 對ai3種不同的智商類型提出對應的測試方法和數學公式
對ai3種不同的智商類型提出對應的測試方法和數學公式
前言:本文是未來智能實驗室關于人工智能智商的最新研究文章,主要提出智能系統的智能水平會因為測試目的的不同,產生三種不同的智商類型,針對這三種AI智商,本文也提出對應的測試方法和數學公式。
我們在研究中發現,人類在討論AI的智能發展水平時,需求和目的并不相同,由此在評估AI智商時也會出現差異,第一個目的和需求是評判當前的AI系統(或機器人)是否在智力上超越人類 ,第二個需求和目的是了解一個智能產品在服務人類時,究竟有多么聰明,和要付出多少價格。根據這一關鍵區別,未來智能實驗室提出AI系統應該存在三種智商,分別是通用智商、服務智商和價值智商。
0.背景
伴隨著2016年AlphaGo戰勝人類圍棋冠軍李世石,世界范圍人工智能迅猛發展,人工智能威脅論也因此廣泛傳播,同時智能產品蓬勃發展,不斷涌現。人工智能究竟能不能超越人類?這些智能產品的智能究竟達到什么水平?回答這些問題都需要用定量的方法測試智能系統的發展水平。
從1950年圖靈測試提出以來,科學家已經為人工智能發展的評價體系做了很多工作。1950年,圖靈提出了著名的圖靈實驗,采用提問和人類裁判的方法,判斷一臺計算機是否具有同人相當的智力。作為最被廣泛應用的人工智能測試方法,但圖靈測試并不檢驗Ai的智能發展水平,只是判斷智能系統能否與人類智能相同,而且受人為因素干擾太多,嚴重依賴于裁判者和被測試者的主觀判斷,因此往往有人在沒有得到嚴格驗證的情況下宣稱其程序通過圖靈測試,
2015年3月24日“美國科學院院刊(PNAS)發表一篇論文,提出一種新的圖靈測試方法“Visual Turing test” ,這種測試方法用來對計算機的圖像認知能力進行更為深入的評估。
2014年美國佐治亞技術學院的瑞德教授(Mark O. Riedl)認為,智能的本質在于創造力。他設計了一個叫做Lovelace 2.0 版本的測試。Lovelace 2.0 的測試范圍包括:創作有虛擬故事的小說、詩歌創作、油畫和音樂等。
在解決人工智能定量測試的問題上,包括圖靈測試在內的各種方案還存在兩個問題:第一,這些測試方法沒有形成統一的智能模型,并以此為基礎進行分析,區分智能的多個分類。導致無法將不同的智能系統包括人類進行統一的測試;第二是這些測試方法無法定量分析人工智能,或者只定量分析智能的某個方面,但這個系統究竟達到人類智慧的百分之多少,發展速度與人類智慧發展速度比率如何,這些問題在上述研究中沒有涉及。
針對這些問題,研究團隊提出:根據評測目的的不同,智能系統的智能水平評估存在三種智商,分別是:智能系統的通用智商,服務智商和價值智商。這三種智商的理論基礎,詳細定義和評測方法將在以下內容中做詳細闡述。
1.理論基礎:標準智能系統和擴展的馮諾依曼架構
對智能系統包括人類和人工智能系統的智力能力進行評測面臨兩個重要挑戰:第一,人工智能系統目前沒有形成統一的模型;第二,人工智能系統與以人類為代表的生命體之間的比較目前沒有統一的模型。
針對這一問題,2014年 ,中科院虛擬經濟與數據科學研究中心同時也是未來智能實驗室研究團隊成員,劉鋒,石勇,劉穎參考馮·諾伊曼結構、戴維·韋克斯勒人類智力模型、知識管理領域DIKW模型體系等。提出“標準智能模型”,統一描述人工智能系統和人類的特征和屬性,將任何一個智能體視為一個具有“知識的獲取,掌握,創新和反饋”的系統。
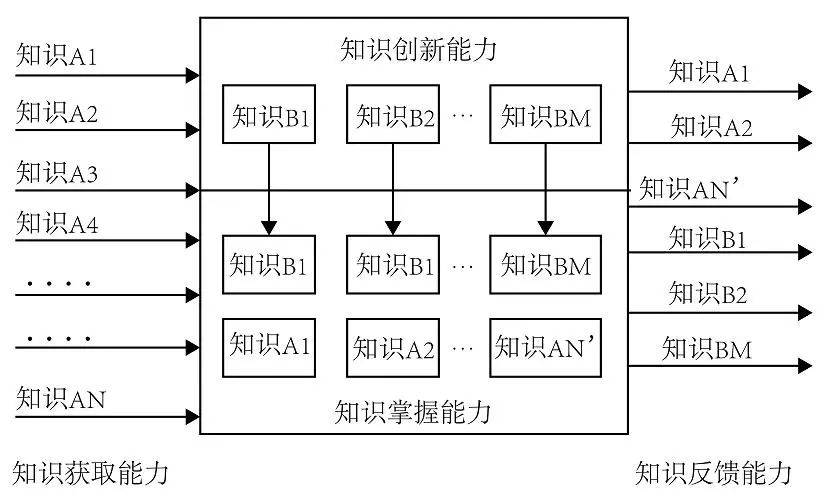
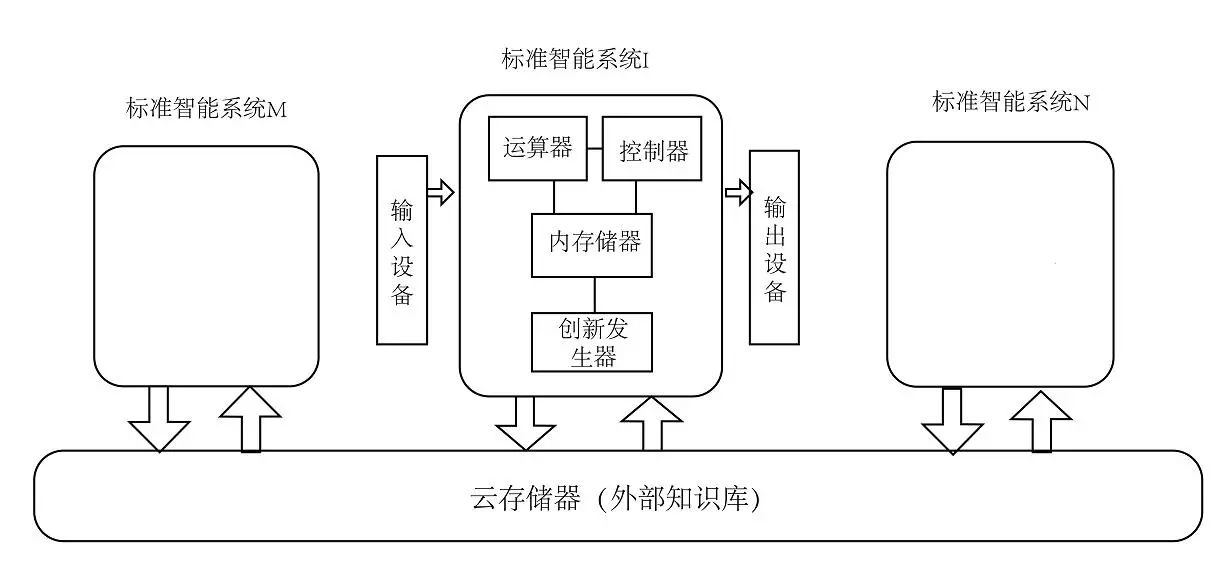
基于這個模型與馮諾依曼架構結合,可以形成擴展的馮諾依曼架構,相比馮諾依曼架構,這個模型增加了創新創造功能,即能夠根據已有的知識,發現新的知識元素和新的規律,使之進入到存儲器,供計算機和控制器使用,并通過輸入/輸出系統與外部進行知識交互。第二個增加的是能夠進行知識共享的外部知識庫或云存儲器,而馮·諾伊曼架構的外部存儲只為單一系統服務。擴展的馮諾依曼架構在構建AI的智商中將起到重要的作用。
2.智能系統三種不同智商的定義
2.1 AI通用智商的提出
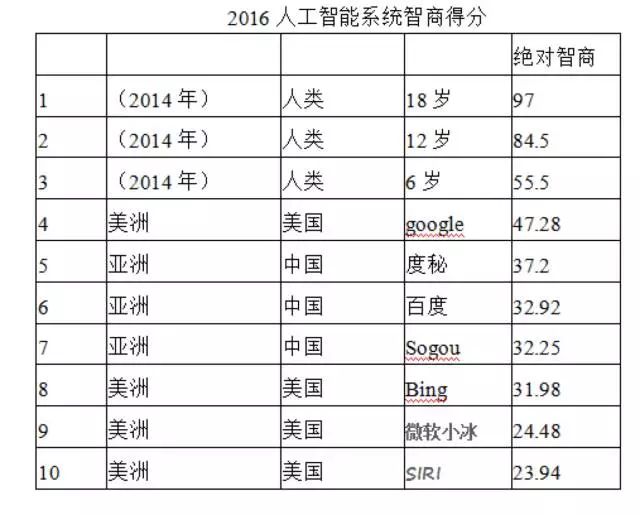
基于標準智能模型,研究團隊建立AI智商測試量表,分別與2014年和2016年對包括谷歌、Siri、百度、Bing等50多個人工智能系統和6歲,12歲和18歲人群進行AI智商測試。從測試結果看,谷歌、百度等人工智能系統的性能比兩年前已有大幅提高,但仍與6歲兒童有一定差距.
應該說上述AI智商測試是為了解決AI能否超越人類智能這個問題而開展的,這個研究是將每一個智能系統包括機器人,AI軟件系統,人類,動物和其他生物當做平等的智能體,觀察其與自然界,其他智能體在交互中顯示出來的智能水平。
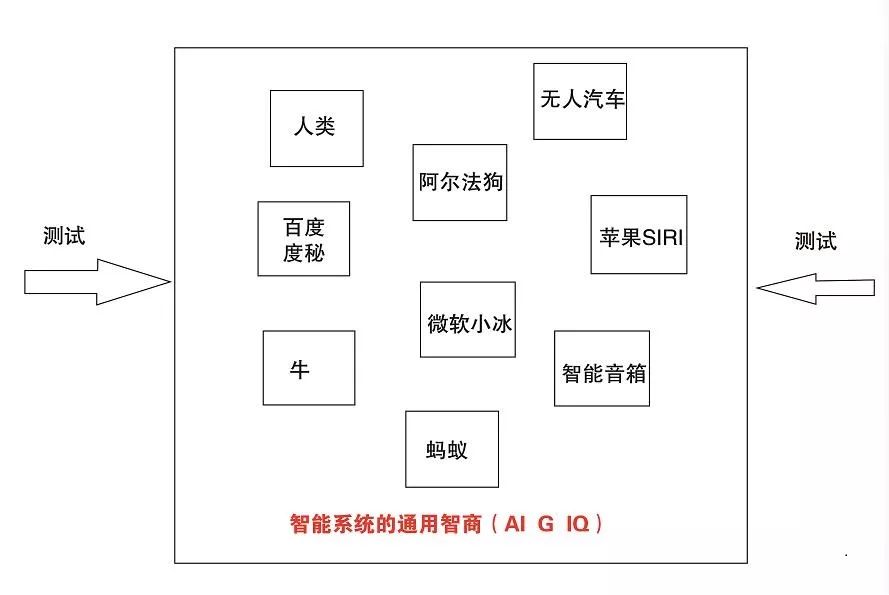
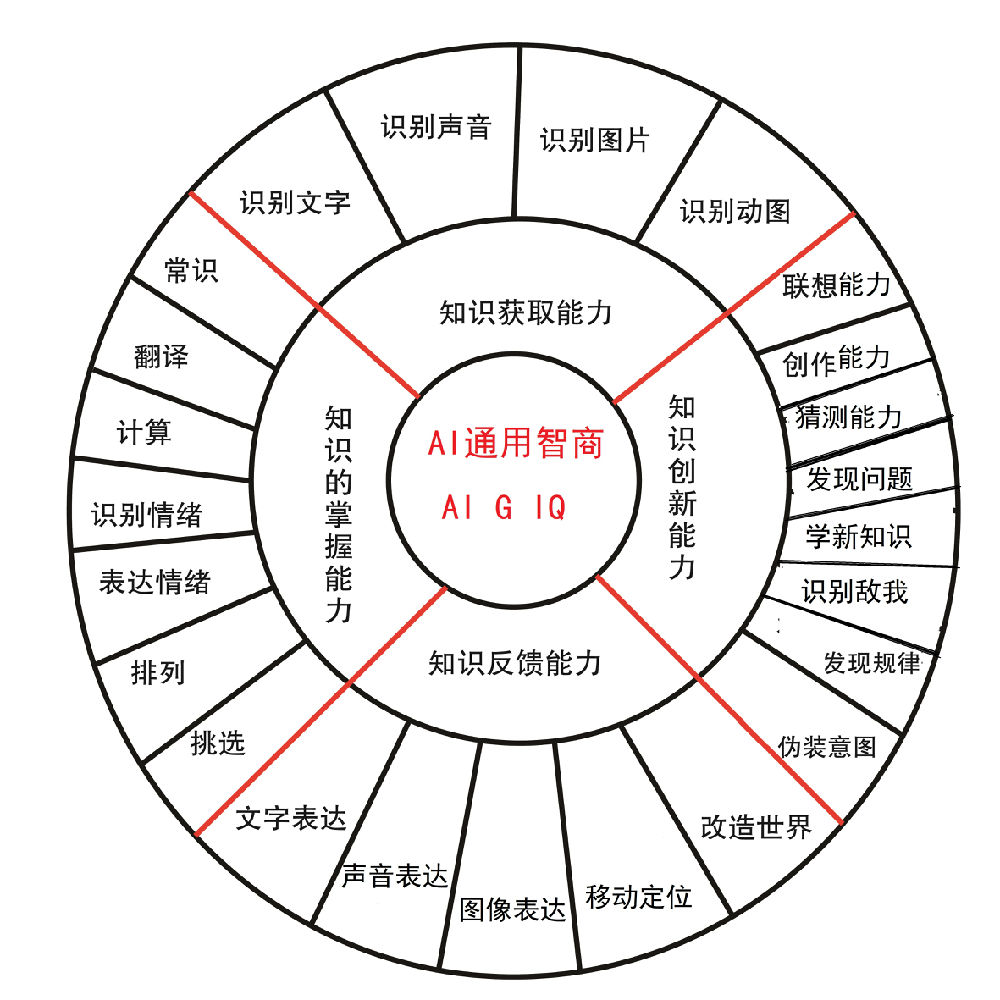
AI通用智商的定義如下:基于標準智能模型,為了解決“評價各智能系統發展水平高低”的問題,將各智能系統視為平等的智能體,通過統一的AI智商測試量表形成的智能評測分數,可以稱為AI系統的通用智商 Artificial intelligence General intelligence quotient (AI G IQ)。
2.2. AI服務智商的提出
在實踐中,我們發現除了少數AI系統的產生是出于科學實驗目的,不為人類提供輔助性服務,其他大多數AI系統是為了更好的服務于人類而被制造出來,它的智能也主要體現在為人類服務的過程中,智能水平越高,也就能更好的為人類提供服務。
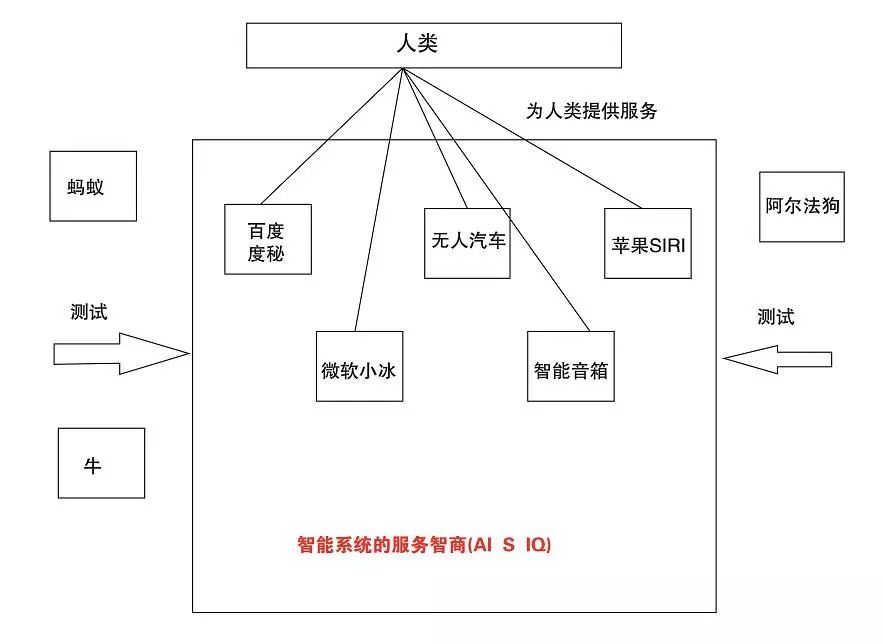
這種情況下,如果用AI的通用智商標準進行評測,就明顯與產品的最初被制造出來的目的有重大差異。這就需要我們根據此類AI系統的特點,基于標準智能模型,選擇與服務相關的指標進行評測,
這些指標與AI的通用智商評測指標有相關性,但又有比較大的差異。包括對人工智能的法律,倫理道德等約束條件也應該放在智能系統服務智商中。而不用放在智能系統的通用智商中。
AI服務智商的定義:基于標準智能模型,為了回答“智能系統如何才是更好的服務于人類”的問題,對智能產品在服務過程中體現的智能水平進行測試,并形成的智能評測分數,可以稱為AI系統的服務智商,Artificial intelligence seveice intelligence quotient (AI S IQ)。
2.3.AI價值智商提出
為人類提供服務或支撐性工作的AI系統,往往會由不同的公司和企業提供相應的智能產品,例如智能音箱就有亞馬遜、百度等品牌,智能聊天機器人包括科大訊飛、蘋果Siri等,由于是由不同企業生產制造,完成相同或相近功能,每個企業的造價或售價也會不同,服務智商與成本或價格關聯會對消費者購買智能產品產生重要的影響。
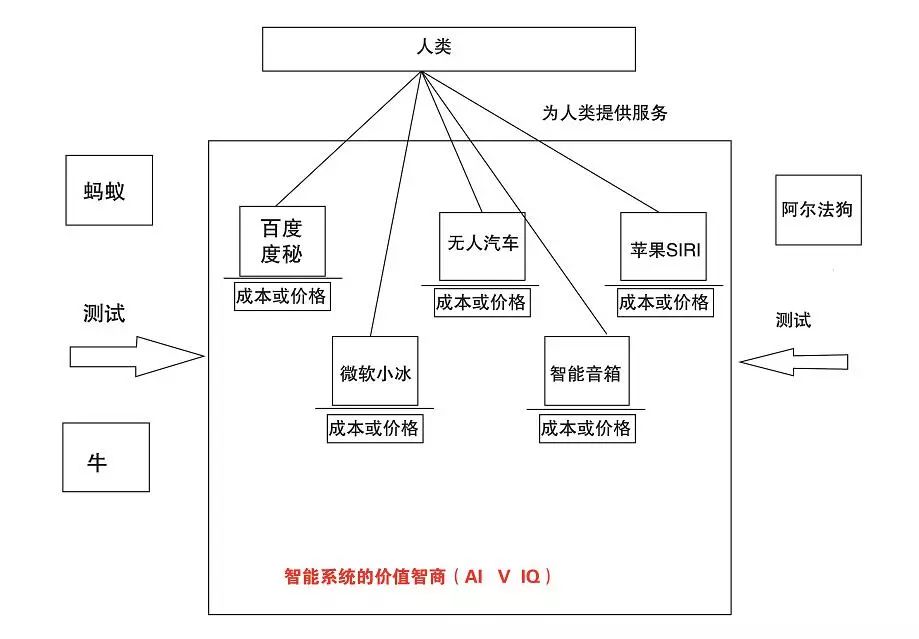
AI價值智商的定義:基于標準智能模型,為了幫助使用者判斷需要用多大經濟代價獲得智能系統的智力能力, 將智能系統的服務智商除以該系統的出售價格,形成的智能評測分數,可以稱為AI系統的價值智商,Artificial intelligence Value intelligence quotient (AI V IQ)。
3.智能系統通用智商和服務智商的測試量表設計。
3.1.智能系統通用智商的測試量表
為了解決AI能否超越人類智慧的問題,2014年開始,本文研究者根據標準智能模型把智能分為“知識的獲取,掌握,創新和反饋”四類能力,在這四類之下又分成15個小分類能力,從更多維度評測AI,人類的智能。這15個小分類是:圖像、文字、聲音的識別和輸出,常識、計算、翻譯、排列,創作、挑選、猜測、發現等能力,每個小分類有不同的權重。
2017年,根據人工智能的發展和對智能的最新研究。研究團隊將AI通用智商評測量表從測試分類和分類權重進行調整,主要調整的內容增加了:1.識別動態圖像的能力,2.情緒的識別與表達能力,3.識別敵我的能力,4.偽裝真實意圖的能力,5.實現移動定位的能力,6.實現改造世界的能力。除此之外對常識和創作的測試也做了更為細化的工作。
令智能系統的通用智商為IQAIG,FGi是二級評價指標項得分,WGi是二級評價指標項的權重,N是評價指標項的個數。因此智能系統的通用智商公式如下:

3.2.智能系統的服務智商測試量表
目前存在大量智能系統,例如聊天機器人,智能化的搜索引擎,智能音箱,智能手機,智能汽車,智能洗衣機,智能冰箱等,它們大部分是作為商品服務于人類的某一需求,這些智能系統可以稱為智能產品。
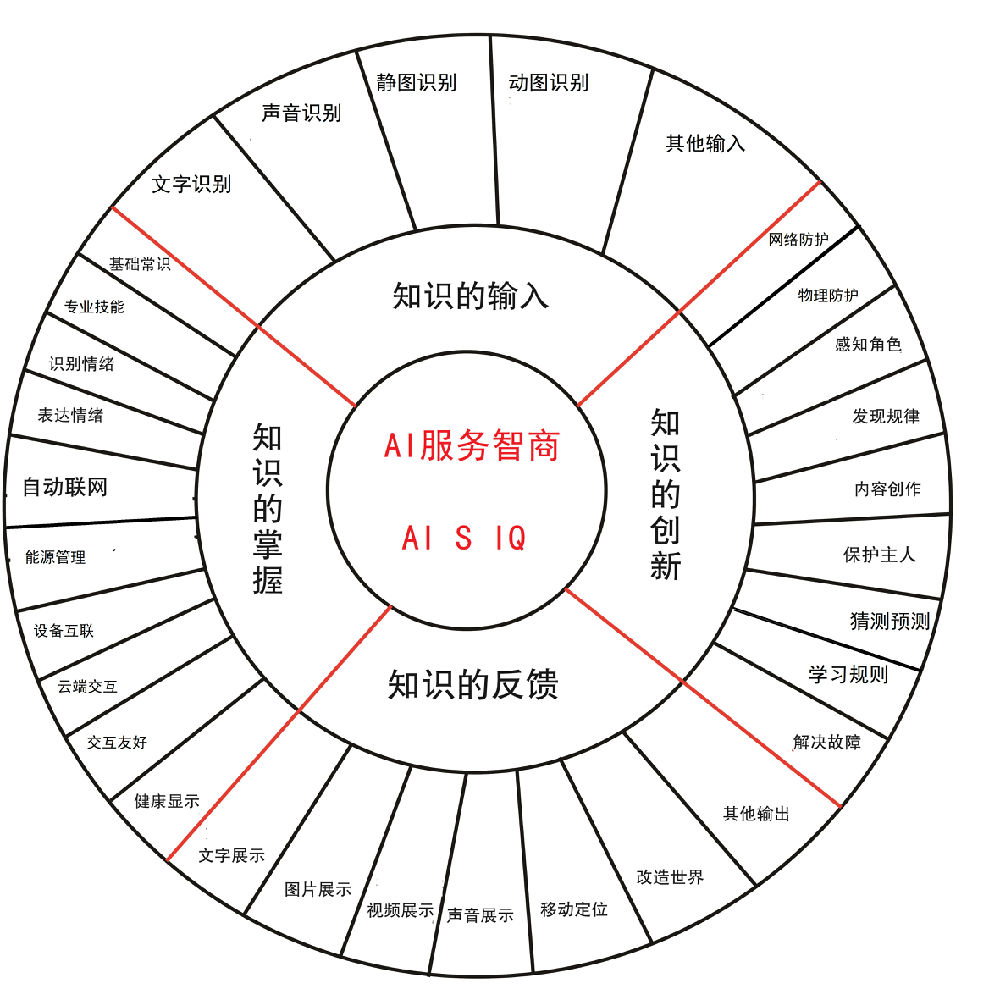
在標準智能系統和擴展的馮諾依曼架構下,提煉他們共同的智能特征,并根據不同的服務需求,形成如下智能系統服務智商的測試量表。在這個服務智商的測試量表中主要突出了以下幾個方面.
1.感知周圍智能系統和使用者身份的能力
2.與互聯網云端交互的能力
3.將自身內部狀況實時顯示給使用者,出現故障給予支持的能力
4.按符合當地法律和倫理道德服務人類的能力
5.危險情況下保護使用者和其他人的能力
6.自身能源使用和自動補充的能力
智能系統的服務智商為IQAIS,FSi是二級評價指標項得分,WSi是二級評價指標項的權重,N是評價指標項的個數。因此智能系統的服務智商公式如下:
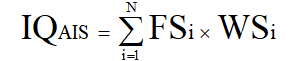
作為一個智能產品服務智商的標準量表,為了盡量全面的覆蓋不同種類的智能產品,在設計智能產品服務智商測試量表時,在測試量表中從知識的獲取,掌握,創新和反饋四個方面為同智能產品留下接口:
-
在知識的獲取分類中增加了”其他”信息輸入方式,用來評估智能產品在知識輸入方面的新方式。
-
在知識的掌握中,增加了“專業常識”,用來評估不同領域智能產品的專業方面技能,
-
在知識的輸出能力中,增加其他輸出能力,用來評估智能產品在知識輸出方面的新方式。
3.3 AI價值智商的形成方法
根據智能系統AI價值智商(AIVIQ)的定義,如果該智能系統通過出售變為產品服務于人類,令智能系統的服務智商為AISIQ,該智能產品的公開售價為P,形成智能系統價值智商的公式如下:
IQAIV=(IQAIS/p)*100
4.總結
通過AI三種智商認為,智能系統根據不同的使用和評測目標,可以有三種不同的智能水平評測方法和由此得出的三種智商:AI通用智商,AI服務智商和AI的價值智商,其中AI的通用智商已在2014年以來的論文中進行深入研究,也通過AI系統和人類的共同評測,分析了谷歌,SiRi,百度等與人類通用智商的差異。
本文新提出的AI服務智商和AI的價值智商為評測智能產品的智能水平提供了理論分析和實現方法。后續工作將基于AI服務智商量表,面向具體的智能產品,如智能音箱,智能手機,智能汽車,智能洗衣機,智能電冰箱等,開展他們的AI通用智商、服務智商和AI價值智商的評測工作。
未來智能實驗室是人工智能學家與科學院相關機構聯合成立的人工智能,互聯網和腦科學交叉研究機構。由互聯網進化論作者,計算機博士劉鋒與中國科學院虛擬經濟與數據科學研究中心石勇、劉穎教授創建。
未來智能實驗室的主要工作包括:建立AI智能系統智商評測體系,開展世界人工智能智商評測;開展互聯網(城市)云腦研究計劃,構建互聯網(城市)云腦技術和企業圖譜,為提升企業,行業與城市的智能水平服務。
-
AI
+關注
關注
87文章
31133瀏覽量
269470 -
人工智能
+關注
關注
1792文章
47425瀏覽量
238962
原文標題:如何測量智能產品的AI智商水平,論AI的三種智商 |未來研究
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
高中數學公式大全
讓你在不看任何數學公式的情況下理解傅里葉分析
FOC有哪些數學公式

數學公式幫助自動駕駛司機規避風險
MathType7.4數學公式編輯器應用程序免費下載
數學公式:可幫助5G網絡有效共享通信頻率
由數學公式和電磁理論分析PCB產品的特性和原理
特性阻抗的數學公式和各種參數詳細概述
基于Transformer與覆蓋注意力機制建模的手寫數學公式識別

高斯如何得到他理論的結果?聊聊高斯概率分布的數學公式





 工商網監
工商網監
評論