡和選擇。
2. 模型優(yōu)化
為了提高M(jìn)LP的性能和泛化能力,通常會采用一系列優(yōu)化策略和技術(shù)。以下是一些關(guān)鍵的模型優(yōu)化方法:
3. 正則化
正則化是防止過擬合的有效手段之一。在MLP中,常用的正則化方法包括L1正則化、L2正則化(也稱為權(quán)重衰減)以及Dropout。
- L1正則化和L2正則化 :通過在損失函數(shù)中添加權(quán)重的絕對值(L1)或平方(L2)作為懲罰項,來限制模型的復(fù)雜度。L1正則化有助于產(chǎn)生稀疏權(quán)重矩陣,而L2正則化則傾向于產(chǎn)生較小的權(quán)重值,兩者都能在一定程度上減少過擬合。
- Dropout :在訓(xùn)練過程中,隨機(jī)丟棄(即設(shè)置為0)神經(jīng)網(wǎng)絡(luò)中的一部分神經(jīng)元及其連接。這種方法可以看作是對多個小型網(wǎng)絡(luò)進(jìn)行訓(xùn)練,并取它們的平均結(jié)果,從而有效減少過擬合,提高模型的泛化能力。
4. 學(xué)習(xí)率調(diào)整
學(xué)習(xí)率是優(yōu)化算法中一個重要的超參數(shù),它決定了權(quán)重更新的步長。過大的學(xué)習(xí)率可能導(dǎo)致訓(xùn)練過程不穩(wěn)定,甚至無法收斂;而過小的學(xué)習(xí)率則會使訓(xùn)練過程過于緩慢。因此,在訓(xùn)練過程中動態(tài)調(diào)整學(xué)習(xí)率是非常必要的。常見的學(xué)習(xí)率調(diào)整策略包括學(xué)習(xí)率衰減、學(xué)習(xí)率預(yù)熱(warmup)以及使用自適應(yīng)學(xué)習(xí)率算法(如Adam、RMSprop等)。
5. 批量大小與批標(biāo)準(zhǔn)化
- 批量大小 :批量大小(batch size)是指每次迭代中用于更新權(quán)重的樣本數(shù)量。較大的批量大小可以提高內(nèi)存利用率和并行計算效率,但可能降低模型的泛化能力;較小的批量大小則有助于更快地收斂到更好的局部最優(yōu)解,但訓(xùn)練過程可能更加不穩(wěn)定。選擇合適的批量大小是平衡訓(xùn)練速度和性能的關(guān)鍵。
- 批標(biāo)準(zhǔn)化 :批標(biāo)準(zhǔn)化(Batch Normalization, BN)是一種通過規(guī)范化每一層神經(jīng)元的輸入來加速訓(xùn)練的技術(shù)。它可以減少內(nèi)部協(xié)變量偏移(Internal Covariate Shift)問題,使得模型訓(xùn)練更加穩(wěn)定,同時也有助于提高模型的泛化能力。
6. 初始化策略
權(quán)重的初始值對神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程和最終性能有很大影響。良好的初始化策略可以幫助模型更快地收斂到全局最優(yōu)解。在MLP中,常用的初始化方法包括隨機(jī)初始化(如均勻分布或正態(tài)分布初始化)、Xavier/Glorot初始化和He初始化等。這些方法旨在保持輸入和輸出的方差一致,從而避免梯度消失或爆炸的問題。
7. 早停法
早停法(Early Stopping)是一種簡單而有效的防止過擬合的方法。在訓(xùn)練過程中,除了使用驗證集來評估模型性能外,還可以設(shè)置一個“早停”條件。當(dāng)模型在驗證集上的性能開始下降時(即出現(xiàn)過擬合的跡象),立即停止訓(xùn)練,并返回在驗證集上表現(xiàn)最好的模型參數(shù)。這種方法可以有效地避免在訓(xùn)練集上過擬合,同時保留模型在未知數(shù)據(jù)上的泛化能力。
六、應(yīng)用場景與挑戰(zhàn)
MLP作為一種通用的神經(jīng)網(wǎng)絡(luò)模型,具有廣泛的應(yīng)用場景,包括但不限于分類、回歸、聚類、降維等任務(wù)。然而,隨著深度學(xué)習(xí)技術(shù)的不斷發(fā)展,MLP也面臨著一些挑戰(zhàn)和限制:
- 計算資源消耗大 :尤其是在處理大規(guī)模數(shù)據(jù)集和高維特征時,MLP的訓(xùn)練和推理過程需要消耗大量的計算資源和時間。
- 難以捕捉局部特征 :與卷積神經(jīng)網(wǎng)絡(luò)(CNN)等專門設(shè)計的網(wǎng)絡(luò)結(jié)構(gòu)相比,MLP在處理具有局部結(jié)構(gòu)特征的數(shù)據(jù)(如圖像、音頻等)時可能表現(xiàn)不佳。
- 超參數(shù)調(diào)整復(fù)雜 :MLP的性能很大程度上取決于其結(jié)構(gòu)設(shè)計和超參數(shù)的選擇。然而,這些超參數(shù)的調(diào)整往往依賴于經(jīng)驗和試錯法,缺乏系統(tǒng)性的指導(dǎo)原則。
盡管如此,MLP作為深度學(xué)習(xí)領(lǐng)域的基礎(chǔ)模型之一,其簡單性和靈活性仍然使其在許多實際應(yīng)用中發(fā)揮著重要作用。隨著技術(shù)的不斷進(jìn)步和算法的不斷優(yōu)化,相信MLP的性能和應(yīng)用范圍將會得到進(jìn)一步的提升和拓展。
-
人工神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
1文章
119瀏覽量
14625 -
模型
+關(guān)注
關(guān)注
1文章
3243瀏覽量
48842 -
神經(jīng)元
+關(guān)注
關(guān)注
1文章
363瀏覽量
18452
發(fā)布評論請先 登錄
相關(guān)推薦
基于結(jié)構(gòu)化平均感知機(jī)的分詞器Java實現(xiàn)
分詞工具Hanlp基于感知機(jī)的中文分詞框架
如何使用Keras框架搭建一個小型的神經(jīng)網(wǎng)絡(luò)多層感知器
Watson感知模型分析
Watson感知模型分析
人工智能–多層感知器基礎(chǔ)知識解讀
一個結(jié)合監(jiān)督學(xué)習(xí)的多層感知機(jī)模型
解讀CV架構(gòu)回歸多層感知機(jī);自動生成模型動畫

基于結(jié)構(gòu)感知的雙編碼器解碼器模型
多層感知機(jī)(MLP)的設(shè)計與實現(xiàn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論