 提出了一個用于求解數學應用題的增強學習框架,準確率提升15%
提出了一個用于求解數學應用題的增強學習框架,準確率提升15%
增強學習和人類學習的機制非常相近,DeepMind已經將增強學習應用于AlphaGo以及Atari游戲等場景當中。阿凡題研究院、電子科技大學和北京大學的合作研究首次提出了一種基于DQN(Deep Q-Network)的算術應用題自動求解器,能夠將應用題的解題過程轉化成馬爾科夫決策過程,并利用BP神經網絡良好的泛化能力,存儲和逼近增強學習中狀態-動作對的Q值。實驗表明該算法在標準測試集的表現優異,將平均準確率提升了將近15%。
研究背景
自動求解數學應用題(MWP)的研究歷史可追溯到20世紀60年代,并且最近幾年繼續吸引著研究者的關注。自動求解應用數學題首先將人類可讀懂的句子映射成機器可理解的邏輯形式,然后進行推理。該過程不能簡單地通過模式匹配或端對端分類技術解決,因此,設計具有語義理解和推理能力的應用數學題自動求解器已成為通向通用人工智能之路中不可缺少的一步。
對于數學應用題求解器來說,給定一個數學應用題文本,不能簡單的通過如文本問答的方式端到端的來訓練,從而直接得到求解答案,而需要通過文本的處理和數字的推理,得到其求解表達式,從而計算得到答案。因此,該任務不僅僅涉及到對文本的深入理解,還需要求解器具有很強的邏輯推理能力,這也是自然語言理解研究中的難點和重點。
近幾年,研究者們從不同的角度設計算法,編寫求解系統,來嘗試自動求解數學應用題,主要包括基于模板的方法,基于統計的方法,基于表達式樹的方法,以及基于深度學習生成模型的方法。目前,求解數學應用題相關領域,面臨訓練數據集還不夠多,求解算法魯棒性不強,求解效率不高,求解效果不好等多種問題。由于數學題本身需要自然語言有足夠的理解,對數字,語義,常識有極強的推理能力,然而大部分求解方法又受到人工干預較多,通用性不強,并且隨著數據復雜度的增加,大部分算法求解效果急劇下降,因此設計一個求解效率和效果上均有不錯表現的自動求解器,是既困難又非常重要的。
相關工作
算術應用題求解器:
作為早期的嘗試,基于動詞分類,狀態轉移推理的方法,只能解決加減問題。為了提高求解能力,基于標簽的方法,設計了大量映射規則,把變量,數字映射成邏輯表達式,從而進行推理。由于人工干預過多,其擴展困難。
基于表達式樹的方法,嘗試識別相關數字,并對數字對之間進行運算符的分類,自底向上構建可以求解的表達式樹。除此之外,會考慮一些比率單位等等的限制,來進一步保證構建的表達式的正確性。基于等式樹的方法,采用了一個更暴力的方法,通過整數線性規劃,枚舉所有可能的等式樹。基于樹的方法,都面臨著隨著數字的個數的增減,求解空間呈指數性增加。
方程組應用題求解器:
對于方程組應用題的求解,目前主要是基于模板的方法。該方法需要將文本分類為預定義的方程組模板,通過人工特征來推斷未知插槽的排列組合,把識別出來的數字和相關的名詞單元在插槽中進行填充。基于模板的方法對數據的依賴性較高,當同一模板對應的題目數量減少,或者模板的復雜性增加時,這種方法的性能將急劇下降。
本文的主要貢獻如下:
第一個嘗試使用深度增強學習來設計一個通用的數學應用題自動求解框架
針對應用題場景,設計了深度Q網絡相應的狀態,動作,獎勵函數,和網絡結構。
在主要的算術應用題數據集上驗證了本文提出的方法,在求解效率和求解效果上都取得了較好的結果。
方案介紹
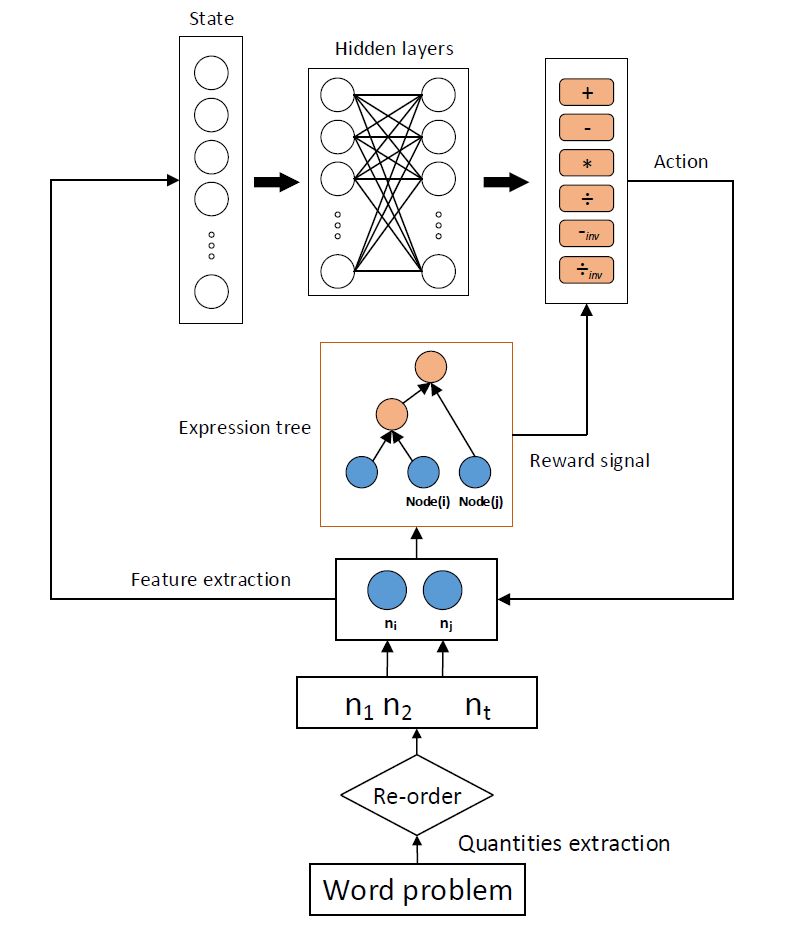
基于深度Q網絡的數學應用題求解器
本文提出的框架如上圖所示。給出一個數學應用題,首先采用數字模式提取用于構建表達式樹的相關數字,然后根據重排序制定的規則,對提取出來的相關數字進行順序調整,比如對于“3+4*5”,我們希望優先計算4*5,這里的數字5,對應的文本段是“5元每小時“”,顯然這里的數字“5”的單位是“元/小時”,當數字“4”的單位是“小時”,數字“3”的單位是“元”,遇到這種情況,調整4和5放到數字序列的最前面,隨后,用已排好序的數字序列自底向上的構建表達式樹。首先,根據數字“4”和數字“5”各自的信息,相互之間的信息,以及與問題的關系,提取相應的特征作為增強學習組件中的狀態。
然后,將此特征向量作為深度Q網絡中前向神經網絡的輸入,得到“+”,“-”,反向“-”,“*”,“/”,反向“/”六種動作的Q值,根據epsilon-greedy選擇合適的操作符作為當前的動作,數字“4”和“5”根據當前采取的動作,開始構建表達式樹。下一步,再根據數字”4“和數字”3“,或者數字”5“和數字“3”,重復上一步的過程,把運算符數字的最小公共元祖來構建表達式樹。直到沒有多余相關數字,建樹結束。隨后將詳細介紹深度Q網絡的各個部件的設計方式。
狀態:
對于當前的數字對,根據數字模式,提取單個數字,數字對之間,問題相關的三類特征,以及這兩個數字是否已經參與表達式樹的構建,作為當前的狀態。其中,單個數字,數字對,問題相關這三類特征,有助于網絡選擇正確的運算符作為當前的動作;數字是否參與已經參與表達式樹的構建,暗示著當前數字對在當前表達式樹所處的層次位置。
動作:
因為本文處理的是簡單的算術應用題,所以只考慮,加減乘除四則運算。在構建樹的過程中,對于加法和乘法,兩個數字之間不同的數字順序將不影響計算結果,但是減法和除法不同的順序將導致不同的結果。由于,我們實現確定好數字的順序,所以添加反向減法和反向除法這兩個操作是非常有必要的。因此,總共加減乘除,反向減法和除法6種運算符作為深度Q網絡需要學習的動作。
獎勵函數:
在訓練階段,深度Q網絡根據當前兩個數字,選擇正確的動作,得到正確的運算符,環境就反饋一個正值作為獎勵,否則反饋一個負值作為懲罰。
參數學習:
本文采用了一個兩層的前向神經網絡用于深度Q網絡計算期望的Q值。網絡的參數θ將根據環境反饋的獎勵函數來更新學習。本文使用經驗重放存儲器來存儲狀態之間的轉移,并從經驗重放存儲器中批量采樣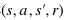 ,用于更新網絡參數。模型的損失函數如下:
,用于更新網絡參數。模型的損失函數如下:
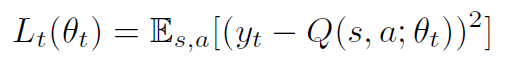
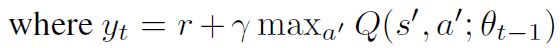
利用損失函數的梯度值來更新參數,來縮小預測的Q值和期望的目標Q值的差距,公式如下:
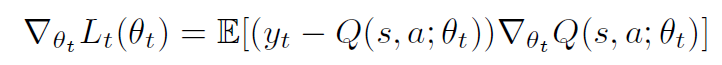
算法流程如下:

實驗
本文采用了AI2, IL, CC這三個算術應用題數據集,進行實驗。其中AI2有395道題目,題目中含有不相關的數字,只涉及加減法。IL有562道題目,題目中含有不相關的數字,只涉及加減乘除單步運算;CC有600道題,題目中不含有不相關的數字,涉及加減乘除的兩步運算。
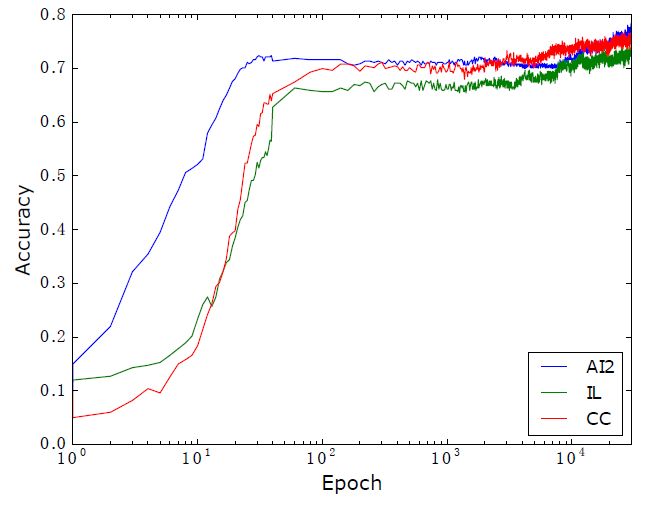
三個數據集準確率如下圖:
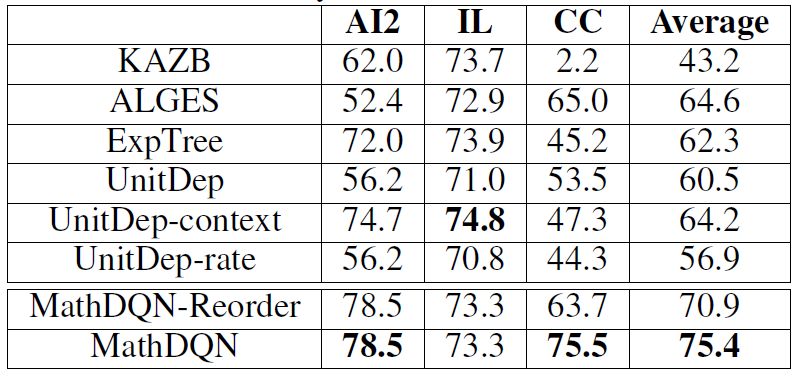
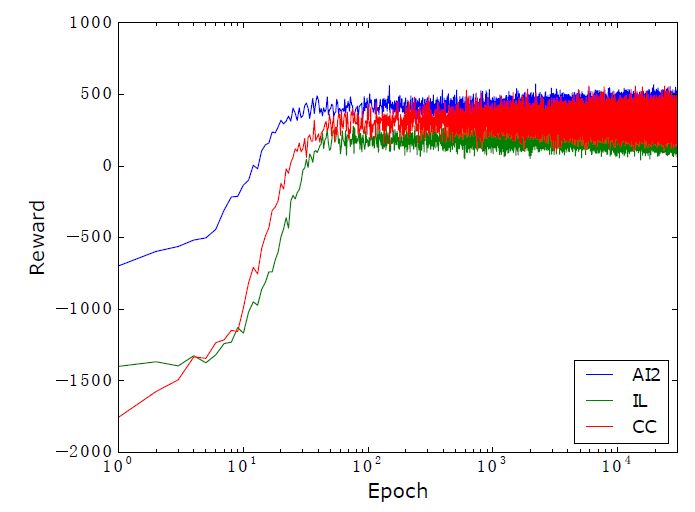
觀察上述實驗結果發現,本文提出的方法在AI2,CC數據集上取得了最好的效果。ALGES在IL上表現很好,但是在AI2和CC數據集上表現卻很差,這從側面證明了我們的方法有更好的通用性。UnitDep提出的單位依賴圖對只有加減運算的AI2數據集沒有明顯的效果,其增加的Context特征在CC數據集上有取得了明顯的效果,但是卻在AI2數據集上效果明顯下降,這里表現出人工特征的局限性。對于本文提出的方法,重排序在CC數據集上,提升效果明顯,由于AI2只有加減運算,IL只涉及單步運算,所以在這兩個數據集上效果不變。
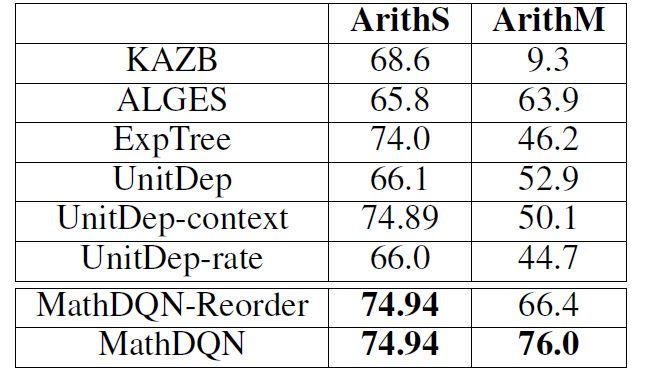
除此之外,本文還做了單步和多步的斷點分析,實驗效果表明,本文提出的方法在多步上表現十分優異,實驗結果如下圖:
運行時間如下圖:
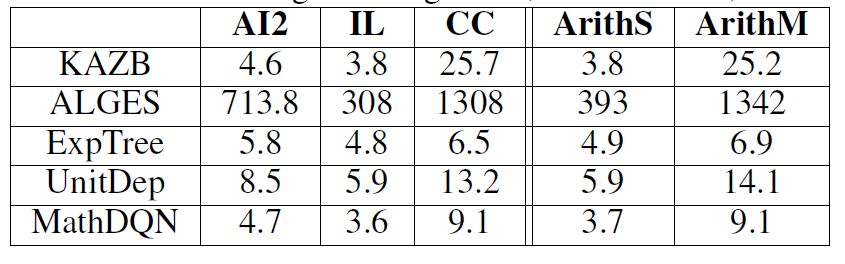
觀察單個題目求解需要的時間,我們可以發現,多步運算的數據集CC,在時間上明顯耗費更多。ALGES由于要枚舉所有可能的候選樹,因此耗費時間最長。本文提出的方法,求解效率僅次于只有SVM做運算符,和相關數字分類的ExpTree。
平均獎勵和準確率的走勢如下圖:
總結
本文首次提出了一個用于求解數學應用題的增強學習框架,在基準數據上其求解效率和求解效果展現出較好的效果。
未來,我們將繼續沿著深度學習,增強學習這條線去設計數學應用題自動求解器,來避免過多的人工特征。同時在更大更多樣化的數據集上,嘗試求解方程組應用題。
-
算法
+關注
關注
23文章
4612瀏覽量
92894 -
深度學習
+關注
關注
73文章
5503瀏覽量
121162
原文標題:【AAAI Oral】用DeepMind的DQN解數學題,準確率提升15%
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
動態分配多任務資源的移動端深度學習框架
人工智能首次超過人眼準確率 人臉識別準確度已經提升4個數量級
阿里達摩院公布自研語音識別模型DFSMN,識別準確率達96.04%
機器學習實用指南——準確率與召回率

人臉識別準確率大幅度提升,離不開科技企業的努力
MATLAB教程之如何使用MATLAB求解數學問題資料概述
AI垃圾分類的準確率和召回率達到99%
華裔女博士提出:Facebook提出用于超參數調整的自我監督學習框架
如何提升人臉門禁一體機的識別準確率?






 工商網監
工商網監
評論