 單向鏈表中的存值與存址、數據與p_next分離問題
單向鏈表中的存值與存址、數據與p_next分離問題
周立功教授數年之心血之作《程序設計與數據結構》以及《面向AMetal框架與接口的編程(上)》,書本內容公開后,在電子行業掀起一片學習熱潮。經周立功教授授權,本公眾號特對《程序設計與數據結構》一書內容進行連載,愿共勉之。
第三章為算法與數據結構,本文為3.2 單向鏈表中的3.2.1 存值與存址和3.2.2 數據與p_next分離。
>>> 3.2.1存值與存址
1、存值
在結構體中,雖然不能用“當前結構體類型”作為結構體成員的類型,但可以用“指向當前結構體類型的指針”作為結構體成員的類型。比如:

其中,slist 是single list 的縮寫,表明該結點是單向鏈表結點。由于AMetal平臺規定字母大小寫不能混用,且類型名、變量名、函數名等只能使用小寫字母,宏定義只能使用大寫字母,因此為了與AMetal平臺保持一致,類型名中的字母全部使用小寫。
由于p_next是指針類型而不是結構體,它所指向的是同一種類型的結構體變量。事實上,編譯器在確定結構體的長度之前就已經知道了指針的長度,因此這種類型的自引用是合法的。p_next不僅是struct _slist_node類型中的一員,而且又指向struct _slist_node類型的數據,接著開始為這個結構體創建類型名slist_node_t。即:

AMetal規定使用typedef定義的新類型名必須以“_t”結尾,為了與AMetal保持一致,后續的類型名結尾為“_t”。但一定要警惕下面這樣的聲明陷阱:

在聲明p_next指針時,typedef還沒有結束,slist_node_t還不能使用,所以編譯器報告錯誤信息。當然,也可以在定義結構體前先用typedef,即可在聲明p_next指針時,使用類型定義slist_node_t。比如:

最后也可以結合上述2種方法按照以下形式進行定義:

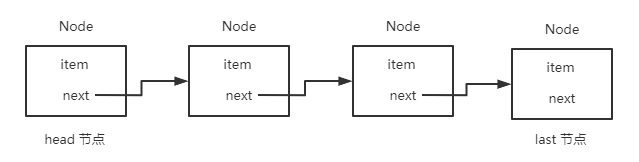
即定義了一個結構體類型,這種方法常用于鏈表(list)、樹(tree)與許多其它的動態數據結構。p_next稱為鏈(link),每個結構將通過p_next鏈接到后面的結構,詳見圖 3.1。其中,data用于存放結點中的數據,該數據是由調用者(應用程序)提供的,p_next用于存放指向鏈表中下一個結點的指針(地址)。其中的箭頭表示鏈,p_next的值是下一個結點的地址,當p_next的值為NULL(0),表示鏈表已經結束。因此可以將鏈表想象為一系列連續的元素,元素與元素之間的鏈接關系只是為了確保所有的元素都可以被訪問。如果錯誤地丟失了一個鏈接,則從這個位置開始往后的所有元素都無法訪問。

圖 3.1 鏈表示意圖
通常需要定義一個指向鏈表頭結點的指針p_head,便于從鏈表的頭結點開始,順序地訪問鏈表中所有的結點。比如:
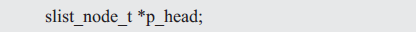
添加頭結點p_head后,完整的鏈表示意圖詳見圖3.2。

圖3.2 添加指向鏈表頭結點的指針
此時,只要獲取p_head的值,即可依次遍歷(訪問)鏈表的所有結點。比如:

對于操作鏈表的函數,必須進行測試,以確保在操作空鏈表是也是正確的。如果直接使用p_head訪問各個結點,當遍歷結束后,則p_head的值為NULL,它不再指向第一個結點,從而丟失了整個鏈表,因此必須通過一個臨時指針變量訪問鏈表的各個結點。比如:
接下來,考慮將結點添加到鏈表的尾部。在初始狀態下,鏈表是一個不包含任何結點的空表,此時p_head為NULL,那么新增的結點就是頭結點,直接修改p_head的值,使其從NULL變為指向新結點的指針,鏈表的變化詳見圖3.3。
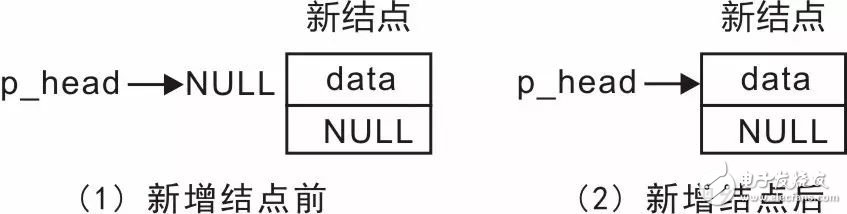
圖3.3 鏈表為空時新增結點
由于新結點添加在鏈表的尾部,因此新結點中p_next的值為NULL,詳見程序清單3.6。
程序清單3.6 新增結點范例程序(鏈表為空)

現在我們來編寫一個簡單的示例,驗證結點是否添加成功,詳見程序清單3.7。
程序清單3.7 添加結點范例程序(1)

如果結點加入成功,則可以通過printf將數據1打印出來。遺憾的是,運行該程序后,什么現象都沒有看到。當鏈表為空時,添加一個結點的核心工作是“修改p_head的值,使其從NULL變為指向新結點的指針”。在調用slist_add_tail()后,p_head被修改了嗎?
當將指針傳遞給函數時,其傳遞的是值。如果想要修改原指針,而不是指針的副本,則需要傳遞指針的指針。p_head是在主程序中定義的,其后僅僅是將NULL值作為實參傳遞給了slist_add_tail()的形參。此后p_head與slist_add_tail()再無任何關聯,因此slist_add_tail()根本不可能修改p_head。要想在調用時修改p_head,則必須將該指針的地址傳遞給slist_add_tail(),詳見程序清單3.8。
程序清單3.8 鏈表為空時新增結點的范例程序

如程序清單3.9所示的測試程序可以驗證添加結點是否成功,首先初始化鏈表為空,接著傳遞p_head的地址,然后從頭結點開始,依次訪問各個結點。
程序清單3.9 添加結點范例程序(2)

當鏈表不為空時,假定已經存在一個值為data1的結點,再添加一個值為data2的結點,鏈表的變化詳見圖3.4。
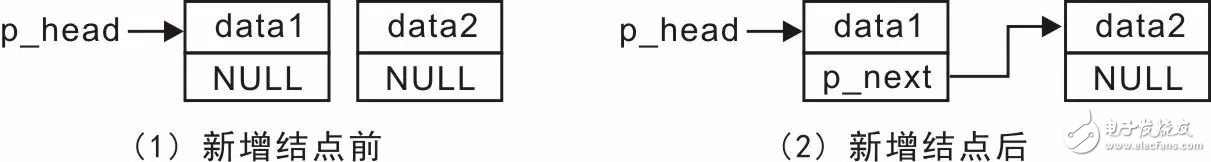
圖3.4 鏈表非空時新增結點
其實現的過程僅需要修改原鏈表尾結點p_next的值,使其從NULL指針變為指向新結點的指針,詳見程序清單3.10。
程序清單3.10 新增結點范例程序

現在可以在程序清單3.9的基礎上,添加更多的結點作為測試程序,詳見程序清單3.11。
程序清單3.11 添加結點范例程序(3)

通過該程序可以驗證結點添加成功,但仔細觀察程序清單3.10可以發現,新增一個結點時,需要判定當前鏈表是否為空,然后再根據實際情況作出相應的處理。產生條件判斷的原因是鏈表可能為空,沒有一個有效結點。如果鏈表初始時就存在一個結點head:

由于這是一個實際的結點,不再是指向頭結點的指針,因此鏈表不可能為空,鏈表示意圖詳見圖 3.5。

圖 3.5 鏈表示意圖
對于這種類型的鏈表,始終存在一個無需有效數據的頭結點,對于空鏈表,其至少包含該頭結點,空鏈表示意圖詳見圖3.6。由于在初始化時不包含其它任何結點,因此p_next的值為NULL。
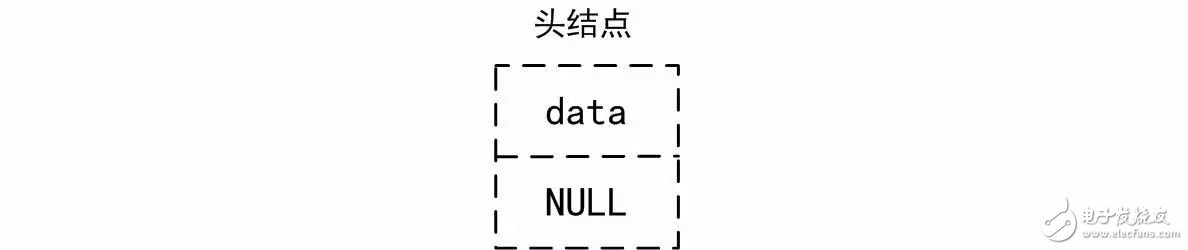
圖3.6 空鏈表示意圖
當需要添加一個新的結點時,則從頭結點開始尋找尾結點。當找到尾結點時,則修改尾結點的p_next值,使其從NULL指針變為指向新結點的指針,詳見程序清單3.12。
程序清單3.12 新增結點范例程序

注意,這里的p_head始終指向存在的頭結點,與程序清單3.6中的p_head意義不同,可以使用如程序清單3.13所示的測試程序對其進行測試,由于初始化時無后繼結點,因此p_next域的值為NULL。
程序清單3.13 添加結點范例程序(4)

雖然如程序清單3.12所示的程序不再使用判斷語句,但又帶來了新的問題,頭結點的data被閑置,僅使用了p_next,則勢必浪費內存。當然,對于當前示例來講data是int類型數據,僅占用4個字節,浪費4個字節或許還能接受,如果data是其它類型呢?
如果鏈表的元素是學生記錄中的數據,由于學生記錄中的數據分別為不同類型的數據,因此結構體是最好的選擇。而作為范例程序無法面面俱到,所以僅以幾個典型的數據為例作為結構體的成員。基于此,專門為學生記錄中的數據定義一個結構體類型與新的結構體類型名。其數據類型定義如下:
即可用此結構體存儲學生記錄中的數據,其成員在內存中的存儲關系詳見圖 3.7。如果將element_type_t聲明與student_t相同的類型,則鏈表數據結構為:

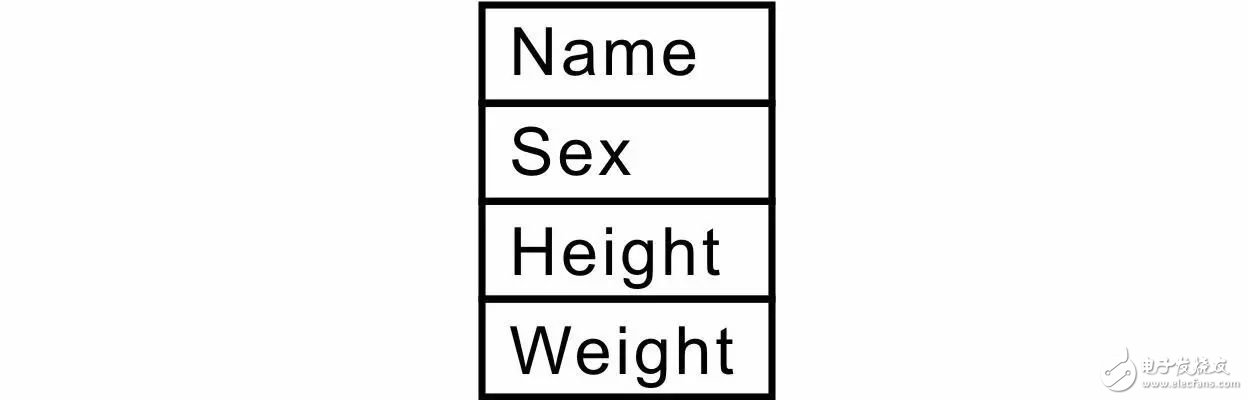
圖 3.7
即與應用程序相關的數據data的類型為另一個結構體類型student_t。
此時只要定義一個slist_node_t類型的變量node,即可引用結構體的成員:

那么該鏈表各成員在內存中的存儲關系就確定下來了,詳見圖 3.8。如果使用表達式

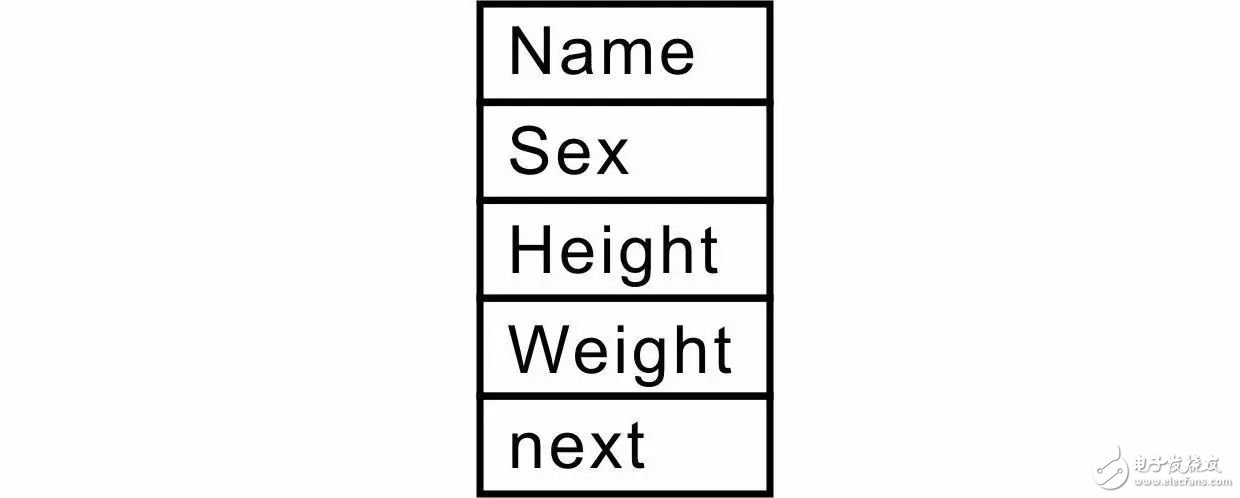
圖 3.8
即可通過node變量引用slist_node_t結構體的成員data。此時,只要將node.data看作一個student_t類型變量,即可使用表達式

引用student_t結構體成員data的成員name(學生記錄中的數據)。
當鏈表中的數據從int類型變為student_t時,浪費的空間將是student_t類型的大小。這里僅僅是一個示例,學生記錄可能包含更多其它的信息,比如,學號、年級、血型、宿舍號等,則頭結點浪費的空間將會更大。
同時,這里也隱含了一個問題,數據類型的改變將導致程序行為的改變,使得該程序無法做到通用,必須在編譯前確定好數據類型,則程序不能以通用庫的形式發布。如果要使代碼通用,就要使用能接受任意數據類型的void *。
2、存址
為了通用還是在鏈表中存放void *類型的元素,即可用鏈表存儲用戶傳入的任意指針類型數據,則鏈表結點的數據結構定義如下:

其中,結點的數據域類型為void *類型指針,data指向用戶數據,結點中的數據是由調用者(應用程序)提供的用戶數據。
雖然void *看起來是一個指針,其本質上則是一個整數,因為在大多數編譯器中指針與int占用的存儲空間大小一樣,所以通用鏈表是一個結點數據域類型為int型的鏈表,只不過結點的數據域中存儲的是與應用程序關聯的用戶數據的地址。
假設存儲在struct _student結構體學生記錄中的數據就是用戶數據,那么只要將存儲學生記錄的結構體變量的地址傳遞給鏈表結點的數據域就行了,即p->data指向用戶數據的結構體存儲空間,詳見圖 3.9。如果void *指針指向的不是結構體或者字符串,而是int型之類的簡單類型,那么只要在使用時進行強制類型轉換即可。

圖 3.9 data指向用戶數據
如果為了使鏈表數據與學生記錄結構體關聯,則必須先定義一個學生記錄,然后將鏈表結點中的void *指針指向該學生記錄。與之前直接將學生結構體作為鏈表結點的數據成員的鏈表相比,每個結點都會多耗費一個void *指針的空間。雖然一個結點耗費的空間并不多,但如果結點很多,其浪費的內存還是相當可觀的,特別是在一些內存資源本身就很緊張的嵌入式系統中。
顯然,要想節省內存空間,則不能定義void *類型指針,必須將數據(比如,學生記錄)和鏈表結點的p_next放在一起,但這樣做則無法做到重用鏈表程序。
分析當前鏈表結點的定義,其主要包含兩個部分:鏈表關心的p_next指針和用戶關心的data數據。回顧如程序清單3.12所示的slist_add_tail()函數,沒有出現任何訪問data的代碼,從而說明data與鏈表無關。既然如此,是否可以將它們分離呢?
>>> 3.2.2 數據與p_next分離
由于鏈表只關心p_next指針,因此完全沒有必要在鏈表結點中定義數據域,那么只保留p_next指針就好了。鏈表結點的數據結構(slist.h)定義如下:

由于結點中沒有任何數據,因此節省了內存空間,其示意圖詳見圖3.10。

圖3.10 鏈表示意圖
當用戶需要使用鏈表管理數據時,僅需關聯數據和鏈表結點,最簡單的方式是將數據和鏈表結點打包在一起。以int類型數據為例,首先將鏈表結點作為它的一個成員,再添加與用戶相關的int類型數據,該結構體定義如下:

由此可見,無論是什么數據,鏈表結點只是用戶數據記錄的一個成員。當調用鏈表接口時,僅需將node的地址作為鏈表接口參數即可。在定義鏈表結點的數據結構時,由于僅刪除了data成員,因此還是可以直接使用原來的slist_add_tail()函數,管理int型數據的范例程序詳見程序清單3.14。
程序清單3.14 管理int型數據的范例程序

由于用戶需要初始化head為NULL,且遍歷時需要操作各個結點的p_next指針。而將數據和p_next分離的目的就是使各自的功能職責分離,鏈表只需要關心p_next的處理,用戶只關心數據的處理。因此,對于用戶來說,鏈表結點的定義就是一個“黑盒子”,只能通過鏈表提供的接口訪問鏈表,不應該訪問鏈表結點的具體成員。
為了完成頭結點的初始賦值,應該提供一個初始化函數,其本質上就是將頭結點中的p_next成員設置為NULL。鏈表初始化函數原型為:

由于頭結點的類型與其它普通結點的類型一樣,因此很容易讓用戶誤以為,這是初始化所有結點的函數。實際上,頭結點與普通結點的含義是不一樣的,由于只要獲取頭結點就可以遍歷整個鏈表,因此頭結點往往是被鏈表的擁有者持有,而普通結點僅僅代表單一的一個結點。為了避免用戶將頭結點和其它結點混淆,需要再定義一個頭結點類型(slist.h):

基于此,將鏈表初始化函數原型(slist.h)修改為:

其中,p_head指向待初始化的鏈表頭結點,slist_init()函數的實現詳見程序清單3.15。
程序清單3.15 鏈表初始化函數

在向鏈表添加結點前,需要初始化頭結點。即:

由于重新定義了頭結點的類型,因此添加結點的函數原型也應該進行相應的修改。即:

其中,p_head指向鏈表頭結點,p_node為新增的結點,slist_add_tail()函數的實現詳見程序清單3.16。
程序清單3.16 新增結點范例程序

同理,當前鏈表的遍歷采用的還是直接訪問結點成員的方式,其核心代碼如下:
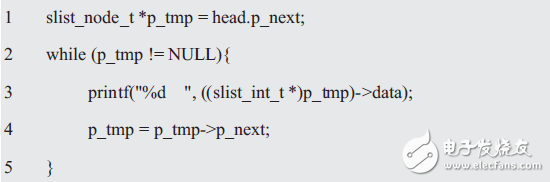
這里主要對鏈表作了三個操作:(1)得到第一個用戶結點;(2)得到當前結點的下一個結點;(3)判斷鏈表是否結束,與結束標記(NULL)比較。
基于此,將分別提供三個對應的接口來實現這些功能,避免用戶直接訪問結點成員。它們的函數原型為(slist.h):

其實現代碼詳見程序清單3.17。
程序清單3.17 遍歷相關函數實現

程序中獲取的第一個用戶結點,其實質上就是頭結點的下一個結點,因此可以直接調用slist_next_get()實現。盡管slist_next_get()在實現時并沒有用到參數p_head,但還是將p_head參數傳進來了,因為實現其它的功能時將會用到p_head參數,比如,判斷p_pos是否在鏈表中。當有了這些接口函數后,即可完成遍歷,詳見程序清單3.18。
程序清單3.18 使用各個接口函數實現遍歷的范例程序

由此可見,slist_begin_get()和slist_end_get()的返回值決定了當前有效結點的范圍,其范圍為一個半開半閉的空間,即:[begin,end),包括begin,但是不包括end。當begin與end相等時,表明當前鏈表為空,沒有一個有效結點。
在程序清單3.18所示的遍歷程序中,只有printf()語句才是用戶實際關心的語句,其它語句都是固定的模式,為此可以封裝一個通用的遍歷函數,便于用戶順序處理與各個鏈表結點相關聯的數據。顯然,只有使用鏈表的用戶才知道數據的具體含義,對數據的實際處理應該交由用戶完成,比如,程序清單3.18中的打印語句,因此訪問數據的行為應該由用戶定義,定義一個回調函數,通過參數傳遞給遍歷函數,每遍歷到一個結點時,都調用該回調函數處理對數據進行處理。遍歷鏈表的函數原型(slist.h)為:

其中,p_head指向鏈表頭結點,pfn_node_process為結點處理回調函數。每遍歷到一個結點時,都會調用pfn_node_process指向的函數,便于用戶根據需要自行處理結點數據。當調用該回調函數時,會自動將用戶參數p_arg作為回調函數的第1個參數,將指向當前遍歷到的結點的指針作為回調函數的第2個參數。
當遍歷到某個結點時,用戶可能希望終止遍歷,此時只要在回調函數中返回負值即可。一般地,若要繼續遍歷,函數執行結束后返回0。slist_foreach()函數的實現詳見程序清單3.19。
程序清單3.19 遍歷鏈表范例程序

現在可以使用這些接口函數,迭代如程序清單3.14所示的功能,詳見程序清單3.20。
程序清單3.20 管理int型數據的范例程序
-
數據結構
+關注
關注
3文章
573瀏覽量
40141 -
程序設計
+關注
關注
3文章
261瀏覽量
30398 -
周立功
+關注
關注
38文章
130瀏覽量
37656 -
鏈表
+關注
關注
0文章
80瀏覽量
10570
原文標題:周立功:輕松掌握單向鏈表中的存值與存址、數據與p_next分離
文章出處:【微信號:ZLG_zhiyuan,微信公眾號:ZLG致遠電子】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA的設計中為什么避免使用鎖存器
C語言單向鏈表
C語言學習筆記一:單向鏈表動態數據結構
請問FPGA用什么存數據?
鎖存器的缺點和優點
數據 采-存-傳系統(FPGA)

Hadoop大數據存算分離方案:計算層無縫對接存儲系統
Apache Doris巨大飛躍:存算分離新架構介紹
LinkedBlockingQueue基于單向鏈表的實現





 工商網監
工商網監
評論