 一文掌握Python多線程
一文掌握Python多線程
目錄
- 1 多線程
- 1.1 簡介
- 1.2 線程模塊
- 1.3 使用 _thread 創建線程
- 1.4 使用 threading 創建線程
- 1.5 線程同步鎖
- 1.6 線程優先級隊列( Queue)
- 1.7 ThreadLocal
- 1.8 線程池
- 2 多進程與多線程
- 2.1 區別
- 3.2 線程切換
- 3.3 CPU密集型&IO密集型
- 3.4 異步IO
1 多線程
1.1 簡介
多線程類似于同時執行多個不同程序,多線程運行有如下優點:
使用線程可以把占據長時間的程序中的任務放到后臺去處理。
用戶界面可以更加吸引人,比如用戶點擊了一個按鈕去觸發某些事件的處理,可以彈出一個進度條來顯示處理的進度。
程序的運行速度可能加快。
在一些等待的任務實現上如用戶輸入、文件讀寫和網絡收發數據等,線程就比較有用了。在這種情況下我們可以釋放一些珍貴的資源如內存占用等等。
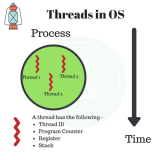
每個獨立的線程有一個程序運行的入口、順序執行序列和程序的出口。但是線程不能夠獨立執行,必須依存在應用程序中,由應用程序提供多個線程執行控制。
每個線程都有他自己的一組CPU寄存器,稱為線程的上下文,該上下文反映了線程上次運行該線程的CPU寄存器的狀態。
指令指針和堆棧指針寄存器是線程上下文中兩個最重要的寄存器,線程總是在進程得到上下文中運行的,這些地址都用于標志擁有線程的進程地址空間中的內存。
線程可以被搶占(中斷)。在其他線程正在運行時,線程可以暫時擱置(也稱為睡眠) -- 這就是線程的退讓。
線程可以分為:
內核線程:由操作系統內核創建和撤銷。
用戶線程:不需要內核支持而在用戶程序中實現的線程。
Python3 線程中常用的兩個模塊為:_thread和threading(推薦使用)
thread模塊已被廢棄。用戶可以使用threading模塊代替。所以,在 Python3 中不能再使用thread模塊。為了兼容性,Python3 將thread重命名為_thread。
1.2 線程模塊
Python3 通過兩個標準庫_thread和threading提供對線程的支持。
_thread提供了低級別的、原始的線程以及一個簡單的鎖,它相比于threading模塊的功能還是比較有限的。
threading模塊除了包含_thread模塊中的所有方法外,還提供的其他方法:
threading. current_thread(): 返回當前的線程變量。
threading.enumerate(): 返回一個包含正在運行的線程的列表。正在運行指線程啟動后、結束前,不包括啟動前和終止后的線程。
threading.active_count(): 返回正在運行的線程數量,與len(threading.enumerate())有相同的結果。
threading.Thread(target, args=(), kwargs={}, daemon=None):
創建Thread類的實例。
target:線程將要執行的目標函數。
args:目標函數的參數,以元組形式傳遞。
kwargs:目標函數的關鍵字參數,以字典形式傳遞。
daemon:指定線程是否為守護線程。
threading.Thread類提供了以下方法與屬性:
__init__(self, group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None):
self:初始化Thread對象。
group:線程組,暫時未使用,保留為將來的擴展。
target:線程將要執行的目標函數。
name:線程的名稱。
args:目標函數的參數,以元組形式傳遞。
kwargs:目標函數的關鍵字參數,以字典形式傳遞。
daemon:指定線程是否為守護線程。
start(self):啟動線程。將調用線程的run()方法。
run(self):線程在此方法中定義要執行的代碼。
join(self, timeout=None):等待線程終止。默認情況下,join()會一直阻塞,直到被調用線程終止。如果指定了timeout參數,則最多等待timeout秒。
is_alive(self):返回線程是否在運行。如果線程已經啟動且尚未終止,則返回True,否則返回False。
getName(self):返回線程的名稱。
setName(self, name):設置線程的名稱。
ident屬性:線程的唯一標識符。
daemon屬性:線程的守護標志,用于指示是否是守護線程。
一個簡單的線程實例:
import threading import time def print_numbers(): for i in range(5): time.sleep(1) print(i) # 創建線程 thread = threading.Thread(target=print_numbers) # 啟動線程 thread.start() # 等待線程結束 thread.join() 輸出結果為: 0 1 2 3 4
1.3 使用 _thread 創建線程
Python中使用線程有兩種方式:函數或者用類來包裝線程對象。
函數式:調用_thread模塊中的start_new_thread()函數來產生新線程。語法如下:_thread.start_new_thread ( function, args[, kwargs] )
參數說明:
function:線程函數。
args:傳遞給線程函數的參數,他必須是個tuple類型。
kwargs:可選參數。
#!/usr/bin/python3
import _thread
import time
# 為線程定義一個函數
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# 創建兩個線程
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: 無法啟動線程")
while 1:
pass
執行以上程序輸出結果如下:
Thread-1: Wed Jan 5 17:38:08 2022
Thread-2: Wed Jan 5 17:38:10 2022
Thread-1: Wed Jan 5 17:38:10 2022
Thread-1: Wed Jan 5 17:38:12 2022
Thread-2: Wed Jan 5 17:38:14 2022
Thread-1: Wed Jan 5 17:38:14 2022
Thread-1: Wed Jan 5 17:38:16 2022
Thread-2: Wed Jan 5 17:38:18 2022
Thread-2: Wed Jan 5 17:38:22 2022
Thread-2: Wed Jan 5 17:38:26 2022
執行以上程后可以按下 ctrl-c 退出。
1.4 使用 threading 創建線程
我們可以通過直接從threading.Thread繼承創建一個新的子類,并實例化后調用 start() 方法啟動新線程,即它調用了線程的 run() 方法:
#!/usr/bin/python3 import threading import time exitFlag = 0 class myThread (threading.Thread): def __init__(self, threadID, name, delay): threading.Thread.__init__(self) self.threadID = threadID self.name = name self.delay = delay def run(self): print ("開始線程:" + self.name) print_time(self.name, self.delay, 5) print ("退出線程:" + self.name) def print_time(threadName, delay, counter): while counter: if exitFlag: threadName.exit() time.sleep(delay) print ("%s: %s" % (threadName, time.ctime(time.time()))) counter -= 1 # 創建新線程 thread1 = myThread(1, "Thread-1", 1) thread2 = myThread(2, "Thread-2", 2) # 開啟新線程 thread1.start() thread2.start() thread1.join() thread2.join() print ("退出主線程") 執行結果如下; 開始線程:Thread-1 開始線程:Thread-2 Thread-1: Wed Jan 5 17:34:54 2022 Thread-2: Wed Jan 5 17:34:55 2022 Thread-1: Wed Jan 5 17:34:55 2022 Thread-1: Wed Jan 5 17:34:56 2022 Thread-2: Wed Jan 5 17:34:57 2022 Thread-1: Wed Jan 5 17:34:57 2022 Thread-1: Wed Jan 5 17:34:58 2022 退出線程:Thread-1 Thread-2: Wed Jan 5 17:34:59 2022 Thread-2: Wed Jan 5 17:35:01 2022 Thread-2: Wed Jan 5 17:35:03 2022 退出線程:Thread-2 退出主線程
1.5 線程同步鎖
如果多個線程共同對某個數據修改,則可能出現不可預料的結果,為了保證數據的正確性,需要對多個線程進行同步。
使用Thread對象的Lock和Rlock可以實現簡單的線程同步,這兩個對象都有acquire方法和release方法,對于那些需要每次只允許一個線程操作的數據,可以將其操作放到acquire和release方法之間。如下:
多線程的優勢在于可以同時運行多個任務(至少感覺起來是這樣)。但是當線程需要共享數據時,可能存在數據不同步的問題。
考慮這樣一種情況:一個列表里所有元素都是 0,線程set從后向前把所有元素改成 1,而線程print負責從前往后讀取列表并打印。
那么,可能線程"set"開始改的時候,線程"print"便來打印列表了,輸出就成了一半0一半1,這就是數據的不同步。為了避免這種情況,引入了鎖的概念。
鎖有兩種狀態——鎖定和未鎖定。每當一個線程比如"set"要訪問共享數據時,必須先獲得鎖定;如果已經有別的線程比如"print"獲得鎖定了,那么就讓線程"set"暫停,也就是同步阻塞;等到線程"print"訪問完畢,釋放鎖以后,再讓線程"set"繼續。
經過這樣的處理,打印列表時要么全部輸出0,要么全部輸出1,不會再出現一半0一半1的尷尬場面。
#!/usr/bin/python3
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, delay):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.delay = delay
def run(self):
print ("開啟線程: " + self.name)
# 獲取鎖,用于線程同步
threadLock.acquire()
print_time(self.name, self.delay, 3)
# 釋放鎖,開啟下一個線程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 創建新線程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 開啟新線程
thread1.start()
thread2.start()
# 添加線程到線程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有線程完成
for t in threads:
t.join()
print ("退出主線程")
輸出結果為:
開啟線程: Thread-1
開啟線程: Thread-2
Thread-1: Wed Jan 5 17:36:50 2022
Thread-1: Wed Jan 5 17:36:51 2022
Thread-1: Wed Jan 5 17:36:52 2022
Thread-2: Wed Jan 5 17:36:54 2022
Thread-2: Wed Jan 5 17:36:56 2022
Thread-2: Wed Jan 5 17:36:58 2022
退出主線程
獲得鎖的線程用完后一定要釋放鎖,否則那些苦苦等待鎖的線程將永遠等待下去,成為死線程。所以盡量用try...finally來確保鎖一定會被釋放
1.6 線程優先級隊列( Queue)
Python 的Queue模塊中提供了同步的、線程安全的隊列類,包括FIFO(先入先出)隊列Queue,LIFO(后入先出)隊列LifoQueue,和優先級隊列 PriorityQueue。
這些隊列都實現了鎖原語,能夠在多線程中直接使用,可以使用隊列來實現線程間的同步。
Queue 模塊中的常用方法:
Queue.qsize():返回隊列的大小
Queue.empty():如果隊列為空,返回True,反之False
Queue.full():如果隊列滿了,返回True,反之False,Queue.full 與 maxsize 大小對應
Queue.get([block[, timeout]]):獲取隊列,timeout等待時間
Queue.get_nowait():相當Queue.get(False)
Queue.put(item):寫入隊列,timeout等待時間
Queue.put_nowait(item):相當Queue.put(item, False)
Queue.task_done():在完成一項工作之后,Queue.task_done()函數向任務已經完成的隊列發送一個信號
Queue.join():實際上意味著等到隊列為空,再執行別的操作
#!/usr/bin/python3
import queue
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print ("開啟線程:" + self.name)
process_data(self.name, self.q)
print ("退出線程:" + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print ("%s processing %s" % (threadName, data))
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
# 創建新線程
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充隊列
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# 等待隊列清空
while not workQueue.empty():
pass
# 通知線程是時候退出
exitFlag = 1
# 等待所有線程完成
for t in threads:
t.join()
print ("退出主線程")
執行結果:
開啟線程:Thread-1
開啟線程:Thread-2
開啟線程:Thread-3
Thread-3 processing One
Thread-1 processing Two
Thread-2 processing Three
Thread-3 processing Four
Thread-1 processing Five
退出線程:Thread-3
退出線程:Thread-2
退出線程:Thread-1
退出主線程
1.7 ThreadLocal
在多線程環境下,每個線程都有自己的數據。一個線程使用自己的局部變量比使用全局變量好,因為局部變量只有線程自己能看見,不會影響其他線程,而全局變量的修改必須加鎖,比較麻煩
因此,ThreadLocal應運而生,不用查找dict,ThreadLocal自動做這件事:
import threading
# 創建全局ThreadLocal對象:
local_school = threading.local()
def process_student():
print ('Hello, %s (in %s)' % (local_school.student, threading.current_thread().name))
def process_thread(name):
# 綁定ThreadLocal的student:
local_school.student = name
process_student()
t1 = threading.Thread(target= process_thread, args=('Alice',), name='Thread-A')
t2 = threading.Thread(target= process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
執行結果:
Hello, Alice (in Thread-A)
Hello, Bob (in Thread-B)
全局變量local_school就是一個ThreadLocal對象,每個Thread對它都可以讀寫student屬性,但互不影響。可以把local_school看成全局變量,但每個屬性如local_school.student都是線程的局部變量,可以任意讀寫而互不干擾,也不用管理鎖的問題,ThreadLocal內部會處理。
可以理解為全局變量local_school是一個dict,不但可以用local_school.student,還可以綁定其他變量,如local_school.teacher等等。
ThreadLocal最常用的地方就是為每個線程綁定一個數據庫連接,HTTP請求,用戶身份信息等,這樣一個線程的所有調用到的處理函數都可以非常方便地訪問這些資源。
1.8 線程池
點擊了解 線程池 multiprocessing.dummy.Pool
2 多進程與多線程
2.1 區別
多進程模式最大的優點就是穩定性高,因為一個子進程崩潰了,不會影響主進程和其他子進程。(當然主進程掛了所有進程就全掛了,但是Master進程只負責分配任務,掛掉的概率低)著名的Apache最早就是采用多進程模式。
多進程模式的缺點是創建進程的代價大,在Unix/Linux系統下,用fork調用還行,在Windows下創建進程開銷巨大。另外,操作系統能同時運行的進程數也是有限的,在內存和CPU的限制下,如果有幾千個進程同時運行,操作系統連調度都會成問題。
多線程模式通常比多進程快一點,但是也快不到哪去,而且,多線程模式致命的缺點就是任何一個線程掛掉都可能直接造成整個進程崩潰,因為所有線程共享進程的內存。在Windows上,如果一個線程執行的代碼出了問題,經常可以看到這樣的提示:該程序執行了非法操作,即將關閉,其實往往是某個線程出了問題,但是操作系統會強制結束整個進程。
在Windows下,多線程的效率比多進程要高,所以微軟的IIS服務器默認采用多線程模式。由于多線程存在穩定性的問題,IIS的穩定性就不如Apache。為了緩解這個問題,IIS和Apache現在又有多進程+多線程的混合模式,真是把問題越搞越復雜。
3.2 線程切換
無論是多進程還是多線程,只要數量一多,效率肯定上不去,為什么呢?
我們打個比方,假設學生正在準備中考,每天晚上需要做語文、數學、英語、物理、化學這5科的作業,每項作業耗時1小時。
如果先花1小時做語文作業,做完了,再花1小時做數學作業,這樣,依次全部做完,一共花5小時,這種方式稱為單任務模型,或者批處理任務模型。
假設打算切換到多任務模型,可以先做1分鐘語文,再切換到數學作業,做1分鐘,再切換到英語,以此類推,只要切換速度足夠快,這種方式就和單核CPU執行多任務是一樣的了,以幼兒園小朋友的眼光來看,就正在同時寫5科作業。
但是,切換作業是有代價的,比如從語文切到數學,要先收拾桌子上的語文書本、鋼筆(這叫保存現場),然后,打開數學課本、找出圓規直尺(這叫準備新環境),才能開始做數學作業。操作系統在切換進程或者線程時也是一樣的,它需要先保存當前執行的現場環境(CPU寄存器狀態、內存頁等),然后,把新任務的執行環境準備好(恢復上次的寄存器狀態,切換內存頁等),才能開始執行。這個切換過程雖然很快,但是也需要耗費時間。如果有幾千個任務同時進行,操作系統可能就主要忙著切換任務,根本沒有多少時間去執行任務了,這種情況最常見的就是硬盤狂響,點窗口無反應,系統處于假死狀態。
所以,多任務一旦多到一個限度,就會消耗掉系統所有的資源,結果效率急劇下降,所有任務都做不好。
3.3 CPU密集型&IO密集型
是否采用多任務的第二個考慮是任務的類型。我們可以把任務分為CPU密集型和IO密集型
CPU密集型任務的特點是要進行大量的計算,消耗CPU資源,比如計算圓周率、對視頻進行高清解碼等等,全靠CPU的運算能力。
這種計算密集型任務雖然也可以用多任務完成,但是任務越多,花在任務切換的時間就越多,CPU執行任務的效率就越低,所以,要最高效地利用CPU,CPU密集型任務同時進行的數量應當等于CPU的核心數。
CPU密集型任務由于主要消耗CPU資源,因此,代碼運行效率至關重要。Python這樣的腳本語言運行效率很低,完全不適合CPU密集型任務。對于CPU密集型任務,最好用C語言編寫。
IO密集型,涉及到網絡、磁盤IO的任務都是IO密集型任務,這類任務的特點是CPU消耗很少,任務的大部分時間都在等待IO操作完成(因為IO的速度遠遠低于CPU和內存的速度)。對于IO密集型任務,任務越多,CPU效率越高,但也有一個限度。常見的大部分任務都是IO密集型任務,比如Web應用。
IO密集型任務執行期間,99%的時間都花在IO上,花在CPU上的時間很少,因此,用運行速度極快的C語言替換用Python這樣運行速度極低的腳本語言,完全無法提升運行效率。對于IO密集型任務,最合適的語言就是開發效率最高(代碼量最少)的語言,腳本語言是首選,C語言最差。
CPU密集型任務配置盡可能少的線程數量,如配置Ncpu+1個線程的線程池。IO密集型任務則由于需要等待IO操作,線程并不是一直在執行任務,則配置盡可能多的線程,如2*Ncpu
3.4 異步IO
考慮到CPU和IO之間巨大的速度差異,一個任務在執行的過程中大部分時間都在等待IO操作,單進程單線程模型會導致別的任務無法并行執行,因此,我們才需要多進程模型或者多線程模型來支持多任務并發執行。
現代操作系統對IO操作已經做了巨大的改進,最大的特點就是支持異步IO。如果充分利用操作系統提供的異步IO支持,就可以用單進程單線程模型來執行多任務,這種全新的模型稱為事件驅動模型,Nginx就是支持異步IO的Web服務器,它在單核CPU上采用單進程模型就可以高效地支持多任務。在多核CPU上,可以運行多個進程(數量與CPU核心數相同),充分利用多核CPU。由于系統總的進程數量十分有限,因此操作系統調度非常高效。用異步IO編程模型來實現多任務是一個主要的趨勢。
對應到Python語言,單進程的異步編程模型稱為協程,有了協程的支持,就可以基于事件驅動編寫高效的多任務程序。
鏈接:https://www.cnblogs.com/jingzh/p/18276352
-
cpu
+關注
關注
68文章
10863瀏覽量
211747 -
多線程
+關注
關注
0文章
278瀏覽量
19954 -
線程
+關注
關注
0文章
504瀏覽量
19682 -
多進程
+關注
關注
0文章
14瀏覽量
2615
原文標題:2 多進程與多線程
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
你要掌握的labview多線程
Python多線程編程運行【python簡單入門】
Python多線程編程原理
淺析Python使用多線程實現串口收發數據
python多線程和多進程對比
python創建多線程的兩種方法
什么是多線程編程?多線程編程基礎知識
C#多線程技術
RT-Thread學習筆記 --(4)RT-Thread多線程學習過程總結

python創建多線程的兩種方法
Python多線程的使用
關于Python多進程和多線程詳解
Python中多線程和多進程的區別





 工商網監
工商網監
評論