 軟件設計哲學 于延保代碼改造中的實踐
軟件設計哲學 于延保代碼改造中的實踐
作者:京東保險 王奕龍
本文主要給大家分享軟件設計中的兩個理念,為什么我稱軟件設計是“理念”而不是“方法”或“原則”呢?這個想法主要受《A philosophy of software design》的影響,它將軟件設計稱為“哲學”,而哲學本身沒有嚴格的定論,同樣地,我覺得軟件設計是每個開發者的理念,相同功能的迭代,往往會有不同的看法或思想,也所謂每個人的代碼風格,所以本次分享不求同,只求能給大家帶來一點啟發。兩個理念如下:
沒有一蹴而就的設計:軟件設計不會停止,需要隨著功能迭代(增量開發)更新現有設計,因為在迭代過程中相關開發、業務經驗不斷累積,必然會產生更好的設計方式,最初的設計通常不是最好的
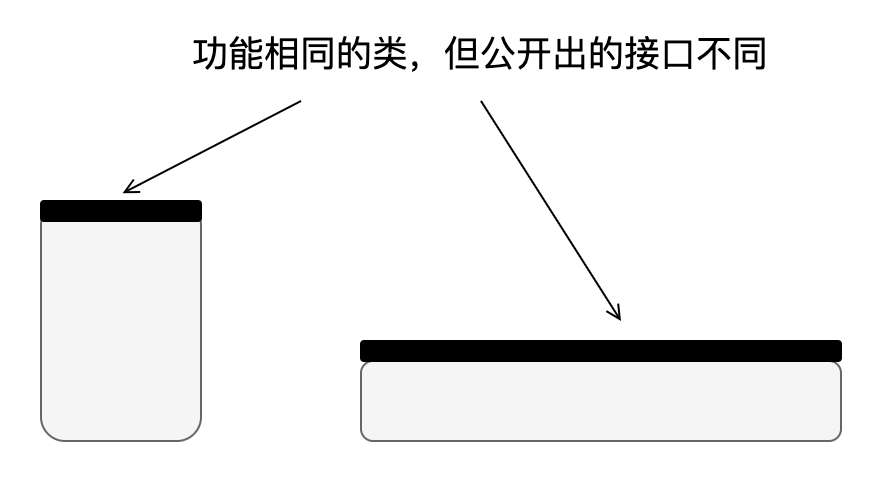
堅持“深”模塊設計:“深”這個觀點來自 《A philosophy of software design》,它將每個模塊看作一個矩形,如下圖所示:
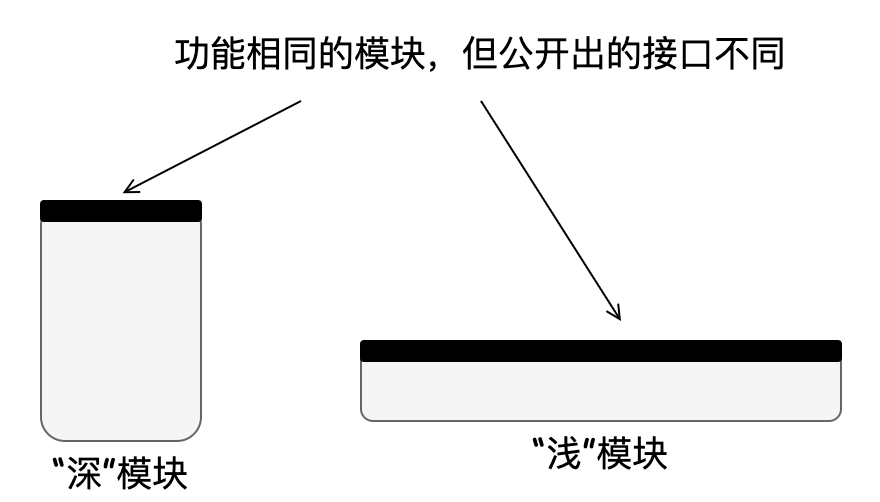
矩形的面積代表模塊提供的功能,頂部邊緣代表模塊公開出的接口,邊緣長度代表接口的復雜性,越長接口越復雜。設計較好的模塊比較深,因為它在簡單的接口后隱藏了許多功能,其內部的復雜性只有一小部分對開發者可見。堅持深模塊設計也就意味著提供調用簡單但功能強大的接口。
這兩個理念,我想通過實際的業務開發:延保補購功能迭代來敘述,在開始之前我想先給大家簡單介紹一下什么是延保的補購:
延保補購是購買商品時未購買延保,事后再為該商品購買延保的行為。比如雙十一購買了一部手機,期望能用五年,但是下單時,沒有一起購買延保,之后再去補購 “五年只換不修” 的延保便是延保的補購。
目前在京東商城“延保服務”頻道頁能進行補購,大家可以在商城搜索 “延保”點擊“京東延保”跳轉:
業務邏輯介紹
為方便大家理解,我將其中的邏輯做了一些簡化,在查詢用戶可補購的訂單時,它會執行如下邏輯:
/** * AddBuy 作為補購的代碼命名定義,定義補購相關門面接口 */ public class AddBuyFacadeServiceImpl implements AddBuyFacadeService { // 補購相關訂單查詢 Service @Resource private AddBuyOrderQueryService orderQueryService; // 補購相關延保查詢 Service @Resource private AddBuyYbQueryService ybQueryService; // 延保結果構建 Service @Resource private AddBuyBuildService buildService; /** * 查詢多條可補購延保的訂單信息 */ @Override public List queryList(AddBuyListRequest req) { // 1. 查詢主商品訂單 OrderInfoRequest orderInfoRequest = new OrderInfoRequest(); orderInfoRequest.setUserNo(req.getUserNo()); // ... List orderInfoList = orderQueryService.listOrderInfo(orderInfoRequest); // 2. 查詢這些訂單可購買的延保信息 YbInfoRequest ybInfoRequest = new YbInfoRequest(); ybInfoRequest.setUserNo(req.getUserNo()); // ... // key: orderNo value: ybInfoList Map> orderNoYbListMap = ybQueryService.listYbInfo(ybInfoRequest); // 3. 封裝訂單和推薦延保信息 return buildService.buildRecommendInfo(orderInfoList, orderNoYbListMap); } }
執行步驟如下:
先查詢主商品訂單
查詢這些訂單可購買的延保信息
封裝訂單和推薦延保信息
補購功能會被推廣到很多不同的 渠道 使用,渠道指的是補購功能推廣的范圍,包括微信(WEI_XIN)和PLUS客服推廣(PLUS)等等:
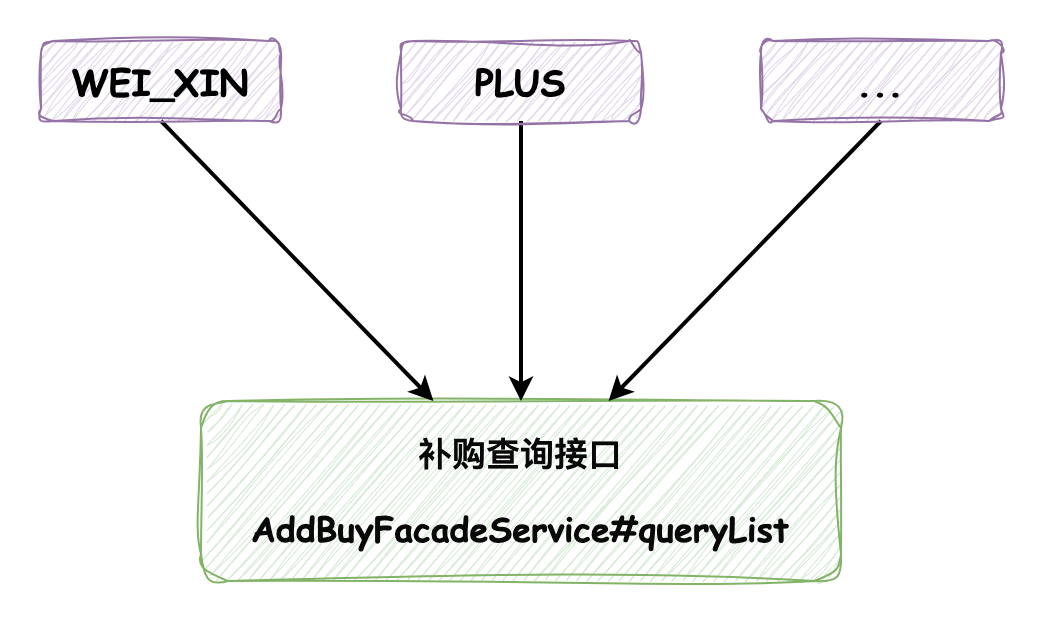
這個渠道值會在查詢做標記,如下所示為補購查詢請求對象 AddBuyListRequest:
public class AddBuyListRequest { private String userNo; // 渠道值信息 private String channel; // ... }
功能迭代
初期功能并沒有針對渠道參數做校驗和管理,也就是說前端傳什么后端就接什么,導致出現了異常的XXX未知渠道。為了對渠道進行管控,并根據現有渠道做個性化補購,現在便需要在此基礎上迭代“渠道管控”的功能:
渠道值校驗:校驗未知的渠道值,對現有渠道進行管理
個性化補購:指定渠道查詢 固定品類 的延保等定制化邏輯,比如規定渠道 “PLUS” 渠道只能查詢 “手機” 品類的延保
為滿足功能,首先定義 ChannelConfig 渠道配置類,其中包含如下字段:
public class ChannelConfig { /** * 渠道 */ private String channel; /** * 要查詢的主品一級類目編碼 */ private List mainFirstCategoryCodeList; // ... }
初版設計
初版設計時,定義 channelConfigMap 以 key: channel value: config 的形式維護所有渠道值,在方法 queryList 執行時,會先校驗渠道的存在,存在的話繼續執行邏輯,并把 config 對象 透傳 到各個查詢方法中,以執行篩選指定品類等定制化邏輯,如下:
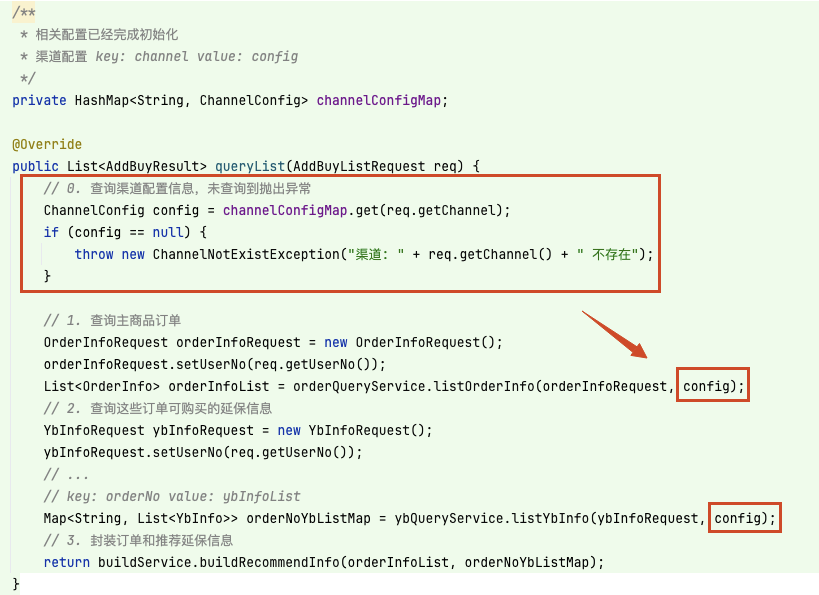
在方法 queryList 中,可以發現渠道配置幾乎 貫穿了接口邏輯執行的始終,雖然對該方法的改動并不大,但對于其中的查詢方法 listOrderInfo 和 listYbInfo 來說,會使它們的方法復用變得困難。
如果想復用其中查詢訂單的接口(其中第 1 步邏輯):
List listOrderInfo(OrderInfoRequest orderInfoRequest, ChannelConfig config);
在構建查詢入參的時候就難免不對渠道配置 ChannelConfig config 參數產生疑問:“這個入參的作用是什么”?點進去看它的字段:如果發現有很多字段,那么開發者大概率不會去了解每個字段的含義,并且也沒辦法記住這么多字段的作用是什么,這就會導致開發者直接去看 listOrderInfo 方法的實現,分析其中哪些字段是有用的,哪些是沒用的。這使得一件本可以簡單查看方法入參 OrderInfoRequest 便能復用該方法的事情變得異常復雜,需要了解太多查詢訂單信息之外的知識,大大增加了認知負荷。
從本質上去考慮:“在調用查詢訂單接口時,我們需要了解‘渠道配置’相關的內容嗎?”,顯然是不需要的,否則為通用查詢接口帶來的復雜性就太高了,進而使得接口變“淺”。
那么該如何避免這些問題呢?最初我想到兩種簡單的辦法:
詳細的配置注釋:將配置的每個字段描述的足夠清楚,那么使用該接口的研發人員不需要去了解代碼實現便能知道根據渠道如何添加一個合適的配置入參
查詢方法實現中添加配置默認值兜底:解決調用者不傳該參數或者某些字段為空的特殊情況,降低復用難度
但是這樣并不解決根本問題,入參中包含渠道配置依然會暴露其帶來的復雜性。如果開發者要復用該 listOrderInfo 方法并篩選特定品類的訂單,那么需要寫如下邏輯:
/** * 復用 listOrderInfo 方法樣例 */ public void reuseExample(Request req) { OrderInfoRequest orderInfoRequest = new OrderInfoRequest(); orderInfoRequest.setUserNo(req.getUserNo()); ChannelConfig config = new ChannelConfig(); // 賦值指定的品類編碼 config.setMainFirstCategoryCodeList(Collections.singleton("1234")); List orderInfoList = orderQueryService.listOrderInfo(orderInfoRequest, config); // ... }
一旦篩選條件中涉及渠道配置中的字段,都要創建一個渠道配置 ChannelConfig 對象,都要去了解這個類中定義了哪些字段。
這時候我就在想,那么為何不將渠道配置 ChannelConfig 中的字段都提出來放到另一個參數 OrderInfoRequest 中呢?那么這樣在入參中便能不再傳入渠道配置了,如下所示:
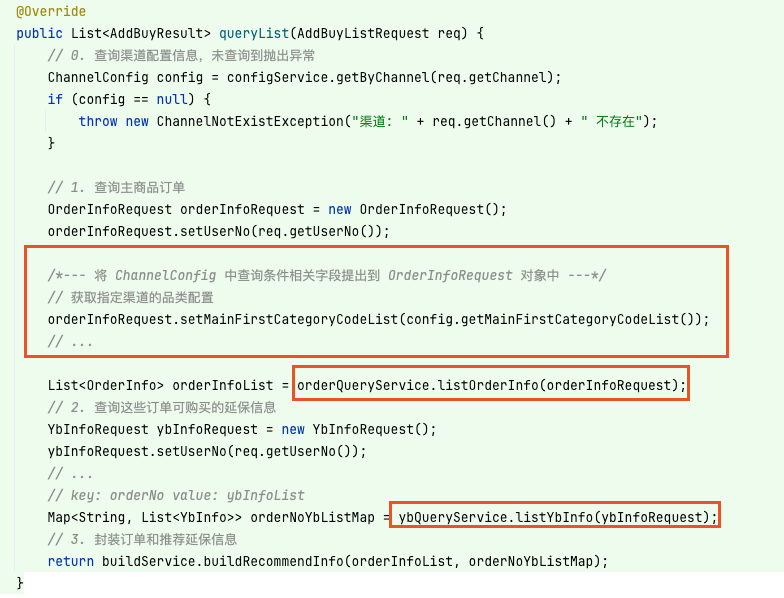
這樣當開發者復用 listOrderInfo 方法時,只需關注 OrderInfoRequest 對象并為相關字段賦值即可,這樣通用的訂單查詢接口便無需再關注渠道配置相關的內容了。
但是到這里還沒完,有一點值得考慮:渠道配置信息 ChannelConfig 作為 不可變的對象,并不應該被公開出來,而且在一般情況下,開發者會習慣使用 Lombok 的注解 @Data 為類做標注,如下:
@Data public class ChannelConfig { // ... }
這樣它每個字段的寫(set)操作都是公開(public)的,一旦對原本不可變的數據進行修改,那么因此產生的問題將非常難排查。相對應地,在《重構》一書中,提到過類似觀點:“對于所有可變的數據,只要它的作用域超出單個方法,我就會將其封裝起來,只允許通過方法訪問,數據的作用域越大,封裝就越重要,因為這樣能夠很清楚的知道哪些地方讀了這些數據或寫了這些數據,如果我們想避免其他開發者修改這個對象的話,那么就可以不公開出 set 方法”。
對 @Data 的觀點:@Data 注解實際上有些被濫用,在面向對象的開發中,通常我們都會把類內字段聲明為 private,但是又在類上標記 @Data 注解,為每個字段生成 Getter 和 Setter 方法,使得 private 失效。雖然多數時候并不會引發問題,但是更好的做法應該是針對字段指定 Getter 和 Setter 方法,而不是泛泛的生成全部,特別是如果要定義某些不可變的字段時,要尤為注意。此外,當整個對象都不可變時,每次獲取該對象時返回它的深拷貝也是很有必要的,否則其被修改后,引發的線上問題非常難定位和排查,這個對象被使用的越多,則越需要警惕。
所以,我們需要將渠道配置對象隱藏起來。
信息隱藏
為了不暴露 ChannelConfig 對象,定義渠道配置服務 ChannelConfigService,并提供校驗渠道的方法,如下:
public interface ChannelConfigService { /** * 校驗渠道是否存在,否則拋出異常 * * @throws ChannelNotExistException 渠道不存在異常 */ void checkChannelExist(String channel) throws ChannelNotExistException; // ... } @Service public class ChannelConfigServiceImpl implements ChannelConfigService { /** * 渠道配置 key: channel value: config */ private HashMap channelConfigMap; @Override public void checkChannelExist(String channel) throws ChannelNotExistException { if (StringUtils.isBlank(channel) || !channelConfigMap.containsKey(channel)) { throw new ChannelNotExistException("渠道: " + req.getChannel() + " 不存在"); } } }
這樣將保存渠道配置的 Map channelConfigMap 就下沉到了 ChannelConfigServiceImpl 實現中,queryList 方法中將不再暴露 ChannelConfig 對象,校驗渠道值邊以方法的形式,如下:

同樣地,封裝品類查詢條件等與配置相關的邏輯也需要被隱藏起來,因為已經沒有渠道配置 config對象了,那么這部分該如何處理呢?
我是這樣做的:在渠道配置服務中 ChannelConfigService 定義獲取品類配置的方法 getMainFirstCategoryCodeList,這樣便無需公開渠道配置對象了:
public interface ChannelConfigService { /** * 獲取主品類目編碼配置,默認值為空列表對象 */ List getMainFirstCategoryCodeList(String channel); // ... } @Service public class ChannelConfigServiceImpl implements ChannelConfigService { /** * 渠道配置 key: channel value: config */ private HashMap channelConfigMap; // ... @Override public List getMainFirstCategoryCodeList(String channel) { ChannelConfig config = channelConfigMap.get(channel); // 默認返回空 List if (config == null || CollectionUtils.isEmpty(config.getMainFirstCategoryCodeList())) { return Collections.emptyList(); } return Collections.unmodifiableList(config.getMainFirstCategoryCodeList()); } }
開發者只需根據接口公開出的方法來獲取相應的配置信息即可,并不需要對渠道配置對象 ChannelConfig 做了解,改動如下:
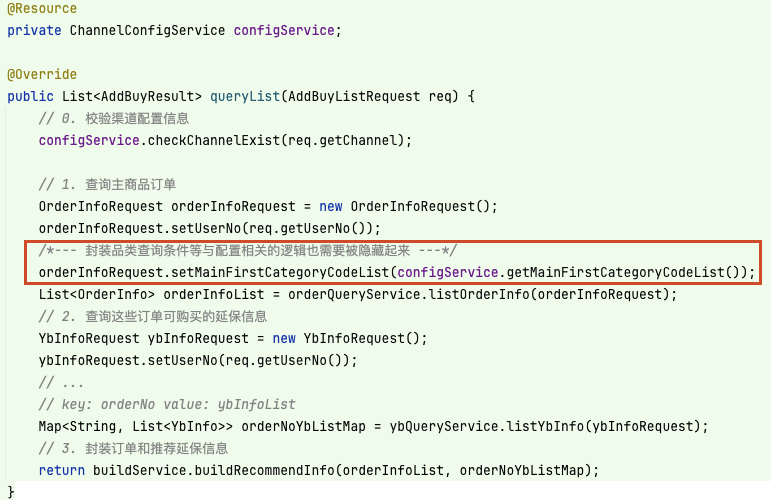
做過頭了
還有一種方式是將渠道配置服務 ChannelConfigService 注入到訂單查詢服務 AddBuyOrderQueryService 中,并添加渠道配置相關的處理邏輯:
@Service public class AddBuyOrderQueryServiceImpl implements AddBuyOrderQueryService { @Resource private ChannelConfigService configService; @Override public List listOrderInfo(OrderInfoRequest orderInfoRequest) { // ... // 過濾一級品類,如果沒有指定則取渠道配置的一級品類配置 List firstCategoryCodeList; if (CollectionUtils.isNotEmpty(orderInfoRequest.getMainFirstCategoryCodeList())) { firstCategoryCodeList = orderInfoRequest.getMainFirstCategoryCodeList(); } else { firstCategoryCodeList = configService.getMainFirstCategoryCodeList(orderInfoRequest.getChannel()); } processMainFistCategory(firstCategoryCodeList); // ... } }
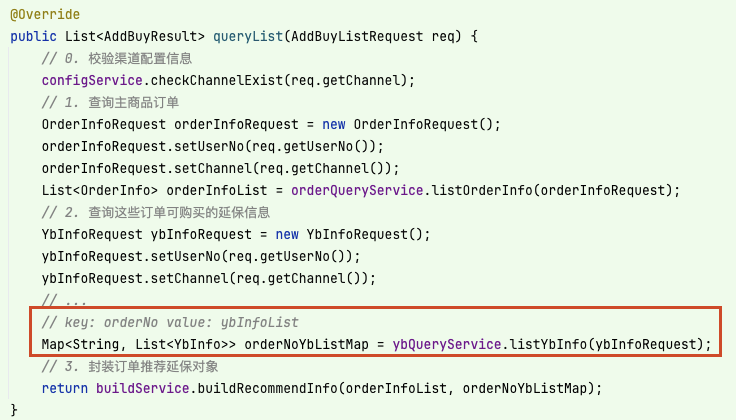
雖然這樣做將渠道配置相關信息隱藏得更深,幾乎不暴露到補購查詢 queryList 邏輯中,如下:

但是有一個問題需要考慮:訂單查詢接口屬于通用查詢接口,將渠道配置服務 ChannelConfigService 下沉到其中,便使訂單和渠道的知識發生耦合,并且在邏輯中存在依賴,渠道配置的改動可能會影響通用的訂單查詢。這樣做,可能就有些過頭了。
擴展性設計對復雜度的管理
隨著業務發展,有新的服務方提供延保的查詢服務(對應代碼中步驟 2),這些服務需要接入現有補購邏輯中,并根據渠道的不同,查詢不同的延保服務。
這是非常典型的策略模式應用場景,原有延保查詢服務和新增的延保查詢服務都將作為不同的策略來實現。借助策略模式實現擴展性并不困難,常見的有兩種實現方法,但是它們對策略帶來的復雜性處理是不同的:
第一種保持延保查詢服務 AddBuyYbQueryService 公開的方法不變,使用靜態代理模式在其實現中 AddBuyYbQueryServiceImpl 借助 HashMap 保存所有策略,并根據渠道的不同執行不同的策略:
public interface AddBuyYbQueryService { Map> listYbInfo(YbInfoRequest ybInfoRequest); } /** * 實現 ApplicationContextAware 用于注入 ApplicationContext 獲取想要的策略(Bean) * 實現 InitializingBean 用于在應用啟動時,根據策略類型 AddBuyYbQueryStrategy 加載所有的策略 */ @Service public class AddBuyYbQueryServiceImpl implements AddBuyYbQueryService, ApplicationContextAware, InitializingBean { private ApplicationContext applicationContext; private HashMap nameServiceMap; // 渠道配置 Service @Resource private ChannelConfigService configService; @Override public Map> listYbInfo(YbInfoRequest ybInfoRequest) { String ybType = configService.getYbType(ybInfoRequest.getChannel()); // 通過定義枚舉實現 ybType 與具體策略實現的關聯 YbQueryStrategyEnum strategyEnum = YbQueryStrategyEnum.parseByType(ybType); AddBuyYbQueryStrategy ybQueryStrategy = nameServiceMap.get(strategyEnum.getQueryServiceName()); return ybQueryStrategy.listYbInfo(ybInfoRequest); } @Override public void afterPropertiesSet() { nameServiceMap = new HashMap(); nameServiceMap.putAll(applicationContext.getBeansOfType(AddBuyYbQueryStrategy.class)); } @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { this.applicationContext = applicationContext; } }
策略 AddBuyYbQueryStrategy 接口方法簽名與延保查詢服務 AddBuyYbQueryService 中方法簽名一致,它們的類關系圖如下所示:
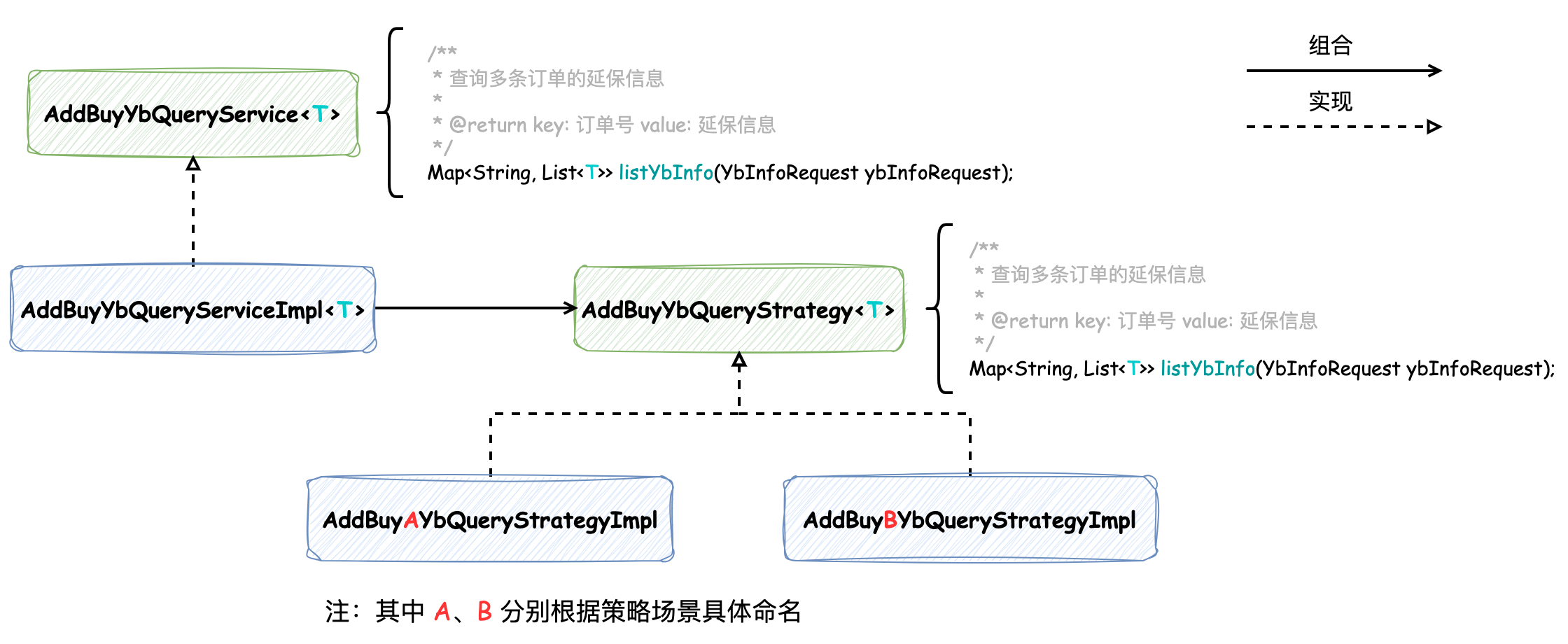
延保查詢服務 AddBuyYbQueryService 的 listYbInfo 方法不變,那么 原方法 queryList 邏輯也不需要改變,這樣便將策略帶來的復雜度隱藏了起來。
第二種是創建策略上下文 AddBuyYbQueryStrategyContext,將對應的策略管理起來并通過調用 getSpecificStrategy 直接暴露具體的策略,如下:
public interface AddBuyYbQueryStrategyContext { AddBuyYbQueryStrategy getSpecificStrategy(YbInfoRequest ybInfoRequest); }
那么這樣對原方法的改動如下:
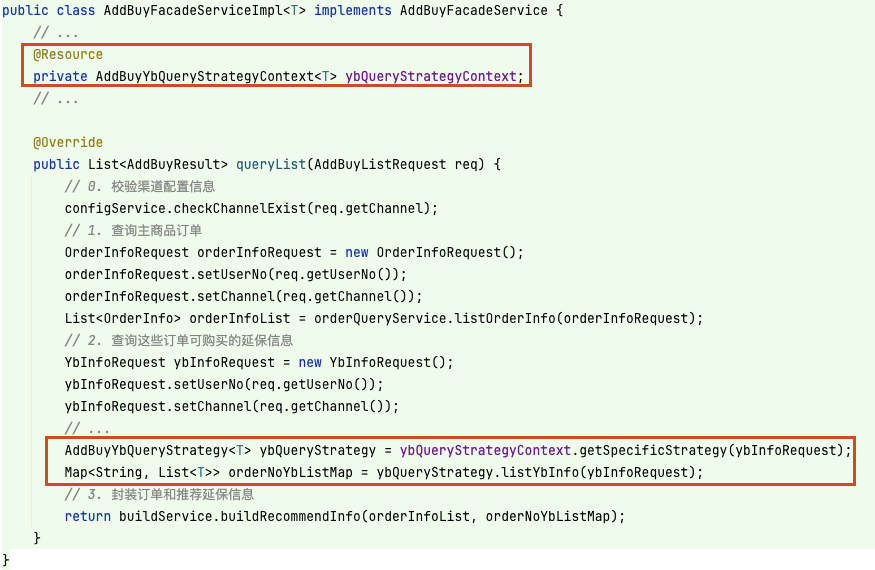
這樣會將使用策略模式的復雜度暴露到原方法 queryList 中,實際上開發者在這個方法中不需要了解策略該如何分配等相關邏輯。
封裝推薦延保信息的邏輯(其中第 3 步)由于引入了不同類型的延保服務,也需要根據不同的延保對象類型適配相應的策略,同樣需要使用策略模式,但實現邏輯類似,不再贅述,不過不同點是該步驟一并使用了模板方法模式:
封裝訂單和推薦延保信息的 buildRecommendInfo 方法主要步驟為封裝訂單信息(initialMainOrderInfo)和封裝推薦的延保信息(initialRecommendYbInfo),其中封裝訂單信息的邏輯是通用的,而封裝推薦的延保信息步驟需要分別處理不同的延保類型,所以借助了模板方法模式。將后者其定義為抽象方法,由子類不同的策略去分別實現,抽象模板類如下:
public abstract class AbstractAddBuyBuildService implements AddBuyBuildStrategy { @Override public List buildRecommendInfo(List orderInfoList, Map> orderNoYbListMap) { List res = new ArrayList(orderNoYbListMap.size()); // Group By OrderNo Map orderNoOrderInfoMap = orderInfoList.stream().collect(Collectors.toMap(OrderInfo::getOrderid, x -> x)); // orderNoBindListEntry: (key: 訂單號;value: 訂單對應的延保信息) for (Map.Entry> orderNoYbListEntry : orderNoYbListMap.entrySet()) { // 訂單信息 OrderInfo orderInfo = orderNoOrderInfoMap.get(orderNoYbListEntry.getKey()); // 延保信息 List ybList = orderNoYbListEntry.getValue(); AddBuyResult element = new AddBuyResult(); // 1. 封裝訂單信息 MainOrderInfo mainOrderInfo = initialMainOrderInfo(orderInfo); element.setMainOrderInfo(mainOrderInfo); // 2. 封裝推薦的延保信息 List recommendYbInfo = initialRecommendYbInfo(ybList); element.setRecommendYbInfoList(recommendYbInfo); res.add(element); } return res; } // 封裝訂單信息作為私有方法,被各個不同的策略復用 private MainOrderInfo initialMainOrderInfo(OrderInfo orderInfo) { // ... } // 抽象初始化推薦延保的方法,用于子類實現不同的策略 protected abstract List initialRecommendYbInfo(List ybList); }
類關系圖如下:
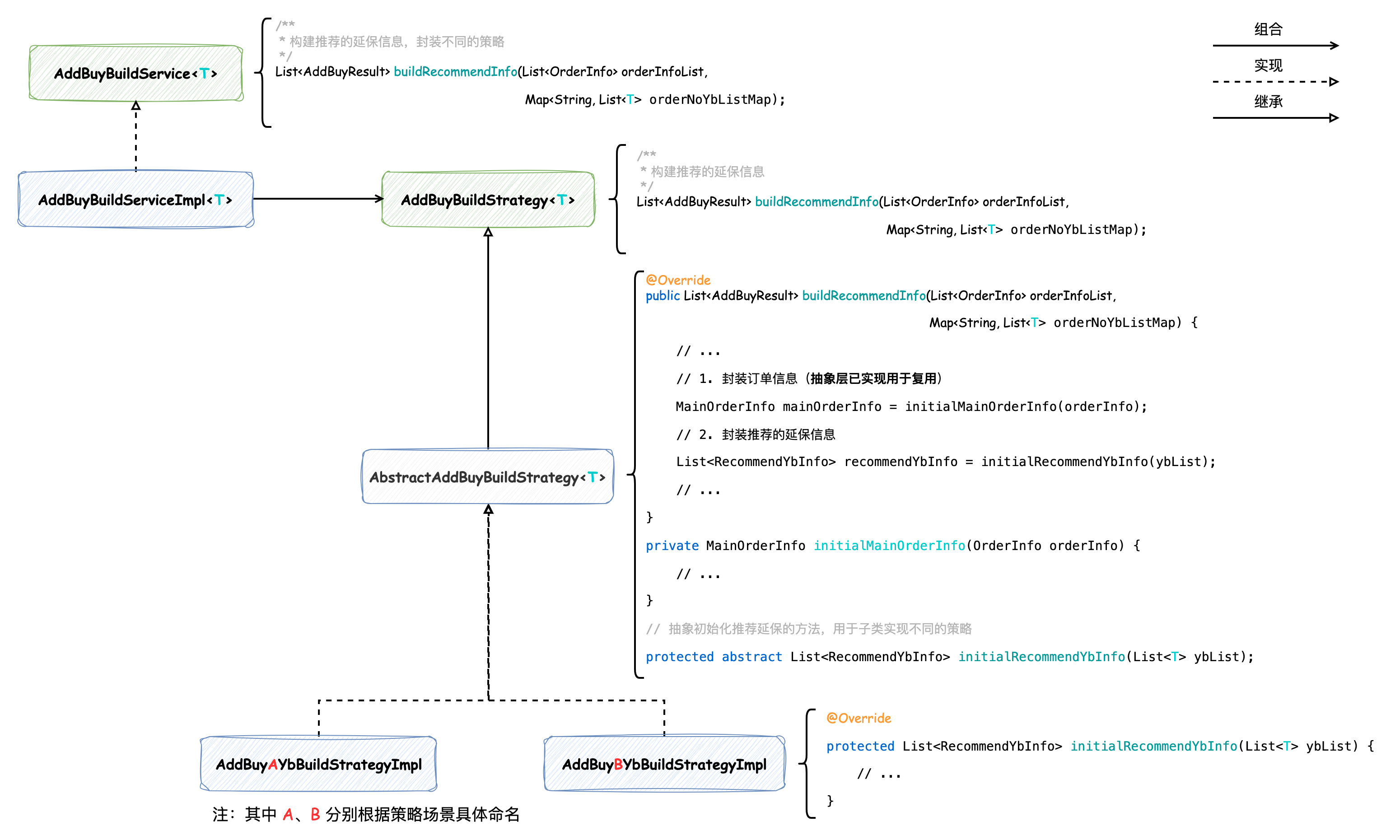
這樣便能實現通用邏輯的復用。使用模板方法模式并不復雜,實現這種模式需要借助繼承(extends),而繼承在設計原則中被強調“少用繼承,多用組合”,而且在一些軟件設計相關的書中也會經常看到對繼承的詬病,比如在《程序員修煉之道》中便將其稱為“繼承稅”,并且舉了一個非常好玩的例子:
你想要一根香蕉,但得到的卻是一只拿著香蕉的大猩猩,甚至還有整個森林
其表達的意思也不難理解:強調繼承使父類中的大量信息發生泄露,讓維護在每個類中的知識在繼承關系之間 “波動”,暴露了太多的知識出來,做不到抽象和信息隱藏。一方面會使子類獲得太多無關的知識,另一方面如果在子類中大量使用這些通用的部分,便會使得耦合加深,父類中信息變更可能為子類帶來意想不到的后果。
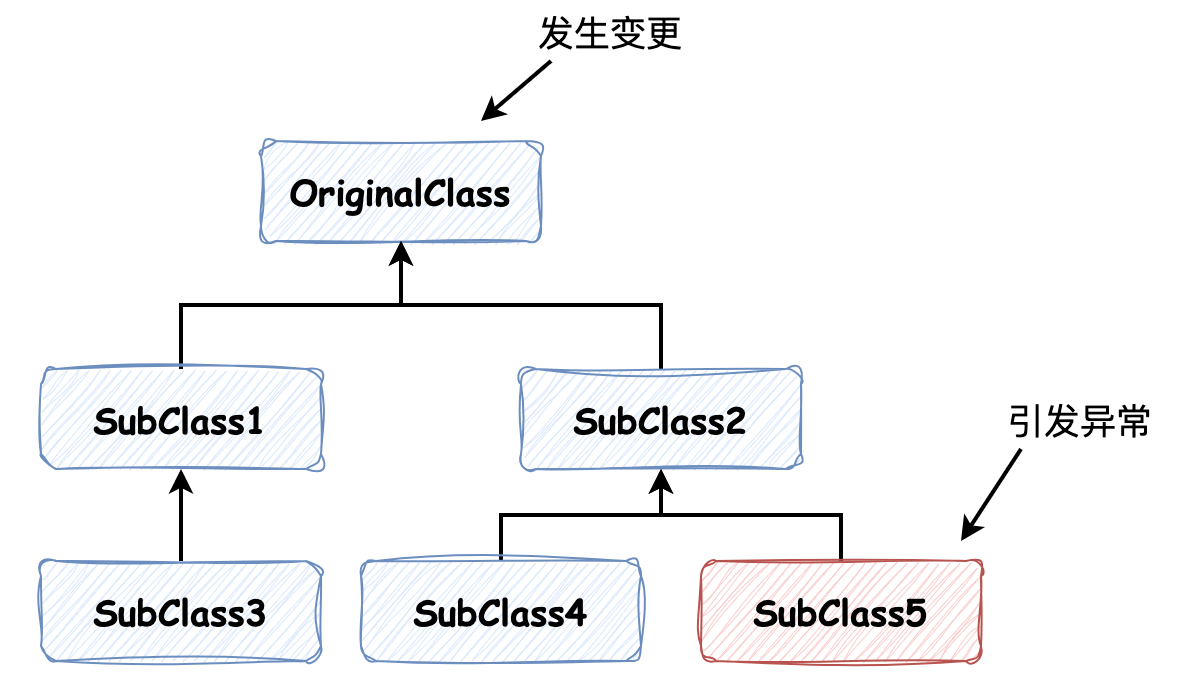
以如上繼承關系為例,如果父類中某些內容發生變更,子類中對其使用的話,那么可能會引起子類行為的改變,而如果這種改變并不引起編譯期異常的話,便很難發現,使得代碼的可維護性大大降低。那么不用繼承該怎么辦呢?常見的觀點有兩個:
使用接口實現來代替類的繼承,保證多態又不會造成信息的緊耦合
使用組合代替繼承:比如想要香蕉,那么直接將包含香蕉的類注入進來,不再通過繼承去獲取了
但是,我覺得繼承也并不能被一票否決,在 Java 源碼中常用容器的實現里,都是有抽象層的(AbstractList, AbstractMap 等等),通過繼承它們,實現了大量代碼復用,為各種不同容器的實現提供了很多方便之處。所以,我覺得繼承能被應用需要具備以下前提條件:
保持不變性:父類中抽象出來的供復用的通用方法、字段保持不變
控制繼承樹的高度:繼承樹高度越高引入的復雜度越大,所以需要控制樹高,限制一層繼承關系,那么復雜度便可控
總結
我覺得軟件設計更應該站在代碼閱讀者的角度上,考慮如何降低復雜度,設計更深的模塊,并隨著功能迭代,不斷更新現有設計,而并不是將注意力放在如何改動更簡單上,代碼的堆疊可能會導致復雜性不斷累積,以至于在不能滿足業務功能迭代時,花更多的時間去重構。
審核編輯 黃宇
-
軟件設計
+關注
關注
3文章
58瀏覽量
17773 -
代碼
+關注
關注
30文章
4788瀏覽量
68612
發布評論請先 登錄
相關推薦
HarmonyOS應用點擊完成時延問題定位流程及原理
【軟件干貨】Android應用進程如何保活?

基于FPA的軟件工作量綜合評估研究與實踐

「重構:改善既有代碼的設計」實戰篇
TLV3201電流檢測電路的時延應該怎么算?
軟件設計哲學:新“代碼整潔之道”
該如何提高代碼容錯率、降低代碼耦合度?






 工商網監
工商網監
評論