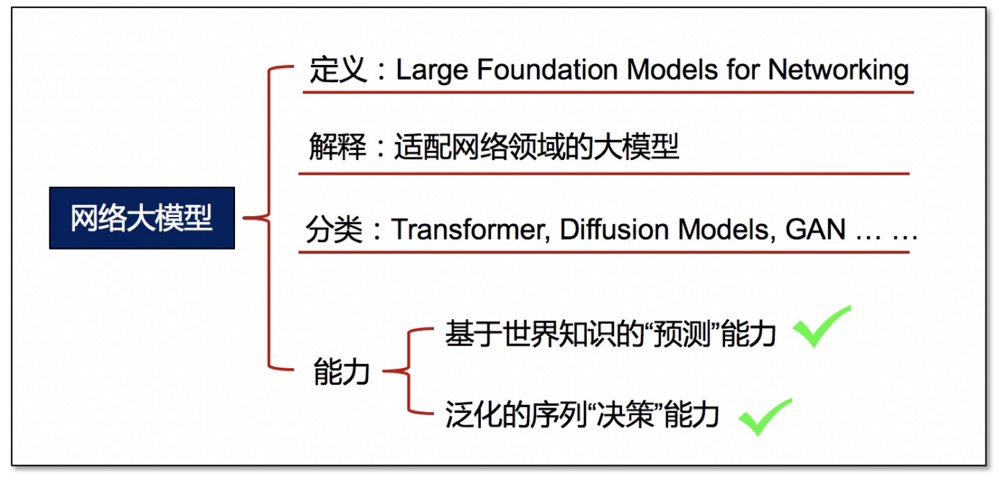
 什么是網絡大模型技術
什么是網絡大模型技術
作者簡介:黃玉棟,北郵博士,研究方向時敏確定性網絡與網絡智能
當前,生成式人工智能被認為是21世紀最重要的技術突破之一,其為人類社會帶來了工作范式的轉變,極大地提高了人類生產力。比如,2022年12月ChatGPT橫空出世,以火箭般的流行速度短短五天吸引了超過100萬用戶,兩個月后月活用戶達到1億,其為代表的對話系統達到接近人類水平,不僅能幫助人類完成寫郵件、寫代碼、撰寫報告、生成圖像、生成視頻等工作,甚至在AlphaCode程序設計競賽中擊敗了45.7%的程序員,通用人工智能被認為有望重塑或取代當前80%的人類工作。
2023年1月,生物界首次實現從零合成全新蛋白,2023年2月,Meta開源LlaMA模型,2023年3月,谷歌打造出PaLM-E具身智能機器人,此外,生成式人工智能已被全面用于分子結構預測、芯片設計、蛋白質生成、通信信道預測等生物、醫療、材料、機器人、信息科學領域。
那么,生成式人工智能可否用于網絡領域?有哪些場景和關鍵技術?跟以前的智能有什么區別?前沿進展如何?怎么實現?這是大家關心和熱議的話題。本文作為科普入門資料,將以通俗易懂的方式,以基于Transformer架構的大模型技術為主線,分析“網絡大模型”的核心原理、關鍵技術、場景應用和發展趨勢。
什么是網絡大模型技術?
本文將適配網絡領域的大模型技術稱為“網絡大模型“技術,即“Large Foundation Models for Networking”。其中,基礎模型有很多種,比如Transformer,Diffusion Models, GAN,以及它們的衍生改進版本,不同基礎模型服務于不同的模態(即輸入數據)和任務場景。縱然模型千變萬化,其本質卻始終如一。本文將網絡大模型的主要能力分為兩種,第一種是基于世界知識的“預測”能力,第二種是泛化的序列“決策”能力。接下來首先介紹第一種能力。
基于世界知識的預測能力
什么是預測?
回顧一個經典的例子,給你三組數據,第一組x=1,y=1.05,第二組x=2,y=4.17, 第三組x=4,y=15.99,請猜一下x=3時,y應該等于多少。
人們通過分析,可以得出數據滿足y=x*x的規律,因此x=3時,y大約等于9。這就是一個最簡單的預測的過程,可以被描述為y=F(x),其中F是一個函數。但真實問題中很多輸入輸出關系是非線性的復雜映射,需要用海量數據來擬合,因此有了神經網絡的概念,并用一個損失函數來最小化預測的誤差。
比如例子中實際采集的數據是x=3時,y=9.01,那么輸出9就存在一定的誤差。一個神經網絡模型包含輸入層、隱藏層和輸出層,訓練的過程就是不斷的輸入x=3,讓模型調整隱藏層計算權重去猜y=9.8,y=9.5,直到猜到了y=9,就認為模型學會了映射關系,訓練停止。然后推理的過程就是輸入x=3,模型直接輸出y=9。
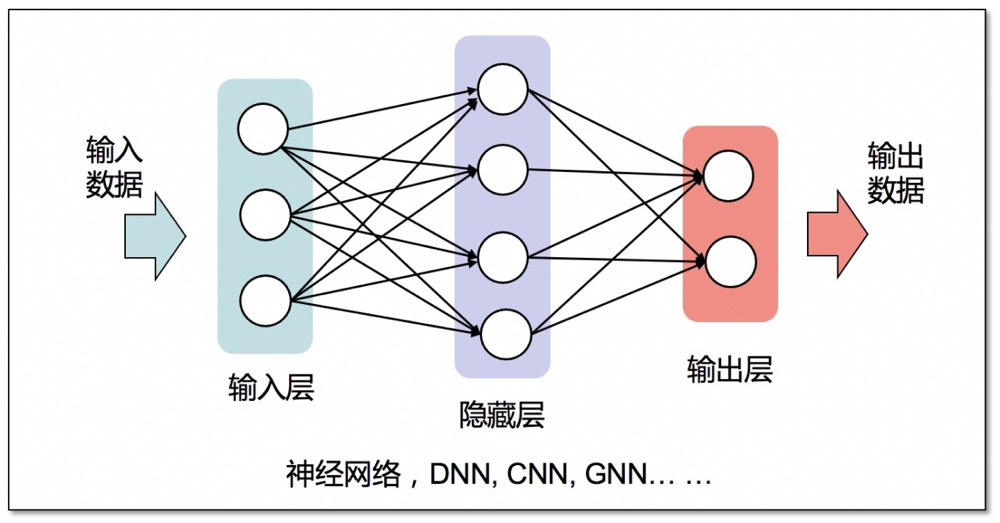
總結一下,本質上模型是用來預測輸入數據和輸出數據之間的非線性關系的,包括訓練和推理兩個步驟,有效數據量越多,模型的預測精度通常越高。其次,模型并不能脫離數據集“憑空產生結果”,要先在訓練過程中通過已知的輸入-輸出對來學習,即監督學習。
此外,模型學習的是產生結果的概率,而非結果本身。雖然在示例中輸入和輸出只是簡單的數字,但在實際應用中,輸入輸出可能是文本、圖像、拓撲、視頻等。針對不同的輸入數據結構和特征,神經網絡模型被不斷改進,例如,用于圖像處理的卷積神經網絡(CNN)和用于處理拓撲的圖神經網絡(GNN)等,在此按下不表。
Transformer的基本原理
Transformer是一種在2017年被提出的廣泛用于自然語言處理的神經網絡結構,即用來預測詞與詞之間的映射關系。舉個問答的例子,如下圖所示,輸入問題是“五月一日是什么節日?”我們希望輸出回答是“五月一日是勞動節”。
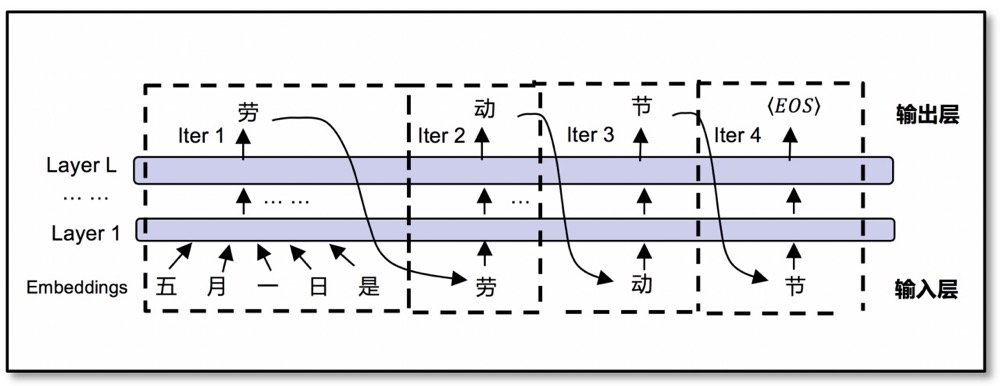
那怎么讓計算機理解語言和文字?首先,需要將每個詞作為一個最小處理單元,即token,然后把這些token轉換為向量,即embeddings。比如假設“月”字用向量[1,0,0,0]表示,“日”字用向量[0,1,0,0]表示。有了向量以后就可以進行矩陣運算,就可以被計算機所“理解”了。然后,Transformer里提出了一個attention注意力機制,用來計算一個輸入文本序列中每個詞與其他詞的相關性,并通過位置編碼來表明序列中詞的位置信息,也就是先看一下前面幾個詞是“五月一日是”,然后開始猜下一個詞概率最大可能是“勞”,再下一個詞是“動”,再下一個詞是“節”。
Transformer的結構優勢在于具有特別好的可擴展性,比如以前的自然語言處理模型很難捕捉長距離依賴,也就是句子長了就丟失了上下文關系信息,再比如attention能夠并行計算,大大提高了訓練的速度。
此外,以前是每個任務都需要單獨訓練一個模型,而Transformer架構非常通用,能很好地適應機器翻譯、文本生成、問答系統等各種任務,這使得模型可以輕松地擴展到更大規模,并實現“one model for all”的效果。
基于世界知識的“大”模型
如果故事到這里結束,Transformer僅僅只會停留在自然語言處理領域。然而接下來,OpenAI大力出奇跡,開啟了大模型新紀元。試想一下,如果把所有已知的詞都作為token,那世界知識能否被編碼成能被計算機“理解”的詞典?神經網絡模型能否誕生出類似人腦的理解能力甚至超越人類的智能?2018年OpenAI發布了首個GPT(Generative Pre-trained Transformer)模型,并提出了無監督預訓練+有監督微調的訓練方法。
最開始GPT-1具有1.17億個模型參數,預訓練數據量約為5GB,到2020年,GPT-3的模型參數量達到了驚人的1750億,預訓練數據量增長到了45TB。在“大”模型背后,Scaling Law縮放法則指出,通過在更多數據上訓練更大的模型,模型性能將不斷提升。且模型達到一定的臨界規模后,表現出了一些開發者最開始未能預測的、更復雜的能力特性,即“涌現”的能力。另外,GPT背后還有大量的工程考慮,比如基于任務的模型微調、提示詞工程、人類意圖對齊等等。
網絡大模型
網絡大模型的主要應用
現今,開源和閉源的基礎大模型已經觸手可及,將大模型適配網絡應用的研究更是如火如荼。接下來,本文將從網絡領域已有數據的角度把大模型應用分為六類,并簡要分析前沿研究進展。
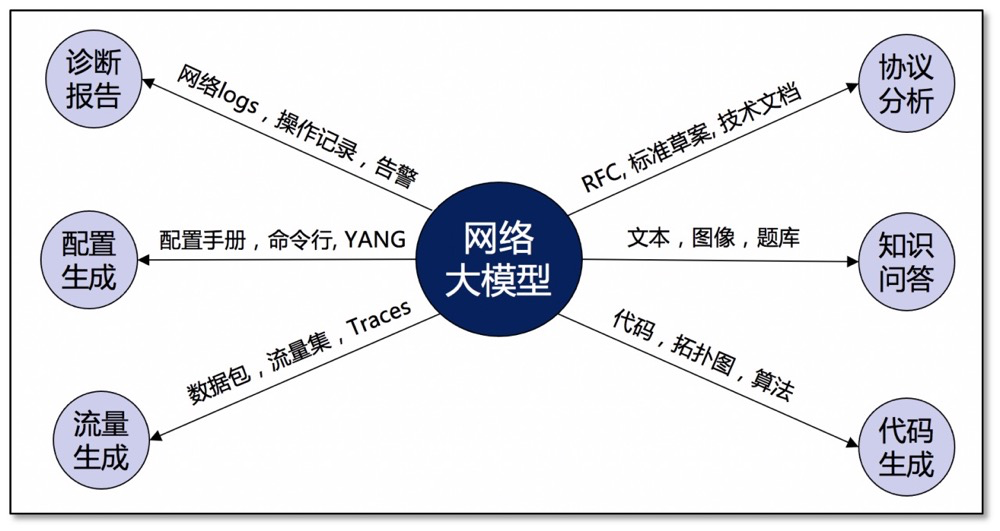
網絡知識問答:網絡知識也屬于世界知識,網絡知識題庫是很好的已有的高質量任務數據集,因此,一個直白的做法是,用多選題等方法對各種基礎模型進行測評,查看其是否掌握、掌握了多少的網絡領域知識,以及探討如何通過微調、提示詞等方法釋放基礎模型在網絡領域的能力。
比如文獻 ^[1]^ 中構建了包含一萬條問答題的TeleQnA數據集來評估大語言模型對電信領域知識的掌握程度,文獻 ^[2]^ 中,包含5732個多選題的NetEval數據集被用來評估比較了26種開源的大語言模型。此外,問答的能力還可被廣泛用于運營商智能客服、以及網絡從業人員的教育培訓。
網絡代碼生成:另一個直白的做法是用大模型來生成網絡領域的工程代碼,比如Python腳本以及linux命令行。此外,通過調用各種代碼庫,還能直接生成用于網絡拓撲、網絡算法等的基礎代碼。圖是網絡中十分標準的結構化數據,文獻 ^[3]^ 中提出用大語言模型生成的代碼分析和管理網絡拓撲圖,比如添加鏈路或者節點地址分類。文獻 ^[4]^ 還提出了利用大語言模型來復現網絡研究論文的代碼的想法,并在小規模的實驗中證明了可行性。
網絡協議分析:網絡協議是網絡設備研發和網絡系統運行的基礎,面對海量的錯綜復雜的RFC文檔,亟需自動化的協議理解能力。然而,不同于普通的文本,協議中包含了規則、狀態、通信流、數據流圖、消息結構等協議實體,給模型推理的準確度帶來很大的挑戰。文獻 ^[5]^ 利用zero-shot和few-shot等方法評估了GPT-3.5-turbo從RFC文檔中提取有限狀態機的能力。
此外,當前的協議設計流程極其緩慢,且涉及復雜的交互過程和配置參數,比如MAC協議,必須針對具體目的和場景進行定制,例如提高吞吐量、降低功耗、保證公平性等。特別是在異構網絡部署場景下,每個無線接入網,例如5G-NR、Wi-Fi、藍牙、Zigbee,甚至衛星接入網,都有自己的協議和屬性,例如考慮容量、延遲、覆蓋程度、安全性、功耗和成本等屬性。考慮到未來網絡更加復雜和多樣化的設置,每個設備上也許能部署一個網絡協議大模型,通過自適應環境來自動生成合適的協議,并將人類從繁重的協議設計工作中解放出來。
網絡配置生成:網絡中有大量異構設備,例如交換機、路由器和中間件。由于廠商和設備型號各有不同,需要大量專業人員來學習設備手冊和用戶手冊、收集合適的命令、驗證配置模板、以及將模板參數映射到控制器數據庫。在此過程中,即使是單個ACL配置錯誤也可能導致網絡中斷。
考慮到不斷增長的異構云網絡以及大量需要管理的計算和存儲設備,統一的自然語言配置界面對于簡化配置過程和實現自配置網絡至關重要。異構的網絡配置數據包括低級別的ACL規則、CLI命令行,以及封裝的YANG Model、XML、JSON等數據格式規范,文獻 ^[6]^ 中基于BERT模型實現了異構廠商設備的自動化管理,即直接從各類設備手冊中學習并生成統一的網絡配置數據模型。
網絡流量生成:網絡流量集對于網絡仿真、網絡測量、攻擊探測、異常流量檢測、逆向協議解析等任務至關重要,然而常常真實的流量因為隱私問題無法獲得,而手動構造的流量集(比如泊松分布)又在保真度和多樣化方面有很大的欠缺。生成式AI具有很好的“泛化”能力,即能夠學到已有數據分布并生成相似分布的數據,可以被用來生成具有不同特征(比如特定IP地址段、端口分布、不同協議類型、包大小分布、到達間隔、持續時間、流分布)的網絡流量集,文獻 ^[7],[8],[9]^ 分別基于Transformer,GAN,和Diffusion Models架構實現了上述目標。
網絡診斷報告:故障排查對于網絡運營商來說是一項繁瑣而繁重的工作。特別是在大規模廣域網絡中,需要跨地域的不同部門之間的協調,而網絡用戶仍會遭受突然的網絡故障或性能下降,并面臨數億美元的經濟損失。通過將大語言模型集成到網絡診斷系統中,大語言模型能夠根據網絡狀態信息生成故障報告,加速故障定位,并根據報告分析和歷史運行數據給出合理的處理建議。
雖然網絡系統中有大量的Log日志、操作記錄和告警報錯信息,但這些非結構化的數據很難被直接用于訓練。最近,文獻 ^[10]^ 設計了從用戶到工作流(workflow)到數據的對話式網絡診斷系統,能夠將用戶意圖映射到工作模板,并從網絡底層獲取網絡狀態信息來填充模板作為診斷反饋答案。此外,產業界中也有比如Juniper提出了Marvis虛擬網絡助手 ^[11]^ 來實現網絡自動化運維管理。
網絡大模型的關鍵技術
實現以上應用并非易事,從相關文獻可以看到,由于網絡領域存在區別于純文本的規則、公式、協議、約束、數學、符號,直接使用基礎模型效果往往差強人意,需要很多額外的工程工作。
首先,部分網絡領域知識可能未被基礎模型學到,容易導致模型產生“幻覺”,比如某些網絡領域專有名詞和協議規則,需要通過微調的方式,比如參數高效的部分微調方式和LoRA低秩矩陣,來增強模型對網絡知識的理解。微調的哲學在于既要為模型引入網絡領域知識,又要保留模型原本學到的世界知識。
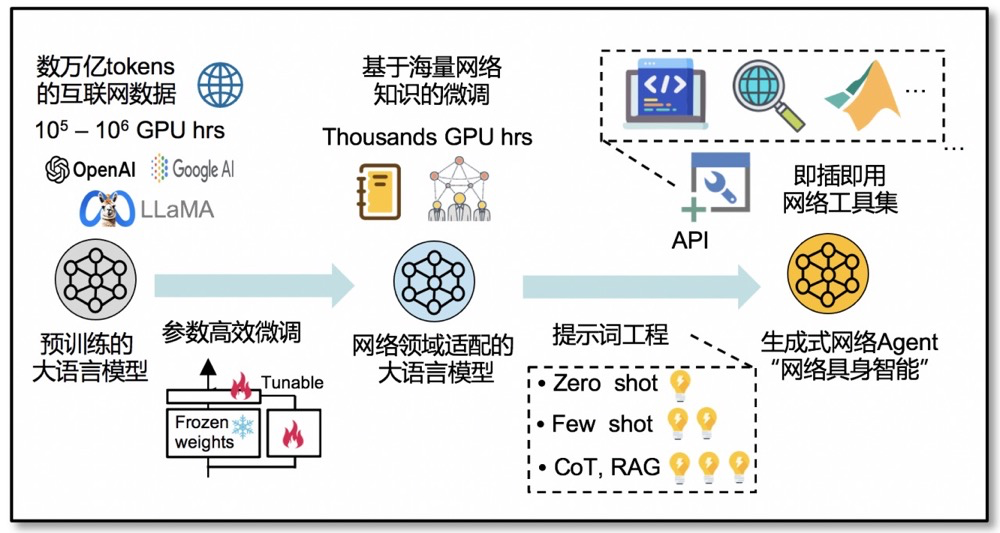
其次,用戶意圖模糊會導致輸入不準確,且許多網絡任務很難用簡單的語言進行表述,因此,需要基于提示詞工程,比如zero-shot, few-shot, 思維鏈,以及RAG檢索增強技術,來構合適的prompt和網絡任務基準測試集;比如思維鏈可以鼓勵大模型采用逐步的推理過程來將復雜的問題拆解為多個簡單子問題,以及通過上傳相關技術文檔供模型檢索來縮小任務范圍并提高推理精度。除了推理精度和推理速度,為了量化網絡大模型的能力,相關的網絡任務層面的屬性和指標,比如回答正確率,任務完成度,生成結果與最優結果之間的數學距離,也待被提出和研究。
另外,考慮到網絡領域存在大量難以被直接用于訓練的非結構化數據,引入Agent技術是一個當前的熱門方向,即通過API等方式,將大語言模型與網絡工具(仿真軟件、監測系統、安全工具、控制器、求解器、搜索引擎)做集成,讓網絡大模型學會使用網絡工具,彌補模型在規劃、計算、求解等方面的短板,最終實現“網絡具身智能”。更多技術細節可參考文獻 ^[12]^ 。下一篇將介紹網絡大模型的第二種能力,即泛化的序列“決策”能力。
-
機器人
+關注
關注
211文章
28562瀏覽量
207702 -
網絡
+關注
關注
14文章
7586瀏覽量
89013 -
人工智能
+關注
關注
1792文章
47514瀏覽量
239228 -
大模型
+關注
關注
2文章
2513瀏覽量
2928
原文標題:秒懂網絡大模型之基于世界知識的預測能力
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于卷積的基礎模型InternImage網絡技術分析
【大語言模型:原理與工程實踐】核心技術綜述
【大語言模型:原理與工程實踐】大語言模型的基礎技術
計算機與網絡技術基礎
基于網絡性能的VoIP語音質量評價模型
網絡中心戰構建模型是什么?
在現場總線中使用藍牙技術替代有線傳輸介質的應用模型
卷積神經網絡模型發展及應用
基于密罐技術的網絡安全模型研究與實現
一種工業通信網絡模型與網絡集成設計

探究Overlay網絡模型和Underlay網絡模型。





 工商網監
工商網監
評論