 深入解讀 PaddlePaddle EDL
深入解讀 PaddlePaddle EDL
百度和 CoreOS 的聯合開發的 PaddlePaddle Elastic Deep Learning(EDL)技術可以把一個機群的利用率提高到接近100%,而基于HPC的一般深度學習機群的使用率往往低于10%。本文作者調研了設計文檔和源碼,訪問了EDL的主要設計者王益,并且在Playground的機群上部署了 EDL,以深度解讀PaddlePaddle Elastic Deep Learning技術。
最近看到 Kubernetes 官方博客上發表特邀文章,介紹了百度和 CoreOS 的聯合開發的 PaddlePaddle Elastic Deep Learning(EDL)技術。文中試驗表明這套技術可以把一個機群的利用率提高到接近100%。要知道基于HPC的一般深度學習機群的使用率往往低于10%。而機群成本是很高的。這樣讓一份投資收獲多倍效益的技術可能讓一家公司的計算投資每年減少數百萬美元,很吸引在AI領域奮斗的團隊。
可惜上文很簡短。為了深入了解 PaddlePaddle EDL,我調研了設計文檔和源碼,訪問了EDL的 主要設計者王益,并且在Playground的機群上部署了EDL。
一般云端的機器學習訓練任務會包含幾個master進程,一些參數服務(parameter server)進程 ,和比較多的訓練進程(training process)。這些進程全部運行在云端機器集群里,有時需要和其它訓練任務共享計算資源,經常還需要和其它的云端服務(比如web服務)共享資源。理想的狀態是機器學習訓練系統知道根據集群資源使用情況和各個任務的優先級動態地調整參數服務 進程和訓練進程的個數,從而達到充分地利用集群CPU/GPU的目的。而這正是Elastic Deep Learning (EDL) 系統的設計目標。
EDL和HPAHorizontal Pod Autoscaling (HPA)是Kubernetes提供的一種彈性調度機制。它的出發點是通過公平分配計算資源給某一個單一的計算任務中的各個Pod來實現分布式系統資源針對單一任務的最優化利用。在“訓練深度學習模型”這個場景下,“某一個單一的計算任務”可能是訓練一個識別圖 像中物體的模型,而另一個“單一的訓練任務”可能是訓練一個語音識別系統。這兩個訓練任務可 能都需要部署在同一個集群里,部署時間有先后,對資源的需求也有不同。理想的情況是 autoscaling controller對每一個這樣的訓練任務所需的系統資源有一個全局的了解,然后按需分配 資源。可是HPA controller并沒有對不同訓練任務有那樣一個全局了解。
另一方面,HPA的彈性調度是針對同種類型的計算任務(homogenous computing task)下的 Pods。但是深度學習系統里的training process和parameter server往往是在不同類型的Pods里 的。我們想要autoscale不同種類的Pods。 這些深度學習訓練系統特有的需求導致使用Kubernetes的時候需要有特定的彈性調度解決方案, 而不能直接采用HPA。而這套特定的解決方案就是本文討論的PaddlePaddle EDL。
PaddleEDL 的設計和實現1.讓Kubernetes支持定制的彈性調度機制
1)配置文件
Kubernetes本身就支持定制的資源管理機制。用戶可以通過提交定制的resource declaration file 和controller file來實現對某種Pods的彈性調度。以下圖為例,這個training_job.yaml保證了 controller會自動監管pservers,并且保證它們的數量在min-instance和max-instance之間。


在Kubernetes集群上,這個定制的資源可以通過kubectl create -f training_job.yaml 命令獲得。接下來,我們需要有個定制的trainingjobcontroller來調度這個資源。
定制的training job controller跑在一個Pod里,對集群資源有一個統一的了解,它通過Kubernetes API對集群資源起到監控和調度的作用。下圖是training job controller配置文件的一個例子。

在Kubernetes集群上,這個定制的資源管理Pod可以通過 kubectl create -f training_job_controller.yaml 命令啟動。
2)控制程序的實現
上面提到的定制化資源在Kubernetes里面目前有兩種實現方式。一種是 Custom Resource Definition (CRD) ,由Kubernetes 1.7版本引入;另一種是 Third Party Resource (TRP) ,自Kuberenets 1.2版本引入,1.8版本中過時(deprecated),1.9版本中將不再支持。 PaddlePaddle項目現在用的是Kubernetes 1.6版本,所以實現的是TRP模式,今后將整合CRD模 式。
當前PaddlePaddle假設只有一個單獨的training job controller在運行。(后續工作可能會考慮多個 controller運行的情況,比如根據某個leader selection機制來管理多個controller)
當前的training job controller依照下面的邏輯管理資源:

彈性調度算法
PaddlePaddle根據定制資源的配置文件(training_job.yaml)來判斷某個job需不需要彈性調度, 而判斷的標準是trainer和pserver的min-instance =/ max-instance。(當前PaddlePaddle只支持 trainer的彈性調度,還不支持pserver的彈性調度)
集群中GPU的調度
controller知道集群中一共有多少個GPU,當前有多少個閑置的GPU,并試圖把閑置的GPU全部 分配給當前的訓練任務。PaddlePaddle給需求GPU的訓練任務定義一個“滿足程度”的評分( fulfillment score),此評分的范圍是[0,1]。PaddlePaddle會優先分配GPU資源給滿足程度評分最低的訓練任務。如果有分數相同的情況,則分別優先考慮GPU需求數,CPU需求數,內存需求數。如果有某個訓練任務的GPU min-instance沒有滿足(除非cur-instance=min-instance),那么PaddlePaddle會把一個滿足程度最高分的訓練任務里的GPU資源拿出來分給它。如果滿足程度分數最高的訓練任務cur-instance=min-instance,則整個集群不再執行新的訓練任務,新來的任務需等待。
集群中CPU的調度
CPU資源的分配和GPU思路相同。controller知道集群中一共有多少個CPU,內存,它們的負載情況;同時也知道訓練任務對CPU的需求。同樣的,CPU資源根據滿足程度評分被按需分配。
2.讓PaddlePaddle支持容錯
這里討論PaddlePaddle的容錯機制。原則上,在一個分布式訓練任務里,如果master進程或者所 有的參數服務進程都死掉了,那么整個訓練任務會被停掉,過一段時間被Kubernetes整個重啟。 否則如果具體訓練進程沒有都死掉,則整個訓練任務繼續。我們來看看PaddlePaddle的錯誤恢復機制。
PaddlePaddle用etcd來記錄訓練進程的狀態。etcd是高可靠性的分布式key-value存儲,訓練進程會定時把自身狀態寫進etcd,而這些信息將會在必要的時候用來恢復訓練進程。具體過程如下圖:

Master進程
當master進程被Kubernetes啟動時,它進行如下操作:
1. 從etcd中取一個唯一的master lock,以此避免多個master實例存在
2. 查看etcd中是否存在任務隊列。如果不存在,則新建一個任務隊列;否則得到這個任務隊列中的信息
3. 把自身的ip地址寫進etcd中/master/addr 這個key中,便于后來的訓練進程和自己通信
4. 開端口監聽訓練進程的任務需求,如果收到來自訓練進程的任務請求,從任務隊列中取任務分配之,并且更新任務隊列。
如果master進程因為任何原因死掉了,Kubernetes會將它重啟,從被重啟到獲取etcd的信息,獲取訓練進程的任務,這個過程一般是幾分鐘。
訓練進程
當訓練進程被Kubernetes啟動時,它進行如下操作:
1. 查看etcd中包含參數服務前綴 /ps/ 獲取當前參數服務進程的數量并等待,直到該數量達到配置文件中的要求
2. 從etcd的/master/addr key中獲取master進程地址
3. 向master發起任務請求,根據任務開始訓練程序
當訓練進程死掉之后,Kubernetes會將它重啟,新起來的進程會重復上述工作直到開始新的訓練工作。
參數服務進程
當參數服務進程被Kubernetes啟動時,它進行如下操作:
1. 從etcd /ps_desired中讀取訓練任務所需求的參數服務進程個數
2. 在etcd /ps/
在etcd里創建這個entry,以此作為自身的id。(如下圖所示)
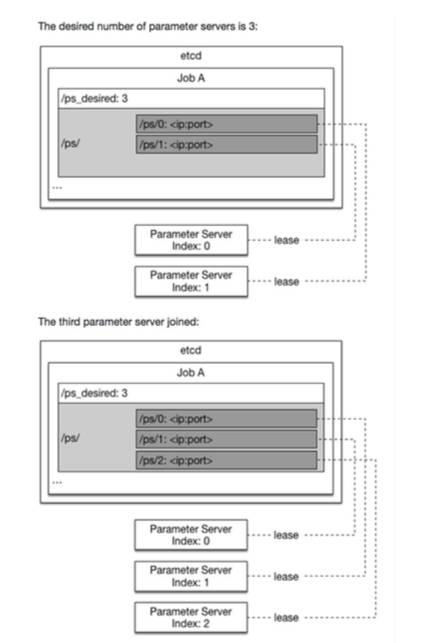
3. 參數服務進程會從自身對應的etcd path中找到已有的訓練結果參數并且將它讀入
4. 參數服務進程開始接收來自訓練進程的請求。
Paddle EDL 和 KubeFlow開源社區中另一個和Kubernetes緊密結合的深度學習系統自然是和Kubernetes同樣來自Google 的TensorFlow。近期,Google開源了KubeFlow項目,旨在利用Kubernetes調度Tensorflow,完成大規模訓練任務。
從設計理念和實現思路來看,Paddle EDL和KubeFlow有非常多的相似之處。從開源的時間來看 ,二者也是同一時段,百度和谷歌的工程師對同一主題的幾乎一樣的理解。不過二者的確存在一些差別。
首先,KubeFlow目前只支持Tensorflow,而Paddle EDL目前只支持PaddlePaddle。而它們底層都依托于Kubernetes。Paddle EDL似乎對Kubernetes的整合更深入一些,比如利用可定制的資源分配方式,和自定義邏輯與Kubernetes API交互。而KubeFlow似乎直接使用Kubernetes一般性的 功能。因此,在彈性調度這個功能上,PaddlePaddle采取的是前文討論的EDL方式,而 KubeFlow現在是HPA方式。這是二者最大的不同。
另外,雖然二者都支持一般的Kubernetes+docker環境,KubeFlow和Google在深度學習生態系 統中的其它開源項目一樣,非常推崇在GCE上布署,深度整合Google云服務。而Paddle EDL并沒有強調布署云的供應商服務。
由于Paddle EDL和KubeFlow都是剛剛開源的項目,更多的細節還在演化當中,我相信開源社區對它們的使用和理解會不斷加深的。不過有一點可以肯定,Kubernetes和深度學習系統的結合將會越來越緊密,一個抽象層的,和Kubernetes API結合更緊密的,可調度不同后端訓練系統(不 再綁定Tensorflow或者PaddlePaddle)的項目也許正在孕育中。
-
cpu
+關注
關注
68文章
10882瀏覽量
212243 -
gpu
+關注
關注
28文章
4754瀏覽量
129080 -
HPA
+關注
關注
1文章
9瀏覽量
8354 -
paddle
+關注
關注
0文章
4瀏覽量
2019 -
edl
+關注
關注
0文章
4瀏覽量
2014
原文標題:一文讀懂百度PaddlePaddle EDL技術
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
中斷和EVAL_6EDL7141_TRAP_1SH之間是否存在優先級關系?
XMC-6EDL_SPI_LINK為什么無法模擬XMC7100芯片?
CC80-CC83配置為EA PWM,當EVAL_6EDL7141_TRAP_1SH事件發生并恢復時,會出現50ns的脈沖如何消除?
如何正確初始化EVAL_6EDL7141_TRAP_1SH函數,使其不會在開始時觸發?
TC397收到EVAL_6EDL7141_TRAP_1SH 3上下文管理EVAL_6EDL7141_TRAP_1SH錯誤怎么解決?
PaddlePaddle Fluid版本的PaddlePaddle如何保存模型
PaddlePaddle Fluid版PaddlePaddle加載圖像數據出錯解決方案
RV1126 PaddlePaddle編譯環境的搭建
基于paddlepaddle的mnist手寫數字識別的詳細分析

新品 | 6EDL04x065xR 和 6EDL04N03PR 系列三相柵極驅動器

新品 | 6EDL04x065xT 系列三相柵極驅動器





 工商網監
工商網監
評論