 Banana Pi BPI-F3 進迭時空RISC-V架構下,AI融合算力及其軟件棧實踐
Banana Pi BPI-F3 進迭時空RISC-V架構下,AI融合算力及其軟件棧實踐
面對未來大模型(LLM)、AIGC等智能化浪潮的挑戰,進迭時空在RISC-V方向全面布局,通過精心設計的RISC-V DSA架構以及軟硬一體的優化策略,將全力為未來打造高效且易用的AI算力解決方案。目前,進迭時空已經取得了顯著的進展,成功推出了第一個版本的智算核(帶AI融合算力的智算CPU)以及配套的AI軟件棧。

軟件棧簡介
AI算法部署旨在將抽象描述的多框架算法模型,落地應用至具體的芯片平臺,一般采用CPU、GPU、NPU等相關載體。在目前的邊緣和端側計算生態中,大家普遍認為NPU相較于傳統CPU有極大的成本優勢,并且缺少基于CPU定制AI算力的能力或者授權,導致在實際落地場景中,NPU的使用率很高。但是NPU有其致命的缺點,各家NPU都擁有獨特的軟件棧,其生態相對封閉,缺乏與其他平臺的互操作性,導致資源難以共享和整合。對于用戶而言,NPU內部機制不透明,使得基于NPU的二次開發,如部署私有的創新算子,往往需要牽涉到芯片廠商,IP廠商和軟件棧維護方,研發難度較大。
著眼于這些實際的需求和問題,我們的智算核在設計和生態上采取了開放策略。以通用CPU為基礎,結合少量DSA定制(符合RISC-V IME擴展框架)和大量微架構創新,以通用CPU的包容性最大程度的復用開源生態的成果,在兼容開源生態的前提下,提供TOPS級別的AI算力,加速邊緣AI。這意味著我們可以避免低質量的重復開發,并充分利用開源資源的豐富性和靈活性,以較小的投入快速部署和使用智算核。這種開放性和兼容性不僅降低了部署大量現有AI模型的門檻,還為用戶提供了更多的創新可能性,使得AI解決方案不再是一個專門的領域,而是每個程序員都可以參與和創新的領域。
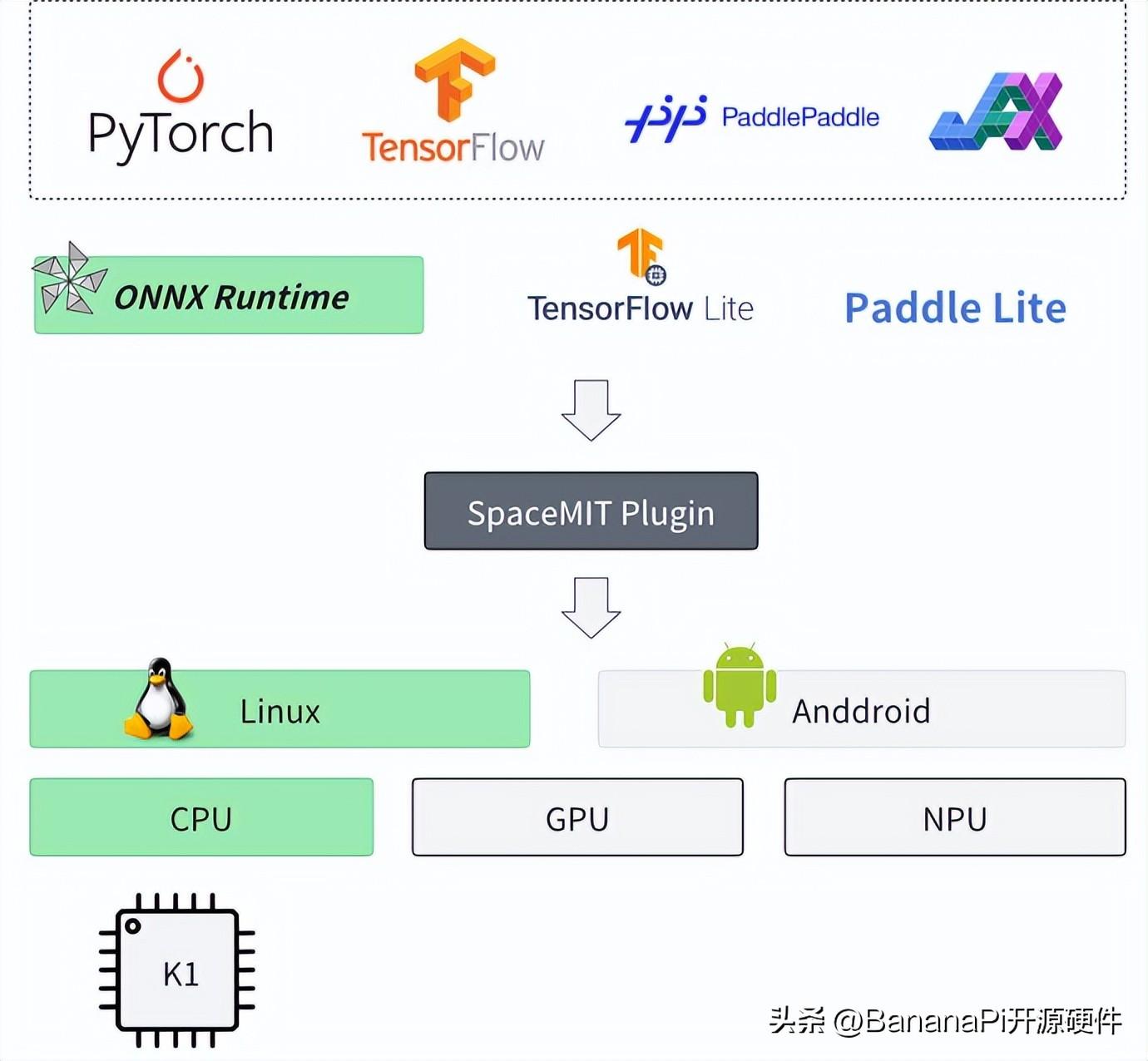
圖一:進迭時空AI軟件棧架構
如上圖所示,基于進迭時空的AI技術路線,我們能輕松的以輕量化插件的方式,無感融入到每一個AI算法部署框架中,目前我們以ONNXRuntime為基礎,結合深度調優的加速后端,就可以成功的將模型高效的部署到我們的芯片上,如上圖所示。對于用戶來說,如果有ONNXRuntime的使用經驗,就可以無縫銜接。
加入進迭時空插件的使用方式如下:
? C/C++
C++
#include
#include "spacemit_ort_env.h"
std::string net_param_path = "your_onnx_model.onnx";
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "ort-demo");
Ort::SessionOptions session_options;
// 可選加載SpaceMIT環境初始化加載專屬EP
Ort::SessionOptionsSpaceMITEnvInit(session_options);
Ort::Session session(env, net_param_path, session_options);
// 加載輸入
// .......
auto output_tensors = session.Run(Ort::RunOptions{nullptr}, input_node_names.data(), &input_tensor, input_count,
output_node_names.data(), output_count);
? python
Python
import onnxruntime as ort
import numpy as np
import spacemit_ort
net_param_path = "resnet18.q.onnx"
session = ort.InferenceSession(net_param_path, providers=["SpaceMITExecutionProvider"])
input_tensor = np.ones((1, 3, 224, 224), dtype=np.float32)
outputs = session.run(None, {"data": input_tensor})
通過開放的軟件棧,使得我們的芯片能夠在短時間內支持大量開源模型的部署,目前已累計驗證了包括圖像分類、圖像分割、目標檢測、語音識別、自然語言理解等多個場景的約150個模型的優化部署,timm、onnx modelzoo、ppl modelzoo等開源模型倉庫的支持通過率接近100%,而且理論上我們能夠支持所有的公開onnx模型。
智算核的軟硬協同優化
在保證通用性和易用性的同時,我們利用智算核的特點,極大的優化了模型推理效率。
離線優化
離線優化包含常見的等價計算圖優化(如常量折疊、算子融合、公共子表達式消除等)、模型量化等,其中模型量化將浮點計算映射為低位定點計算,是其中效果最顯著的優化方式。在智算核融合算力的加持下,算子可編程性很高,相較于NPU固化的量化計算方式,智算核能夠根據模型應用特點,匹配更寬泛的數據分布,實現量化計算的精細化、多樣化,以便于在更小的計算與帶寬負載下,實現更高的推理效率。
運行時優化
區別于NPU系統中,AI算子會根據NPU支持與否,優先調度到NPU上執行,并以host CPU作為備選執行的方式。進迭時空的智算核采用了擴展AI指令的設計,以強大的vector算力和scalar算力作為支撐,確保任意算子都能夠在智算核上得到有效執行,無需擔心算子支持或調度問題。這種設計不僅簡化了用戶的操作流程,還大大提高了模型的執行效率和穩定性。
此外,進迭時空的智算核還支持多核協同工作,進一步提升了AI算力。用戶只需在運行時通過簡單的線程調度,即可靈活調整所使用的AI算力資源。
AI算力指令基礎
智算核的AI算力主要來自擴展的AI指令。我們針對AI應用中算力占比最高的卷積和矩陣乘法,基于RISCV Vector 1.0 基礎指令,新增了專用加速指令。遵從RISCV社區IME group的方式,復用了Vector寄存器資源,以極小的硬件代價,就能給AI應用帶來10倍以上的性能提升。
AI擴展指令按功能分為點積矩陣乘累加指令(后面簡稱矩陣累加指令)和滑窗點積矩陣乘累加指令(后面簡稱滑窗累加指令)兩大類,矩陣累加指令和滑窗累加指令組合,可以轉化成卷積計算指令。
以256位的向量矩陣配合4*8*4的mac單元為例,量化后的8比特輸入數據在向量寄存器中的排布,需要被看成是4行8列的二維矩陣;而量化后的8比特權重數據在寄存器中的排布,會被看成是8行4列的二維矩陣,兩者通過矩陣乘法,得到4行4列輸出數據矩陣,由于輸出數據是32比特的,需要兩個向量寄存器存放結果。
如圖二所示,為矩陣累加指令,輸入數據只從VS1中讀取,權重數據從VS2中讀取,兩者進行矩陣乘法。
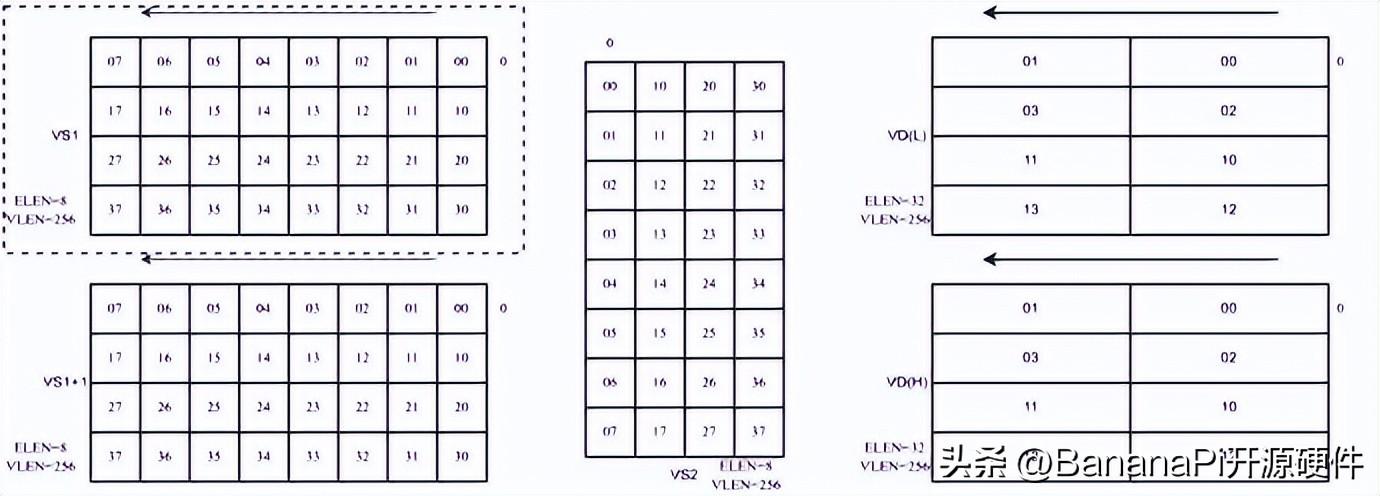
圖二:矩陣累加指令數據排布示例
如圖三所示,為滑窗累加指令,輸入數據只從VS1和VS1+1中讀取,讀取的數據,通過滑動的大小決定(大小為8的倍數),權重數據從VS2中讀取,兩者進行矩陣乘法。
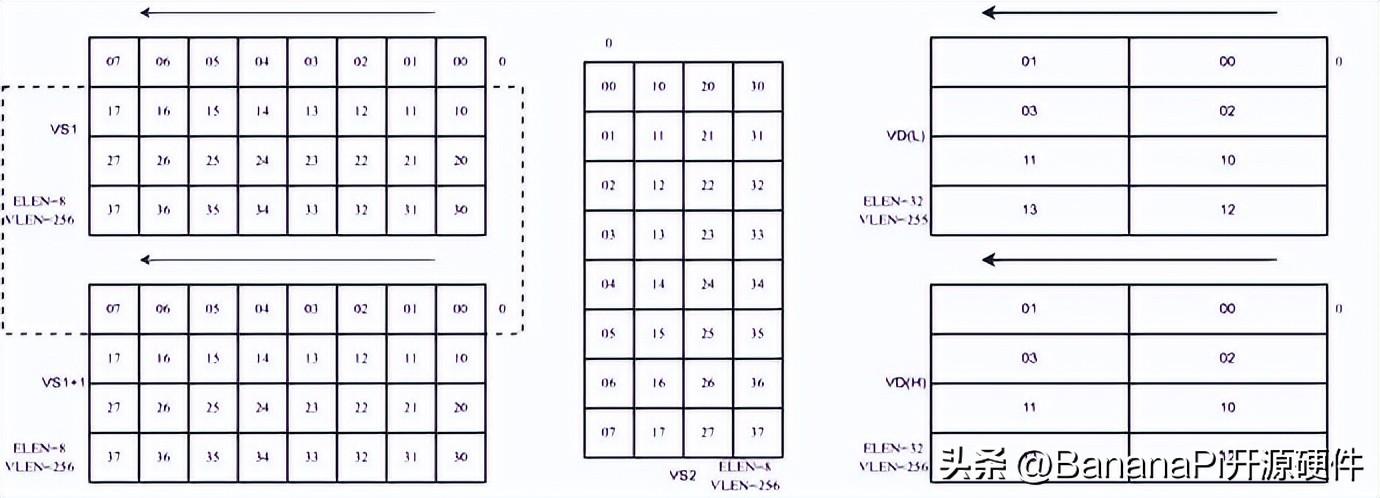
圖三:滑窗累加指令數據排布示例
如下圖所示,9個紅點對應的9行輸入數據(1*k維)和權重進行乘累加計算,就得到了一個卷積值。在做卷積計算的時候,可以把矩陣乘法看成是滑動為零的滑窗指令。通過滑動0,1,2三條指令的計算,就可以完成kernel size 為3x1的的卷積計算。然后通過h維度的三次循環,就可以得到kernel size 為3x3的卷積計算。
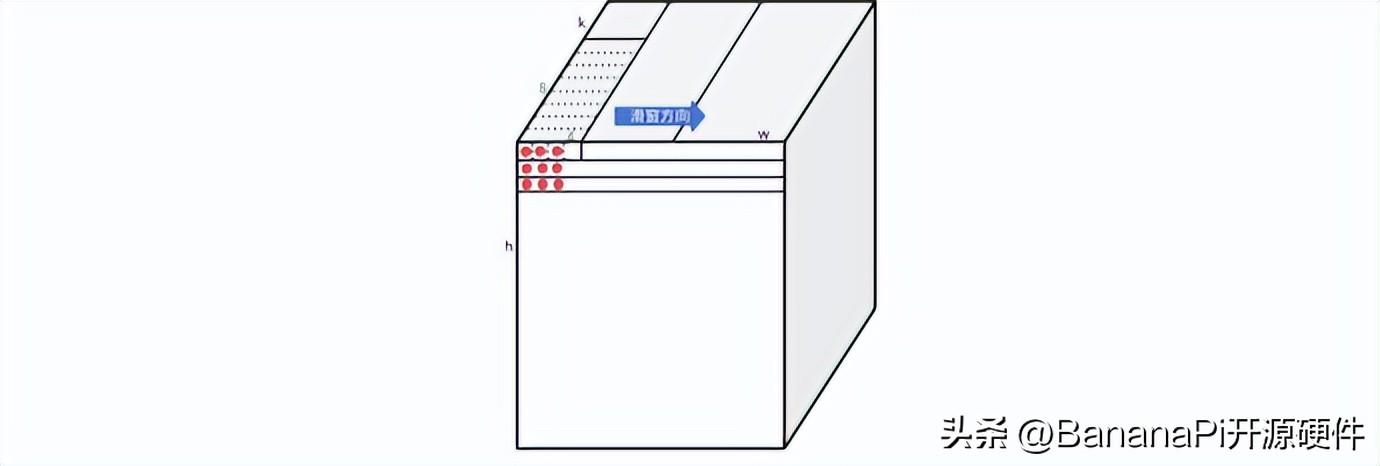
圖四:滑窗累加指令結合矩陣累加指令計算卷積示例
同樣通過滑動0,1,2,0,1五條指令的計算,和h維度五次循環,就可以完成kernel size為5x5的卷積計算,以此類推,可以得到任意kernel size的卷積計算。
效果演示視頻
通過以上軟硬件協同優化,我們在多任務推理時,也有非常高的性能。
重播
00:35
/
00:35
展望
前文提到,通過ONNX與ONNXRuntime的結合,我們能夠便捷地接入開源生態,但這僅僅是實現接入的眾多方式之一。實際上,我們還可以充分利用當前備受矚目的MLIR生態,進一步融入開源的廣闊天地。這種方式不僅充滿想象力,而且具備諸多優勢。
首先,它能夠實現模型的直接原生部署。舉例來說,當我們擁有一個PyTorch模型時,借助torch.compile功能,我們可以直接將模型部署到目標平臺上,無需繁瑣的轉換和適配過程,極大地提升了部署的便捷性。
其次,MLIR生態與LLVM的緊密結合為我們提供了強大的codegen能力。這意味著我們可以利用LLVM豐富的生態系統和工具鏈,進行代碼生成和優化,從而進一步降低AI軟件棧的開發成本。通過codegen,我們可以將高級別的模型描述轉化為底層高效的機器代碼,實現性能的最優化。
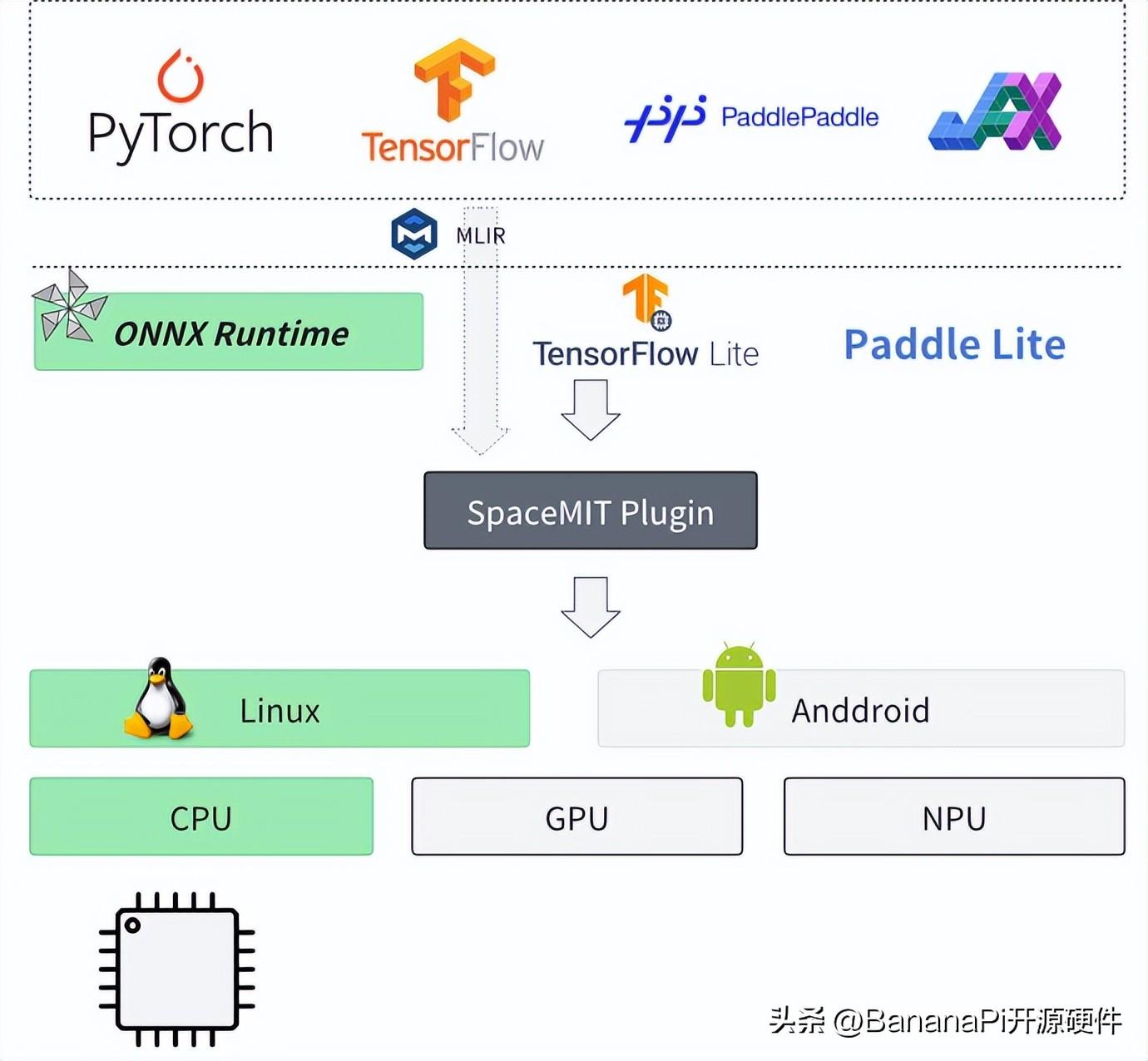
圖五:進迭時空AI軟件棧架構規劃
引用
https://onnxruntime.ai/
https://onnx.ai/
https://mlir.llvm.org/
https://pytorch.org/
-
AI
+關注
關注
87文章
30869瀏覽量
269032 -
人工智能
+關注
關注
1791文章
47269瀏覽量
238439 -
開發板
+關注
關注
25文章
5048瀏覽量
97442 -
RISC-V
+關注
關注
45文章
2277瀏覽量
46157 -
banana pi
+關注
關注
1文章
113瀏覽量
3021
發布評論請先 登錄
相關推薦
如何快速上手進迭時空K1 RISC-V開發板:Banana Pi BPI-F3

香蕉派 BPI-CanMV-K230D-Zero 采用嘉楠科技 K230D RISC-V芯片設計
香蕉派開發板BPI-CanMV-K230D-Zero 嘉楠科技 RISC-V開發板公開發售
Banana Pi BPI-CanMV-K230D-Zero :AIoT 應用的 Kendryte K230D RISC-V

Banana Pi BPI-F3 進迭時空 SpacemiT K1 RISC-V板 運行OpenWRT
Banana Pi BPI-F2S IC設計與FPGA教育學習開發套裝
RISC-V芯片企業 進迭時空完成Pre A+ 輪融資
【RISC-V人才行】 走訪進迭時空

Banana Pi BPI-F3 進控時空SpacemiT K1芯片場景功耗測試
Banana Pi BPI-F3 進迭時空 RISC-V K1芯片開發板支持8G/16G內存

RT-Thread攜手進迭時空:共建RISC-V實時計算生態

業內首顆8核RISC-V終端AI CPU量產芯片K1,進迭時空與中國移動用芯共創AI+時代





 工商網監
工商網監
評論