 全新開源工具,助力FPGA上輕松實現二值化神經網絡
全新開源工具,助力FPGA上輕松實現二值化神經網絡
神經網絡技術起源于上世紀五、六十年代,當時叫感知機,擁有輸入層、輸出層和一個隱含層。輸入的特征向量通過隱含層變換達到輸出層,在輸出層得到分類結果,早期感知機的推動者是Ronsenblatt。后來又發展到多層感知機,而多層感知機在擺脫早期離散傳輸函數的束縛,在訓練算法上使用Werbos發明的反向傳播BP算法,這個就是現在大家常數的神經網絡NN,而目前存在的神經網絡最常見的有:ANN,RNN,以及CNN。CNN是一種多層神經網絡,擅長處理圖像特別是大圖像的相關機器學習問題,它可以通過一系列方法,成功將數據量龐大的圖像識別問題不斷將維,最終使其能夠被訓練。
GUNNESS開源工具
一個叫做GUNNESS的全新的開源工具,可以幫助用戶通過SDSoC 開發環境很輕松的將二值化神經網絡(BNNs)實現在Zynq SoC芯片和Zynq UltraScale+ MPSoC芯片上。GUINNESS基于GUI工具而開發,內部實現利用深度學習框架來訓練一個二值的CNN。關于這部分內容在今年IEEE的國際并行和分布式處理的workshop上有一篇論文對此進行了較為全面的介紹(論文名為“on-chip Memory Based binarized Convolutional Deep Neural Network Applying Batch Normalization Free Technique on an FPGA”),論文中,作者Haruyoshi Yonekawa和Hiroki Nakahara描述了一個他們實現的系統:他們通過在Xilinx ZCU102 Eval 套件上實現一個用于運行VGG-16 benchmark的二值化CNN邏輯系統,其中ZCU102套件其實是基于Zynq UltraScale+ MPSoC芯片而搭建的。在后來比利時 Ghent的FPL2017中作者Nakahara就GUINNESS工具再次進行了介紹。
根據IEEE中發表的這篇paper所述,在Zynq上實現的CNN相比較與在ARM Cortex-A57處理器上運行CNN,運行速度加快了136.8倍,并且功率有效性也提高了44.7倍之多。與在Nvidia Maxwell GPU上運行同樣的CNN相比較,基于Zynq實現的BNN速度加快了4.9倍之多,功耗效率也增長了3.8倍。
不過,對于我們這些游離愛好者來說最值得慶幸的是整個GUINNESS工具可以在Github上access到(https://github.com/HirokiNakahara/GUINNESS)。
圖:Xilinx ZCU102 Zynq UltraScale+ MPSoC Eval Kit
目前的比較火的概念莫過于機器學習,深度學習,人工智能這三方面了,而這些技術的實現都離不開神經網絡的訓練,可以說當前技術的熱點非神經網絡莫屬。但是神經網絡算法往往較為復雜,軟件實現速度往往無法達到需求,專用芯片設計又功能單一且成本高,而通過FPGA實現的話,不僅避免的單用途高成本的投入,同時得到了用戶期望的運算速度,一舉兩得。也相信在以后FPGA將會為神經網絡的研究實現方面有更大的發揮空間。
-
FPGA
+關注
關注
1630文章
21759瀏覽量
604370 -
神經網絡
+關注
關注
42文章
4774瀏覽量
100909 -
人工智能
+關注
關注
1792文章
47442瀏覽量
239009
原文標題:開源工具助你在FPGA上輕松實現二值化神經網絡
文章出處:【微信號:FPGA-EETrend,微信公眾號:FPGA開發圈】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MATLAB神經網絡工具箱函數
labview BP神經網絡的實現
【PYNQ-Z2申請】基于PYNQ的卷積神經網絡加速
【PYNQ-Z2試用體驗】神經網絡基礎知識
基于賽靈思FPGA的卷積神經網絡實現設計
如何設計BP神經網絡圖像壓縮算法?
如何移植一個CNN神經網絡到FPGA中?
用FPGA去實現大型神經網絡的設計
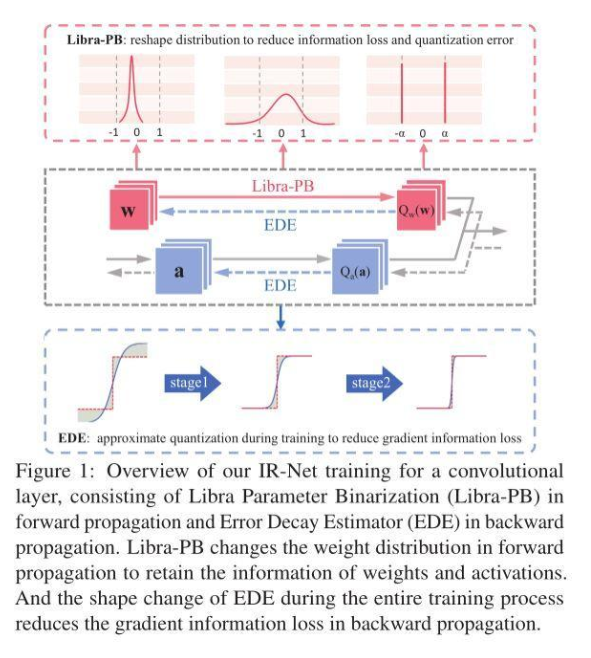
信息保留的二值神經網絡IR-Net,落地性能和實用性俱佳






 工商網監
工商網監
評論