") 用簡潔的語言來闡述YOLO算法
用簡潔的語言來闡述YOLO算法
YOLO算法,英文全稱是You Only Look Once,直接谷歌英文全稱就能找到那篇論文,同時作者也在github上開源了代碼。需要說明的是這篇推文是關(guān)于yolo v1,還有一個升級版。
顧名思義,這個算法就是只看一遍圖片就能把所有的物體都識別出來,這個算法能夠做到實時的物體檢測,大約能達到40幀每秒,速度是非常快的。那如何去入手這個算法呢?相信大家已經(jīng)看過不少介紹YOLO算法的文章了,所以我在這里也不打算深入去講解這個算法了,而是盡量用簡潔的語言去闡述一下這個如此迷人的算法。

和其它推文最大的不同是,我會介紹如何從實戰(zhàn)的角度去自己去做一個數(shù)據(jù)集,如何讓電腦識別特定的一個物體。
那先來看一下我實現(xiàn)的效果是怎么樣的。首先我隨手找了我桌上的藍色水杯,收集了兩百多張自己水杯的圖片,為了減少工作量,我用水杯的數(shù)據(jù)集去替換了原來是車輛(car)的所有數(shù)據(jù)。經(jīng)過十幾個小時的訓(xùn)練之后,效果如下:

那怎么去實現(xiàn)呢?首先我覺得你要先“懂”這個算法,至少你要了解它是怎么實現(xiàn)的,原理是什么,輸入輸出是什么。為了學(xué)習(xí)這個算法,我也是花了大量時間去看作者的論文和代碼。我覺得論文配合代碼是一個很好的學(xué)習(xí)方式。通過代碼可以很清晰去了解它是如何去實現(xiàn)這個算法的。
這個算法的核心在于它把圖片劃分成了7*7個網(wǎng)格,注意這7*7個網(wǎng)格不是將一張圖片切割成49個小塊,而是說一個網(wǎng)格會對應(yīng)一個輸出結(jié)果。可能會覺得有點抽象,我們先來看圖。

比如說上面這張圖,一共有49個網(wǎng)格,每個網(wǎng)格的任務(wù)就是去判斷這個物體的中心點是否落在該網(wǎng)格,如果是落在自身網(wǎng)格,那好,那這個網(wǎng)格就會跟系統(tǒng)匯報。假定上圖中被標(biāo)記的紅色網(wǎng)格我們把它命名為小格,然后小格發(fā)現(xiàn)這里好像有條狗,于是乎它跟系統(tǒng)匯報說:我這里有條狗,然后系統(tǒng)問了一句:那這條狗有多寬有多高?小格好像有點懵,但是根據(jù)它的經(jīng)驗,小格大概能猜出來,于是回答了系統(tǒng):這條狗大概100像素寬,250像素高吧。到這里,小格的任務(wù)就基本完成了,小格只是49個網(wǎng)格之一,其它的網(wǎng)格也一樣。于是系統(tǒng)就收集了49個網(wǎng)格的意見,然后就得到了下圖。

其實在這張圖片中可以出現(xiàn)49*2=81個預(yù)測框,也就是說沒一個網(wǎng)格可以有對目標(biāo)有兩個預(yù)測,因此最多可以出現(xiàn)81個預(yù)測框。可以在圖中看到,其實會出現(xiàn)很多無用框,相鄰的網(wǎng)格可能會出現(xiàn)相似的結(jié)果,以此我們可以通過極大值抑制過濾一部分的預(yù)測框。然后就可以得到下圖結(jié)果。

但是相信我,即使你已經(jīng)全部理解了上面我說的,你也不一定能一下子看懂代碼,在我閱讀代碼的時候發(fā)現(xiàn)雖然代碼不多,邏輯也比較清晰,但是有一些細節(jié)還是讓人難以理解。那我就帶大家來捋一下吧!
比較重要的代碼主要是在pasal_voc.py、config.py、yolo_net.py和train.py。加載數(shù)據(jù)的代碼在pasal_voc.py里面,代碼并不是很難,不過要注意一點的就是一張圖片的label其實是一個7*7*25的矩陣,一個25的向量組成是這樣的:第一位是0或1,表示是否有物體,然后接下來的四位是邊界框的信息,也就是(x,y,w,h),剩下的就是one-hot編碼表類別。而預(yù)測的結(jié)果是7*7*30的,因為要預(yù)測兩個框。
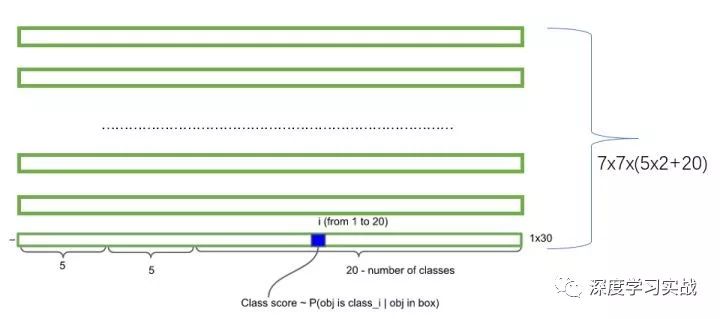
還有一個比較精髓的是它損失函數(shù)的定義,它對每一個預(yù)測值都計算了均方誤差,但是懲罰程度卻是不一樣的。
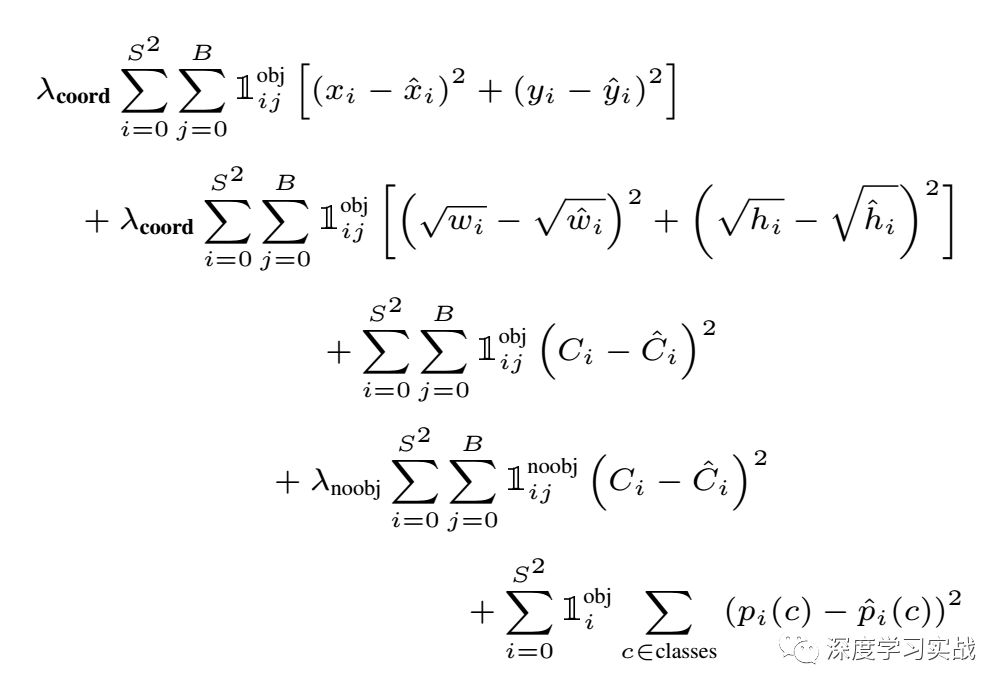
其中λcoord = 5.0, λnoobj = 1.0,λclasses = 2.0,但是這組數(shù)字是這么得來的小編就不知道了,有可能是從大量測試中得到的一組最優(yōu)解,也可能是從數(shù)學(xué)公式推算出來的吧。其實還有很多小細節(jié),是很難描述出來的,如果要把一個小細節(jié)說明白可以就會牽扯到無數(shù)個細節(jié),所以我建議你們自己通過代碼去把細節(jié)搞懂。
在你已經(jīng)了解了代碼之后,就很容易做到文章開頭的那個效果了。那我講解一下我的思路和過程,最重要的還是要自己動手。當(dāng)你去研究過它的數(shù)據(jù)集之后,你會發(fā)現(xiàn)這個數(shù)據(jù)集的標(biāo)注是一個xml文件,每一個圖片就對應(yīng)一個xml文件。當(dāng)你收集好數(shù)據(jù)集之后就可以去做數(shù)據(jù)集標(biāo)記了,但是最簡單的xml文件的格式是要求如下的:

這個是我數(shù)據(jù)集中的標(biāo)注,也是能滿足代碼的最簡單的標(biāo)注,我是自己寫了一個程序幫助我完成標(biāo)記的,但是我推薦你們可以用別人的標(biāo)注工具,因為畢竟別人已經(jīng)寫好了就沒有必要再去重復(fù)造車輪。
這個就是一個標(biāo)注的工具 ,但是我也沒用過,但是看描述應(yīng)該是符合要求的。做好圖片標(biāo)注之后就要考慮如何去修改它的數(shù)據(jù)集呢?難不成一張張粘貼進去,當(dāng)然你可以這樣做,但是工作量是很大的,好吧,那就交給計算機去解決吧。我在加載數(shù)據(jù)集的時候做了一個判斷,如果一旦這張圖片里面有車,我就不加載這個數(shù)據(jù)了,指定一個路徑讓它去加載我們做好的數(shù)據(jù)集。
findcar = 0for obj in objs: cls_ind = obj.find('name').text.lower().strip() if cls_ind == 'car': findcar = 1 break
接下來就是你們思考如何去解決了。當(dāng)你解決這個問題并能訓(xùn)練的時候,如無意外你應(yīng)該能得到和我一樣的結(jié)果,祝你們好運!
-
算法
+關(guān)注
關(guān)注
23文章
4622瀏覽量
93098
原文標(biāo)題:項目實戰(zhàn) | YOLO算法識別特定物體
文章出處:【微信號:gh_a204797f977b,微信公眾號:深度學(xué)習(xí)實戰(zhàn)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
使用C語言進行PID算法實現(xiàn)
用JAVA語言實現(xiàn)RSA公鑰密碼算法
用C語言實現(xiàn)DES算法
用C語言實現(xiàn)FFT算法
如何編寫高效簡潔的C語言代碼
『 RJIBI 』-基于FPGA的YOLO-V3物體識別計算套件
如何使用Zynq SoC硬件加速實現(xiàn)改進TINY YOLO實時車輛檢測的算法
基于深度學(xué)習(xí)YOLO系列算法的圖像檢測
嵌入式設(shè)備的YOLO網(wǎng)絡(luò)剪枝算法
目標(biāo)檢測—YOLO的重要性!
基于YOLO算法實現(xiàn)鋼筋數(shù)量的智能盤點
目標(biāo)檢測YOLO系列算法的發(fā)展過程
目標(biāo)檢測算法YOLO的發(fā)展史和原理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論