 關于EM算法的九層境界的淺薄介紹,?Hinton和Jordan理解的EM算法
關于EM算法的九層境界的淺薄介紹,?Hinton和Jordan理解的EM算法
知乎上有一個討論:EM算法存在的意義是什么?是什么原因使得EM算法這么流行呢?EM算法是Hinton和Jordan強強發力的領域,本文作者縱向解析EM算法的9層境界,深入淺出,值得一讀。
Hinton, 這個深度學習的締造者( 參考攢說 Geoff Hinton), Jordan 當世概率圖模型的集大成者(參考 “喬丹上海行”), 他們碰撞的領域,EM算法!這個是PCA外的,另外一個無監督學習的經典,是我們的主題。
他們怎么認識的呢?Jordan的導師,就是著名的鏈接主義核心人物Rumelhart
(參考“易圖秒懂の連接主義誕生”)。在“人工智能深度學習人物關系[全]”里面我們介紹到,Hinton和Rumelhart是同事,都在Francis Crick的小組。
前言為什么說EM算法是他們強強發力的領域呢?
這里我們討論Hinton和統計大神Jordan的強強發力的領域。當Bayes網絡發展到高級階段, 概率圖模型使得計算成為問題,由此開啟了Variational Bayes領域。在“變の貝葉斯”里面, 我們解釋了研究Variational Bayes,有3撥人。 第一撥人, 把物理的能量搬到了機器學習(參考 “給能力以自由吧!”)。 第二撥人, 就是Hinton,他將VB和EM算法聯系了起來,奠定了現在我們看到的VB的基礎。 第三撥人,就是Jordan, 他重建了VB的框架ELBO的基礎。所以說EM算法擴展的VBEM算法,就是Hinton和Jordan共同發力的部分。
Hinton曾在采訪中,不無感慨的說到, 他當時研究VB和EM算法的關系的時候, 主動去請教當時的EM算法的大佬們, 結果那些人說Hinton是異想天開,神經有問題。 但是最終, 他還是突破重圍,搞定了VBEM算法,打下了VB世界最閃光的那盞燈。老爺子真心不容易! 如果想切實深入到VB的世界, 我推薦Daphne Koller的神書“Probabilistic Graphical Models: Principles and Techniques”, 尤其其中的第8章:The Exponential Family 和第19章 Partially Observed Data。 這兩章幾乎是Hinton對VBEM算法研究的高度濃縮。 國內機器學習牛人王飛躍老師, 率領各路弟子花了5年時間翻譯了這本神書!所以有中文版, 買了,反復閱讀8、19章,要的!
為什么無監督深度學習突出成果都是Hinton和Jordan家的?
無監督深度學習,除了強化學習,主要包括BM、自動編碼器AE和GAN領域。 1)這些領域中的DBN和DBM是Hinton搞的。2)AE中的經典,VAE是DP Kingma和M Welling搞得。DP Kingma碩士導師是LeCun,LeCun的博士后導師是Hinton,并且Welling的博士后導師是Hinton。 3)而GAN是Ian Goodfellow和Yoshua Bengio的杰作, Goodfellow是Bengio的學生, 而Bengio的博士后導師是Jordan。 一句話, 無監督深度學習的經典模型幾乎全是Hinton和Jordan家的。 為什么? 因為能徹底理解EM算法到深不見底的人非Hinton和Jordan莫屬。
你現在明白徹底理解EM算法的重要性了吧? 下面我淺薄的縱向理解(忽略EM的各種變種的橫向)EM算法的9層境界,再回頭反思一下Hinton和Jordan等會對EM算法的理解到何種程度, 簡直嘆而觀止!
EM算法理解的九層境界-
EM 就是 E + M
-
EM 是一種局部下限構造
-
K-Means是一種Hard EM算法
-
從EM 到 廣義EM
-
廣義EM的一個特例是VBEM
-
廣義EM的另一個特例是WS算法
-
廣義EM的再一個特例是Gibbs抽樣算法
-
WS算法是VAE和GAN組合的簡化版
-
KL距離的統一
最經典的例子就是拋3個硬幣,跑I硬幣決定C1和C2,然后拋C1或者C2決定正反面, 然后估算3個硬幣的正反面概率值。
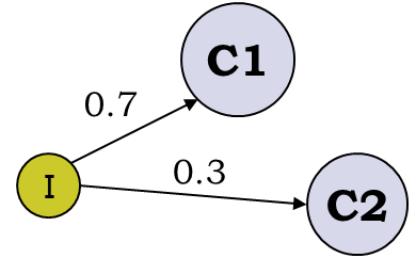
這個例子為什么經典, 因為它告訴我們,當存在隱變量I的時候, 直接的最大似然估計無法直接搞定。什么是隱變量?為什么要引入隱變量? 對隱變量的理解是理解EM算法的第一要義!Chuong B Do & Serafim Batzoglou的Tutorial論文“What is the expectation maximization algorithm?”對此有詳細的例子進行分析。
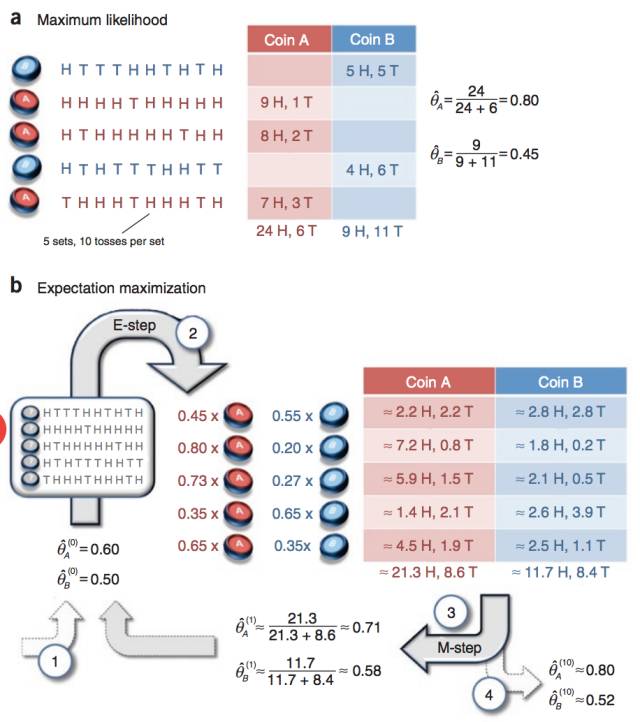
通過隱變量,我們第一次解讀了EM算法的偉大!突破了直接MLE的限制(不詳細解釋了)。

至此, 你理解了EM算法的第一層境界,看山是山。
第二層境界, EM算法就一種局部下限構造如果你再深入到基于隱變量的EM算法的收斂性證明, 基于log(x)函數的Jensen不等式構造, 我們很容易證明,EM算法是在反復的構造新的下限,然后進一步求解。

所以,先固定當前參數, 計算得到當前隱變量分布的一個下屆函數, 然后優化這個函數, 得到新的參數, 然后循環繼續。
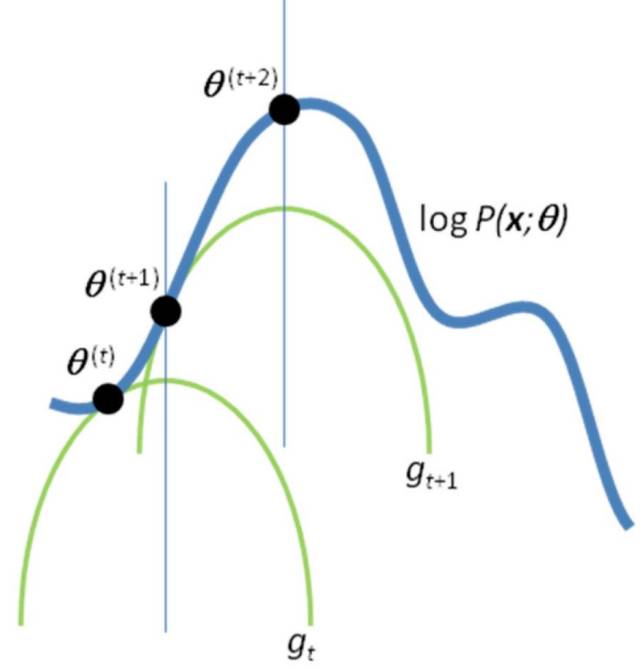
也正是這個不停的構造下限的思想未來和VB方法聯系起來了。 如果你理解了這個, 恭喜你, 進入理解EM算法的第二層境界,看山看石。
第三層境界,K-均值方法是一種Hard EM算法在第二層境界的基礎上, 你就能隨意傲游EM算法用到GMM和HMM模型中去了。 尤其是對GMM的深入理解之后, 對于有隱變量的聯合概率,如果利用高斯分布代入之后:
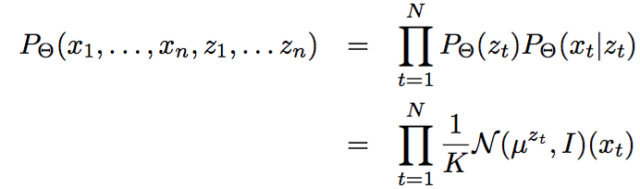
很容易就和均方距離建立聯系:
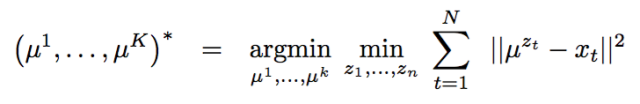
但是,能不能說K-均值就是高斯分布的EM算法呢?不是, 這里雖然拓展到了相同的距離公式, 但是背后邏輯還是不一樣, 不一樣在哪里呢?K-均值在討論隱變量的決定時候,用的是dirac delta 分布, 這個分布是高斯分布的一種極限。

如果你覺得這個擴展不太好理解, 那么更為簡單直觀的就是, k-均值用的hard EM算法, 而我們說的EM算法是soft EM算法。 所謂hard 就是要么是,要么不是0-1抉擇。 而Soft是0.7比例是c1,0.3比例是c2的情況。
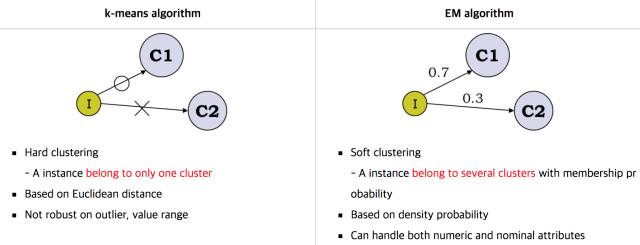
那么充分理解了k-均值和EM算法本身的演化和差異有什么幫助呢?讓你進一步理解到隱變量是存在一種分布的。
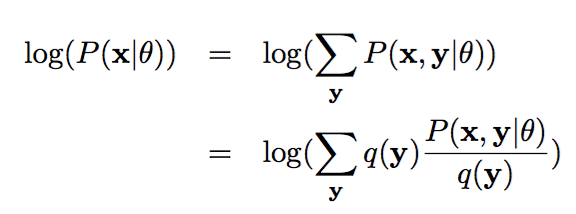
如果你理解了這個, 恭喜你, 進入理解EM算法的第三層境界,看山看峰。
第四層境界,EM 是 廣義EM的特例通過前3層境界, 你對EM算法的理解要跨過隱變量, 進入隱分布的境界。 如果我們把前面的EM收斂證明稍微重復一下,但是引入隱分布。
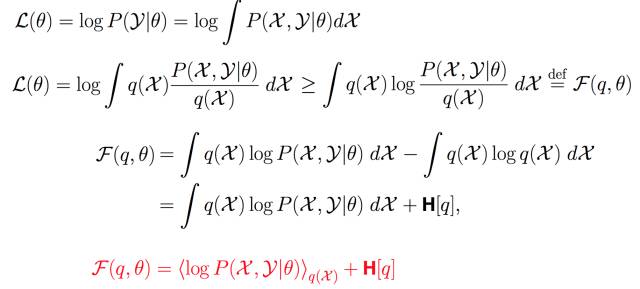
這樣我們把Jensen不等收右邊的部分定義為自由能(如果你對自由能有興趣,請參考“給能量以自由吧!”,如果沒有興趣, 你就視為一種命名)。 那么E步驟是固定參數優化隱分布, M步驟是固定隱分布優化參數,這就是廣義EM算法了。

有了廣義EM算法之后, 我們對自由能深入挖掘, 發現自由能和似然度和KL距離之間的關系:
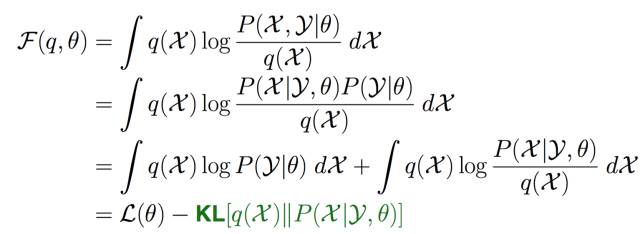
所以固定參數的情況下, 那么只能最優化KL距離了, 那么隱分布只能取如下分布:
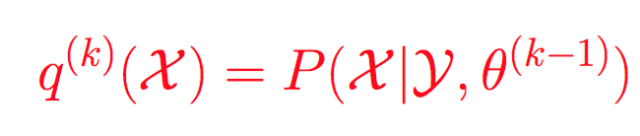
而這個在EM算法里面是直接給出的。 所以EM算法是廣義EM算法的天然最優的隱分布情況。但是很多時候隱分布不是那么容易計算的!
前面的推理雖然很簡單, 但是要理解到位真心不容易, 首先要深入理解KL距離是如何被引入的?
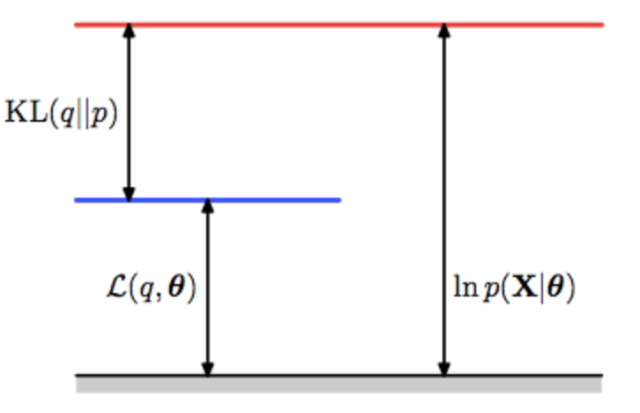
其次要理解, 為什么傳統的EM算法,不存在第一個最優化?因為在沒有限制的隱分布(天然情況下)情況下, 第一個最優就是要求:
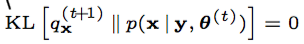
而這個隱分布, EM算法里面是直接給出的,而不是讓你證明得到的。
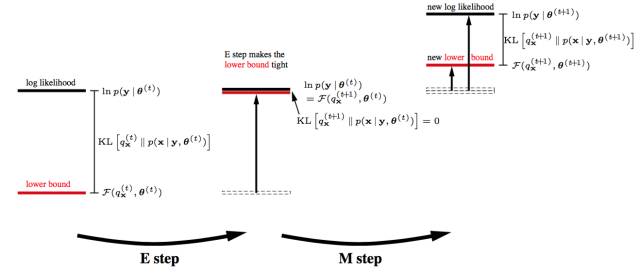
這樣, 在廣義EM算法中,你看到兩個優化步驟,我們進入了兩個優化步驟理解EM算法的境界了。
如果你理解了這個, 恭喜你, 進入理解EM算法的第四層境界,有水有山。
第五層境界,廣義EM的一個特例是VBEM在隱分布沒有限制的時候, 廣義EM算法就是EM算法, 但是如果隱分布本身是有限制的呢?譬如有個先驗分布的限制, 譬如有計算的限制呢?
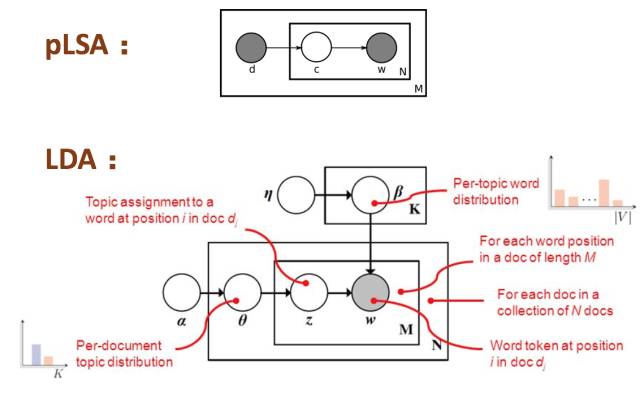
例如先驗分布的限制:從pLSA到LDA就是增加了參數的先驗分布!
例如計算上的限制:mean-field計算簡化的要求,分量獨立。
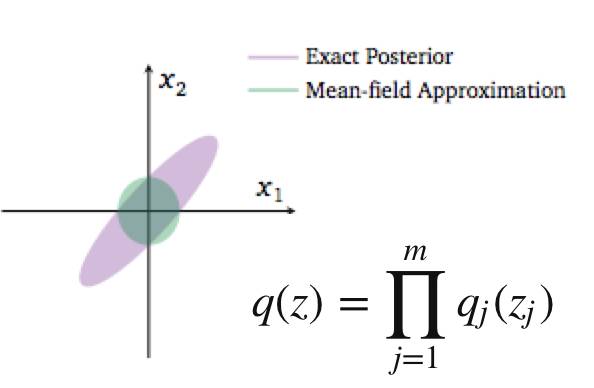
諸如此類限制, 都使得廣義EM里面的第一步E優化不可能達到無限制最優, 所以KL距離無法為0。
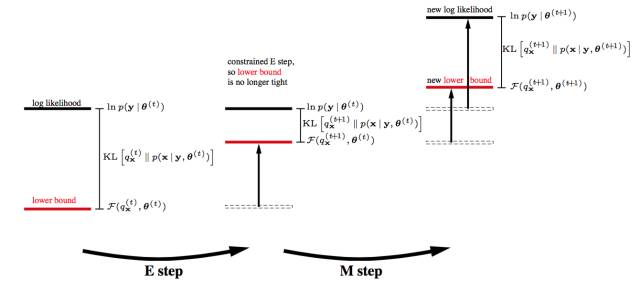
基于有限制的理解, 再引入模型變分的思想, 根據模型m的變化, 對應參數和隱變量都有相應的分布:
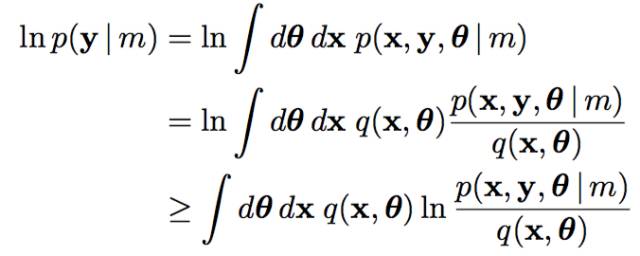
并且滿足分布獨立性簡化計算的假設:
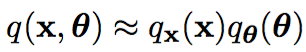
在變分思想下, 自由能被改寫了:
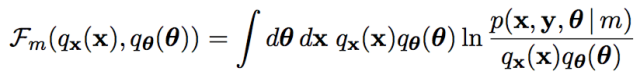
這樣我們就得到了VBEM算法了:
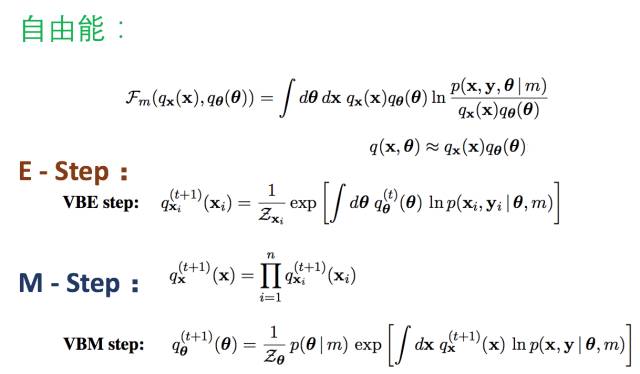
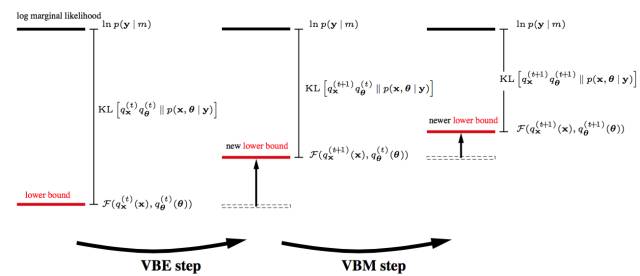
如果你理解了這個, 恭喜你, 進入理解EM算法的第五層境界,水轉山回。
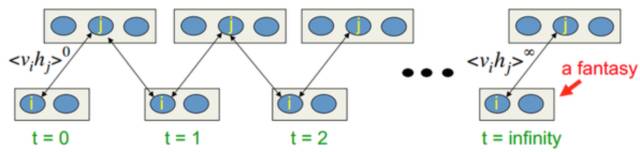
第六層境界,廣義EM的另一個特例是WS算法Hinton老爺子搞定VBEM算法后, 并沒有停滯, 他在研究DBN和DBM的Fine-Tuning的時候, 提出了Wake-Sleep算法。 我們知道在有監督的Fine-Tuning可以使用BP算法, 但是無監督的Fine-Tuning,使用的是Wake-Sleep算法。
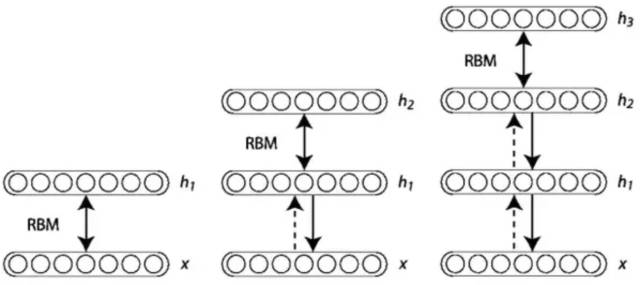
就是這個WS算法,也是廣義EM算法的一種特例。WS算法分為認知階段和生成階段。
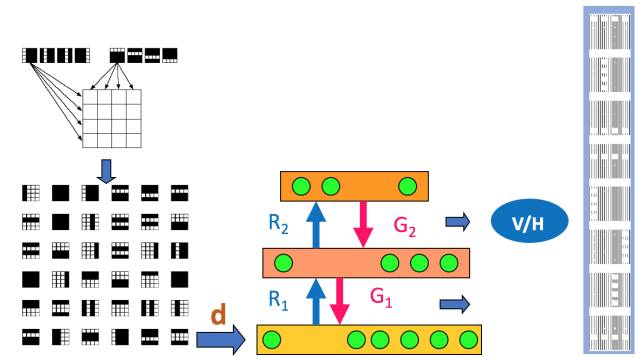
在前面自由能里面,我們將KL距離引入了, 這里剛好這兩個階段分別優化了KL距離的兩種形態。 固定P優化Q,和固定Q優化P。
所以當我們取代自由能理解, 全部切換到KL距離的理解, 廣義EM算法的E步驟和M步驟就分別是E投影和M投影。 因為要求KL距離最優, 可以等價于垂直。 而這個投影, 可以衍生到數據D的流形空間, 和模型M的流形空間。
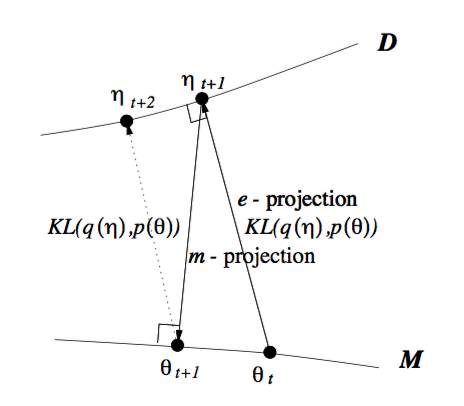
所以你認同WS算法是一種廣義EM算法(GEM)之后, 基于KL距離再認識GEM算法。 引入了數據流形和模型流形。引入了E投影和M投影。
不過要注意的wake識別階段對應的是M步驟, 而sleep生成階段對應的E步驟。 所以WS算法對應的是廣義ME算法。
如果你理解了這個, 恭喜你, 進入理解EM算法的第六層境界,山高水深。
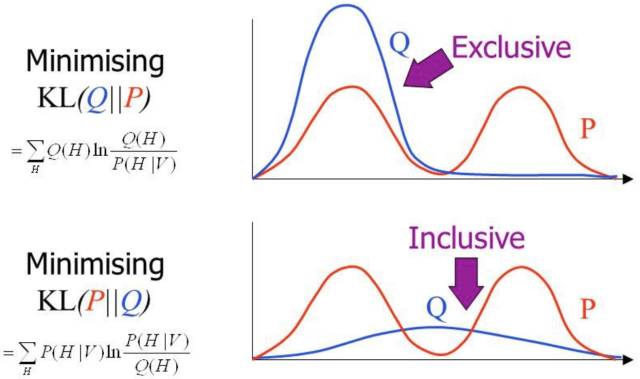
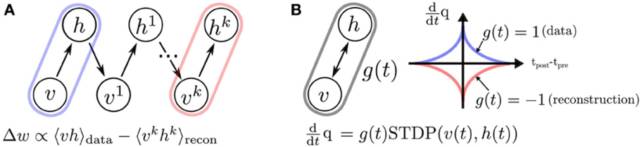
第七層境界,廣義EM的再一個特例是Gibbs Sampling其實,前面基于KL距離的認知, 嚴格放到信息理論的領域, 對于前面E投影和M投影都有嚴格的定義。M投影的名稱是類似的,但是具體是moment projection,但是E投影應該叫I投影,具體是information projection。
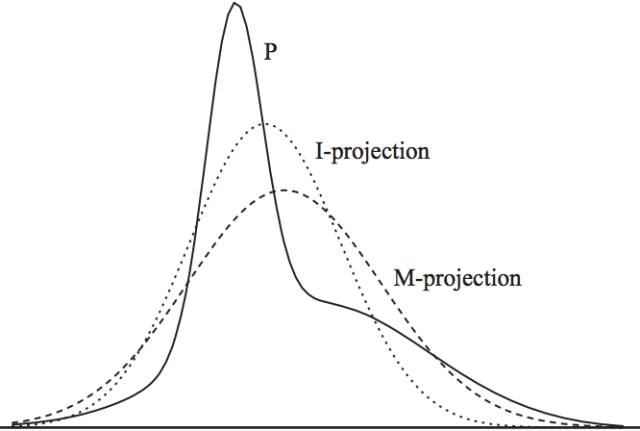
上面這種可能不太容易體會到M投影和I投影的差異, 如果再回到最小KL距離,有一個經典的比較。 可以體會M投影和I投影的差異。上面是I投影,只覆蓋一個峰。 下面是M投影, 覆蓋了兩個峰。
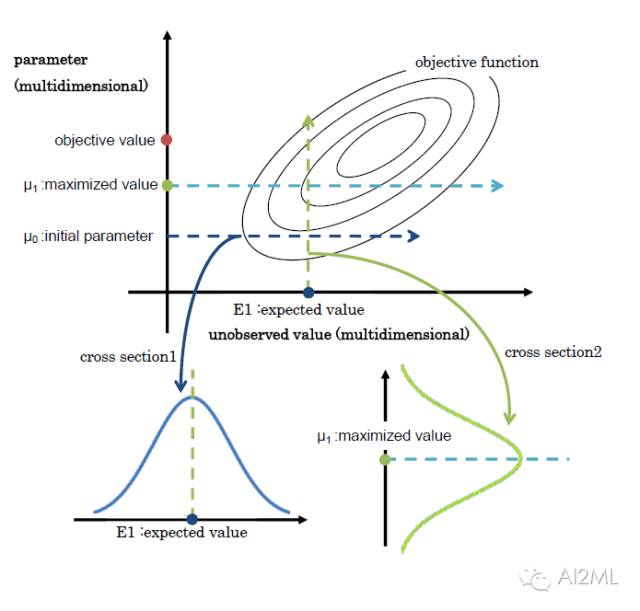
當我們不是直接計算KL距離, 而是基于蒙特卡洛抽樣方法來估算KL距離。

有興趣對此深入的,可以閱讀論文“On Monte Carlo methods for estimating ratios of normalizing constants”
這時候, 廣義EM算法,就是Gibbs Sampling了。 所以Gibbs Sampling,本質上就是采用了蒙特卡洛方法計算的廣義EM算法。
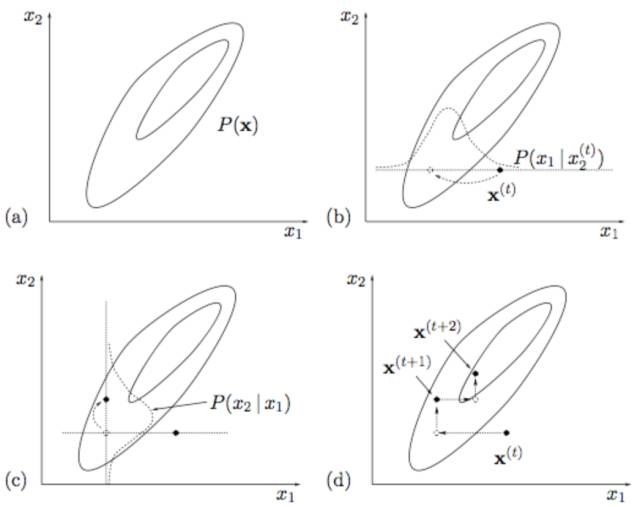
所以, 如果把M投影和I投影看成是一個變量上的最小距離點,那么Gibbs Sampling和廣義EM算法的收斂過程是一致的。
VAE的發明者,Hinton的博士后, Max Welling在論文“Bayesian K-Means as a “Maximization-Expectation” Algorithm”中, 對這種關系有如下很好的總結!
另外,Zoubin Ghahramani, Jordan的博士, 在“Factorial Learning and the EM Algorithm”等相關論文也反復提到他們之間的關系。
這樣, 通過廣義EM算法把Gibbs Sampling和EM, VB, K-Means和WS算法全部聯系起來了。有了Gibbs Sampling的背書, 你是不是能更好的理解, 為什么WS算法可以是ME步驟,而不是EM的步驟呢?另外,我們知道坐標下降Coordinate Descent也可以看成一種Gibbs Sampling過程, 如果有人把Coordinate Descent和EM算法聯系起來, 你還會覺得奇怪么?
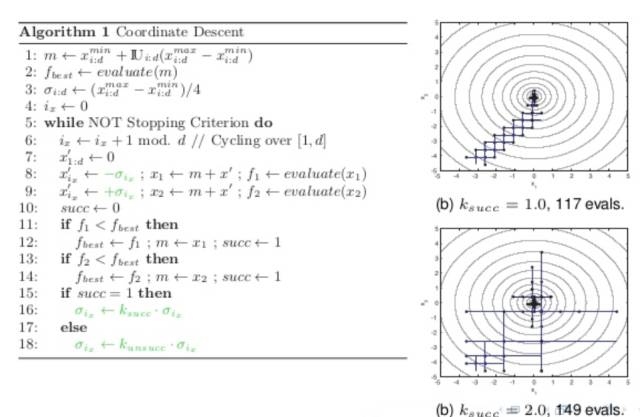
現在我們發現VB和Gibbs Sampling都可以放到廣義EM的大框架下, 只是求解過程一個采用近似逼近, 一個采用蒙特卡洛采樣。 有了EM算法和Gibbs Sampling的關系, 現在你理解, 為什么Hinton能夠發明CD算法了么? 細節就不展開了。
如果你理解了這個, 恭喜你, 進入理解EM算法的第七層境界,山水輪回。
第八層境界,WS算法是VAE和GAN組合的簡化版Jordan的弟子邢波老師,他的學生胡志挺,發表了一篇文章, On Unifying Deep Generative Models,試圖通過WS算法,統一對VAE和GAN的理解。
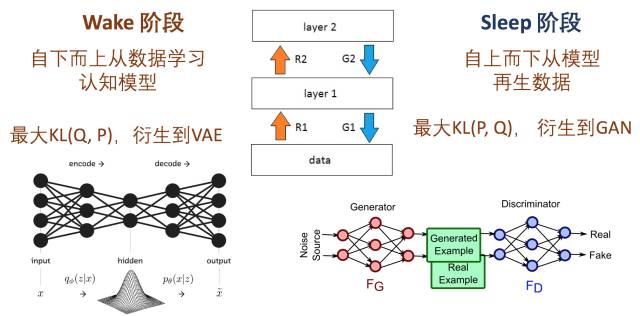
對VAE的理解, 變了加了正則化的KL距離, 而對于GAN的理解變成了加Jensen–Shannon 散度。 所以, 當我們把廣義EM算法的自由能, 在WS算法中看成KL散度, 現在看成擴展的KL散度。 對于正則化擴展, 有很多類似論文, “Mode Regularized Generative Adversarial Networks”, “Stabilizing Training of Generative Adversarial Networks through Regularization” 有興趣可以讀讀。
所以對于VAE,類比WS算法的Wake認知階段,不同的是在ELBO這個VBEM目標的基礎上加了KL散度作為正則化限制。 再應用再參數化技巧實現了VAE。

而對應到GAN,類比Sleep階段,正則化限制換了JSD距離, 然后目標KL距離也隨著不同GAN的變體也可以變化。

所以,VAE和GAN都可以理解為有特殊正則化限制的Wake-Sleep步驟, 那么組合起來也并不奇怪。

這就是為什么那么多論文研究如何組合VAE/GAN到同一個框架下面去。目前對這方面的理解還在廣泛探討中。
如果你理解了這個, 恭喜你, 進入理解EM算法的第八層境界,水中有水、山外有山。
第九層境界,KL距離的統一Jordan 大佬的一片論文, 開啟了KL距離的統一, “On surrogate loss functions and f-divergences”。 里面對于所謂的正反KL距離全部統一到 f 散度的框架下面。 Jordan 首先論述了對于損失函數統一的Margin理論的意義。
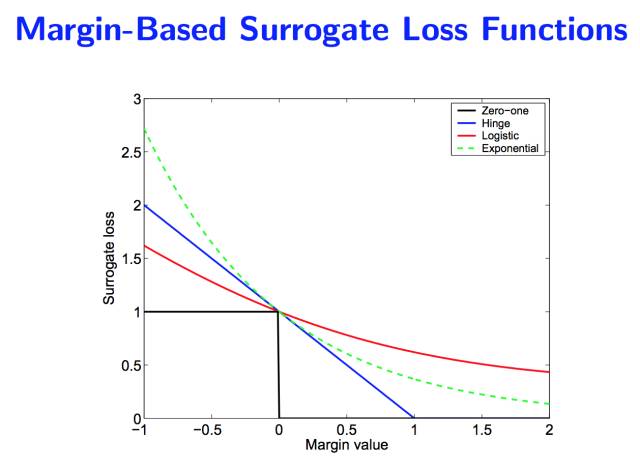
然后把這些損失函數也映射到 f 散度:
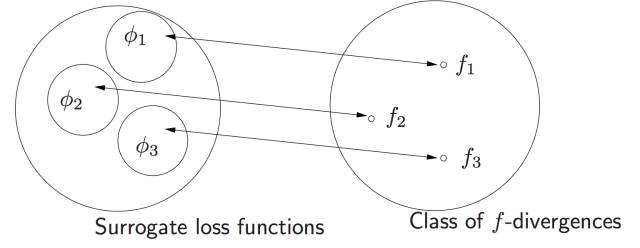
然后微軟的 Sebastian Nowozin, 把 f-散度擴展到GAN “f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization”。

然后對正反KL散度也做了一次統一。
對于 f-散度的理解離不開對Fenchel對偶的理解(參考“走近中神通Fenchel”)。
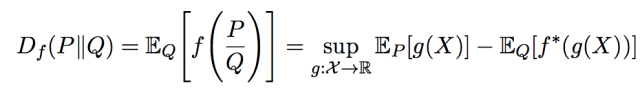
除了f-散度, 還有人基于bregman散度去統一正反KL散度的認知。 KL散度就是香農熵的bregman散度。
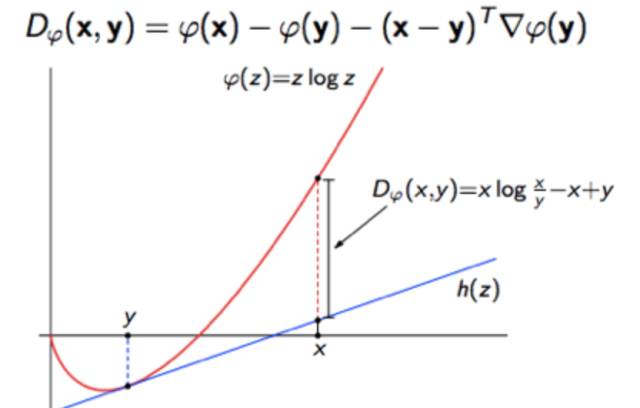
而Bregman散度本身是基于一階泰勒展開的一種偏離度的度量。
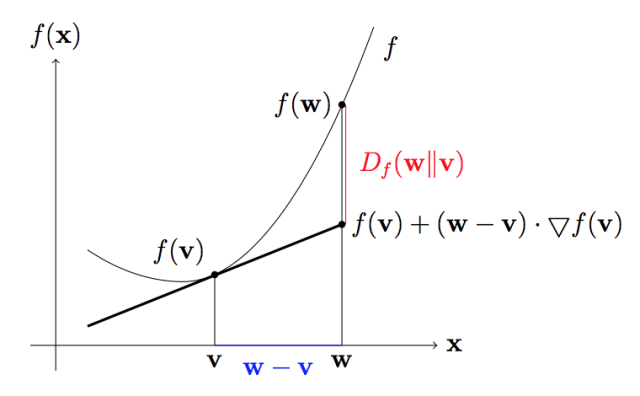
然后再基于Bregman距離去研究最小KL投影, 函數空間采用香農熵(參考“信息熵的由來”)。
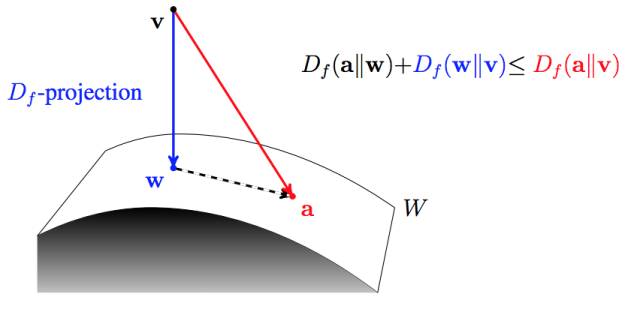
無論f-散度還是bregman散度對正反KL距離的統一, 之后的廣義EM算法, 都會變得空間的最優投影的交替出現。 或許廣義EM算法也成了不同流形空間上的坐標梯度下降算法而已coodinate descent。
如果你理解了這個, 恭喜你, 進入理解EM算法的第九層境界,山水合一。
小結這里淺薄的介紹了理解EM算法的9層境界,托名Hinton和Jordan,著實是因為佩服他們倆和各自的弟子們對EM算法,甚至到無監督深度學習的理解和巨大貢獻。想來Hinton和Jordan對此必定會有更為深刻的理解, 很好奇會到何種程度 。。。 最后依然好奇, 為啥只有他們兩家的子弟能夠不停的突破無監督深度學習?Hinton 老仙說, 機器學習的未來在于無監督學習!
-
JORDAN
+關注
關注
0文章
6瀏覽量
8343 -
EM算法
+關注
關注
0文章
5瀏覽量
7861 -
hinton
+關注
關注
0文章
3瀏覽量
1780
原文標題:EM算法的九層境界:?Hinton和Jordan理解的EM算法
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+介紹基礎硬件算法模塊
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+第九章sigma delta adc閱讀與分享
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+一本介紹基礎硬件算法模塊實現的好書
普中科技HC6800-EM3使用操作手冊

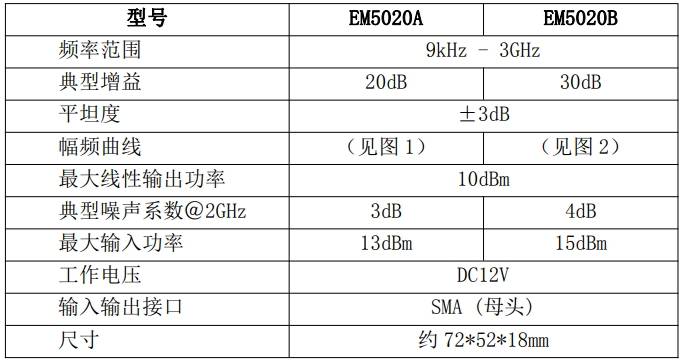
知用EM5020B與EM5020A放大器的對比優勢?
BP神經網絡算法的基本流程包括
德力西變頻器EM6O怎么設定壓力

第二代設計語言首款轎車,領克07 EM-P全球首秀
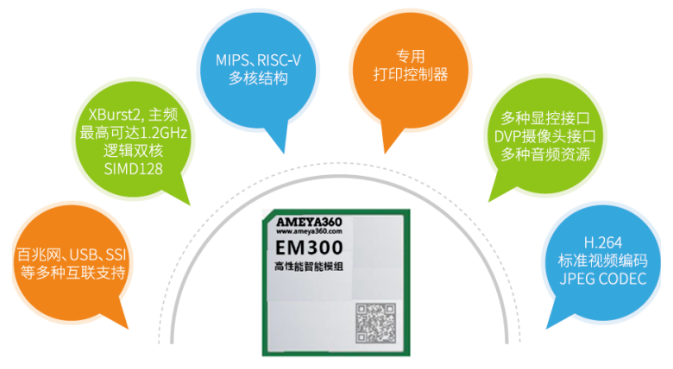
EM300高性能顯示模組產品介紹
知用CYBERTEK近場探頭EM5030E的特征及其應用





 工商網監
工商網監
評論