 讀寫分離解決什么問題
讀寫分離解決什么問題
讀寫分離是一種數據庫架構設計策略,主要解決數據庫在高并發場景下的讀寫性能瓶頸問題。在這種架構中,數據庫的讀操作和寫操作被分離到不同的服務器上,以提高數據庫的并發處理能力和穩定性。
一、讀寫分離的概念
1.1 讀寫分離的定義
讀寫分離是一種數據庫架構設計策略,通過將數據庫的讀操作和寫操作分離到不同的服務器上,實現數據庫的高并發處理和負載均衡。
1.2 讀寫分離的背景
隨著互聯網業務的快速發展,數據庫面臨著越來越多的并發訪問需求。在高并發場景下,數據庫的讀寫性能瓶頸問題日益凸顯。為了解決這一問題,讀寫分離成為了一種有效的解決方案。
二、讀寫分離的工作原理
2.1 主從復制
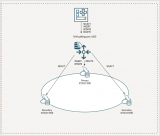
讀寫分離的實現依賴于數據庫的主從復制機制。在主從復制中,一個數據庫實例作為主數據庫(Master),負責處理所有的寫操作;其他數據庫實例作為從數據庫(Slave),負責處理所有的讀操作。
2.2 數據同步
主數據庫在執行寫操作后,會將數據變更同步到從數據庫。這樣,從數據庫可以實時獲取到主數據庫的數據變更,保證數據的一致性。
2.3 負載均衡
讀寫分離通過將讀操作和寫操作分離到不同的服務器上,實現了數據庫的負載均衡。在高并發場景下,讀操作的請求量通常遠大于寫操作,因此將讀操作分配到多個從數據庫上,可以顯著提高數據庫的并發處理能力。
三、讀寫分離的實現方式
3.1 基于中間件的讀寫分離
中間件是一種獨立的軟件組件,用于實現讀寫分離的功能。常見的中間件有MySQL Proxy、Haproxy等。中間件可以根據請求的類型(讀或寫)將請求路由到不同的數據庫實例上。
3.2 基于應用層的讀寫分離
在應用層實現讀寫分離,需要在應用程序中編寫相應的邏輯,根據請求的類型(讀或寫)將請求發送到不同的數據庫實例上。這種方式的優點是可以實現更靈活的讀寫分離策略,但缺點是需要在應用程序中編寫額外的邏輯。
3.3 基于數據庫層的讀寫分離
部分數據庫系統(如MySQL、PostgreSQL等)支持在數據庫層面實現讀寫分離。這種方式的優點是實現簡單,不需要額外的中間件或應用程序邏輯,但可能受到數據庫系統的限制。
四、讀寫分離的優勢
4.1 提高并發處理能力
讀寫分離通過將讀操作和寫操作分離到不同的服務器上,顯著提高了數據庫的并發處理能力。在高并發場景下,讀操作的請求量通常遠大于寫操作,因此將讀操作分配到多個從數據庫上,可以充分利用服務器資源,提高數據庫的并發處理能力。
4.2 負載均衡
讀寫分離實現了數據庫的負載均衡,將讀操作和寫操作分散到不同的服務器上,避免了單點壓力過大的問題。這樣,即使在高并發場景下,數據庫系統也能保持穩定運行。
4.3 降低系統復雜度
讀寫分離簡化了數據庫系統的架構設計,將讀操作和寫操作分離到不同的服務器上,降低了系統的復雜度。這樣,開發人員可以更專注于業務邏輯的實現,提高開發效率。
五、讀寫分離的挑戰
5.1 數據一致性問題
在讀寫分離架構中,數據一致性是一個重要的挑戰。由于主數據庫和從數據庫之間存在數據同步的延遲,可能導致數據不一致的問題。為了解決這一問題,需要采用合適的數據同步策略和一致性保證機制。
5.2 故障切換問題
在讀寫分離架構中,如果主數據庫出現故障,需要將寫操作切換到從數據庫上。這個過程需要保證數據的一致性和系統的可用性。實現故障切換的策略有多種,如自動故障切換、手動故障切換等。
5.3 擴展性問題
隨著業務的發展,數據庫的訪問量可能會持續增長。在讀寫分離架構中,需要考慮如何擴展從數據庫的數量,以滿足不斷增長的讀操作需求。同時,還需要考慮如何平衡主數據庫和從數據庫之間的負載。
六、讀寫分離的最佳實踐
6.1 選擇合適的數據庫系統
在選擇數據庫系統時,需要考慮其對讀寫分離的支持程度。部分數據庫系統(如MySQL、PostgreSQL等)原生支持讀寫分離,可以簡化實現過程。
6.2 采用合適的數據同步策略
為了確保數據一致性,需要選擇合適的數據同步策略。常見的數據同步策略有異步復制、半同步復制和同步復制等。根據業務需求和性能要求,選擇最合適的數據同步策略。
-
服務器
+關注
關注
12文章
9272瀏覽量
85809 -
軟件
+關注
關注
69文章
4995瀏覽量
87881 -
數據庫
+關注
關注
7文章
3842瀏覽量
64565
發布評論請先 登錄
相關推薦
一文解析Redis讀寫分離技術
ddr3的讀寫分離方法有哪些?
通過提高天線增益延長RFID讀寫器操作距離解析
讀寫分離的兩種實現方式
闡述DDR3讀寫分離的方法





 工商網監
工商網監
評論