") 基于CUDA技術(shù)的視頻顯示系統(tǒng)設(shè)計(jì)方案
基于CUDA技術(shù)的視頻顯示系統(tǒng)設(shè)計(jì)方案
NVIDIA 推出的CUDA(計(jì)算統(tǒng)一設(shè)備架構(gòu))是基于GPU 進(jìn)行通用計(jì)算的開發(fā)平臺(tái),非常適合大規(guī)模的并行數(shù)據(jù)計(jì)算。在GPU 流處理器架構(gòu)下用CUDA 技術(shù)實(shí)現(xiàn)編碼并行化,并針對(duì)流處理器架構(gòu)特點(diǎn)進(jìn)行內(nèi)存讀寫等方面的優(yōu)化。
本文在此采用CUDA技術(shù),實(shí)現(xiàn)了計(jì)算機(jī)桌面環(huán)境的多屏幕融合顯示的純軟件拼接系統(tǒng)。該系統(tǒng)不但較以往單一的視頻拼接系統(tǒng)功能更加強(qiáng)大,也較采用分屏器等硬件輔助的融合系統(tǒng)成本更低,適應(yīng)性更強(qiáng)。目前實(shí)驗(yàn)表明,CUDA 技術(shù)在并行處理方面的優(yōu)越性使得該系統(tǒng)畫面實(shí)時(shí)處理快,互動(dòng)展示性好,具有很大的商業(yè)使用前景。
0 引言
近年來隨著大屏幕顯示技術(shù)在各領(lǐng)域應(yīng)用的逐步深入,市場(chǎng)已經(jīng)不滿足單一的影片展示,更多的轉(zhuǎn)向了對(duì)互動(dòng)性更強(qiáng)的計(jì)算機(jī)桌面環(huán)境的融合顯示上來。而目前市場(chǎng)上主流的桌面融合系統(tǒng),多采用分屏器等硬件輔助設(shè)備,成本高,性能差。
統(tǒng)一計(jì)算架構(gòu)(Compute Unified Device Architect-ure,CUDA)是英偉達(dá)(NVIDIA)公司近年來推出的通用并行計(jì)算架構(gòu),它以高性能顯卡GPU為硬件依托,采用CPU+GPU的混合計(jì)算極大的提高了大規(guī)模的圖形數(shù)據(jù)實(shí)時(shí)處理效率。本文設(shè)計(jì)的視頻顯示系統(tǒng),采用CUDA開發(fā)方式實(shí)現(xiàn)了計(jì)算機(jī)桌面圖片的分割計(jì)算、貝塞爾曲線擬合、以及融合圖像計(jì)算等三方面處理。實(shí)時(shí)性高,畫面數(shù)據(jù)計(jì)算理論上精確值1 4 像素,精度好。
1 系統(tǒng)框架設(shè)計(jì)
圖像處理的本質(zhì)是大規(guī)模矩陣運(yùn)算,特別適合并行處理。但CPU 通用計(jì)算很難利用該特性。與此相反,GPU 在并行數(shù)據(jù)運(yùn)算上具有強(qiáng)大的計(jì)算能力,特別適合作運(yùn)算符相同而運(yùn)算數(shù)據(jù)不同的運(yùn)算,當(dāng)執(zhí)行具有高運(yùn)算密度的多數(shù)據(jù)元素時(shí),內(nèi)存訪問的延遲可以被忽略。CUDA 編程模型將CPU 作為主機(jī)(Host ),GPU作為協(xié)處理器(Coprocessor)或設(shè)備(Device),一個(gè)系統(tǒng)中可以存在多個(gè)設(shè)備。在這個(gè)模型中,CPU 與GPU共同工作,CPU 負(fù)責(zé)邏輯性強(qiáng)的事務(wù)處理和串行計(jì)算,GPU 則專注于執(zhí)行高度線程化的并行處理任務(wù)。
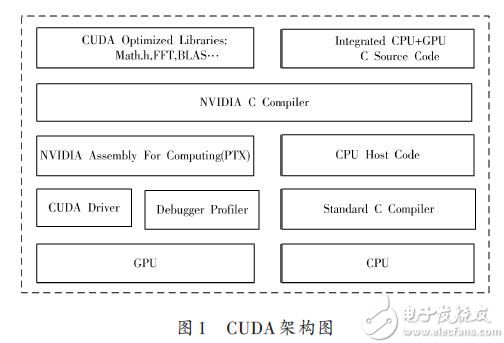
本系統(tǒng)以NVIDIA GeForce GTX470 搭建的計(jì)算平臺(tái)為運(yùn)行環(huán)境,利用顯卡的多頭輸出特性,連接多臺(tái)投影儀組成拼接屏幕陣列,不需要額外增加其他硬件設(shè)備。由于桌面融合顯示系統(tǒng)要處理的圖像數(shù)據(jù)大、實(shí)時(shí)性高的特點(diǎn),所以本系統(tǒng)的軟件設(shè)計(jì)上則廣泛使用了多CPU并行編程技術(shù)和CUDA并行計(jì)算技術(shù),針對(duì)每一個(gè)投影設(shè)備的圖像處理和顯示,系統(tǒng)會(huì)分配一個(gè)專門的線程來處理。該線程會(huì)對(duì)應(yīng)固定的CPU和固定的GPU計(jì)算核心,保證多投影設(shè)備完全并行處理,從而避免了其他系統(tǒng)由于顯示設(shè)備增多,處理數(shù)據(jù)變大而造成的性能下降。CUDA架構(gòu)如圖1所示。
本系統(tǒng)在設(shè)計(jì)中,首先設(shè)置定時(shí)器。定期采集控制屏幕圖像信息保存到公共存儲(chǔ)空間,然后針對(duì)外設(shè)顯示設(shè)備個(gè)數(shù)動(dòng)態(tài)的開啟數(shù)個(gè)線程完成圖像的數(shù)據(jù)分割、圖像的數(shù)據(jù)融合以及圖像的顯示等工作。其中在線程開啟初始就與固定的GPU 計(jì)算核心相關(guān)聯(lián),并把數(shù)據(jù)圖形分割和融合部分采用CUDA技術(shù)進(jìn)行實(shí)現(xiàn),最后同樣采用定時(shí)器技術(shù)同步各個(gè)線程中圖像數(shù)據(jù)顯示工作。
通常采用貝塞爾曲線擬合方法來完成圖像數(shù)據(jù)的融合。該方法的一般做法是先由控制點(diǎn)得出目標(biāo)圖像每行的貝塞爾曲線,組成二維貝塞爾曲面,再將目標(biāo)圖像數(shù)據(jù)采用貼紋理的方法擬合到貝塞爾曲線上從而實(shí)現(xiàn)圖像變形。Bezier 曲線是法國雷諾汽車公司Bezier 提出的一種用控制多邊形定義曲線和曲面的方法。它的擬合插值公式為:
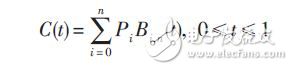
式中:Pi 為構(gòu)成該曲線的特征多邊形;Bi,n (t) 是Bezier基函數(shù),是曲線上各點(diǎn)位置矢量的調(diào)和函數(shù)。Bezier曲線的始點(diǎn)、末點(diǎn)與其特征多邊形端點(diǎn)重合,且始點(diǎn)、末點(diǎn)的切線方向與特征多邊形的第一和最后一條邊一致。
該曲線具有凸包性、對(duì)稱性等特性。貝塞爾曲線的優(yōu)點(diǎn)是給定足夠的控制點(diǎn)后,它能夠擬合任意形狀的曲線。
Bezier曲線的擬合插值公式中,函數(shù)的次數(shù)是與特征多邊形的頂點(diǎn)數(shù)相應(yīng)的,當(dāng)特征多邊形頂點(diǎn)數(shù)為4時(shí),就構(gòu)成三次Bezier 曲線。三次Bezier曲線的擬合插值公式為:

OPenGL技術(shù)提供了易于操作的貝塞爾曲線生成函數(shù)和貼圖函數(shù),但卻無法控制硬件運(yùn)算,效率不高。本系統(tǒng)出于對(duì)時(shí)效性的考慮在實(shí)現(xiàn)過程中并未采用該方法,而是采用CUDA技術(shù)并行矩陣運(yùn)算的方式來進(jìn)行紋理貼圖。根據(jù)CUDA 程序的結(jié)構(gòu)特點(diǎn),本系統(tǒng)處理時(shí),首先根據(jù)人機(jī)交互部分得到的控制點(diǎn)信息采用通常方法生成目標(biāo)圖像每行的貝塞爾曲線。開辟顯存存入GPU,然后對(duì)應(yīng)CUDA 程序結(jié)構(gòu),針對(duì)目標(biāo)圖像上的每一個(gè)像素點(diǎn),為其分配一個(gè)GPU thread 來進(jìn)行處理。
觀察上面的計(jì)算公式發(fā)現(xiàn),當(dāng)獲得了初始控制點(diǎn)坐標(biāo)后,在得出每一條貝賽爾曲線上的點(diǎn)的過程中,彼此并不影響,具有多線程的粗粒度的特性,所以CUDA 并行計(jì)算的時(shí)效性有很大的提高。
2 性能評(píng)估
在多媒體拼接系統(tǒng)中實(shí)時(shí)性是最基本、也是最重要的指標(biāo)。我們觀看到的大屏幕拼接動(dòng)態(tài)效果是由一幀一幀圖片快速顯示而產(chǎn)生的。根據(jù)正常的人眼視覺殘留水平系統(tǒng)要達(dá)到顯示流暢的畫面,1 s 要處理至少25 張圖片,也就是說整個(gè)程序一次圖像處理流程不會(huì)超過40 ms.下面本文將分析一下該系統(tǒng)的時(shí)效性。
由于圖像采集部分和處理部分采用的是異步方式,時(shí)間復(fù)用,而顯然處理部分的耗時(shí)又遠(yuǎn)遠(yuǎn)超過采集部分,所以只列出處理部分的時(shí)間消耗,又因?yàn)樵摬糠中手饕茱@卡GPU 性能影響,所以之對(duì)比不同型號(hào)GPU 的時(shí)間消耗情況。具體如表1所示。
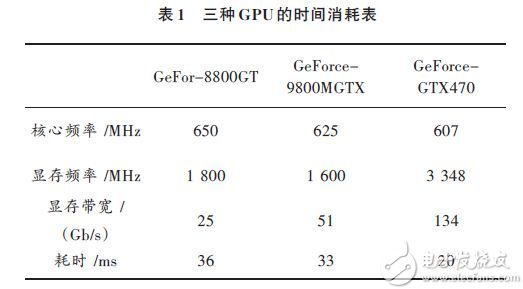
由此我們看出采用GeForce8800GT 顯卡可以基本上完成顯示功能,而采用GeForceGTX470則可以每秒鐘顯示35~40張圖片,是用戶完全感覺流暢的視頻體驗(yàn)。
3 結(jié)語
今年來大屏幕對(duì)計(jì)算機(jī)操作演示的需求越來越多,而高性能顯卡的發(fā)展又促使GPU計(jì)算逐漸成為大規(guī)模并行計(jì)算重要的解決途徑。本系統(tǒng)采用了CUDA技術(shù)實(shí)現(xiàn)了視頻拼接系統(tǒng),目前本系統(tǒng)采用兩個(gè)雙頭顯卡組成顯示功能模塊最多實(shí)現(xiàn)四屏拼接,如果需要更多屏幕拼接顯示時(shí)可以考慮使用網(wǎng)絡(luò)C-S 結(jié)構(gòu)進(jìn)行擴(kuò)展。由于耗時(shí)的圖像處理部分完全有GPU 進(jìn)行計(jì)算,屏幕越多需要計(jì)算的內(nèi)容也隨之增多,而同時(shí)系統(tǒng)顯卡數(shù)量也會(huì)增多,所以該系統(tǒng)不會(huì)隨著拼接屏幕增多而性能下降。由于系統(tǒng)總體采用并行技術(shù),所以將來可以方便地為系統(tǒng)加入時(shí)下流行的人機(jī)互動(dòng)模塊、真實(shí)感渲染模塊等部分,使之真正成為一款高性能多媒體展示系統(tǒng),給用戶一個(gè)全方位真實(shí)的體驗(yàn)。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4989瀏覽量
103093 -
gpu
+關(guān)注
關(guān)注
28文章
4741瀏覽量
128963 -
CUDA
+關(guān)注
關(guān)注
0文章
121瀏覽量
13631 -
分屏器
+關(guān)注
關(guān)注
0文章
4瀏覽量
10753
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
別墅能源管理系統(tǒng)通信設(shè)計(jì)方案
智能家居系統(tǒng)設(shè)計(jì)方案
打破英偉達(dá)CUDA壁壘?AMD顯卡現(xiàn)在也能無縫適配CUDA了
復(fù)雜電磁環(huán)境模擬系統(tǒng)設(shè)計(jì)方案
電磁頻譜數(shù)據(jù)綜合管理系統(tǒng)設(shè)計(jì)方案
電磁頻譜管理系統(tǒng)設(shè)計(jì)方案
電磁軌跡預(yù)測(cè)分析系統(tǒng)設(shè)計(jì)方案
工廠視頻智能分析系統(tǒng)解決方案 TensorFlow
UPS系統(tǒng)設(shè)計(jì)方案解讀
光伏儲(chǔ)能系統(tǒng)設(shè)計(jì)方案
Keil使用AC6編譯提示CUDA版本過高怎么解決?
LED顯示屏設(shè)計(jì)方案
基于 PCIe 的多路視頻采集與顯示子系統(tǒng)介紹
V4L2視頻采集,基于PCIe的多路視頻采集與顯示子系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論