") 袁進(jìn)輝:分享了深度學(xué)習(xí)框架方面的技術(shù)進(jìn)展
袁進(jìn)輝:分享了深度學(xué)習(xí)框架方面的技術(shù)進(jìn)展
來(lái)源:微軟研究院AI頭條
概要:1月17日,院友袁進(jìn)輝博士回到微軟亞洲研究院做了題為《打造最強(qiáng)深度學(xué)習(xí)引擎》的報(bào)告,分享了深度學(xué)習(xí)框架方面的技術(shù)進(jìn)展。
1月17日,院友袁進(jìn)輝博士回到微軟亞洲研究院做了題為《打造最強(qiáng)深度學(xué)習(xí)引擎》的報(bào)告,分享了深度學(xué)習(xí)框架方面的技術(shù)進(jìn)展。報(bào)告中主要講解了何為最強(qiáng)的計(jì)算引擎?專(zhuān)用硬件為什么快?大規(guī)模專(zhuān)用硬件面臨著什么問(wèn)題?軟件構(gòu)架又應(yīng)該解決哪些問(wèn)題?
首先,我們一起來(lái)開(kāi)一個(gè)腦洞:想象一個(gè)最理想的深度學(xué)習(xí)引擎應(yīng)該是什么樣子的,或者說(shuō)深度學(xué)習(xí)引擎的終極形態(tài)是什么?看看這會(huì)給深度學(xué)習(xí)框架和AI專(zhuān)用芯片研發(fā)帶來(lái)什么啟發(fā)。
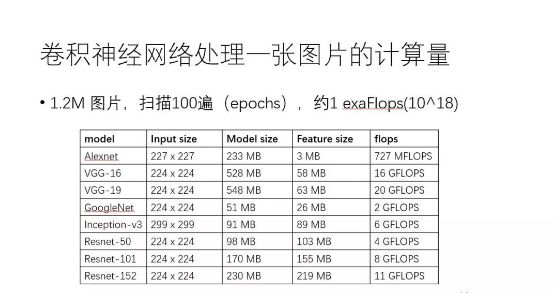
以大家耳熟能詳?shù)木矸e神經(jīng)網(wǎng)絡(luò)CNN 為例,可以感覺(jué)一下目前訓(xùn)練深度學(xué)習(xí)模型需要多少計(jì)算力。下方這張表列出了常見(jiàn)CNN模型處理一張圖片需要的內(nèi)存容量和浮點(diǎn)計(jì)算次數(shù),譬如VGG-16網(wǎng)絡(luò)處理一張圖片就需要16Gflops。值得注意的是,基于ImageNet數(shù)據(jù)集訓(xùn)練CNN,數(shù)據(jù)集一共大約120萬(wàn)張圖片,訓(xùn)練算法需要對(duì)這個(gè)數(shù)據(jù)集掃描100遍(epoch),這意味著10^18次浮點(diǎn)計(jì)算,即1exaFlops。簡(jiǎn)單演算一下可發(fā)現(xiàn),基于一個(gè)主頻為2.0GHz的CPU core來(lái)訓(xùn)練這樣的模型需要好幾年的時(shí)間。
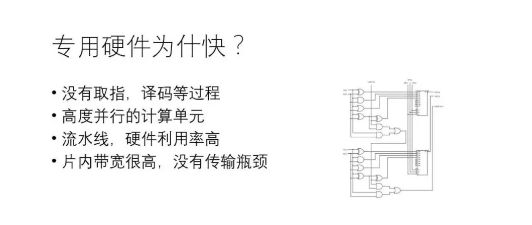
專(zhuān)用硬件比通用硬件(如CPU、GPU)快,有多種原因,主要包括:(1)通用芯片一般經(jīng)歷“取指-譯碼-執(zhí)行”(甚至包括“取數(shù)據(jù)”)的步驟才能完成一次運(yùn)算,專(zhuān)用硬件大大減小了“取指-譯碼”等開(kāi)銷(xiāo),數(shù)據(jù)到達(dá)即執(zhí)行;(2)專(zhuān)用硬件控制電路復(fù)雜度低,可以在相同的面積下集成更多對(duì)運(yùn)算有用的器件,可以在一個(gè)時(shí)鐘周期內(nèi)完成通用硬件需要數(shù)千上萬(wàn)個(gè)時(shí)鐘周期才能完成的操作;(3)專(zhuān)用硬件和通用硬件內(nèi)都支持流水線(xiàn)并行,硬件利用率高;(4)專(zhuān)用硬件片內(nèi)帶寬高,大部分?jǐn)?shù)據(jù)在片內(nèi)傳輸。顯然,如果不考慮物理現(xiàn)實(shí),不管什么神經(jīng)網(wǎng)絡(luò),不管問(wèn)題的規(guī)模有多大,都實(shí)現(xiàn)一套專(zhuān)用硬件是效率最高的做法。問(wèn)題是,這行得通嗎?
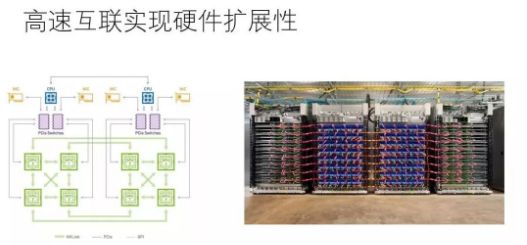
現(xiàn)實(shí)中,不管是通用硬件(如GPU)還是專(zhuān)用硬件(如TPU) 都可以通過(guò)高速互聯(lián)技術(shù)連接在一起,通過(guò)軟件協(xié)調(diào)多個(gè)設(shè)備來(lái)完成大規(guī)模計(jì)算。使用最先進(jìn)的互聯(lián)技術(shù),設(shè)備和設(shè)備之間傳輸帶寬可以達(dá)到100Gbps或者更多,這比設(shè)備內(nèi)部帶寬低上一兩個(gè)數(shù)量級(jí),不過(guò)幸好,如果軟件“調(diào)配得當(dāng)”,在這個(gè)帶寬條件下也可能使得硬件計(jì)算飽和。當(dāng)然,“調(diào)配得當(dāng)”技術(shù)挑戰(zhàn)極大,事實(shí)上,單個(gè)設(shè)備速度越快,越難把多個(gè)設(shè)備“調(diào)配得當(dāng)”。
當(dāng)前深度學(xué)習(xí)普遍采用隨機(jī)梯度下降算法(SGD),一般一個(gè)GPU處理一小塊兒數(shù)據(jù)只需要100毫秒的時(shí)間,那么問(wèn)題的關(guān)鍵就成了,“調(diào)配”算法能否在100毫秒的時(shí)間內(nèi)為GPU處理下一塊數(shù)據(jù)做好準(zhǔn)備,如果可以的話(huà),那么GPU就會(huì)一直保持在運(yùn)算狀態(tài),如果不可以,那么GPU就要間歇性的停頓,意味著設(shè)備利用率降低。理論上是可以的,有個(gè)叫運(yùn)算強(qiáng)度(Arithmetic intensity)的概念,即flops per byte,表示一個(gè)字節(jié)的數(shù)據(jù)上發(fā)生的運(yùn)算量,只要這個(gè)運(yùn)算量足夠大,意味著傳輸一個(gè)字節(jié)可以消耗足夠多的計(jì)算量,那么即使設(shè)備間傳輸帶寬低于設(shè)備內(nèi)部帶寬,也有可能使得設(shè)備處于滿(mǎn)負(fù)荷狀態(tài)。進(jìn)一步,如果采用比GPU更快的設(shè)備,那么處理一塊兒數(shù)據(jù)的時(shí)間就比100毫秒更低,譬如10毫秒,在給定的帶寬條件下,“調(diào)配”算法能用10毫秒的時(shí)間為下一次計(jì)算做好準(zhǔn)備嗎?事實(shí)上,即使是使用不那么快(相對(duì)于TPU 等專(zhuān)用芯片)的GPU,當(dāng)前主流的深度學(xué)習(xí)框架在某些場(chǎng)景(譬如模型并行)已經(jīng)力不從心了。
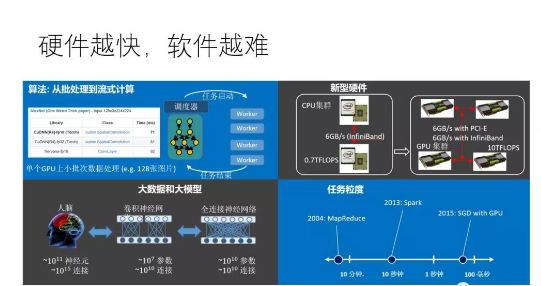
一個(gè)通用的深度學(xué)習(xí)軟件框架要能對(duì)任何給定的神經(jīng)網(wǎng)絡(luò)和可用資源都能最高效的“調(diào)配”硬件,這需要解決三個(gè)核心問(wèn)題:(1)資源分配,包括計(jì)算核心,內(nèi)存,傳輸帶寬三種資源的分配,需要綜合考慮局部性和負(fù)載均衡的問(wèn)題;(2)生成正確的數(shù)據(jù)路由(相當(dāng)于前文想象的專(zhuān)用硬件之間的連線(xiàn)問(wèn)題);(3)高效的運(yùn)行機(jī)制,完美協(xié)調(diào)數(shù)據(jù)搬運(yùn)和計(jì)算,硬件利用率最高。
事實(shí)上,這三個(gè)問(wèn)題都很挑戰(zhàn),本文暫不討論其解法,假設(shè)我們能夠解決這些問(wèn)題的話(huà),會(huì)有什么好處呢?
假設(shè)我們能解決前述的三個(gè)軟件上的難題,那就能“魚(yú)與熊掌兼得”:軟件發(fā)揮靈活性,硬件發(fā)揮高效率,任給一個(gè)深度學(xué)習(xí)任務(wù),用戶(hù)不需要重新連線(xiàn),就能享受那種“無(wú)限大專(zhuān)用硬件”的性能,何其美好。更令人激動(dòng)的是,當(dāng)這種軟件得以實(shí)現(xiàn)時(shí),專(zhuān)用硬件可以比現(xiàn)在所有AI芯片都更簡(jiǎn)單更高效。讀者可以先想象一下怎么實(shí)現(xiàn)這種美好的前景。

讓我們重申一下幾個(gè)觀(guān)點(diǎn):(1)軟件真的非常關(guān)鍵;(2)我們對(duì)宏觀(guān)層次(設(shè)備和設(shè)備之間)的優(yōu)化更感興趣;(3)深度學(xué)習(xí)框架存在一個(gè)理想的實(shí)現(xiàn),正如柏拉圖心中那個(gè)最圓的圓,當(dāng)然現(xiàn)有的深度學(xué)習(xí)框架還相距甚遠(yuǎn);(4)各行各業(yè)的公司,只要有數(shù)據(jù)驅(qū)動(dòng)的業(yè)務(wù),最終都需要一個(gè)自己的“大腦”,這種“大腦”不應(yīng)該只被少數(shù)巨頭公司獨(dú)享。

-
硬件
+關(guān)注
關(guān)注
11文章
3328瀏覽量
66223 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5503瀏覽量
121162 -
cnn
+關(guān)注
關(guān)注
3文章
352瀏覽量
22215
原文標(biāo)題:深度學(xué)習(xí)引擎的終極形態(tài)是什么?
文章出處:【微信號(hào):AItists,微信公眾號(hào):人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深度學(xué)習(xí)在自然語(yǔ)言處理方面的研究進(jìn)展





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論