 詳細解析GPU的算法的3大優勢以及并行化的研究問題
詳細解析GPU的算法的3大優勢以及并行化的研究問題
GPU計算的目的即是計算加速。相比于CPU,其具有以下三個方面的優勢:
1
并行度高:GPU的Core數遠遠多于CPU,從而GPU的任務并發度也遠高于CPU;
2
內存帶寬高:GPU的內存系統帶寬幾十倍高于CPU;
3
運行速度快:GPU在浮點運算速度上較之CPU也具有絕對優勢。
另一方面,GPU采用的SIMD(Single Instruction Multiple Data)架構,這決定了其對執行的任務具有特定的要求(如不適合判斷邏輯過多的任務,數據大小不可控的任務等)。而且,應用程序在GPU上也需有特定的實現,包括算法的GPU并行化,程序的定制等。因此,針對GPU并行處理的研究成為一大研究熱點。
現有GPU采用SIMD方式執行,即所有線程塊在同一時刻執行相同的程序,從而若這些線程塊處理的數據量相差大,或計算量分布不均,便會帶來線程塊的負載不均,進而影響整個任務執行效率。這類問題實則常見的Skew Handling或Load Inbalance問題。
應用算法的GPU并行化之所以成為一個研究問題而不僅僅是工程問題,這其中的主要的問題在于
1GPU不支持內存的動態分配,從而對于輸出結果大小不確定的任務是一個極大的挑戰;2GPU的SIMD特性使得很多算法不易很好實現,即如何充分利用GPU線程塊的并行度;3共享數據的競爭讀寫,共享數據的鎖機制帶來大量的等待時間消耗。
GPU作為一種協處理器,其的執行受CPU調度。在實際應用中,GPU更多的也是配合CPU工作,從而基于CPU/GPU異構系統的統一任務調度更具實用意義,也是有關GPU的重要研究方面。
GPU采用SIMD架構,各線程塊在同一時刻執行相同的Instruction,但對應的是不同的數據。但事實上,GPU線程塊具有如下特征:
每個線程塊只對應于一個的流處理器(SM),即其只能被該對應的SM執行,而一個SM可以對應多個線程塊;SM在執行線程塊時,線程塊中的線程以Warp(每32個線程)為單位調度及并行執行;
線程塊內的線程可同步,而不同線程塊的同步則只能由CPU調用同步命令完成;
不同線程塊的運行相互獨立。
因此,為不同的線程塊分配不同的任務,使得GPU做到任務并行,最大化GPU的利用成為可能并具有重要的研究意義。
-
gpu
+關注
關注
28文章
4740瀏覽量
128951 -
并行化
+關注
關注
0文章
9瀏覽量
2850
原文標題:基于GPU的算法并行化
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

【招聘】算法、圖像檢索、嵌入式、測試、架構、GPU優化等職位(bj&sh)
請問Mali GPU的并行化計算模型是怎樣構建的?
求大佬分享一種基于GPU的Voronoi圖并行柵格生成算法
基于GPU的并行APSP問題的研究
基于GPU的遙感圖像融合并行算法研究
基于GPU的并行化運動目標檢測方法的研究
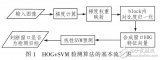
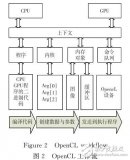
基于Spark的BIRCH算法并行化的設計與實現
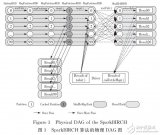
基于GPU的數字圖像并行處理研究

基于Hadoop平臺的LDA算法的并行化實現

基于自適應線程束的GPU并行PSO算法





 工商網監
工商網監
評論