 BP網絡的基本概念和訓練原理
BP網絡的基本概念和訓練原理
BP網絡 ,全稱為 反向傳播神經網絡(Backpropagation Neural Network) ,是一種基于誤差反向傳播算法(Error Backpropagation Algorithm)的多層前饋神經網絡。BP網絡自1985年提出以來,因其強大的學習和適應能力,在機器學習、數據挖掘、模式識別等領域得到了廣泛應用。以下將對BP網絡的基本概念、訓練原理及其優缺點進行詳細闡述。
一、BP網絡的基本概念
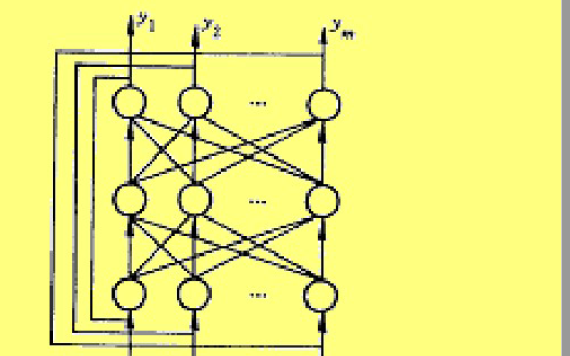
BP網絡是一種前饋式神經元網絡,其核心在于通過誤差反向傳播算法來訓練網絡,使網絡的輸出逐漸接近期望輸出。BP網絡由多個層次組成,主要包括輸入層、隱藏層(可以有多個)和輸出層。每一層都包含多個神經元,這些神經元通過帶有權重的連接相互連接,形成復雜的網絡結構。
- 輸入層 :接收外部輸入信號,不進行任何計算,僅作為數據輸入的接口。
- 隱藏層 :對輸入信號進行非線性變換,是神經網絡的核心部分,負責學習輸入與輸出之間的復雜映射關系。隱藏層可以有一層或多層,層數和神經元數量根據具體問題而定。
- 輸出層 :輸出網絡的處理結果,通常與問題的具體目標(如分類、回歸等)相對應。
BP網絡的特點是各層神經元僅與相鄰層神經元之間相互全連接,同層內神經元之間無連接,各層神經元之間無反饋連接,構成具有層次結構的前饋型神經網絡系統。
二、BP網絡的訓練原理
BP網絡的訓練過程主要基于誤差反向傳播算法,通過不斷調整網絡的權值和閾值,使得網絡的輸出誤差逐漸減小,從而實現對復雜問題的學習和解決。訓練過程主要分為兩個階段:前向傳播和反向傳播。
1. 前向傳播
前向傳播是信號在網絡中從輸入層向輸出層傳播的過程。具體來說,輸入層的信號經過加權和運算后傳遞給隱藏層,隱藏層的神經元接收來自前一層的信號,經過激活函數處理后再傳遞給下一層,直到最終到達輸出層。每一層的輸出都是下一層輸入的來源。前向傳播的計算公式如下:
[
y_i = fleft(sum_{j=1}^{n} w_{ij} x_j + b_iright)
]
其中,(y_i) 表示當前神經元的輸出,(f(cdot)) 為激活函數(如Sigmoid函數、ReLU函數等),(w_{ij}) 為從神經元(j)到神經元(i)的連接權重,(x_j) 為前一層的輸入(或神經元(j)的輸出),(b_i) 為神經元(i)的偏置項。
2. 反向傳播
反向傳播是誤差從輸出層向輸入層反向傳播的過程,用于調整網絡中的連接權重和偏置項,以減小網絡輸出與期望輸出之間的誤差。反向傳播算法的核心是鏈式法則,通過計算誤差關于各層權重的梯度,即誤差信號在各層之間的反向傳播,來更新權重和偏置項。
反向傳播的具體步驟如下:
- 計算誤差 :首先,計算網絡輸出與期望輸出之間的誤差,常用的誤差函數為均方誤差(Mean Squared Error, MSE):
[
E = frac{1}{2} sum_{k=1}{l} (d_k - o_k)2
]
其中,(d_k) 為期望輸出,(o_k) 為實際輸出,(l) 為輸出層神經元的數量。 - 誤差反向傳播 :然后,利用鏈式法則計算誤差關于各層權重的梯度。梯度表示了權重變化對誤差減少的影響程度,通過梯度下降法更新權重,使誤差逐步減小。梯度計算公式如下:
[
Delta w_{ij} = -eta frac{partial E}{partial w_{ij}}
]
其中,(eta) 為學習率,決定了權重更新的步長。 - 更新權重和偏置 :最后,根據計算得到的梯度信息,更新每個神經元的權重和偏置:
[
w_{ij} = w_{ij} + Delta w_{ij}
]
[
b_i = b_i + Delta b_i
]
其中,(Delta b_i) 為偏置項的變化量,其計算方法與(Delta w_{ij})類似。
三、BP網絡的優缺點
優點
- 非線性映射能力 :BP神經網絡通過隱藏層的非線性激活函數,能夠學習和逼近復雜的非線性映射關系,解決傳統方法難以處理的問題。
- 自學習和自適應能力 :網絡在訓練過程中能夠自動調整權重和偏置項,以適應不同輸入數據的特性,表現出較強的自學習和自適應能力。這種能力使得BP網絡在面對復雜、多變的數據環境時,能夠不斷優化自身,提高預測的準確性和魯棒性。
- 泛化能力強 :經過充分訓練的BP網絡,不僅能夠準確擬合訓練數據,還能對未見過的數據進行合理的預測和分類,即具有較強的泛化能力。這種能力使得BP網絡在實際應用中具有廣泛的適用性,可以用于解決各種復雜的問題。
- 易于實現并行處理 :BP網絡的結構特點使得其易于實現并行處理。在硬件條件允許的情況下,可以通過并行計算來加速網絡的訓練和推理過程,提高處理效率。
- 容錯性高 :BP神經網絡具有一定的容錯性,即在網絡中的部分神經元或連接受到損壞時,整個網絡仍然能夠保持一定的功能,并繼續進行學習和預測。這種容錯性使得BP網絡在實際應用中更加可靠和穩定。
缺點
- 訓練時間長 :BP網絡的訓練過程需要反復迭代,通過多次前向傳播和反向傳播來調整權重和偏置項,直到誤差滿足一定的條件為止。這個過程可能需要花費大量的時間,尤其是在網絡結構復雜、數據量龐大的情況下。
- 容易陷入局部最優 :由于BP網絡采用梯度下降法來更新權重和偏置項,而梯度下降法容易陷入局部最優解而非全局最優解。這可能導致網絡的性能無法得到充分發揮,影響預測和分類的準確性。
- 對初始權重敏感 :BP網絡的訓練效果在很大程度上取決于初始權重的選擇。如果初始權重選擇不當,可能會導致訓練過程收斂緩慢甚至無法收斂。因此,在實際應用中需要仔細選擇初始權重或采用一些優化策略來避免這個問題。
- 過擬合問題 :當BP網絡的復雜度過高(如隱藏層過多、神經元過多)而訓練數據有限時,網絡容易出現過擬合現象。即網絡對訓練數據過度擬合,而對未見過的數據預測效果不佳。為了解決這個問題,需要采取一些正則化方法(如L1正則化、L2正則化、Dropout等)來限制網絡的復雜度。
- 對激活函數的選擇敏感 :BP網絡的性能還受到激活函數的影響。不同的激活函數具有不同的特性,適用于不同的應用場景。如果選擇的激活函數不合適,可能會導致網絡訓練困難或性能不佳。因此,在實際應用中需要根據具體問題選擇合適的激活函數。
四、BP網絡的應用
BP網絡因其強大的學習和適應能力,在多個領域得到了廣泛應用。以下是一些典型的應用場景:
- 模式識別 :BP網絡可以用于圖像識別、語音識別、手寫體識別等模式識別任務。通過訓練網絡來學習輸入數據的特征表示和類別信息,實現對未知數據的分類和識別。
- 預測與回歸 :BP網絡還可以用于時間序列預測、股票價格預測、房價預測等回歸任務。通過分析歷史數據中的規律和趨勢,網絡可以學習到數據之間的復雜關系,并據此對未來數據進行預測。
- 控制領域 :在控制系統中,BP網絡可以用于實現智能控制策略。通過對系統的輸入輸出數據進行學習,網絡可以掌握系統的動態特性,并輸出控制信號以調整系統的運行狀態。
- 數據挖掘 :在數據挖掘領域,BP網絡可以用于特征提取、聚類分析等任務。通過對大量數據進行分析和學習,網絡可以發現數據中的隱藏模式和規律,為數據挖掘提供有力的支持。
- 自然語言處理 :在自然語言處理領域,BP網絡可以用于文本分類、情感分析、機器翻譯等任務。通過對文本數據進行預處理和特征提取,網絡可以學習到文本之間的語義關系和表達方式,并據此進行文本的分類、翻譯等處理。
五、BP網絡的改進與發展
隨著人工智能技術的不斷發展,BP網絡也在不斷改進和完善。以下是一些常見的改進方法和發展趨勢:
- 優化算法 :為了克服傳統BP算法收斂速度慢、容易陷入局部最優等缺點,研究者們提出了許多優化算法,如動量法、共軛梯度法、牛頓法等。這些算法通過改進權重更新策略或引入新的優化目標來加速訓練過程并提高網絡的性能。
- 深度學習 :深度學習是神經網絡的一個重要分支,它通過構建更深的網絡結構來捕捉數據中的復雜特征。隨著計算能力的提升和大數據的普及,深度學習在多個領域取得了突破性進展。作為深度學習的基礎模型之一,BP網絡也在不斷向更深的層次發展。
- 集成學習 :集成學習是一種通過組合多個學習器來提高整體性能的方法。將BP網絡與其他機器學習算法(如決策樹、支持向量機等)進行集成學習,可以充分利用各自的優勢來提高模型的泛化能力和預測精度。
- 無監督學習與半監督學習 :傳統的BP網絡主要依賴于有監督學習來訓練網絡。然而,在實際應用中往往存在大量無標簽的數據。為了充分利用這些數據中的信息,研究者們提出了無監督學習和半監督學習的BP網絡變體。
無監督學習 :在無監督學習中,BP網絡可以應用于聚類、降維等任務。例如,自編碼器(Autoencoder)就是一種特殊的無監督BP網絡,它通過編碼器將輸入數據壓縮成低維表示(即編碼),再通過解碼器重構原始數據。通過最小化重構誤差,自編碼器能夠學習到數據的內在結構和特征。這種結構可以用于數據降維、異常檢測等任務。
半監督學習 :半監督學習結合了有監督學習和無監督學習的特點,它利用少量的有標簽數據和大量的無標簽數據來訓練模型。在半監督BP網絡中,可以利用無標簽數據來預訓練網絡,以學習數據的通用特征;然后利用有標簽數據對網絡進行微調,以提高分類或回歸的準確性。這種方法可以有效緩解標簽數據不足的問題,提高模型的泛化能力。
- 卷積神經網絡(CNN)與循環神經網絡(RNN)的結合 :雖然BP網絡是這些網絡的基礎,但現代深度學習模型如卷積神經網絡(CNN)和循環神經網絡(RNN)在特定任務上表現出色。CNN特別適用于處理圖像數據,通過卷積和池化操作來提取圖像特征;而RNN則擅長處理序列數據,如文本、時間序列等。將BP網絡的訓練原理與CNN或RNN相結合,可以構建出既能處理復雜數據又能進行有效學習的混合模型。
- 正則化與稀疏性 :為了防止過擬合,研究者們提出了多種正則化方法,如L1正則化、L2正則化、Dropout等。這些方法通過限制網絡的復雜度或增加稀疏性來減少過擬合的風險。在BP網絡中引入這些正則化策略,可以顯著提高模型的泛化能力。
- 硬件加速 :隨著硬件技術的發展,特別是GPU和TPU等專用計算設備的出現,BP網絡的訓練速度得到了顯著提升。這些硬件設備能夠并行處理大量數據,加速網絡的訓練和推理過程。此外,一些定制化硬件如神經形態計算芯片也在不斷發展中,它們有望為BP網絡提供更高效、更節能的計算平臺。
- 可解釋性與透明性 :雖然BP網絡在多個領域取得了顯著成果,但其內部工作機制仍然相對復雜且難以解釋。為了提高模型的可解釋性和透明性,研究者們開始探索各種方法,如特征可視化、注意力機制等。這些方法有助于理解模型是如何做出決策的,從而增強用戶對模型的信任度和接受度。
綜上所述,BP網絡作為一種經典的多層前饋神經網絡,在多個領域展現出了強大的學習和適應能力。隨著技術的不斷進步和研究的深入,BP網絡將繼續得到改進和發展,以應對更加復雜和多變的應用場景。未來,我們可以期待看到更多基于BP網絡的創新應用和解決方案的出現,為人工智能技術的發展貢獻更多的力量。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100772 -
BP網絡
+關注
關注
0文章
27瀏覽量
22027 -
機器學習
+關注
關注
66文章
8418瀏覽量
132646
發布評論請先 登錄
相關推薦
用matlab編程進行BP神經網絡預測時如何確定最合適的,BP模型
人工智能基本概念機器學習算法

深度學習基本概念
BP神經網絡的原理、結構及 訓練方法
循環神經網絡的基本概念
LLM預訓練的基本概念、基本原理和主要優勢
BP神經網絡的基本結構和訓練過程





 工商網監
工商網監
評論