 解密Elasticsearch:深入探究這款搜索和分析引擎
解密Elasticsearch:深入探究這款搜索和分析引擎
?開篇
最近使用Elasticsearch實現畫像系統,實現的dmp的數據中臺能力。同時調研了競品的架構選型。以及重溫了redis原理等。特此做一次es的總結和回顧。網上沒看到有人用Elasticsearch來完成畫像的。我來做第一次嘗試。
背景說完,我們先思考一件事,使用內存系統做數據庫。他的優點是什么?他的痛點是什么?
?一、原理
這里不在闡述全貌。只聊聊通訊、內存、持久化三部分。
通訊
es集群最小單元是三個節點。兩個從節點搭配保證其高可用也是集群化的基礎。那么節點之間RPC通訊用的是什么?必然是netty,es基于netty實現了Netty4Transport的通訊包。初始化Transport后建立Bootstrap,通過MessageChannelHandler完成接收和轉發。es里區分server和client,如圖1。序列化使用的json。es在rpc設計上偏向于易用、通用、易理解。而不是單追求性能。
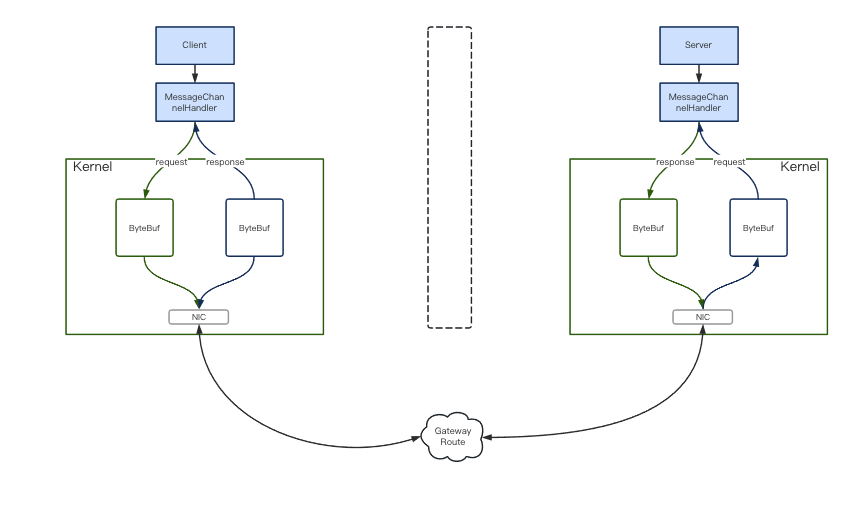
??
圖1
有了netty的保駕護航使得es放心是使用json序列化。
內存
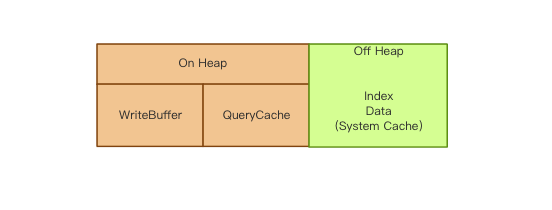
??
圖2
es內存分為兩部分【on heap】和【off heap】。on heap這部分由es的jvm管理。off heap則是由lucene管理。on heap 被分為兩部分,一部分可以回收,一部分不能回收。
能回收的部分index buffer存儲新的索引文檔。當被填滿時,緩沖區的文檔會被寫入到磁盤segment上。node上共享所有shards。
不能被回收的有node query cache、shard request cache、file data cache、segments cache
node query cache是node級緩存,過濾后保存在每個node上,被所有shards共享,使用bitset數據結構(布隆優化版)關掉了評分。使用的LRU淘汰策略。GC無法回收。
shard request cache是shard級緩存,每個shard都有。默認情況下該緩存只存儲request結果size等于0的查詢。所以該緩存不會被hits,但卻緩存hits.total,aggregations,suggestions。可以通過clear cache api清除。使用的LRU淘汰策略。GC無法回收。
file data cache 是把聚合、排序后的data緩存起來。初期es是沒有doc values的,所以聚合、排序后需要有一個file data來緩存,避免磁盤IO。如果沒有足夠內存存儲file data,es會不斷地從磁盤加載數據到內存,并刪除舊的數據。這些會造成磁盤IO和引發GC。所以2.x之后版本引入doc values特性,把文檔構建在indextime上,存儲到磁盤,通過memory mapped file方式訪問。甚至如果只關心hits.total,只返回doc id,關掉doc values。doc values支持keyword和數值類型。text類型還是會創建file data。
segments cache是為了加速查詢,FST永駐堆內內存。FST可以理解為前綴樹,加速查詢。but!!es 7.3版本開始把FST交給了堆外內存,可以讓節點支持更多的數據。FST在磁盤上也有對應的持久化文件。
off heap 即Segments Memory,堆外內存是給Lucene使用的。 所以建議至少留一半的內存給lucene。
es 7.3版本開始把tip(terms index)通過mmp方式加載,交由系統的pagecache管理。除了tip,nvd(norms),dvd(doc values), tim(term dictionary),cfs(compound)類型的文件都是由mmp方式加載傳輸,其余都是nio方式。tip off heap后的效果jvm占用量下降了78%左右。可以使用_cat/segments API 查看 segments.memory內存占用量。
由于對外內存是由操作系統pagecache管理內存的。如果發生回收時,FST的查詢會牽扯到磁盤IO上,對查詢效率影響比較大。可以參考linux pagecache的回收策略使用雙鏈策略。
持久化
es的持久化分為兩部分,一部分類似快照,把文件緩存中的segments 刷新(fsync)磁盤。另一部分是translog日志,它每秒都會追加操作日志,默認30分鐘刷到磁盤上。es持久化和redis的RDB+AOF模式很像。如下圖
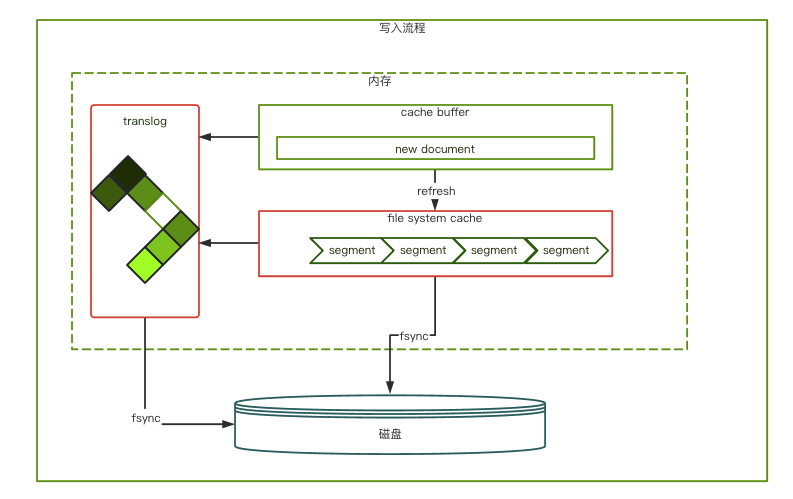
??
圖3
上圖是一個完整寫入流程。磁盤也是分segment記錄數據。這里濡染跟redis很像。但是內部機制沒有采用COW(copy-on-write)。這也是查詢和寫入并行時load被打滿的原因所在。
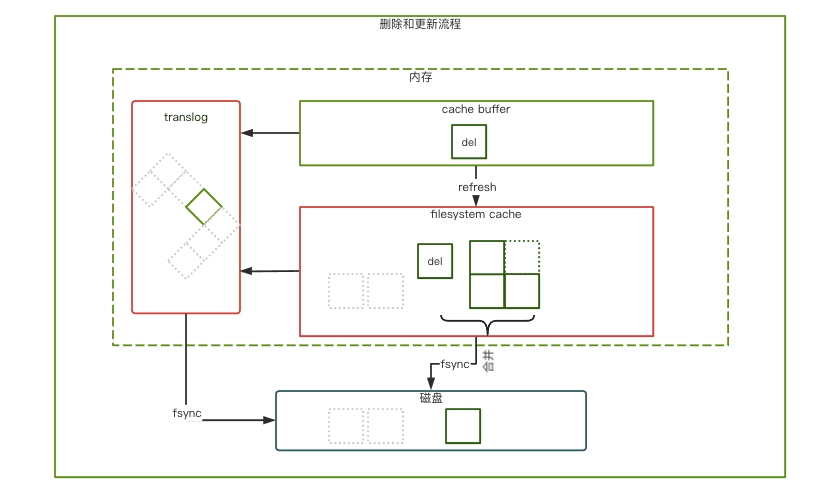
??
圖4
如果刪除操作,并不是馬上物理清除被刪除的文檔,而是標記為delete狀態;更新操作,標記原有的文檔為delete狀態,再插入一條新的文檔。( 如圖4)
系統中會產生很多的Segment file文件。所以定期要執行合并(merge)操作,將多個Segment file文件合并為一個。在合并的過程中,會將標記刪除的文件進行物理刪除操作。
ES記錄每個Segment file文件的提交點(commit point),用于管理所有的Segment file文件。
小結
es內存和磁盤的設計上非常巧妙。零拷貝上采用mmap方式,磁盤數據映射到off heap,也就是lucene。為了加速數據的訪問,es每個segment都有會一些索引數據駐留在off heap里;因此segment越多,瓜分掉的off heap也越多,這部分是無法被GC回收!
結合以上兩點可以清楚知道為什么es非常吃內存了。
二、應用
用戶畫像系統中有以下難點需要解決。
1.人群預估:根據標簽選出一類人群,如20-25歲的喜歡電商社交的男性。20-25歲∩電商社交∩男性。通過與或非的運算選出符合特征的clientId的個數。這是一組。
我們組與組之前也是可以在做交并差的運算。如既是20-25歲的喜歡電商社交的男性,又是北京市喜歡擼鐵的男性。(20-25歲∩電商社交∩男性)∩(20-25歲∩擼鐵∩男性)。對于這樣的遞歸要求在17億多的畫像庫中,秒級返回預估人數。
2.人群包圈選:上述圈選出的人群包。 要求分鐘級構建。
3.人包判定:判斷一個clientId是否存在若干個人群包中。要求10毫秒返回結果。
我們先嘗試用es來解決以上所有問題。
人群預估,最容易想到方案是在服務端的內存中做邏輯運算。但是圈選出千萬級的人群包人數秒級返回的話在服務端做代價非常大。這時候可以吧計算壓力拋給es存儲端,像查詢數據庫一樣。使用一條語句查出我們想要的數據來。
例如mysql
select a.age from a where a.tel in (select b.age from b);
對應的es的dsl類似于
{"query":{"bool":{"must":[{"bool":{"must":[{"term":{"a9aa8uk0":{"value":"age18-24","boost":1.0}}},{"term":{"a9ajq480":{"value":"male","boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}},{"bool":{"adjust_pure_negative":true,"boost":1.0}}],"adjust_pure_negative":true,"boost":1.0}}}
這樣使用es的高檢索性能來滿足業務需求。無論所少組,組內多少的標簽。都打成一條dsl語句。來保證秒級返回結果。
使用官方推薦的RestHighLevelClient,實現方式有三種,一種是拼json字符串,第二種調用api去拼字符串。我使用第三種方式BoolQueryBuilder來實現,比較優雅。它提供了filter、must、should和mustNot方法。如
/**
* Adds a query that must not appear in the matching documents.
* No {@code null} value allowed.
*/
public BoolQueryBuilder mustNot(QueryBuilder queryBuilder) {
if (queryBuilder == null) {
throw new IllegalArgumentException("inner bool query clause cannot be null");
}
mustNotClauses.add(queryBuilder);
return this;
}
/**
* Gets the queries that must not appear in the matching documents.
*/
public List mustNot() {
return this.mustNotClauses;
}
使用api的可以大大的show下編代碼的能力。
構建人群包。目前我們圈出最大的包有7千多萬的clientId。想要分鐘級別構建完(7千萬數據在條件限制下35分鐘構建完)需要注意兩個地方,一個是es深度查詢,另一個是批量寫入。
es分頁有三種方式,深度分頁有兩種,后兩種都是利用游標(scroll和search_after)滾動的方式檢索。
scroll需要維護游標狀態,每一個線程都會創建一個32位唯一scroll id,每次查詢都要帶上唯一的scroll id。如果多個線程就要維護多個游標狀態。search_after與scroll方式相似。但是它的參數是無狀態的,始終會針對對新版本的搜索器進行解析。它的排序順序會在滾動中更改。scroll原理是將doc id結果集保留在協調節點的上下文里,每次滾動分批獲取。只需要根據size在每個shard內部按照順序取回結果即可。
寫入時使用線程池來做,注意使用的阻塞隊列的大小,還要選擇適的拒絕策略(這里不需要拋異常的策略)。批量如果還是寫到es中(比如做了讀寫分離)寫入時除了要多線程外,還有優化寫入時的refresh policy。
人包判定接口,由于整條業務鏈路非常長,這塊檢索,上游服務設置的熔斷時間是10ms。所以優化要優化es的查詢(也可以redis)畢竟沒負責邏輯處理。使用線程池解決IO密集型優化后可以達到1ms。tp99高峰在4ms。
?三、優化、瓶頸與解決方案
以上是針對業務需求使用es的解題方式。還需要做響應的優化。同時也遇到es的瓶頸。
1.首先是mapping的優化。畫像的mapping中fields中的type是keyword,index要關掉。人包中的fields中的doc value關掉。畫像是要精確匹配;人包判定只需要結果而不需要取值。es api上人包計算使用filter去掉評分,filter內部使用bitset的布隆數據結構,但是需要對數據預熱。寫入時線程不易過多,和核心數相同即可;調整refresh policy等級。手動刷盤,構建時index.refresh_interval 調整-1,需要注意的是停止刷盤會加大堆內存,需要結合業務調整刷盤頻率。構建大的人群包可以將index拆分成若干個。分散存儲可以提高響應。目前幾十個人群包還是能支撐。如果日后成長到幾百個的時候。就需要使用bitmap來構建存儲人群包。es對檢索性能很卓越。但是如遇到寫操作和查操作并行時,就不是他擅長的。比如人群包的數據是每天都在變化的。這個時候es的內存和磁盤io會非常高。上百個包時我們可以用redis來存。也可以選擇使用MongoDB來存人包數據。
四、總結
以上是我們使用Elasticsearch來解決業務上的難點。同時發現他的持久化沒有使用COW(copy-on-write)方式。導致在實時寫的時候檢索性能降低。
使用內存系統做數據源有點非常明顯,就是檢索塊!尤其再實時場景下堪稱利器。同時痛點也很明顯,實時寫會拉低檢索性能。當然我們可以做讀寫分離,拆分index等方案。
除了Elasticsearch,我們還可以選用ClickHouse,ck也是支持bitmap數據結構。甚至可以上Pilosa,pilosa本就是BitMap Database。
?
?
參考
?貝殼DMP平臺建設實踐?
?Mapping parameters | Elasticsearch Reference [7.10] | Elastic?
?Elasticsearch 7.3 的 offheap 原理?
審核編輯 黃宇
-
數據庫
+關注
關注
7文章
3799瀏覽量
64389 -
引擎
+關注
關注
1文章
361瀏覽量
22561 -
Elasticsearch
+關注
關注
0文章
29瀏覽量
2831
發布評論請先 登錄
相關推薦
構建高效搜索解決方案,Elasticsearch & Kibana 的完美結合
Elasticsearch 再次開源

Meta開發新搜索引擎,減少對谷歌和必應的依賴
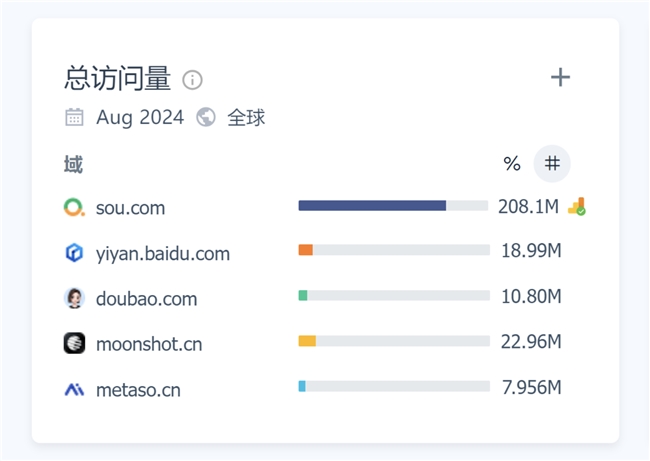
月訪問量超2億,增速113%!360AI搜索成為全球增速最快的AI搜索引擎
OpenAI推出SearchGPT原型,正式向Google搜索引擎發起挑戰
微軟計劃在搜索引擎Bing中引入AI摘要功能
深入探究 MEMS LVCMOS 振蕩器 SiT1602 系列 52 種標準頻率
深入理解渲染引擎:打造逼真圖像的關鍵

OpenAI發布全新搜尋引擎,引領搜索體驗新高度
OpenAI注冊新域名,準備推出結合AI技術的搜索引擎挑戰谷歌
OpenAI或將推出ChatGPT搜索引擎
生成式AI恐使搜索引擎衰退,預計2026年搜索量將下滑25%
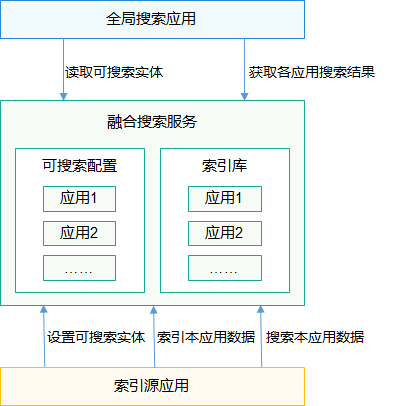
鴻蒙OS開發之 融合搜索概述





 工商網監
工商網監
評論