 基于RDMA技術的Mayastor解決方案
基于RDMA技術的Mayastor解決方案
1. 方案背景和挑戰
1.1. Mayastor簡介
OpenEBS是一個廣受歡迎的開源云原生存儲解決方案,托管于CNCF(云原生計算基金會)之下,旨在通過擴展Kubernetes的能力,為有狀態應用提供靈活的持久性存儲。Mayastor是OpenEBS項目中的關鍵存儲引擎,它以其高性能、耐久性和易于管理的特點,為云原生應用提供了理想的存儲解決方案。Mayastor的特點包括:
基于NVMe-oF:Mayastor利用NVMe-oF協議,這是一種基于網絡的NVMe訪問方法,允許NVMe設備通過以太網或其他網絡結構進行遠程訪問,這有助于提高存儲系統的性能和可擴展性。
支持多種設備類型:雖然Mayastor優化了NVMe-oF的使用,但它并不要求必須使用NVMe設備或云卷,也可以與其他類型的存儲設備配合使用。
與Kubernetes集成:Mayastor作為OpenEBS的一部分,與Kubernetes緊密集成,允許開發人員和運維人員使用Kubernetes的原生工具(如kubectl)來管理和監控存儲資源。
Mayastor適用于需要高性能和耐久性存儲解決方案的云原生應用場景,特別是在邊緣計算、大數據分析、流媒體處理等領域。它可以幫助開發人員構建高可用性和可擴展性的有狀態應用,同時降低存儲系統的復雜性和成本。通過利用NVMe-oF協議和最新一代固態存儲設備的性能能力,Mayastor能夠提供低開銷的存儲抽象,滿足有狀態應用對持久性存儲的需求。
1.2. 問題與挑戰
當前Mayastor只提供了NVMe over TCP技術實現數據存儲服務,不支持NVMe over RDMA技術,這就不能充分挖掘NVMe SSD盤的性能優勢,主要問題和挑戰包括:
1、性能瓶頸:
Mayastor依賴于TCP來實現NVMe SSD的數據傳輸,這意味著它不可避免地繼承了TCP的性能瓶頸。TCP的頭部開銷和擁塞控制機制限制了數據傳輸的有效速率,尤其是在處理大量小數據包時更為明顯。對于需要高速訪問和處理的NVMe SSD來說,這種限制可能顯著影響Mayastor的整體性能。
2、延遲敏感應用的挑戰:
對于那些對延遲要求極高的應用(如高頻交易、實時數據分析等),Mayastor當前的TCP實現可能無法提供足夠的低延遲保證。TCP的延遲增加和抖動問題可能導致這些應用的性能下降,從而影響業務決策的時效性和準確性。
3、資源消耗:
在高并發場景下,Mayastor處理TCP數據包時涉及的頻繁中斷和上下文切換會顯著增加CPU的負載。這不僅會降低系統整體的計算效率,還可能影響Mayastor處理其他存儲請求的能力,導致整體性能下降。
2. 方案介紹
2.1. 整體架構
本方案是基于馭云ycloud-csi架構,將Mayastor整合進來,通過Gateway提供數據通路的RDMA加速,提高IO性能。在Host側通過DPU卸載,可以進一步解放工作節點上的CPU負載,獲取更好的應用性能。整體架構如下所示(標綠和標藍部分是自研組件):

本方案將不同的組件分別部署在不同的node,主要包含:
Master Node上,部署 csi的控制器csi-controller,用于創建volume和NVMe-oF target。
Worker Node上,部署csi-node-host,配合csi-node-dpu,通過volumeattachment發現DPU掛載的NVMe盤,然后執行綁定或者格式化。
DPU上,部署csi-node-dpu和opi-bridge。opi-bridge是卡對opi-api存儲的實現;csi-node-dpu 負責給host側掛盤。
Storage Node上,部署Mayastor和GATEWAY,GATEWAY是對SPDK封裝的一個服務,用于后端Mayastor存儲,對外提供NVMe target訪問。
2.2. 方案描述
本方案主要由ycloud-csi、RDMA Gateway和Mayastor后端存儲三個部分組成,下面將對這三個部分進行介紹。
2.2.1.ycloud-csi
通過ycloud-csi架構可以接入第三方的存儲,讓第三方存儲很方便的使用DPU的能力。其包括ycloud-csi-controller、ycloud-csi-node-host和ycloud-csi-node-dpu,主要職責是為K8s的負載提供不同的存儲能力。
2.2.1.1.Ycloud-csi-controller
Ycloud-csi-controller主要實現以下兩類功能:
針對pvc,調用第三方的controller,創建卷,創建快照和擴容等;
針對pod,提供存儲的兩種連接模式:AIO和NVMe-oF(因為opi目前只支持這兩種)。如果是NVMe-oF,則調用不同的plugin在GATEWAY上創建NVMe-oF target。
2.2.1.2.Ycloud-csi-node
Ycloud-csi-node使用插件系統,對接不同的第三方存儲。 ycloud-csi-node按node角色分為ycloud-csi-node-dpu、ycloud-csi-node-host和ycloud-csi-node-default,不同角色的csi-node功能不同,下面分別加以說明:
Ycoud-csi-node-dpu需要處理host和DPU側的掛盤請求,根據不同的連接模式(AIO或者NVMe-oF),連接遠程存儲。
Ycloud-csi-node-host把DPU側導出的volume掛載到pod中。
Ycloud-csi-node-default 也就是默認的工作模式,工作于smartNic場景。完成掛載volume,導入pod中。
2.2.2.RDMA Gateway
RDMA Gateway是基于SPDK開發的存儲服務,可以部署在io-engine相同的節點上,負責連接本地Mayastor的target,對外提供NVMe oF存儲服務。
2.2.3. Mayastor storage
后端存儲采用Mayastor,管理不同節點上的硬盤存儲。
2.3. 工作流程
2.3.1.存儲卷創建流程
用戶的App運行在POD中。為了能存放持久的數據,需要給POD掛載存儲卷。在啟動POD之前,可以先創建好PVC,以供后面使用。創建PVC的過程如下:
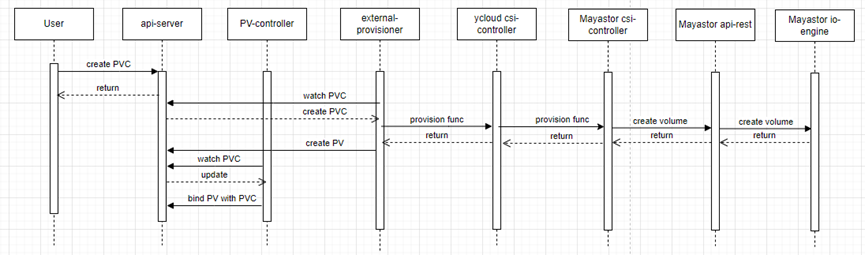
圖中除了包含上一章節介紹的組件外,還有兩個k8s系統提供的用于方便對接csi的組件:
external-provisioner:用戶創建pvc時,該sidecar 會調用csi-controller的CreateVolume創建存儲并創建pv與之前的pvc綁定。
Pv-controller:當底層存儲準備好存儲空間后,該sidecar會更新PVC的狀態為bound。
2.3.2.存儲卷掛載流程
在POD的描述yaml文件里,會指定使用的存儲卷PVC。創建POD后,K8s的調度器會選擇一個合適的節點來啟動POD,然后attacher會把PVC連接到指定節點上,csi-node會把存儲卷掛載到POD中。
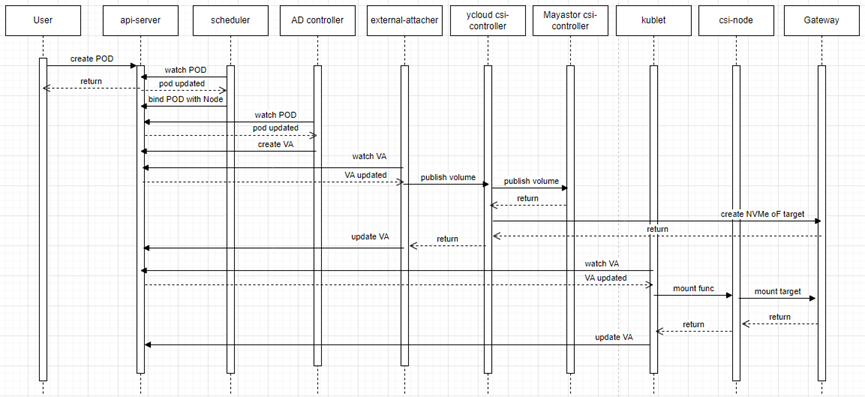
圖中包含兩個k8s系統提供的用于對接csi的組件:
external-attacher:會 watch VolumeAttachment 對象。根據 .spec.attacher 判斷是不是需要自己處理,如果是則調用ControllerPublishVolume 方法,將.spec.persistentVolumeName 這個 Volume attach 到 .spec.nodeName 這個節點上。
AD controller: 會 watch Pod 對象,利用Pod 的 Volume 列表計算出 該 Node 上的 PV 列表,然后和 node.Status.VolumesAttached 值進行對比,沒有attach 的話就執行 attach 操作。
3. 方案測試結果
3.1. Pod掛盤
通過相應的 yaml 描述文件,可以完成創建PVC,刪除PVC,創建/刪除snapshot,在POD中掛載PVC,并驗證操作成功。經驗證可知,Mayastor原生支持的操作,在添加Gateway之后,仍可以支持。
操作截圖如下:
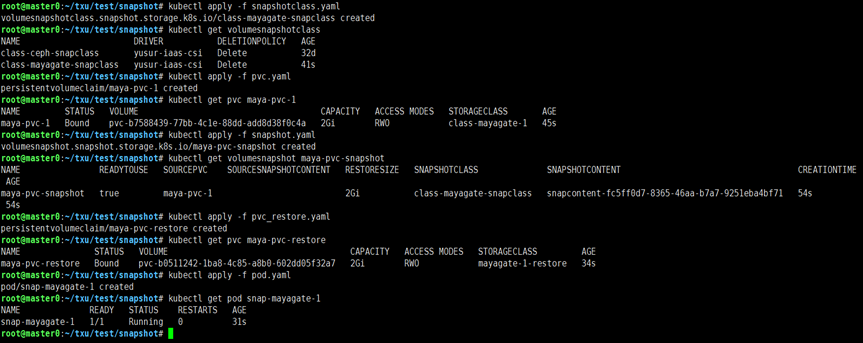
運行kubectl describe pod snap-mayagate-1命令查看pod,結果如下:
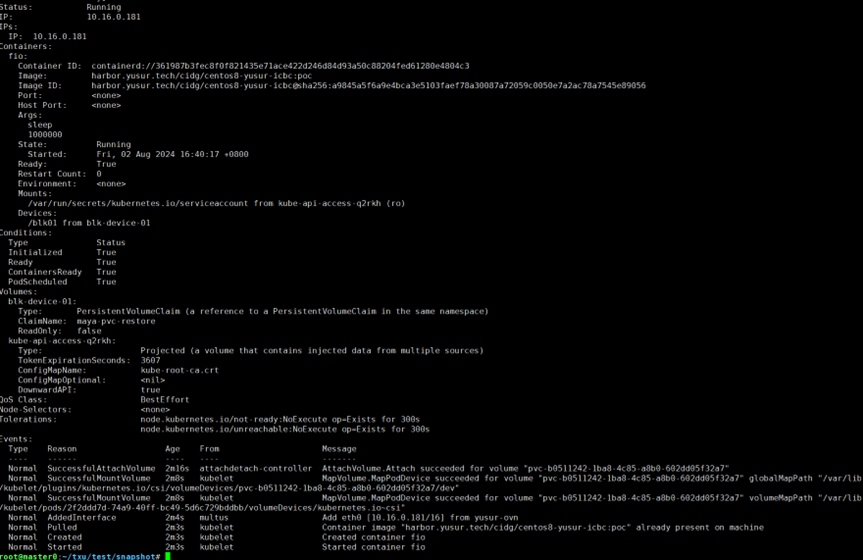
可以連進pod進行簡單的寫操作測試:
3.2. 性能對比
本方案基于單節點Mayastor創建單副本存儲池,在以下測試場景與傳統Mayastor方案進行對比:
io-engine threads:設置io-engine的線程個數為2,4,6,8,分別測試;
Transport:Mayastor采用NVMe over TCP,Gateway采用NVMe over RDMA;
IO方式:隨機讀,隨機寫,順序讀,順序寫,30%寫的混合讀寫;
不同的測試采樣位置:
在Gateway/io-engine本地,目標是使用本地連接提供測試基準數據
在host通過nvme-cli的connect創建盤符來訪問,這是host側采用smartNic的場景
在host通過DPU直通來訪問存儲,是我們主要關注的測試case
考慮多個性能指標:測試的性能指標包括iops,吞吐,延遲和host cpu消耗。
(1) 隨機寫延遲分析
隨機寫延遲的測試結果,如下圖所示:
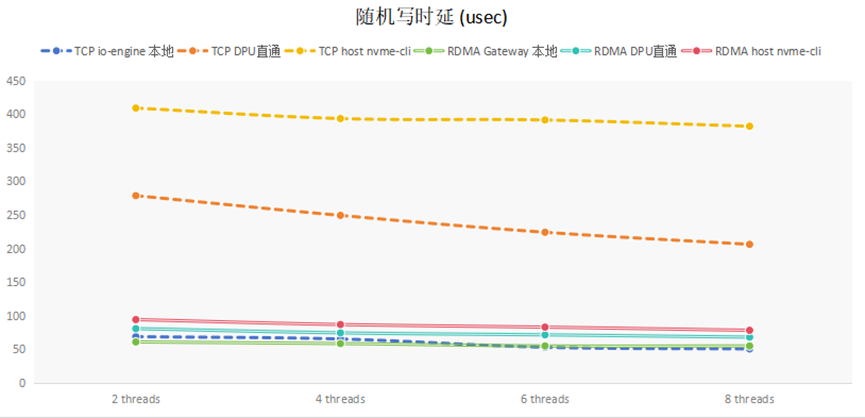
對比TCP和RDMA在不同地方的采樣,可知,io-engine所在節點本地訪問延遲較小,在另外一個節點訪問,TCP延遲增加了一個數量級,而RDMA延遲增加較小。
(2)順序寫帶寬分析
順序寫帶寬的測試結果,如下圖所示:
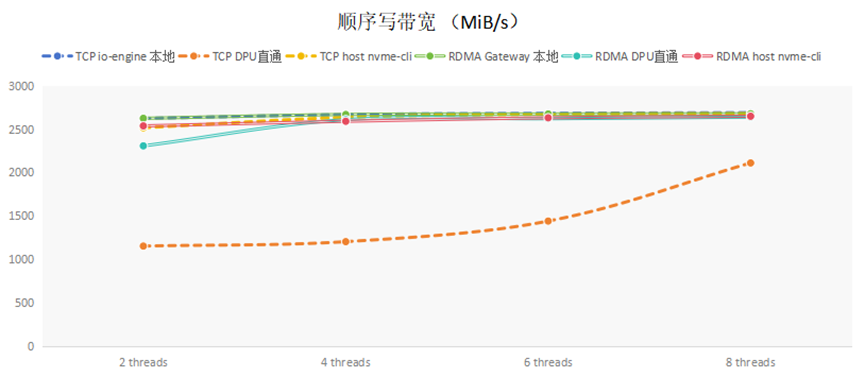
通過在本地直接對于NVMe SSD硬盤測試,發現SSD可支持帶寬大約2680MiB/s左右。從表中可以看到,使用nvme cli連接,無論是TCP還是RDMA,都可以接近后端存儲支持的最大帶寬。單獨看DPU直通的數據,RDMA的性能遠遠超過TCP的性能。這是因為TCP由軟件棧處理,需要消耗大量CPU資源,DPU內僅有4core,CPU資源不足造成的。
(3) 隨機寫IOPS分析
隨機寫IOPS的測試結果,如下圖所示:
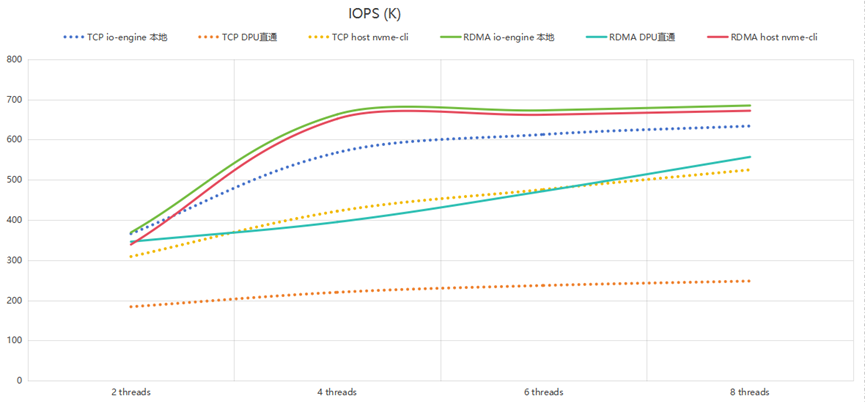
可以看到:
1.RDMA的io-engine本地和host nvme-cli兩個測試位置曲線接近,說明RDMA是完全卸載到硬件處理,性能好;
2. TCP的兩種方式性能有差別,特別是TCP DPU直通方式的上限是200kiops,說明瓶頸是在DPU的CPU上。
另外把Host cli訪問的數據單獨拿出來,用這兩行單獨作圖,如下:
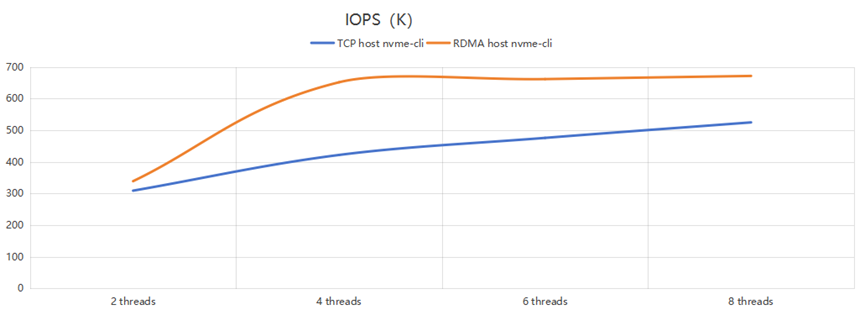
可以看到,當io-engine thread個數為4時,RDMA Gateway已經基本可以壓滿后端存儲;再增加threads個數影響不大。但TCP直連時,性能還是會隨著threads增加而增大。這說明RDMA在相對較低的資源條件下就可以達到較高的性能,其加速效果較好。
(4)隨機讀IOPS分析
隨機讀IOPS的測試結果,如下圖所示:
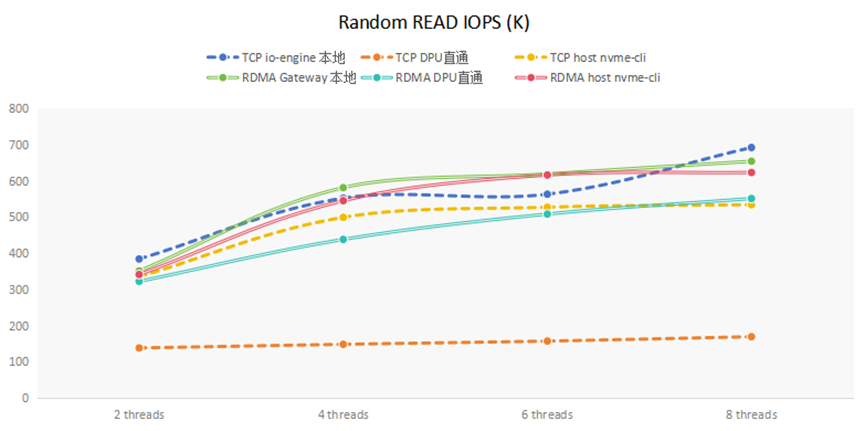
可以看到TCP DPU直通方式隨機讀的上限是150kiops,說明瓶頸是在DPU的CPU上。
另外把Host cli訪問的數據單獨拿出來,用這兩行單獨作圖,如下:
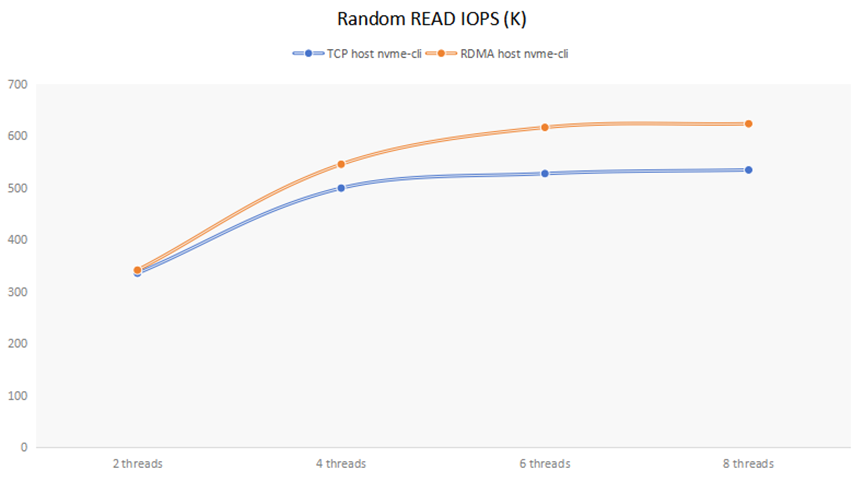
可以看到,當io-engine thread個數為2時,Mayastor TCP方式與RDMA Gateway相差不大,說明瓶頸在于存儲后端;當io-engine thread個數大于等于4時,RDMA Gateway的性能要比TCP方式大約提高20%左右。
對于30%寫的混合讀寫方式,由于讀操作占主體,跟上面讀操作的結果類似,在Host cli情形下,RDMA Gateway的性能要比TCP方式大約提高20%左右。
(5) Host側CPU使用分析
在fio測試過程中,通過腳本記錄Host上top命令的輸出信息,獲取CPU的使用信息。
下圖是用Host cli連接時使用CPU的截圖記錄, TCP協議與RDMA協議的對比。(測試中Mayastor io-engine 采用8 core。)
測試命令是:
| fio -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -size=100G -bs=4k -numjobs=16 -runtime=300 -group_reporting -filename=/dev/filename -name=Rand_Write_Testing |
依次對于三個不同的掛接設備進行測試:/dev/nvme2n1是Host側TCP cli;/dev/nvme3n1是Host側RDMA cli;/dev/nvme0n26是DPU側RDMA直通。
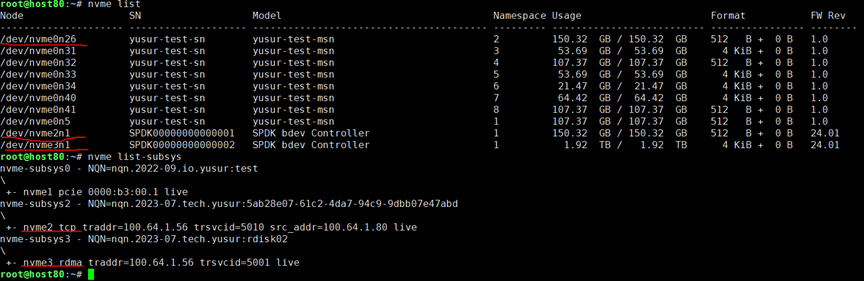
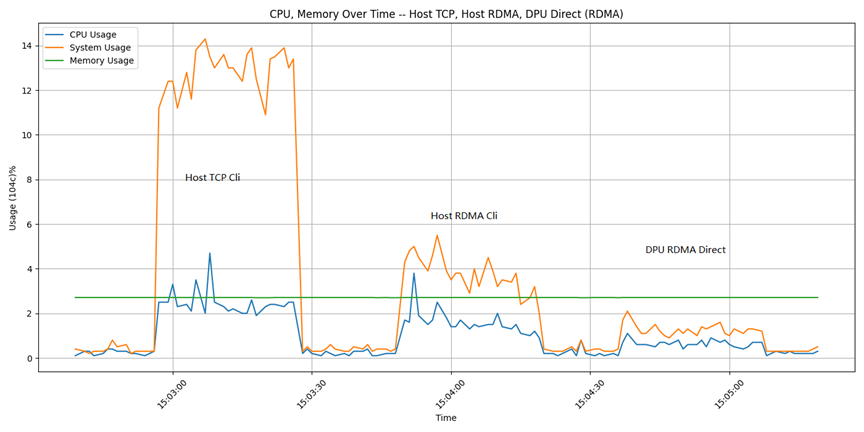
在3個掛載盤上分別做fio測試的IOPS結果分別是:655k,684k,646k。可以看到測試出的性能結果相差不大。上圖是測試過程中通過腳本記錄的CPU使用情況。可以看到,相對于TCP,使用RDMA協議可以節省大量的CPU。
4. 方案優勢總結
1、顯著提升性能:
通過前面測試數據可以看到,在DPU直通連入的場景下,本方案比原生的Mayastor方案隨機寫IOPS性能提升40%左右,隨機讀IOPS性能提升20%左右。在DPU直通的場景下,TCP方式延約200毫秒,RDMA方式約80毫秒,本方案可以減少60%左右的時延。這是因為本方案充分利用了RDMA的超低延遲和高性能特性。RDMA的零拷貝和繞過CPU的傳輸方式極大地減少數據傳輸過程中的延遲和CPU消耗,使Mayastor能夠更高效地處理NVMe SSD的讀寫請求。
2、優化資源利用:
通過前面測試數據可以看到,采用RDMA的方式連接后端存儲,相對于TCP方式可以節省50%左右的Host cpu。本方案通過NVMe over RDMA減少Mayastor對CPU和內存的占用,使系統資源能夠更多地用于其他計算任務,這有助于提升Mayastor的整體穩定性和可靠性,同時降低運營成本。
3、增強可擴展性和靈活性:
RDMA技術還提供了更好的可擴展性和靈活性。隨著數據中心規模的擴大和存儲需求的增長,Mayastor可以通過支持NVMe over RDMA來更輕松地應對這些挑戰。RDMA的遠程直接內存訪問特性使得跨節點的數據傳輸更加高效和可靠,有助于構建更強大的分布式存儲系統。
4、支持更多應用場景:
有了NVMe over RDMA的支持,Mayastor將能夠更好地滿足那些對性能有極高要求的應用場景。無論是高頻交易、實時數據分析還是大規模數據庫事務處理,Mayastor都將能夠提供更加穩定和高效的數據存儲服務。
綜上所述,從Mayastor影響的角度來看,NVMe over RDMA技術相較于TCP在性能、延遲和資源消耗方面均展現出顯著優勢。對于追求極致性能的數據中心和應用場景來說,Mayastor未來能夠支持NVMe over RDMA將是一個重要的里程碑,有助于進一步提升其市場競爭力和用戶體驗。
本方案來自于中科馭數軟件研發團隊,團隊核心由一群在云計算、數據中心架構、高性能計算領域深耕多年的業界資深架構師和技術專家組成,不僅擁有豐富的實戰經驗,還對行業趨勢具備敏銳的洞察力,該團隊致力于探索、設計、開發、推廣可落地的高性能云計算解決方案,幫助最終客戶加速數字化轉型,提升業務效能,同時降低運營成本。
審核編輯 黃宇
-
云計算
+關注
關注
39文章
7800瀏覽量
137401 -
DPU
+關注
關注
0文章
358瀏覽量
24179 -
RDMA
+關注
關注
0文章
77瀏覽量
8949 -
云原生
+關注
關注
0文章
249瀏覽量
7950
發布評論請先 登錄
相關推薦
RDMA RNIC虛擬化方案
利用CXL技術重構基于RDMA的內存解耦合

采用Sun StorEdge技術創建存儲解決方案
技術盛宴 | 淺析RDMA網絡下MMU水線設置
RDMA是什么?RDMA網卡有什么作用?
RDMA技術簡介 RDMA的控制通路和數據通路方案
RDMA技術簡介
RDMA技術簡介
rdma網絡是什么?RDMA網絡有什么應用場景?
以太網RDMA RoCE的技術局限





 工商網監
工商網監
評論