") FP8模型訓(xùn)練中Debug優(yōu)化思路
FP8模型訓(xùn)練中Debug優(yōu)化思路
目前,市場(chǎng)上許多公司都積極開展基于 FP8 的大模型訓(xùn)練,以提高計(jì)算效率和性能。在此,我們整理并總結(jié)了客戶及 NVIDIA 技術(shù)團(tuán)隊(duì)在 FP8 模型訓(xùn)練過程中的 debug 思路和方法,供大家參考。
在討論之前,建議大家使用我們推薦的 FP8 訓(xùn)練的 Recipe,即使用 Delayed scaling,在 History length 為 1024 的窗口中選取最大的 amax 數(shù)值作為計(jì)算 scaling factor 的方法。當(dāng)然,我們也在不斷優(yōu)化這個(gè) Recipe,未來隨著更多 FP8 的實(shí)踐案例,將繼續(xù)為大家總結(jié)和分享,期待共同探索和優(yōu)化 debug 的思路和方案。
在收集和整理了大量 FP8 訓(xùn)練的案例后,我們發(fā)現(xiàn),F(xiàn)P8 訓(xùn)練中遇到的問題一般可以分成以下三類。
第一類問題:Spike Issue
Spike Issue 其實(shí)并不是 FP8 訓(xùn)練所特有的,在 BF16 中也可能會(huì)遇到此類問題,并且實(shí)際上根據(jù) NVIDIA 技術(shù)團(tuán)隊(duì)內(nèi)部訓(xùn)練的一些曲線,可以看到 FP8 的 Spike Issue 要比 BF16 還要小一些。所以,如果遇到了 Spike Issue,很多情況下可以暫時(shí)不用特別關(guān)注 FP8。另外,這里推薦兩篇關(guān)于 Spike 的研究,供大家參考。
關(guān)于 Adam Optimizer 對(duì) Spike 的影響。
關(guān)于使用 SWA 增強(qiáng)訓(xùn)練的穩(wěn)定性,減少 Spike 出現(xiàn)的情況。
整體上,如果我們遇到的 Spike 和曾經(jīng)在 BF16 上遇到的差不多,這種情況很可能不是 FP8 的問題。當(dāng)然,也有例外的情況,比如我們遇到的 Spike 需要很多迭代步才能夠恢復(fù)正常,那這種情況下可以說明這個(gè) loss 和 BF16 有本質(zhì)上的差異, 可以考慮是第二類問題。
第二類問題:
FP8 loss 和 BF16 不匹配或者發(fā)散
在 Validation loss 曲線上,不論是預(yù)訓(xùn)練還是 SFT,如果有 BF16 作為 Baseline,并且可以看到 FP8 和 BF16 有差距,這種情況下應(yīng)該如何處理?
一般這類問題可以分成兩種情況,包括:
情況 1:在訓(xùn)練的初始階段,不論是 Train from scratch 還是 Continue train,如果剛切換到 FP8 進(jìn)行訓(xùn)練,一開始就出現(xiàn)了 loss 比較大或者直接跑飛,這種情況下大概率是軟件問題造成的,因此建議大家使用 NVIDIA 最新的 Transformer Engine 和 Megatron Core 的軟件棧,這樣很多軟件的問題可以及時(shí)被修復(fù),從而讓大家少跑一些彎路。同時(shí)還有另外一種情況,在軟件不斷的更新過程中,為了性能的優(yōu)化會(huì)增加很多新的特性。如果一些特性是剛剛加入的,可能在 FP8 上暫時(shí)還沒有遇到特殊情況,因此建議,大家如果使用了一些很新的特性,屆時(shí)可以先嘗試關(guān)閉掉這些新特性,檢查是否是由于這些新特性的實(shí)現(xiàn)不夠完善造成 loss 的問題。
情況 2:我們已經(jīng)訓(xùn)練了一段時(shí)間,比如已經(jīng)訓(xùn)練了幾百 Billion 的 Tokens,loss 出現(xiàn)了差距,這種情況一般就不是軟件問題了。問題可能是給大家推薦的這個(gè) Recipe 并不適用于某些數(shù)據(jù)集或某些模型結(jié)構(gòu)。這種情況下,可以通過下面的案例去進(jìn)行拆解。
第三類問題:FP8 loss 非常吻合,
但是 Downstream tasks 會(huì)有一些差異
訓(xùn)練中,我們的 Validation loss 曲線吻合的非常好,比如 loss 差距的量級(jí)大概是在十的負(fù)三次方,但是在一些下游任務(wù)上打分的方面可能會(huì)出現(xiàn)問題,那應(yīng)該如何處理?這樣的問題一般分為兩種情況,包括:
情況 1:進(jìn)行下游任務(wù)打分的時(shí)候,會(huì)進(jìn)行多任務(wù)打分。如果所有的任務(wù)和 BF16 baseline 對(duì)比,或者和當(dāng)時(shí)上一代的模型對(duì)比,打分結(jié)果差異很大,這種情況大概率是評(píng)估過程中出現(xiàn)了問題。比如,Checkpoint 導(dǎo)出來的格式不對(duì),或者 Scale 沒有取對(duì)等評(píng)估流程的問題。因此我們還需要進(jìn)行排除,確認(rèn)是否是導(dǎo)出模型和評(píng)估流程出現(xiàn)了問題。
情況 2:另一種情況,如前文提到的“在訓(xùn)練了幾百 Billion 的 Token 之后,loss 出現(xiàn)了差距”,和這種情況很相似,此時(shí)大部分任務(wù)都沒問題,只有個(gè)別的一兩個(gè)任務(wù)發(fā)現(xiàn)跟 BF16 的 Baseline 有明顯差距,如 3% 或者 5% 的掉點(diǎn)。這種情況下,建議改變 FP8 訓(xùn)練的 Recipe,默認(rèn)的 Recipe 是 Delayed scaling,即選用先前迭代步存下來的 scale 值,我們可以替換成 Current scaling,即選用當(dāng)前迭代步的 scale 值,或者把部分的矩陣做一些回退到 BF16 的操作,具體方法下文會(huì)進(jìn)行介紹。
以下是一個(gè)案例,通過這個(gè)案例,可以初步了解哪些方法在現(xiàn)階段可以進(jìn)行嘗試。
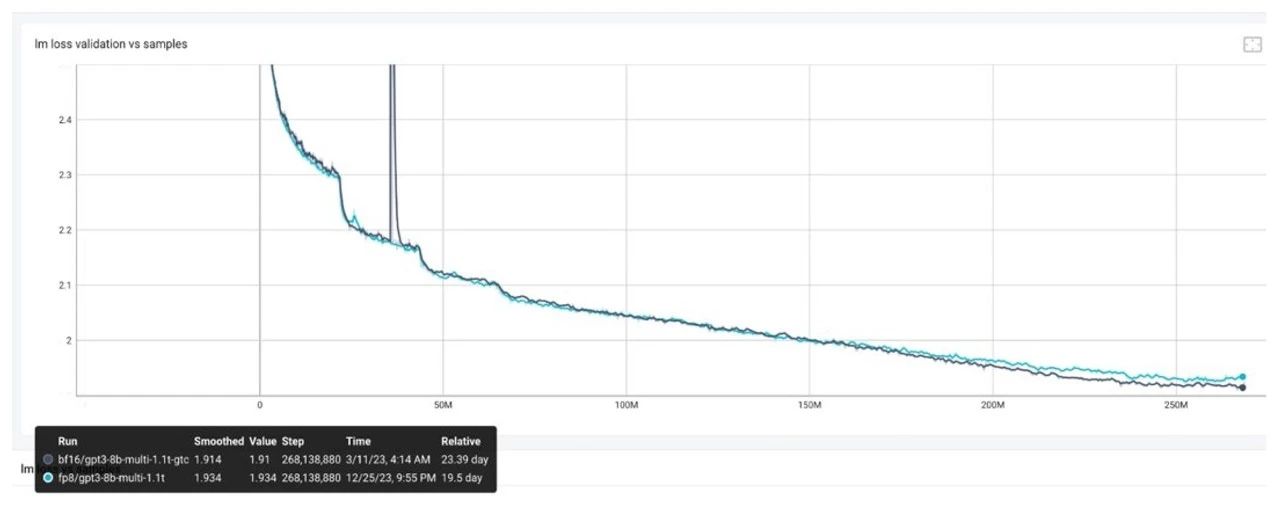
這是一個(gè)類似于 Llama 2 的模型,雖然模型規(guī)模較小,但已經(jīng)訓(xùn)練了 1.1T 個(gè) Tokens,使用了如下推薦的配置,包括:
Pytorch 23.10 版本
TE Commit 為 d76118d
FP8 format:hybird
History Length:1024
Algo:Max
FP8 Wgrad Override:True
我們發(fā)現(xiàn),比較接近 loss 末尾的時(shí)候,差異就會(huì)隨之出現(xiàn),并且顯然已經(jīng)不是十的負(fù)三次方的量級(jí),這種情況下,可以考慮以下的步驟進(jìn)行問題的排查。

第一步:Sequence Parallel off
在軟件前期的時(shí)候,首先盡可能嘗試關(guān)閉一些根據(jù)經(jīng)驗(yàn)判斷可能有問題的特性。比如在引入 FP8 初期,軟件上的 Sequence Paralleism(SP)經(jīng)常會(huì)引起一些問題,因此可以先嘗試進(jìn)行關(guān)閉,如果發(fā)現(xiàn)關(guān)閉后并沒有問題,可以初步判斷 loss 不是由軟件引起的,從而大概率可以推斷是 Recipe 不夠完善造成的。
第二步:我們可以做一個(gè)恢復(fù)性實(shí)驗(yàn)
嘗試看一下當(dāng)前訓(xùn)練出現(xiàn)問題的 FP8 的 Checkpoint,比如最后一個(gè)點(diǎn),把這個(gè) Checkpoint 切換到 BF16 訓(xùn)練,查看是否可以恢復(fù)到 BF16 的 Baseline。我們目前遇到的大多數(shù)情況都是可以恢復(fù)的。因此在這個(gè)基礎(chǔ)的情況下,可以繼續(xù)嘗試下一步 debug 的方法。
第三步:三類矩陣的問題排查
大多數(shù)情況下,整個(gè)模型跑在 FP8 上并不多見。對(duì)于 Transformer layer 的每個(gè) Gemm 來說,整個(gè)訓(xùn)練過程中,有三類矩陣跑在 FP8 上,包括它的前向 Fprop,以及反向 Wgrad 和 Dgrad,因此現(xiàn)在需要判斷三類矩陣的哪個(gè)矩陣出了問題,當(dāng)然,更細(xì)致一些應(yīng)該判斷具體是哪一個(gè) Transformer layer 的矩陣出了問題。不過,這個(gè)特性還在開發(fā)過程中,目前還是一個(gè)比較初步的判斷,需要檢查是前向的矩陣還是反向的兩個(gè)矩陣其中之一出現(xiàn)了差錯(cuò)。因此這一步中,可以首先把這三類矩陣全部轉(zhuǎn)成 BF16 訓(xùn)練。不過,我們做的是一個(gè) Fake quantization,通俗的解釋就是使用 BF16 進(jìn)行訓(xùn)練,但是在做 BF16 計(jì)算之前,會(huì)先把它的輸入 Cast 成 FP8,然后再 Cast back 回到 BF16。這個(gè)時(shí)候,其實(shí)數(shù)據(jù)表示它已經(jīng)是 FP8 表示范圍內(nèi)的值了, 自然這個(gè) scaling 使用的就是 Current scaling,或者說沒有 Scaling。這種情況下,會(huì)發(fā)現(xiàn)把三類矩陣全部都切回 Fake quantization 進(jìn)行訓(xùn)練的時(shí)候,此時(shí)的 loss 曲線是可以貼近 BF16 Baseline 的。因此,下面需要一個(gè)矩陣一個(gè)矩陣的進(jìn)行排除。

三類矩陣包括前向的 Fprop,以及反向的 Wgrad 和 Dgrad。因此我們可以遵循一個(gè)相對(duì)簡單的思路——逐一嘗試,就是每次訓(xùn)練把其中一個(gè)矩陣設(shè)置為 BF16 計(jì)算, 經(jīng)我們嘗試后,可以看到:
在 Fprop 矩陣上面做 BF16 計(jì)算,會(huì)發(fā)現(xiàn)對(duì) loss 的影響并不是很大。
在 Wgrad 矩陣上面做 BF16 計(jì)算,影響也非常小。
在 Dgrad 矩陣上面做 BF16 計(jì)算,即只有 Dgrad 計(jì)算執(zhí)行在 BF16,而 Fprop 和 Wgrad 全部執(zhí)行在 FP8,此時(shí)會(huì)發(fā)現(xiàn) loss 會(huì)回到 BF16 的 Baseline。
現(xiàn)在我們已經(jīng)定位到了有問題的矩陣是 Dgrad,是否還有方法再做進(jìn)一步的挽救從而避免性能損失太多?這種情況下,可以去進(jìn)行以下嘗試。

在 Transformer Engine (TE) 的后續(xù)版本中,計(jì)劃支持用戶使用 Current scaling,即還是使用 FP8 去做 Gemm 的運(yùn)算。但是我們不用前面給大家推薦的這個(gè) Delayed scaling recipe,而是使用當(dāng)前輸入的 scale 值,雖然會(huì)損失一點(diǎn)性能,但是相比于把整個(gè) Gemm 回退到 BF16 做計(jì)算,它的性能損失會(huì)小很多。
當(dāng)對(duì) Dgrad 使用了 Current scaling 之后,會(huì)發(fā)現(xiàn) loss 曲線已經(jīng)和 BF16 的 Baseline 吻合了。
以上就是一個(gè)相對(duì)完整的 debug 的思路,供大家參考和討論。
關(guān)于作者
高慧怡
NVIDIA 深度學(xué)習(xí)解決方案架構(gòu)師,2020 年加入 NVIDIA 解決方案架構(gòu)團(tuán)隊(duì),從事深度學(xué)習(xí)應(yīng)用在異構(gòu)系統(tǒng)的加速工作,目前主要支持國內(nèi) CSP 客戶在大語言模型的訓(xùn)練加速工作。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5047瀏覽量
103326 -
模型
+關(guān)注
關(guān)注
1文章
3277瀏覽量
48957 -
DEBUG
+關(guān)注
關(guān)注
3文章
94瀏覽量
19939
原文標(biāo)題:探索 FP8 訓(xùn)練中 Debug 思路與技巧
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深層神經(jīng)網(wǎng)絡(luò)模型的訓(xùn)練:過擬合優(yōu)化
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】+大模型微調(diào)技術(shù)解讀
Pytorch模型訓(xùn)練實(shí)用PDF教程【中文】
分享一種用于神經(jīng)網(wǎng)絡(luò)處理的新8位浮點(diǎn)交換格式
小米在預(yù)訓(xùn)練模型的探索與優(yōu)化

Multilingual多語言預(yù)訓(xùn)練語言模型的套路
介紹幾篇EMNLP'22的語言模型訓(xùn)練方法優(yōu)化工作
【AI簡報(bào)20231103期】ChatGPT參數(shù)揭秘,中文最強(qiáng)開源大模型來了!

NVIDIA GPU架構(gòu)下的FP8訓(xùn)練與推理

深度學(xué)習(xí)模型訓(xùn)練過程詳解
TensorRT-LLM低精度推理優(yōu)化

FP8數(shù)據(jù)格式在大型模型訓(xùn)練中的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論