") 通過(guò)學(xué)習(xí)PPT地址和xgboost導(dǎo)讀和實(shí)戰(zhàn)地址來(lái)對(duì)xgboost原理和應(yīng)用分析
通過(guò)學(xué)習(xí)PPT地址和xgboost導(dǎo)讀和實(shí)戰(zhàn)地址來(lái)對(duì)xgboost原理和應(yīng)用分析
1、背景
關(guān)于xgboost的原理網(wǎng)絡(luò)上的資源很少,大多數(shù)還停留在應(yīng)用層面,本文通過(guò)學(xué)習(xí)陳天奇博士的PPT地址和xgboost導(dǎo)讀和實(shí)戰(zhàn)地址,希望對(duì)xgboost原理進(jìn)行深入理解。
2、xgboost vs gbdt
說(shuō)到xgboost,不得不說(shuō)gbdt。了解gbdt可以看我這篇文章地址,gbdt無(wú)論在理論推導(dǎo)還是在應(yīng)用場(chǎng)景實(shí)踐都是相當(dāng)完美的,但有一個(gè)問(wèn)題:第n顆樹(shù)訓(xùn)練時(shí),需要用到第n-1顆樹(shù)的(近似)殘差。從這個(gè)角度來(lái)看,gbdt比較難以實(shí)現(xiàn)分布式(ps:雖然難,依然是可以的,換個(gè)角度思考就行),而xgboost從下面這個(gè)角度著手

注:紅色箭頭指向的l即為損失函數(shù);紅色方框?yàn)檎齽t項(xiàng),包括L1、L2;紅色圓圈為常數(shù)項(xiàng)。利用泰勒展開(kāi)三項(xiàng),做一個(gè)近似,我們可以很清晰地看到,最終的目標(biāo)函數(shù)只依賴(lài)于每個(gè)數(shù)據(jù)點(diǎn)的在誤差函數(shù)上的一階導(dǎo)數(shù)和二階導(dǎo)數(shù)。
3、原理
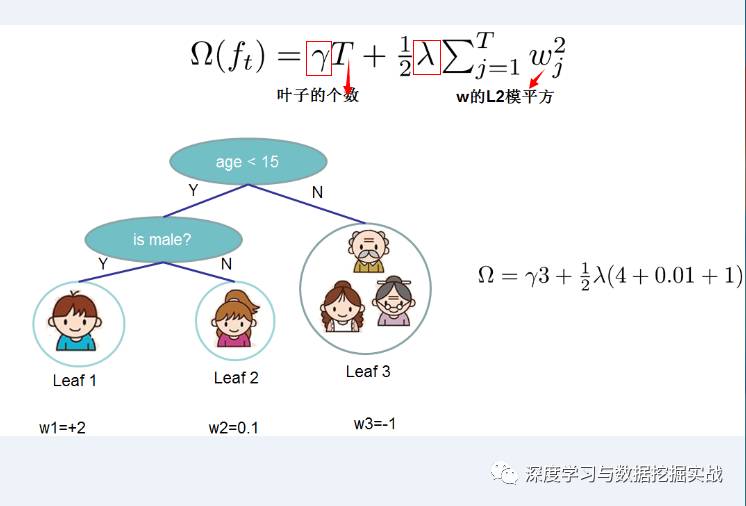
(1)定義樹(shù)的復(fù)雜度對(duì)于f的定義做一下細(xì)化,把樹(shù)拆分成結(jié)構(gòu)部分q和葉子權(quán)重部分w。下圖是一個(gè)具體的例子。結(jié)構(gòu)函數(shù)q把輸入映射到葉子的索引號(hào)上面去,而w給定了每個(gè)索引號(hào)對(duì)應(yīng)的葉子分?jǐn)?shù)是什么。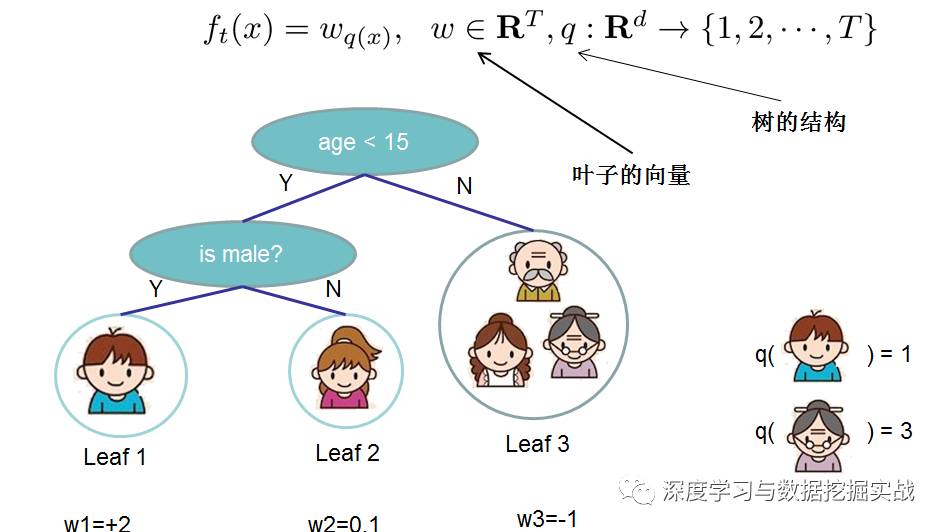
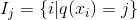
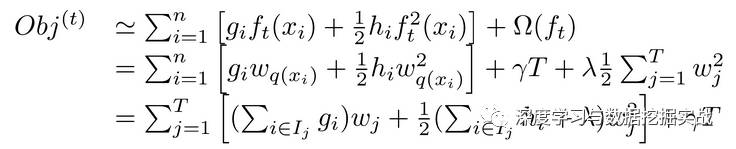
這一個(gè)目標(biāo)包含了TT個(gè)相互獨(dú)立的單變量二次函數(shù)。我們可以定義
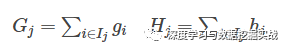
最終公式可以化簡(jiǎn)為
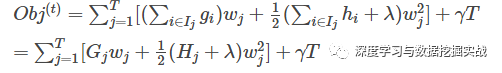
通過(guò)對(duì)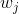
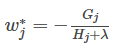
然后把
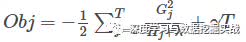
(2)打分函數(shù)計(jì)算示例
Obj代表了當(dāng)我們指定一個(gè)樹(shù)的結(jié)構(gòu)的時(shí)候,我們?cè)谀繕?biāo)上面最多減少多少。我們可以把它叫做結(jié)構(gòu)分?jǐn)?shù)(structure score)
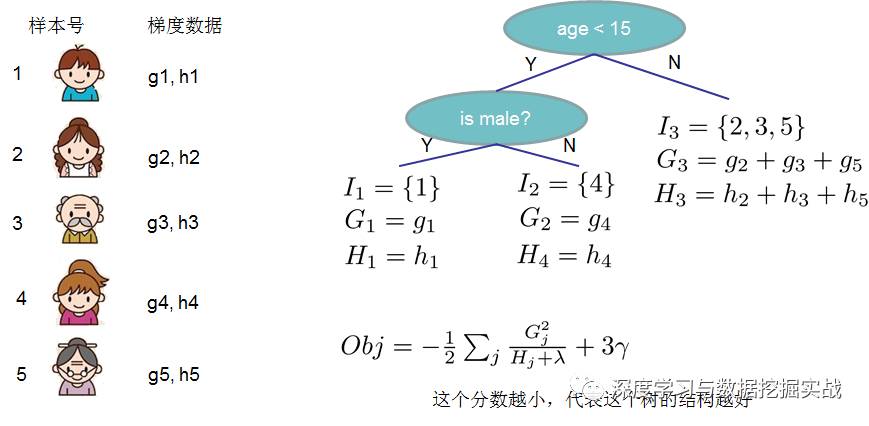
(3)枚舉不同樹(shù)結(jié)構(gòu)的貪心法
貪心法:每一次嘗試去對(duì)已有的葉子加入一個(gè)分割
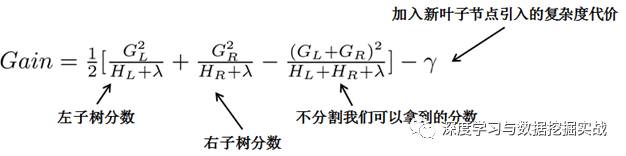
對(duì)于每次擴(kuò)展,我們還是要枚舉所有可能的分割方案,如何高效地枚舉所有的分割呢?我假設(shè)我們要枚舉所有x < a 這樣的條件,對(duì)于某個(gè)特定的分割a我們要計(jì)算a左邊和右邊的導(dǎo)數(shù)和。

我們可以發(fā)現(xiàn)對(duì)于所有的a,我們只要做一遍從左到右的掃描就可以枚舉出所有分割的梯度和GL和GR。然后用上面的公式計(jì)算每個(gè)分割方案的分?jǐn)?shù)就可以了。
觀察這個(gè)目標(biāo)函數(shù),大家會(huì)發(fā)現(xiàn)第二個(gè)值得注意的事情就是引入分割不一定會(huì)使得情況變好,因?yàn)槲覀冇幸粋€(gè)引入新葉子的懲罰項(xiàng)。優(yōu)化這個(gè)目標(biāo)對(duì)應(yīng)了樹(shù)的剪枝, 當(dāng)引入的分割帶來(lái)的增益小于一個(gè)閥值的時(shí)候,我們可以剪掉這個(gè)分割。大家可以發(fā)現(xiàn),當(dāng)我們正式地推導(dǎo)目標(biāo)的時(shí)候,像計(jì)算分?jǐn)?shù)和剪枝這樣的策略都會(huì)自然地出現(xiàn),而不再是一種因?yàn)閔euristic(啟發(fā)式)而進(jìn)行的操作了。
4、自定義損失函數(shù)
在實(shí)際的業(yè)務(wù)場(chǎng)景下,我們往往需要自定義損失函數(shù)。這里給出一個(gè)官方的 鏈接地址
5、Xgboost調(diào)參
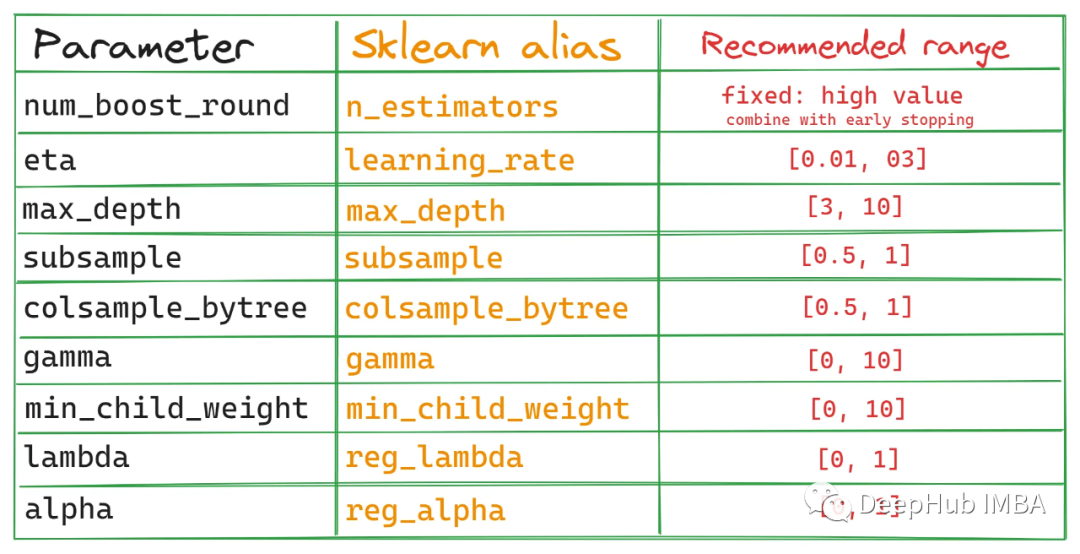
由于Xgboost的參數(shù)過(guò)多,使用GridSearch特別費(fèi)時(shí)。這里可以學(xué)習(xí)下這篇文章,教你如何一步一步去調(diào)參。地址
6、python和R對(duì)xgboost簡(jiǎn)單使用
任務(wù):二分類(lèi),存在樣本不均衡問(wèn)題(scale_pos_weight可以一定程度上解讀此問(wèn)題)
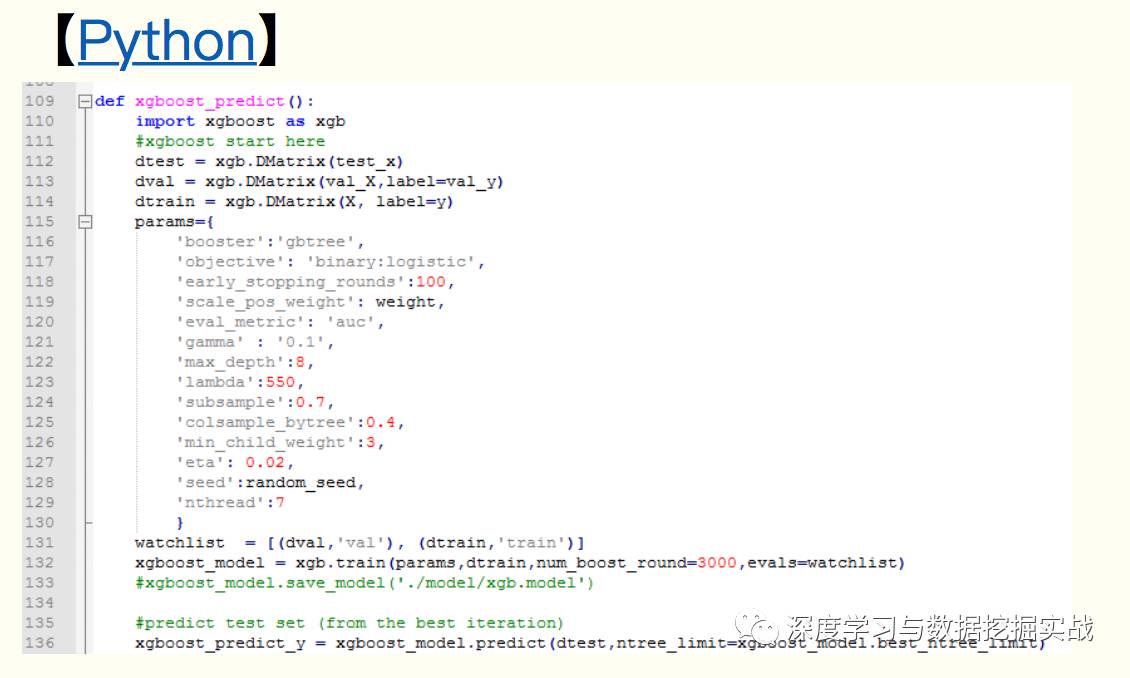
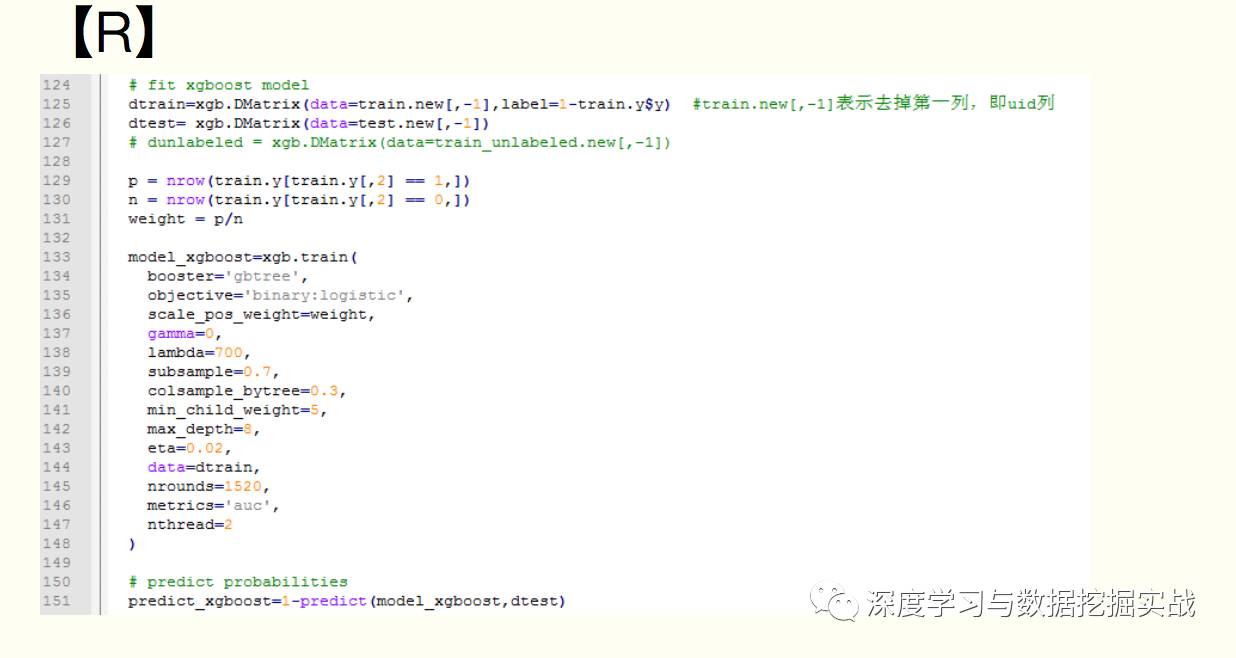
7、Xgboost中比較重要的參數(shù)介紹
(1)objective [ default=reg:linear ] 定義學(xué)習(xí)任務(wù)及相應(yīng)的學(xué)習(xí)目標(biāo),可選的目標(biāo)函數(shù)如下:
-
“reg:linear” –線性回歸。
-
“reg:logistic” –邏輯回歸。
-
“binary:logistic” –二分類(lèi)的邏輯回歸問(wèn)題,輸出為概率。
-
“binary:logitraw” –二分類(lèi)的邏輯回歸問(wèn)題,輸出的結(jié)果為wTx。
-
“count:poisson” –計(jì)數(shù)問(wèn)題的poisson回歸,輸出結(jié)果為poisson分布。 在poisson回歸中,max_delta_step的缺省值為0.7。(used to safeguard optimization)
-
“multi:softmax” –讓XGBoost采用softmax目標(biāo)函數(shù)處理多分類(lèi)問(wèn)題,同時(shí)需要設(shè)置參數(shù)num_class(類(lèi)別個(gè)數(shù))
-
“multi:softprob” –和softmax一樣,但是輸出的是ndata * nclass的向量,可以將該向量reshape成ndata行nclass列的矩陣。沒(méi)行數(shù)據(jù)表示樣本所屬于每個(gè)類(lèi)別的概率。
-
“rank:pairwise” –set XGBoost to do ranking task by minimizing the pairwise loss
(2)’eval_metric’ The choices are listed below,評(píng)估指標(biāo):
-
“rmse”: root mean square error
-
“l(fā)ogloss”: negative log-likelihood
-
“error”: Binary classification error rate. It is calculated as #(wrong cases)/#(all cases). For the predictions, the evaluation will regard the instances with prediction value larger than 0.5 as positive instances, and the others as negative instances.
-
“merror”: Multiclass classification error rate. It is calculated as #(wrong cases)/#(all cases).
-
“mlogloss”: Multiclass logloss
-
“auc”: Area under the curve for ranking evaluation.
-
“map”:Mean average precision
-
“ndcg@n”,”map@n”: n can be assigned as an integer to cut off the top positions in the lists for evaluation.
-
“ndcg-“,”map-“,”ndcg@n-“,”map@n-“: In XGBoost, NDCG and MAP will evaluate the score of a list without any positive samples as 1. By adding “-” in the evaluation metric XGBoost will evaluate these score as 0 to be consistent under some conditions.
(3)lambda [default=0]L2 正則的懲罰系數(shù)
(4)alpha [default=0]L1 正則的懲罰系數(shù)
(5)lambda_bias在偏置上的L2正則。缺省值為0(在L1上沒(méi)有偏置項(xiàng)的正則,因?yàn)長(zhǎng)1時(shí)偏置不重要)
(6)eta [default=0.3]為了防止過(guò)擬合,更新過(guò)程中用到的收縮步長(zhǎng)。在每次提升計(jì)算之后,算法會(huì)直接獲得新特征的權(quán)重。 eta通過(guò)縮減特征的權(quán)重使提升計(jì)算過(guò)程更加保守。缺省值為0.3取值范圍為:[0,1]
(7)max_depth [default=6]數(shù)的最大深度。缺省值為6 ,取值范圍為:[1,∞]
(8)min_child_weight [default=1]孩子節(jié)點(diǎn)中最小的樣本權(quán)重和。如果一個(gè)葉子節(jié)點(diǎn)的樣本權(quán)重和小于min_child_weight則拆分過(guò)程結(jié)束。在現(xiàn)行回歸模型中,這個(gè)參數(shù)是指建立每個(gè)模型所需要的最小樣本數(shù)。該成熟越大算法越conservative取值范圍為: [0,∞]
-
python
+關(guān)注
關(guān)注
56文章
4801瀏覽量
84878 -
GBDT
+關(guān)注
關(guān)注
0文章
13瀏覽量
3907
原文標(biāo)題:數(shù)據(jù)科學(xué)家工具箱|xgboost原理以及應(yīng)用詳解
文章出處:【微信號(hào):DatamingHacker,微信公眾號(hào):深度學(xué)習(xí)與數(shù)據(jù)挖掘?qū)崙?zhàn)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何通過(guò)XGBoost解釋機(jī)器學(xué)習(xí)
PyInstaller打包xgboost算法包等可能出現(xiàn)問(wèn)題是什么
基于xgboost的風(fēng)力發(fā)電機(jī)葉片結(jié)冰分類(lèi)預(yù)測(cè) 精選資料分享
基于xgboost的風(fēng)力發(fā)電機(jī)葉片結(jié)冰分類(lèi)預(yù)測(cè) 精選資料下載
ATM地址,ATM地址是什么意思
面試中出現(xiàn)有關(guān)Xgboost總結(jié)
XGBoost號(hào)稱(chēng)“比賽奪冠的必備大殺器”,橫掃機(jī)器學(xué)習(xí)競(jìng)賽罕逢敵手
XGBoost原理概述 XGBoost和GBDT的區(qū)別
基于遺傳算法和隨機(jī)森林的XGBoost改進(jìn)方法
在幾個(gè)AWS實(shí)例上運(yùn)行的XGBoost和LightGBM的性能比較
XGBoost超參數(shù)調(diào)優(yōu)指南
XGBoost 2.0介紹
詳解XGBoost 2.0重大更新!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論