") 探討條件GAN在圖像生成中的應(yīng)用
探討條件GAN在圖像生成中的應(yīng)用
生成對抗網(wǎng)絡(luò)一直是深度學(xué)習(xí)的重要工具,經(jīng)過近幾年的發(fā)展,GANs也衍生出了許多不同的模式,例如DCGANs、Wasserstein GANs、BEGANs等。本文將要探討的是條件GAN(Conditional GANs)在圖像生成中的應(yīng)用。
條件GANs已經(jīng)應(yīng)用與多種跟圖像有關(guān)的任務(wù)中了,但分辨率通常都不高,并且看起來很不真實。而在這篇論文中,英偉達和加州大學(xué)伯克利分校的研究人員共同提出了一個新方法合成高分辨率的街景,利用條件GANs從語義標(biāo)簽映射生成的2048x1024的圖像不僅在視覺上更吸引人,同時生成了新的對抗損失以及新的多尺度生成器和判別器體系結(jié)構(gòu)。
合成實例級別的圖像
接下來就是該項目的具體實驗過程。首先,是基線算法pix2pix的運用。pix2pix是用于圖像翻譯的條件GAN框架,它包含一個生成網(wǎng)絡(luò)G和一個判別網(wǎng)絡(luò)D。在這項任務(wù)中,生成網(wǎng)絡(luò)G的目標(biāo)就是將語義標(biāo)簽映射翻譯成接近真實的圖像,而判別網(wǎng)絡(luò)D的目標(biāo)是將生成圖像與真實圖像作對比。
pix2pix利用U-Net作為生成網(wǎng)絡(luò),同時用基礎(chǔ)的卷積網(wǎng)絡(luò)作為判別器。然而,利用數(shù)據(jù)集Cityspaces生成的圖像分辨率最高只有256x256的,以至于訓(xùn)練過程十分不穩(wěn)定,生成圖片的質(zhì)量也不是很好,所以pix2pix框架需要進行一些改善升級。
研究人員將生成網(wǎng)絡(luò)換成由粗到精的網(wǎng)絡(luò),并采用多尺度的判別網(wǎng)絡(luò)結(jié)構(gòu)。同時采用穩(wěn)定的對抗學(xué)習(xí)目標(biāo)函數(shù)。
由粗到精的生成網(wǎng)絡(luò)(Coarse-to-fine generator)
研究人員將生成網(wǎng)絡(luò)分成了兩部分:全局生成網(wǎng)絡(luò)G1和局部增強網(wǎng)絡(luò)G2。全局生成網(wǎng)絡(luò)G1的可接受的分辨率為1024x512,局部增強網(wǎng)絡(luò)輸出的圖像分辨率為前一個圖像的4倍。如果還想得到更高的合成圖像,可以繼續(xù)增加局部增強網(wǎng)絡(luò)。
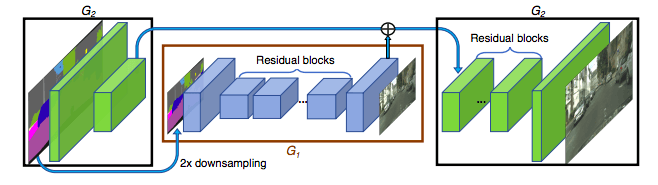
生成網(wǎng)絡(luò)結(jié)構(gòu)
多尺度判別網(wǎng)絡(luò)(multi-scale discriminators)
對GAN的判別網(wǎng)絡(luò)來說,高分辨率的圖像是不小的挑戰(zhàn)。為了區(qū)分真正的高清圖片與合成圖片,判別網(wǎng)絡(luò)需要一個巨大的接收區(qū)(receptive field)。所以這就需要一個更深的網(wǎng)絡(luò)或更大的卷積核。但是這兩種方法都會增加網(wǎng)絡(luò)的能力,有可能導(dǎo)致過度擬合。并且它們在訓(xùn)練時都需要更大的存儲腳本,這對高分辨率的圖像生成來說是很稀少的。
為了解決這一問題,研究人員提出了使用多尺度判別器的方法,即用三種擁有同樣結(jié)構(gòu)的網(wǎng)絡(luò),但針對不同尺寸的圖片運行。能處理最大尺寸的網(wǎng)絡(luò)擁有最大的接收區(qū),它能引導(dǎo)生成網(wǎng)絡(luò)生成整體更協(xié)調(diào)的圖像。而處理最小尺寸的網(wǎng)絡(luò)能引導(dǎo)生成網(wǎng)絡(luò)在細(xì)節(jié)上處理得更仔細(xì)。
損失函數(shù)
研究人員從鑒別網(wǎng)絡(luò)的多個層中提取特征,并學(xué)習(xí)從真實和合成圖像中匹配這些中間表征。為了方便表示,我們將判別網(wǎng)絡(luò)Dk的第i層表示為Dk(i),特征匹配損失LFM(G, Dk)表示為:
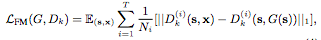
其中T是總層數(shù),Ni表示每層的組成要素。
最終將GAN損失和特征匹配損失結(jié)合起來的函數(shù)表示為:
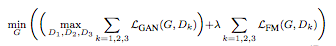
其中λ控制兩項的重要性。
現(xiàn)有的圖像合成方法僅使用語義標(biāo)簽映射,其中每個像素值代表像素所屬的對象類別。這種映射不區(qū)分同一類別的對象。另一方面,實例級別的語義標(biāo)簽映射包括每個單獨對象的唯一ID。要包含實例映射,一個簡單的方法是將其直接傳遞給網(wǎng)絡(luò),或者將其編碼成一個單獨的向量。然而,由于不同圖像可能包含不同數(shù)量相同類別的對象,所以這兩種方法在實踐中都難以實現(xiàn)。
所以我們選擇用實例映射,它能夠提供語義標(biāo)簽映射中沒有的對象邊界(object boundary)。例如,當(dāng)多個相同類別的對象彼此相鄰是,只查看語義標(biāo)簽映射無法區(qū)分它們。
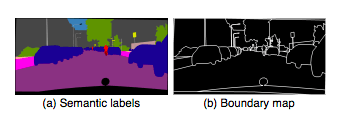
下圖顯示用實例邊界映射訓(xùn)練的模型,圖像邊界更清晰。

結(jié)果對比
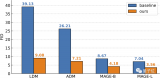
為了量化合成圖像的質(zhì)量,研究人員對其進行語義分割,并比較預(yù)測的預(yù)測的部分與輸入部分的匹配程度。從下表可以看出,我們使用的方法遠遠優(yōu)于其他方法,并且十分接近原始圖像。

在CityScapes數(shù)據(jù)集上,在沒有損失函數(shù)的情況下,我們的方法也依然比其他兩種方法更優(yōu)。
在NYU數(shù)據(jù)集上,我們的方法生成的圖片比其他方法生成的圖片看起來更真實。
其他結(jié)果:
輸入標(biāo)簽(左)與合成圖像(右)
放大后可以看到圖中對象的細(xì)節(jié)更清晰
在ADE20K數(shù)據(jù)集的實驗,我們的結(jié)果生成的圖片真實度與原圖相差無幾
在Helen Face數(shù)據(jù)集上的實驗,用戶可以在互動界面實時改變臉部特征。例如變換膚色、加胡子等等
各位可以到網(wǎng)站上自行繪制你的“大作”:uncannyroad.com/
結(jié)語
實驗的結(jié)果表明,條件GANs無需手動調(diào)整損失函數(shù)或提前訓(xùn)練網(wǎng)絡(luò),就能合成高分辨率的逼真圖像。我們的成果將幫助許多需要高分辨率圖像,但卻沒有預(yù)先訓(xùn)練網(wǎng)絡(luò)的領(lǐng)域,比如醫(yī)療影像和生物領(lǐng)域。
同時,這篇論文還向我們展示出,圖像到圖像的合成pipeline可以用來生成多種結(jié)果。研究人員認(rèn)為這些成果有助于擴大圖片合成的應(yīng)用范圍。
-
GaN
+關(guān)注
關(guān)注
19文章
1950瀏覽量
73776 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5510瀏覽量
121336
原文標(biāo)題:通過協(xié)同繪制用GAN合成高分辨率無盡道路
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
如何精確高效的完成GaN PA中的I-V曲線設(shè)計?
【洞幺邦】基于深度學(xué)習(xí)的GAN應(yīng)用風(fēng)格遷移
圖像生成對抗生成網(wǎng)絡(luò)gan_GAN生成汽車圖像 精選資料推薦
特倫托大學(xué)與Inria合作:使用GAN生成人體的新姿勢圖像
GAN技術(shù)再到新高度 利用pytorch技術(shù)生成72種圖像
圖像生成領(lǐng)域的一個巨大進展:SAGAN
GAN在圖像生成應(yīng)用綜述

必讀!生成對抗網(wǎng)絡(luò)GAN論文TOP 10
生成對抗網(wǎng)絡(luò)GAN論文TOP 10,幫助你理解最先進技術(shù)的基礎(chǔ)
基于譜歸一化條件生成對抗網(wǎng)絡(luò)的圖像修復(fù)算法

基于自注意力機制的條件生成對抗網(wǎng)絡(luò)模型
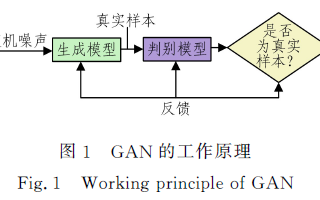
基于GAN-inversion的圖像重構(gòu)過程
探討GAN背后的數(shù)學(xué)原理(上)
探討GAN背后的數(shù)學(xué)原理(下)
何愷明新作RCG:無自條件圖像生成新SOTA!與MIT首次合作!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論