 對于谷歌應用傳統的自動語音識別(ASR)系統的解析
對于谷歌應用傳統的自動語音識別(ASR)系統的解析
目前,谷歌的各種語音搜索應用還在使用傳統的自動語音識別(ASR)系統,它包括一個包括聲學模型(AM )、一個發音模型(PM)和一個語言模型(LM),它們都是彼此獨立訓練的,而且需要研究人員在不同數據集上進行手動調試。例如,當聲學模型采集到一些聲波特征,它會參考上下文中的音素,有時甚至是一些無關的音素來生成一系列subword單元預測。之后,發音模型會在手工設計的詞典中為預測音素映射序列,最后再由語言模型根據序列概率分配單詞。
和聯合訓練所有組件相比,這種對各模型進行獨立訓練其實是一種次優的選擇,它會使整個過程更復雜。在過去幾年中,端對端系統開發越來越受歡迎,它們的思路是把這些獨立的組件組合成一個單一系統共同學習,但一個不可忽視的事實是,雖然端對端模型在論文中表現出了一定的希望,但沒人真正確定它們比傳統的做法效果更優。
為了驗證這一點,近日,谷歌推薦了一篇由Google Brain Team發表的新論文:State-of-the-art Speech Recognition With Sequence-to-Sequence Models,介紹了一種新的、在性能上超越傳統做法的端對端語音識別模型。論文顯示,相較于現在最先進的語音識別工具,谷歌新模型的字錯誤率(WER)只有5.6%,比前者的6.7%提升了16%。此外,在沒有任何預測評分的前提下,用于輸出初始字假設的端對端模型在體量上是傳統工具的十八分之一,因為它不包含獨立的語言模型和發音模型。
這個新模型的系統建立在Listen-Attend-Spell(LAS)端到端體系結構上,該結構由3部分組成,其中Listen組件的編碼器和標準聲學模型類似,把時頻語音信號x作為輸入,并用一組神經網絡層將輸入映射為一個高水平的表征henc。Attend接收前者編碼器的輸出,并用henc來學習輸入x和預測subword單元{yn, … y0}之間的對齊。其中每個subword單元通常是字形或詞形。組合,Attend組件將輸出傳輸給Spell組件(解碼器),它類似語言模型,能產生一組預測字詞的概率分布。
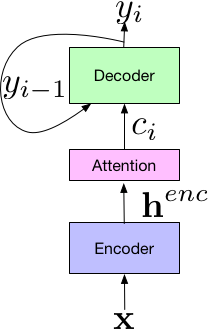
不同于傳統的獨立訓練,LAS的所有組件都在一個單一的端到端神經網絡中聯合訓練,這意味著它更簡單方便。此外,由于LAS是一個徹底的神經網絡,所以它不需要外部增設手工組件,例如有窮狀態轉移機、lexicon或TN模型。最后,LAS不需要像傳統模型一樣用單獨系統生成的決策樹或time alignment來做Bootstrap,它可以在給定文本轉錄和相對應音頻資料的情況下直接訓練。
在論文中,谷歌大腦團隊還介紹他們在LAS中引入各類新穎的結構對神經網絡做了調整,包括改進傳遞給解碼器的attention vector,以及用更長的subword單元對網絡進行訓練(如wordpiece)。他們也用了大量優化訓練方法,其中就有使用最低錯詞率進行訓練。這些創新都是端到端模型較傳統性能提升16%的原因。
這項研究另一個值得興奮的點是多方言和多語言系統,這可能開啟一些潛在應用,由于它是一個經優化的單個神經網絡,模型的簡單性使它獨具吸引力。在LAS中,研究人員可以將所有方言、語言數據整合在一起進行訓練,而無需針對各個類別單獨設置AM、PM和LM。據論文介紹,經測試,谷歌的這個模型在7種英語方言、9種印度語言上表現良好,并超越了對照組的單獨訓練模型。
雖然這個數據結果令人興奮,但這暫時還不是一個真正成熟的工作,因為它還不能實時處理語音,而這是它被用于語音搜索的一個重大前提。此外,這些模型生成的數據和實際數據仍存在不小的差距,它們只學習了22000個音頻文本對話,在語料庫數據積累上遠比不上傳統方法。當面對一些罕見的詞匯時,比如一些人工設計的專業名詞、專有名詞,端到端模型還不能正確編寫。因此,為了讓它們能更實用、適用,谷歌大腦的科學家們未來仍將面臨諸多問題。
-
谷歌
+關注
關注
27文章
6168瀏覽量
105372 -
語音識別
+關注
關注
38文章
1739瀏覽量
112656 -
語音搜索
+關注
關注
0文章
6瀏覽量
7822
原文標題:谷歌大腦發力語音搜索:一個用于語音識別的端到端模型
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
手機語音識別應用中DSP該怎么選擇?
TWEN-ASR ONE 語音識別系列教程(1)——運行第一個語音程序
HarmonyOS開發-語音識別
ASR語音識別技術的介紹應用和優勢及實際案例分析
ASR語音技術的原理以及未來發展趨勢分析
探索自動語音識別技術的獨特應用
什么是自動語音識別(ASR)?如何使用深度學習和GPU加速ASR






 工商網監
工商網監
評論