 如何訓練一個有效的eIQ基本分類模型
如何訓練一個有效的eIQ基本分類模型
一、概述
eIQ Neutron神經處理單元(NPU)是一種高度可擴展的加速器核心架構,提供ML加速。與傳統MCU Kinetis、LPC系列相比,MCX N系列首次集成了恩智浦 eIQ Neutron神經處理單元(NPU),用于機器學習(ML)加速。相比單獨的CPU核,eIQ Neutron NPU能夠提供高達42倍的機器學習推理性能,MCX N94x每秒可以執行4.8 G次運算,使其能夠高效地運行在 MCX CPU和eIQ Neutron NPU上。 eIQPortal它是一個直觀的圖形用戶界面(GUI),簡化了ML開發。開發人員可以創建、優化、調試和導出ML模型,以及導入數據集和模型,快速訓練并部署神經網絡模型和ML工作負載。
在本文中,我們將探討如何訓練一個有效的eIQ基本分類模型,并將其成功部署到MCX N947設備上。
硬件環境:
開發板FRDM-MCXN947
顯示屏3.5" TFT LCD(P/N PAR-LCD-S035)
攝像頭OV7670
軟件環境:
eIQ Portal:eIQ MLSoftware Development Environment | NXP Semiconductors
MCUXpressoIDE v11.9.0
Application Code Hub Demo: Label CIFAR10 image
二、基本模型分類訓練及部署
主要內容分為三步:模型訓練、模型轉換和模型部署。
1.數據集準備
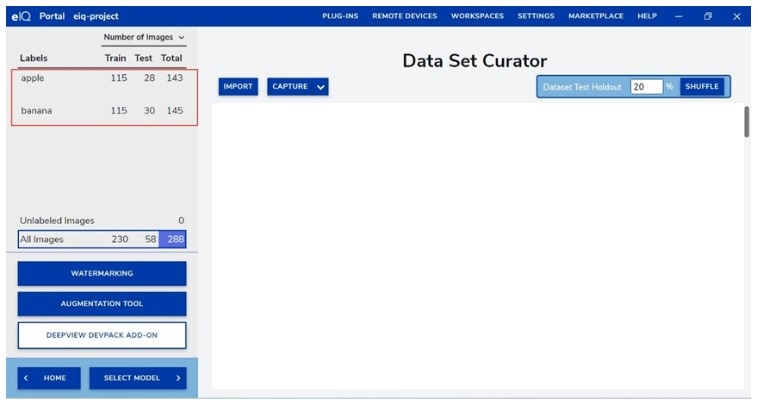
數據集為簡單演示apple、banana兩分類,訓練集、測試集比例為8:2,根據eIQ_Toolkit_UG.pdf提到的3.3.2 Structured folders dataset:

文件夾結構如下:
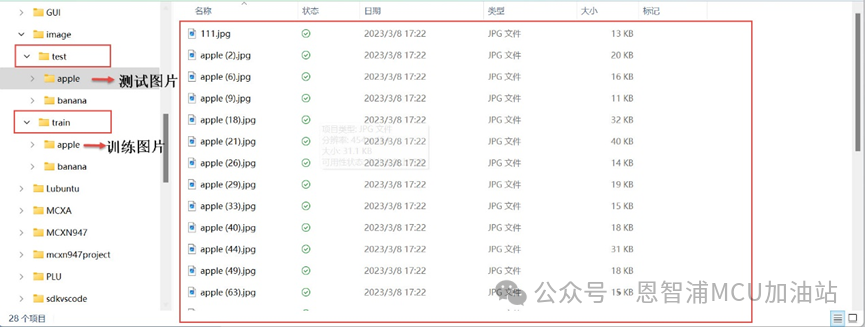
注:數據集需按照以上文件夾格式設置
2. 創建工程及數據集導入eIQ
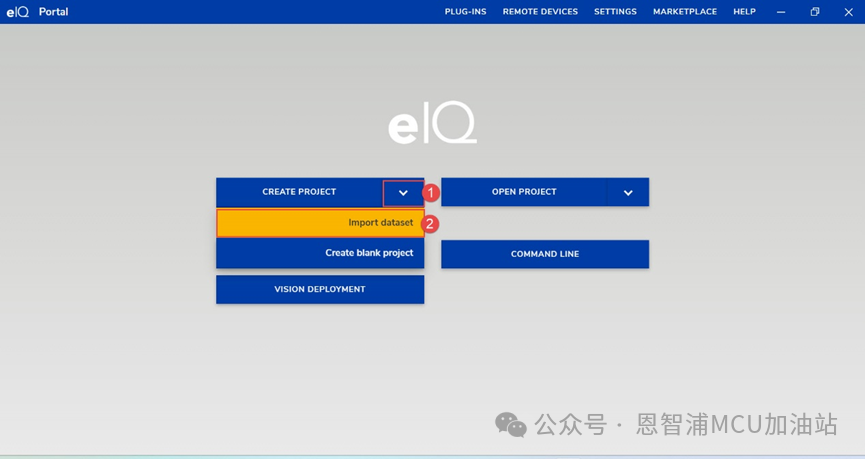
(1) 打開eIQ Portal工具,點擊create project->import dataset:
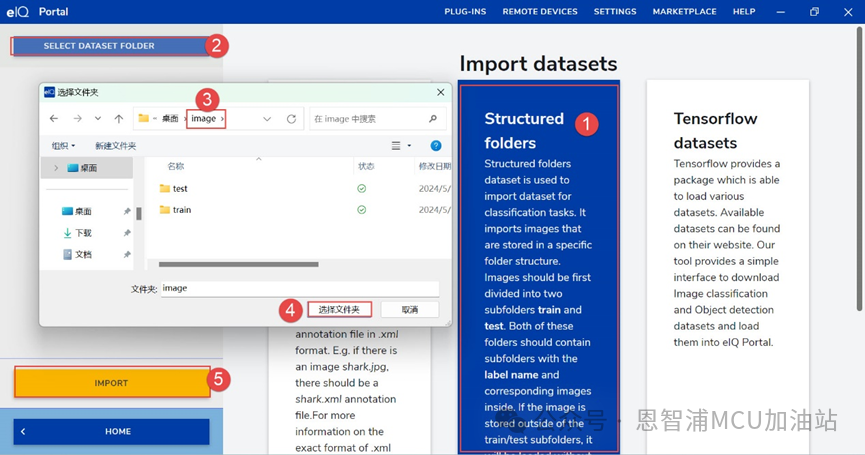
(2) 以StructuredFolders導入:
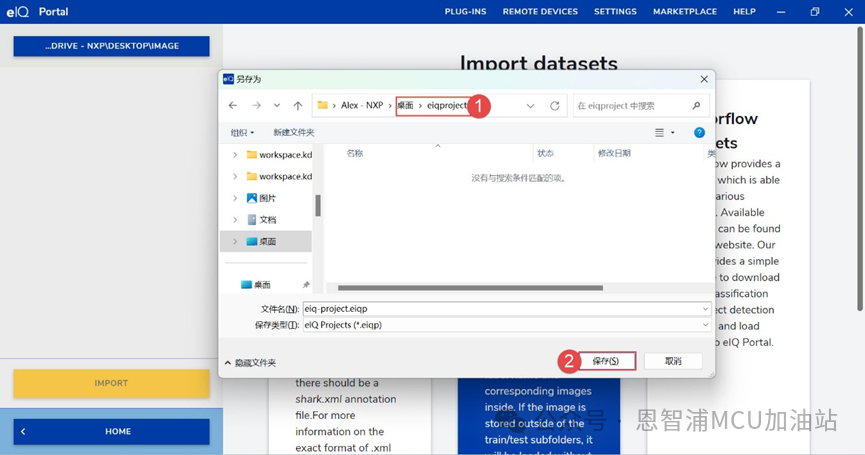
(3) 點擊“IMPORT”后,選擇工程保存路徑,點擊“保存”:
3.選擇base models訓練
(1)數據集導入后,點擊select model,選擇base models,修改input size為128,128,3:
(2)點擊start training。注:其他參數根據需要進行設定即可,此處learning rate、batch size、epoch為默認值,此處為演示,訓練一輪,用戶可以根據需要訓練模型達到應用要求。訓練完成如下:
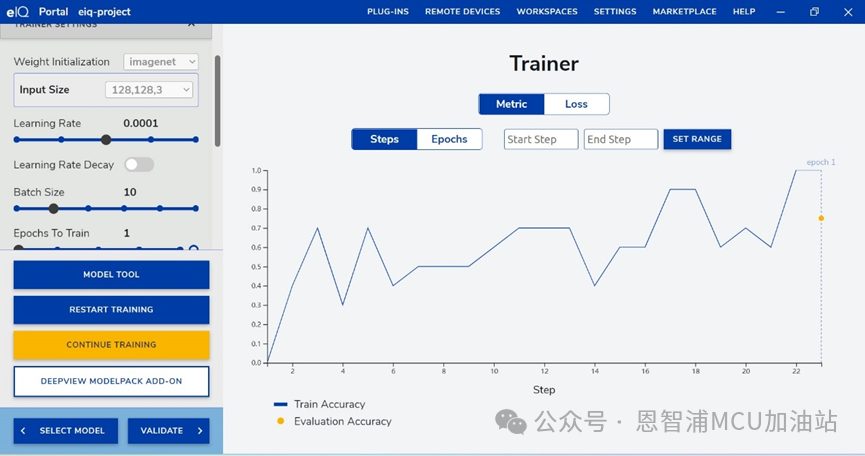
如果精度一直不達標,可以通過修改各訓練參數,或者更新訓練數據,再次點擊CONTINUE TRAINING繼續進行訓練。
4.模型評估VALIDATE
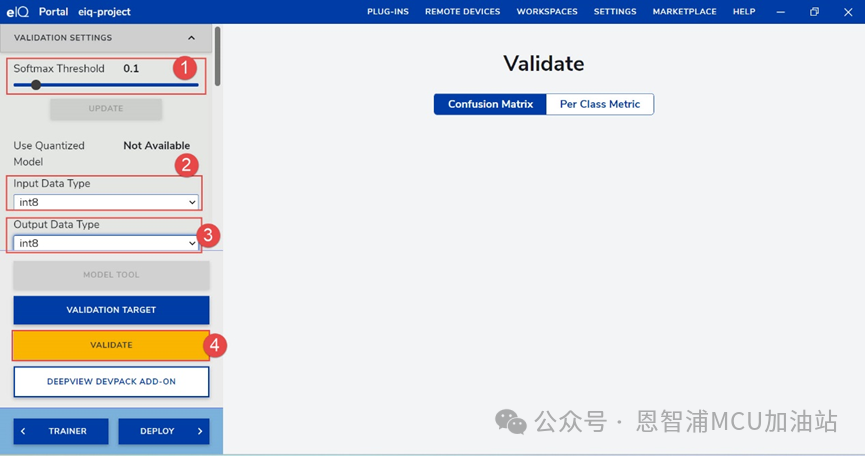
(1) 點擊VALIDATE,進入模型評估,設置參數Softmax,input DataType和output Data Type,目前MCXN系列Neutron NPU只支持int8類型,選擇Softmax函數的閾值是一個需要綜合考慮多種因素的過程,應該根據具體的應用場景和性能目標來決定最合適的閾值,在實際操作中,需要通過多次實驗和調整來找到最佳的閾值:
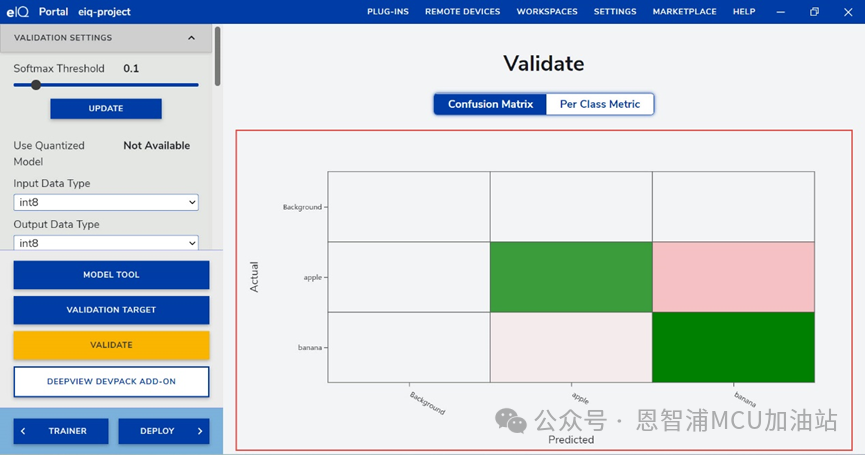
(2).設置完成后,點擊VALIDATE,等待生成混淆矩陣,通過混淆矩陣我們可以清晰看出不同類別的分類情況,圖中x軸是預測的標簽,y軸是實際的標簽,可以看到每一張圖片預測標簽和實際標簽的對應情況:
5.模型導出TensorFlow Lite
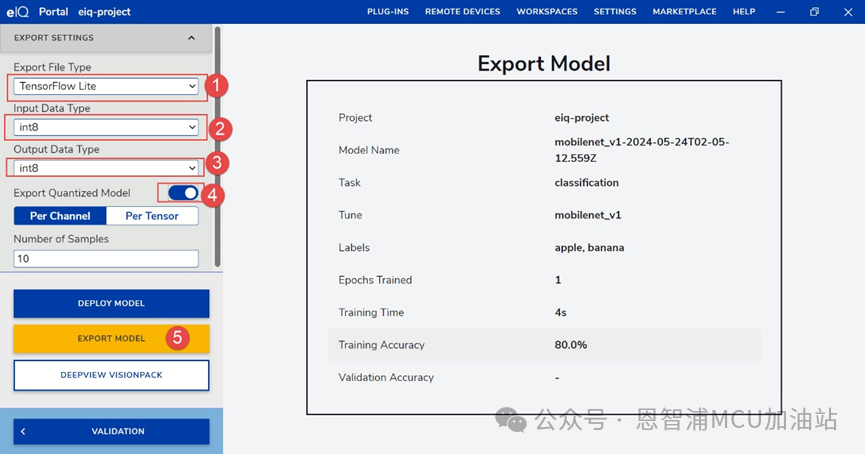
(1) 點擊DEPLOY,設置Export file Type,input Data Type和output Data Type,打開Export Quantized Model,然后點擊Export Model:
(2).設置模型保存位置,點擊保存:
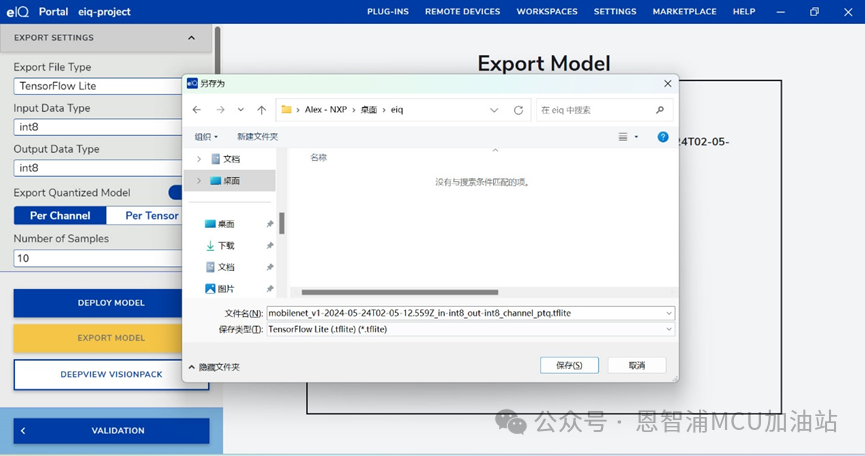
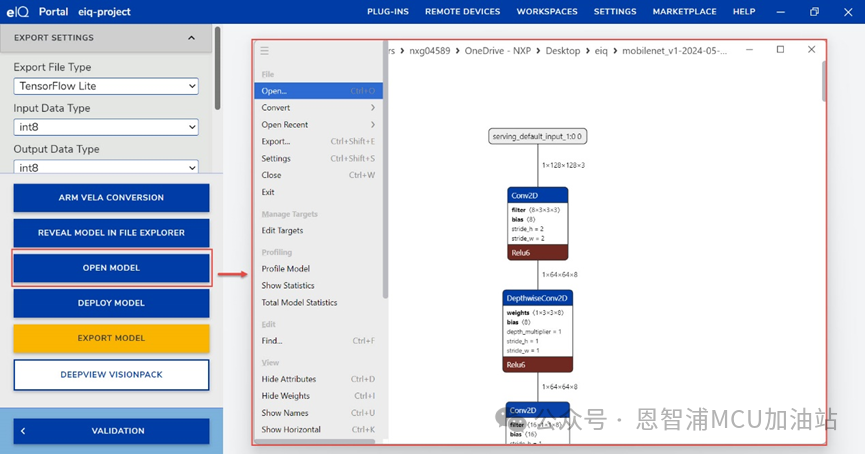
6.轉換TensorFlow Lite for Neutron (.tflite)
(1) 保存完成后,點擊open model,可以查看模型結構:
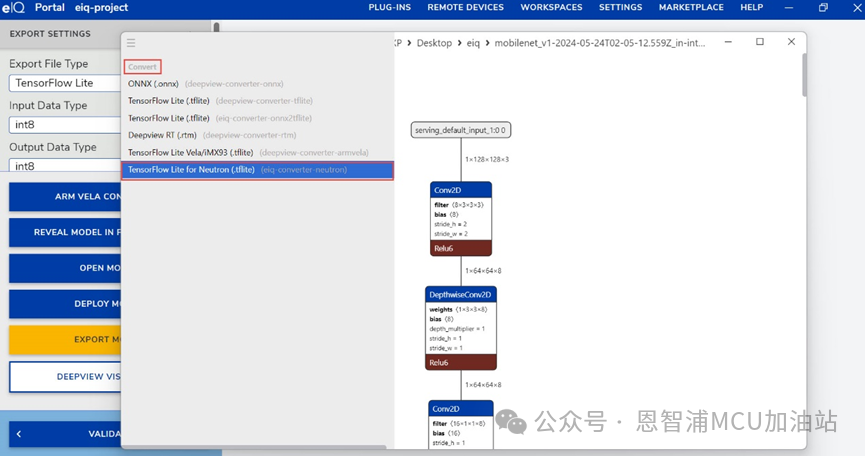
(2) 點擊convert,選擇TensorFlow Lite for Neutron (.tflite):
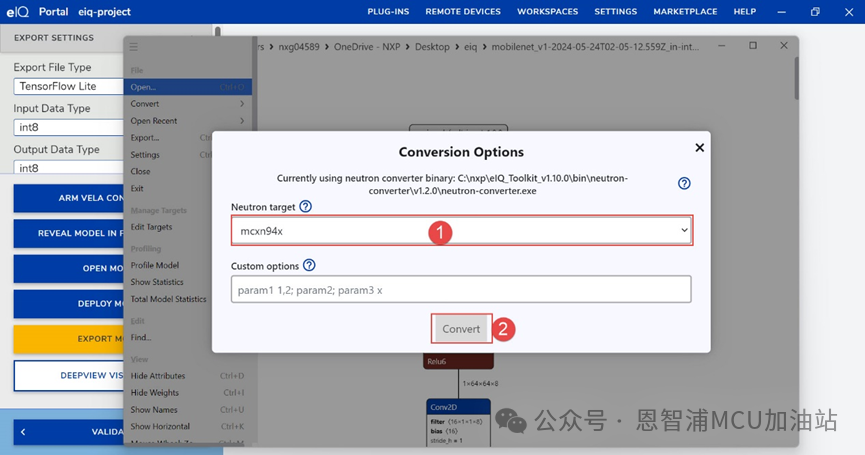
(3) 選擇Neutron Target,點擊convert,設置保存路徑即可:
7.將模型部署到Label CIFAR10 image工程
此示例基于機器學習算法,由 MCXN947 提供支持, 它可以標記來自相機的圖像,并在LCD底部顯示物體的類型。
該模型在數據集CIFAR10上進行訓練,它支持 10 類圖像:
“飛機”、“汽車”、“鳥”、“貓”、“鹿”、“狗”、“青蛙”、“馬”、“船”、“卡車”。
(1) 打開MCUXpresso IDE,從Application Code Hub導入Label CIFAR10 image工程:
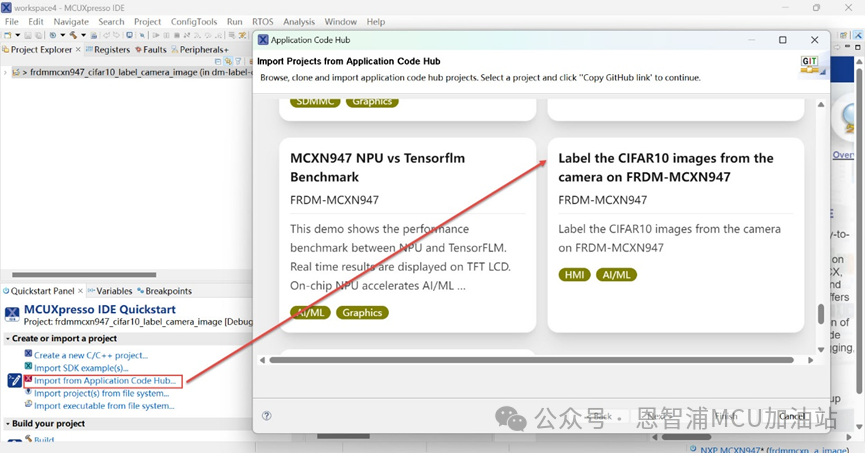
(2) 選擇工程,點擊GitHub Link->Next:
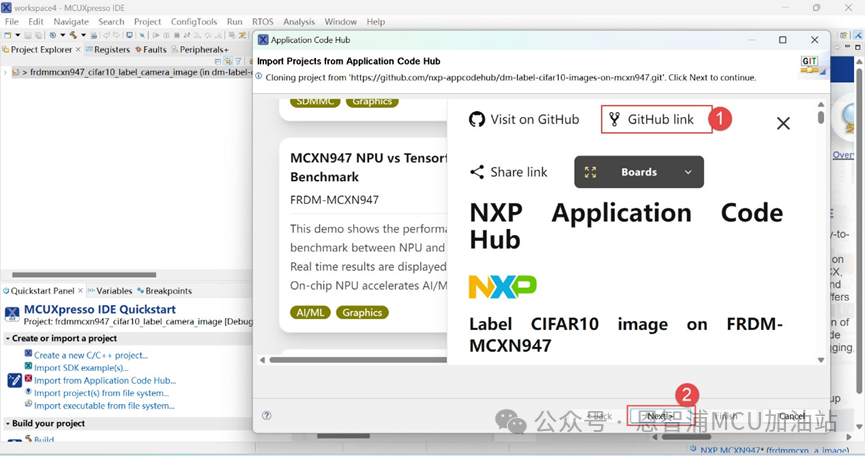
(3).設置保存路徑,Next->Next->Finish:
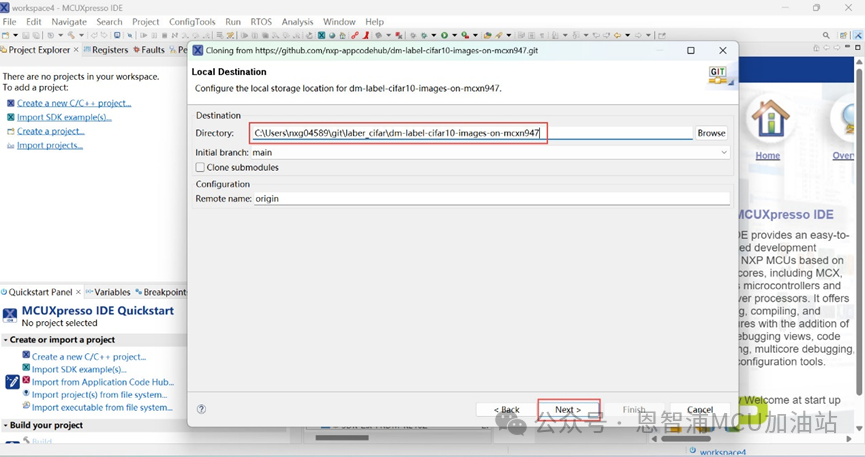
(4).導入成功后,點擊“source”文件夾->model文件夾,打開model_data.s,將最后通過eiq轉換的模型文件復制到model文件下,在model_data.s修改導入模型的名稱(轉換模型的名稱):
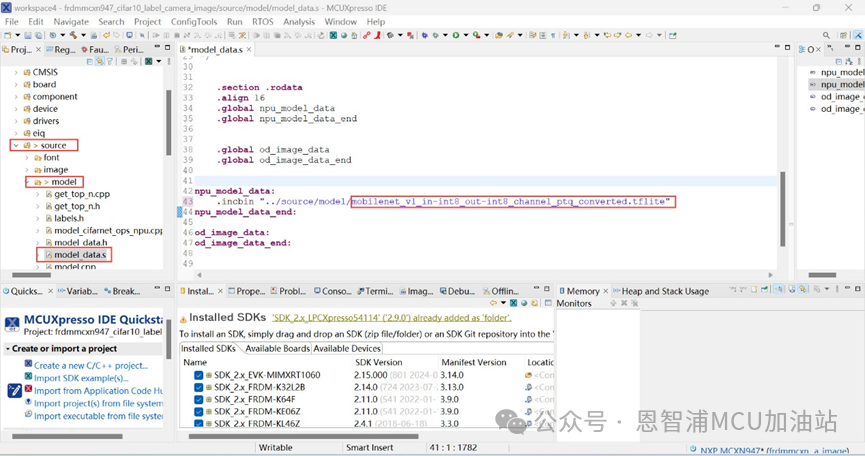
注:工程中導入的模型是經過多次訓練得到的模型
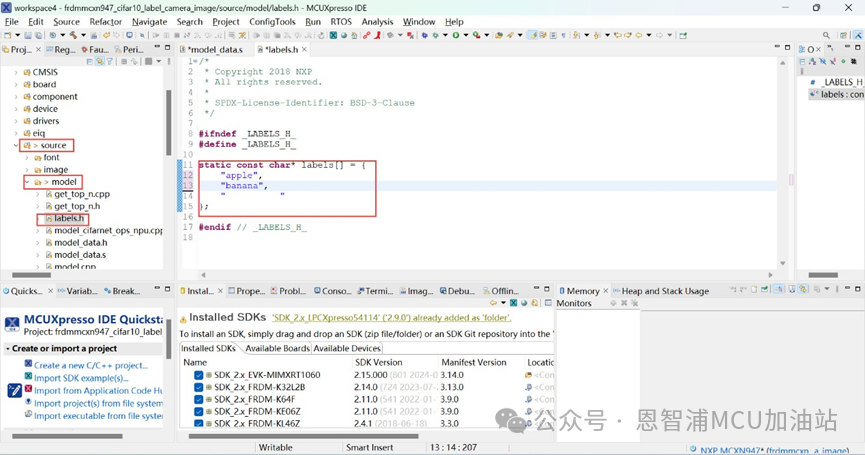
(5) 點擊“source”文件夾->model文件夾->打開labers.h文件,修改labers[ ],標簽順序為eIQ中數據集顯示的順序 :
(6) 編譯工程,下載到開發板。
三、實驗結果

四、總結
對于希望在MCX N系列邊緣設備上實現高效機器學習應用的開發人員來說,掌握這些技術和工具是至關重要的。
通過高效利用eIQ Neutron NPU的強大性能和eIQ Portal的便捷工具,開發人員可以大大簡化從模型訓練到部署的整個過程。這不僅加速了機器學習應用的開發周期,還提升了應用的性能和可靠性。
作者:王浩 楊聰哲
-
處理器
+關注
關注
68文章
19286瀏覽量
229817 -
mcu
+關注
關注
146文章
17148瀏覽量
351186 -
恩智浦
+關注
關注
14文章
5860瀏覽量
107457 -
機器學習
+關注
關注
66文章
8418瀏覽量
132628 -
NPU
+關注
關注
2文章
284瀏覽量
18610
原文標題:MCX N947:eIQ基本分類模型訓練及部署
文章出處:【微信號:NXP_SMART_HARDWARE,微信公眾號:恩智浦MCU加油站】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
EIQ onnx模型轉換為tf-lite失敗怎么解決?
如何使用eIQ門戶訓練人臉檢測模型?
訓練一個機器學習模型,實現了根據基于文本分析預測葡萄酒質量
結合BERT模型的中文文本分類算法
一種基于BERT模型的社交電商文本分類算法

融合文本分類和摘要的多任務學習摘要模型







 工商網監
工商網監
評論