 使用OpenVINO和LlamaIndex構建Agentic-RAG系統
使用OpenVINO和LlamaIndex構建Agentic-RAG系統
背景
RAG 系統的全稱是 Retrieval-augmented Generation,本質上是 Prompt Engineering,通過在 Prompt 中注入檢索得到的外部數據,可以有效地解決大語言模型在知識時效性和專業性上的不足。但同時傳統的 RAG 系統也有它的缺陷,例如靈活性較差,由于 RAG 會過分依賴于向量數據庫的檢索結果,導致其在解決一些復雜問題的時候,只是一味地 “搬運” 檢索結果,無法通過推理找到更優的解決途徑,此外隨著向量數據庫的規模增大,傳統 RAG 也無法高效對輸入請求進行分類和過濾,導致檢索過程猶如“大海撈針”,費時費力。
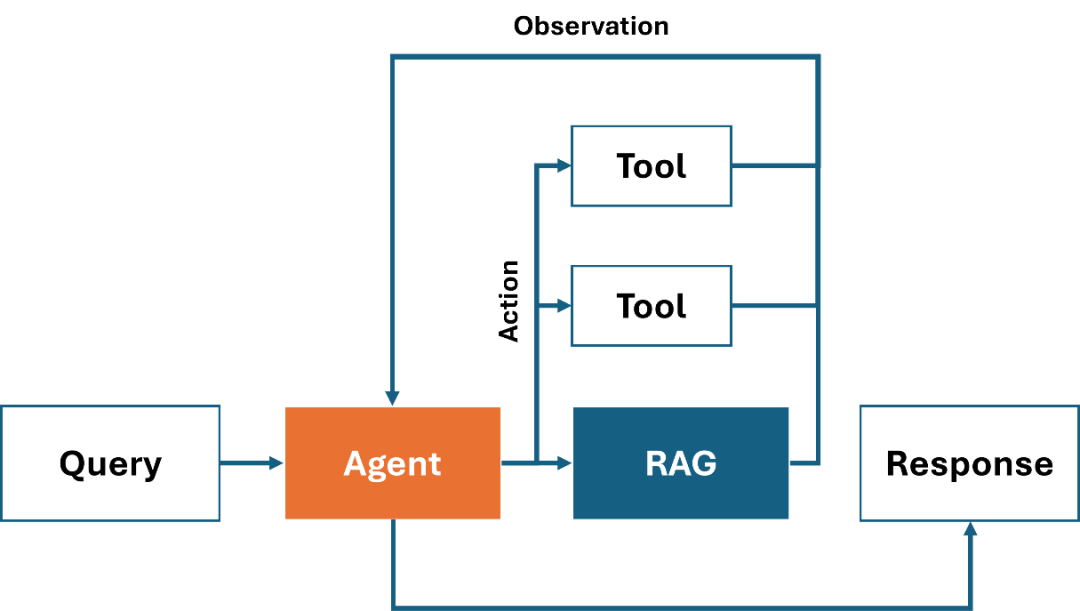
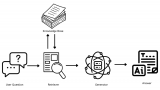
圖:Agentic-RAG系統示例
而基于 AI 智能體的 RAG 系統(以下簡稱 Agentic-RAG )恰好可以解決傳統 RAG 在靈活性上的不足,它通過將多個不同類別的 RAG 檢測器,以工具的形式集成在 AI 智能體中,讓 AI 智能體根據用戶的請求,判斷是否需要調用 RAG 搜索上下文,以及調用哪個 RAG 工具進行檢索,例如在回答一個歷史相關的問題時,Agentic-RAG 就會優先在歷史類的 RAG 檢索器中搜索答案,又或是在回答一個涉及數學計算的問題時,Agentic-RAG 則不會使用 RAG,而是調用數據計算相關的工具,甚至如果 LLM 本身具備一定的數據運算能力話,則完全不需要調用外部工具,直接輸出答案。當然我們也可以將 RAG 和其他外部工具結合起來,協同解決更復雜的問題,如上圖所示,在這個過程中,AI智能 體會將任務拆解后,在每個步驟中分別調用不同的工具,或是 RAG 組件來輸出最終答案。接下來我們就一起看下如何利用 OpenVINO 和 LlamaIndex 工具來構建一個 Agentic-RAG 系統。
完整示例:
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/llm-rag-llamaindex/llm-rag-llamaindex.ipynb
第一步模型轉換與量化
LLM 和 Embedding 模型是 RAG系統中必要的組件,這里我們可以通過 Optimum-intel CLI 分別把他們轉化為 OpenVINO 的 IR 格式,并進行量化壓縮。
安裝方法:
pip install optimum[openvino]
LLM:
optimum-cli export openvino --model {llm_model_id} --task text-generation-with-past --trust-remote-code --weight-format int4 {llm_model_path}
Embedding:
pip install optimum[openvino]
第二步 模型任務初始化
目前基于 OpenVINO 的 LLM,Embedding 以及 Reranker 任務均已被集成在 LlamaIndex 框架中,開發者可以非常方便地利用導出的 LLM 和 Embedding 模型,將這兩類任務在 LlamaIndex 中進行初始化。
安裝方法:
pip install llama-index llama-index-llms-openvino llama-index-embeddings-openvino
LLM:
from llama_index.llms.openvino import OpenVINOLLM
llm = OpenVINOLLM(
model_name=str(llm_model_path),
tokenizer_name=str(llm_model_path),
context_window=3900,
max_new_tokens=1000,
model_kwargs={"ov_config": ov_config},
device_map=llm_device.value,
completion_to_prompt=completion_to_prompt,
)
Embedding:
from llama_index.embeddings.huggingface_openvino import OpenVINOEmbedding embedding = OpenVINOEmbedding(folder_name=embedding_model_path, device=embedding_device.value)
第三步 構建RAG工具
接下來我們可以利用初始化后的 LLM 以及 Embedding 組件來構建 RAG 工具。第一步需要在 LlamaIndex 創建一個標準的 RAG 檢索引擎,為了方便演示,該檢索器僅使用默認的向量相似度搜索方式進行上下文過濾,如果想了解更完整的 RAG 搭建方法,可以參考 OpenVINO notebooks 倉庫中的另一個示例:
https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-rag-llamaindex
from llama_index.readers.file import PyMuPDFReader from llama_index.core import VectorStoreIndex, Settings from llama_index.core.tools import FunctionTool Settings.embed_model = embedding Settings.llm = llm loader = PyMuPDFReader() documents = loader.load(file_path=text_example_en_path) index = VectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine(similarity_top_k=2)
在完成 RAG 檢索引擎創建后,可以直接調用 LlamaIndex 的接口將它包裝為一個 Agent 的工具,如下所示,同時需要添加對該工具的描述,以便 LLM 判斷在什么時候調用什么工具。
from llama_index.core.tools import QueryEngineTool budget_tool = QueryEngineTool.from_defaults( query_engine, name="Xeon6", description="A RAG engine with some basic facts about Intel Xeon 6 processors with E-cores", )
此外,為了演示 Agentic-RAG 對于復雜任務的拆解與多工具間的路由能力,我們還可以再準備兩個單獨的數學運算工具,供 LLM 選擇。
def multiply(a: float, b: float) -> float: """Multiply two numbers and returns the product""" return a * b multiply_tool = FunctionTool.from_defaults(fn=multiply) def add(a: float, b: float) -> float: """Add two numbers and returns the sum""" return a + b add_tool = FunctionTool.from_defaults(fn=add)
第四步 構建 Agent 任務流水線
因為該示例中用到的 Llama3 還不支持 Function-call,所以這里我們可以創建了一個基于 ReAct 的 Agent 。在 LlamaIndex中搭建 Agent 流水線只需要一行代碼,通過 ReAct Agent.from_tools 接口可以創建一個基礎的 ReAct Agent ,并將剛才定義好的工具及 LLM 組件綁定到該 Agent 中。
agent = ReActAgent.from_tools([multiply_tool, add_tool, budget_tool], llm=llm, verbose=True)
接下來可以測試下效果,我們向 Agent 咨詢了關于“4顆第六代 Xeon CPU 最大線程數“的問題,可以看到 Agent 首先會調用 Xeon 6 的 RAG 系統查詢單顆 CPU 支持的最大線程數,然后再調用數學運算工具將獲得的線程數乘以4,最后將得到的數字反饋給用戶。
response = agent.chat("What's the maximum number of cores in an Intel Xeon 6 processor server with 4 sockets ? Go step by step, using a tool to do any math.")
Thought: The current language of the user is English. I need to use a tool to help me answer the question.
Action: Xeon6
Action Input: {'input': 'maximum cores in a single socket'}
Observation:
According to the provided context information, the maximum cores in a single socket is 144.
Thought: The current language of the user is English. I need to use a tool to help me answer the question.
Action: multiply
Action Input: {'a': 144, 'b': 4}
Observation: 576
Thought: The current language of the user is English. I can answer without using any more tools. I'll use the user's language to answer
Answer: The maximum number of cores in an Intel Xeon 6 processor server with 4 sockets is 576.
總結和展望
通過將 Agent 和 RAG 進行結合,我們直接提升 LLM 在解決復雜任務時的能力,相較于傳統的 RAG,Agentic-RAG 更具產業落地價值。同時隨著多智能體方法的引入,基于 Agent 的 RAG 將逐步取代傳統 RAG 系統,實現更靈活,更精確的大語言模型應用業務體系。
-
AI
+關注
關注
87文章
30887瀏覽量
269065 -
模型
+關注
關注
1文章
3243瀏覽量
48836 -
智能體
+關注
關注
1文章
150瀏覽量
10578 -
OpenVINO
+關注
關注
0文章
93瀏覽量
201
原文標題:使用 OpenVINO? 和 LlamaIndex 構建 Agentic-RAG 系統|開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于OpenVINO和LangChain構建RAG問答系統

【書籍評測活動NO.52】基于大模型的RAG應用開發與優化
從源代碼構建OpenVINO工具套件時報錯怎么解決?
在Raspberry Pi上從源代碼構建OpenVINO 2021.3收到錯誤怎么解決?
如何使用交叉編譯方法為Raspbian 32位操作系統構建OpenVINO工具套件的開源分發
如何使用Python包裝器正確構建OpenVINO工具套件
永久設置OpenVINO trade Windows reg10的工具套件環境變量
從Docker映像為Raspbian OpenVINO工具套件的安裝過程
無法使用Microsoft Visual Studio 2017為Windows 10構建開源OpenVINO怎么解決?
什么是LlamaIndex?LlamaIndex數據框架的特點和功能
什么是RAG,RAG學習和實踐經驗
如何手擼一個自有知識庫的RAG系統
英特爾軟硬件構建模塊如何幫助優化RAG應用

RAG的概念及工作原理
檢索增強型生成(RAG)系統詳解





 工商網監
工商網監
評論